计算机视觉(CV)——卷积神经网络基础
1. 卷积层
1.1 含义
- 对图像和滤波矩阵做内积(逐个元素相乘再求和)的操作
# 二维卷积示例
nn.Conv2d(in channels, out channels, kernel size, stride=1,padding=0, dilation=1, groups=1, bias=True)
各参数含义
- in_channels
输入的四维张量[N, C, H, W]中的C,即输入张量的channels数。这个形参是确定权重等可学习参数的shape所必需的。 - out_channels
即期望的四维输出张量的channels数。 - kernel_size
卷积核的大小,一般我们会使用5x5、3x3这种左右两个数相同的卷积核,因此这种情况只需要写kernel_size = 5这样的就行了。如果左右两个数不同,比如3x5的卷积核,那么写作kernel_size = (3, 5),注意需要写一个tuple,而不能写一个列表(list)。 - stride
卷积核在图像窗口上每次平移的间隔,即所谓的步长。这个概念和Tensorflow等其他框架没什么区别。 - padding
Pytorch与Tensorflow在卷积层实现上最大的差别就在于padding上。Padding即所谓的图像填充,后面的int型常数代表填充的多少(行数、列数),默认为0。需要注意的是这里的填充包括图像的上下左右,以padding = 1为例,若原始图像大小为32x32,那么padding后的图像大小就变成了34x34,而不是33x33。 - dilation = 1
这个参数决定了是否采用空洞卷积,默认为1(不采用)。从中文上来讲,这个参数的意义是从卷积核上的一个参数到另一个参数需要走过的距离,那当然默认是1了,毕竟不可能两个不同的参数占同一个地方吧(为0)。 - groups = 1
决定是否采用分组卷积,现在用的比较多的是groups = in_channel。当groups = in_channel时,是在做的depth-wise conv的,具体思想可以参考MobileNet那篇论文。 - bias = True
是否要添加偏置参数作为可学习参数的一个,默认为True。 - padding_mode = ‘zeros’
即padding的模式,默认采用零填充。
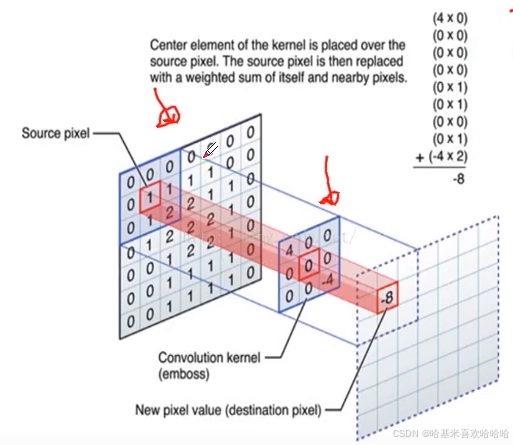
1.2 感受野(Receptive Field)
- 指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野
1.3 卷积层的参数量与计算量
- 参数量:参与计算参数的个数占用内存空间
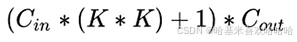
FLOPS:每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标;
FLOPs:浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
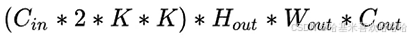
- MAC:乘加次数,用来衡量计算量。
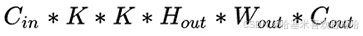
2. 池化层
2.1 定义
- 对输入的特征图进行压缩
- 一方面使特征图变小,简化网络计算复杂度
- 一方面进行特征压缩,提取主要特征
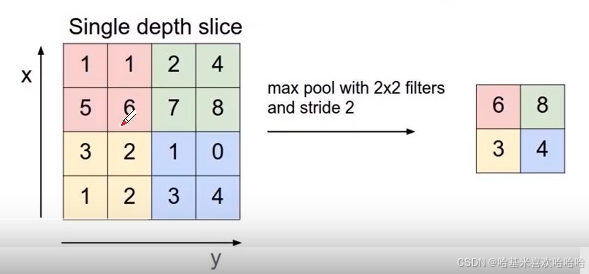
最大池化(Max Pooling)、平均池化(Average Pooling)等
Max Pooling的例子:
# pytorch中的调用
nn.MaxPool2d(kernel size, stride=None, padding=0, dilation=1return indices=False, ceil mode=False)
各参数含义
- kernel_size
注意这里的 kernel_size 跟卷积核不是一个东西。 kernel_size 可以看做是一个滑动窗口,这个窗口的大小由自己指定,如果输入是单个值,例如 3 ,那么窗口的大小就是 3 × 3 ,还可以输入元组,例如 (3, 2) ,那么窗口大小就是 3 × 2。 - stride
上一个参数我们确定了滑动窗口的大小,现在我们来确定这个窗口如何进行滑动。如果不指定这个参数,那么默认步长跟最大池化窗口大小一致。如果指定了参数,那么将按照我们指定的参数进行滑动。例如 stride=(2,3) , 那么窗口将每次向右滑动三个元素位置,或者向下滑动两个元素位置 - padding
这参数控制如何进行填充,填充值默认为0。如果是单个值,例如 1,那么将在周围填充一圈0。还可以用元组指定如何填充,例如 padding = ( 2 , 1 ),表示在上下两个方向个填充两行0,在左右两个方向各填充一列0。 - dilation
空洞卷积,默认 dilation=1,如果kernel_size =3,那么卷积核就是33的框。如果dilation = 2,kernel_size =3,那么每列数据与每列数据中间再加一列空洞,那么卷积核就变成5x5的框。 - return_indices
这是个布尔类型值,表示返回值中是否包含最大值位置的索引。注意这个最大值指的是在所有窗口中产生的最大值,如果窗口产生的最大值总共有5个,就会有5个返回值。 - ceil_mode
这个也是布尔类型值,它决定的是在计算输出结果形状的时候,是使用向上取整还是向下取整。
3. 上采样层
3.1 两种实现方式
- Resize,如双线性插值直接缩放,类似于图像缩放,概念可见最邻近插值算法和双线性插值算法一图像缩放
- 反卷积(Deconvolution),也叫Transposed Convolution
# Pytorch实现函数
nn.functional.interpolate(input, size=None, scale factor=None, mode='nearest, align corners=None)
nn.ConvTranspose2d(in channels, out channels, kernel size, stride=1, padding=0, output_padding=0, bias=True)
4. 激活层
- 激活函数:为了增加网络的非线性,进而提升网络的表达能力;
- ReLU函数、Leakly ReLU函数、ELU函数等
torch.nn.ReLU(inplace=True)
5. BatchNorm层
- 通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布
- Batchnorm是归一化的一种手段,它会减小图像之间的绝对差异,突出相对差异加快训练速度
- 不适用的问题:image-to-image以及对噪声敏感的任务
nn.BatchNorm2d(num features, eps=1e-05,momentum=0.1, affine=True.track running_stats=True)
6. 全连接层
- 连接所有的特征,将输出值送给分类器 (如softmax分类器)
- 对前层的特征进行一个加权和, (卷积层是将数据输入映射到隐层特征空间)将特征空间通过线性变换映射到样本标记空间(也就是label)
- 可以通过1x1卷积 +
global average pooling代替 - 可以通过全连接层参数几余
- 全连接层参数和尺寸相关
nn.Linear(in features, out features, bias)
7. Dropout层
- 在不同的训练过程中随机扔掉一部分神经元
- 测试过程中不使用随机失活,所有的神经元都激活
- 为了防止或减轻过拟合而使用的函数,它一般用在全连接层
nn.dropout
8. 损失层
- 设置一个损失函数用来比较网络的输出和目标值,通过最小化损失来驱动网络的训练
- 网络的损失通过前向操作计算,网络参数相对于损失函数的梯度则通过反向操作计算
# 分类问题损失(离散值,常用于分类/分割问题)
nn.BCELoss()
nn.CrossEntropyLoss()# 回归问题损失(连续值,常用于检测/预测)
nn.L1Loss
nn.MSELoss
nnSmoothL1Loss
9. 优化器
- GD、BGD、SGD、MBGD
- 引入了随机性和噪声
- Momentum、NAG等
- 加入动量原则,具有加速梯度下降的作用
- AdaGrad,RMSProp,Adam、AdaDelta
- 自适应学习率
torch.optim.Adam