[论文阅读] 人工智能 + 软件工程 | 大型语言模型对决传统方法:多语言漏洞修复能力大比拼
大型语言模型对决传统方法:多语言漏洞修复能力大比拼
论文阅读:On the Evaluation of Large Language Models in Multilingual Vulnerability Repair
arXiv:2508.03470
On the Evaluation of Large Language Models in Multilingual Vulnerability Repair
Dong wang, Junji Yu, Honglin Shu, Michael Fu, Chakkrit Tantithamthavorn, Yasutaka Kamei, Junjie Chen
Subjects: Software Engineering (cs.SE)
一段话总结
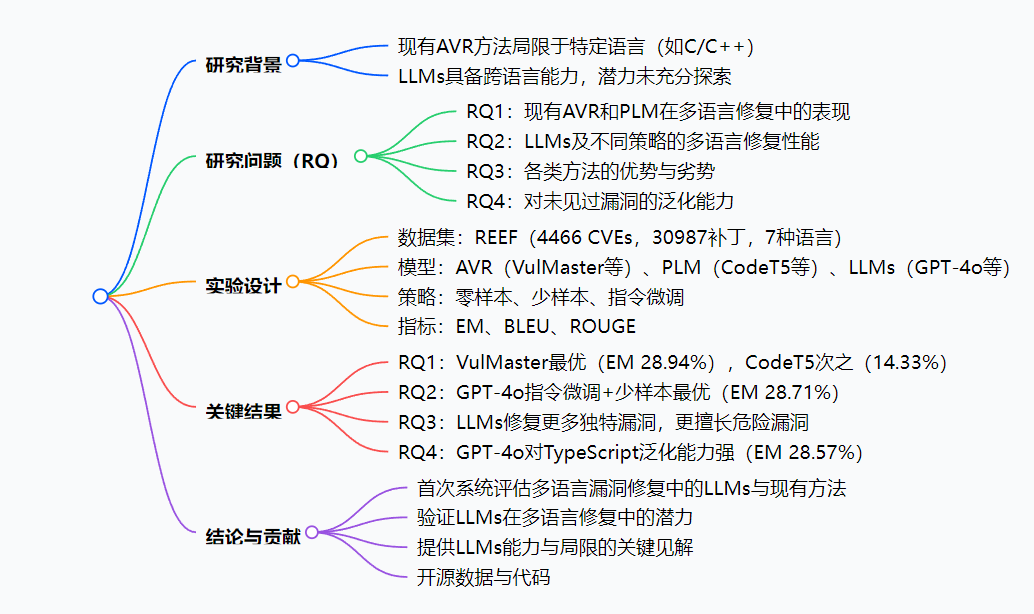
本文通过大规模实证研究,评估了现有自动漏洞修复(AVR)方法和大型语言模型(LLMs) 在七种编程语言(C、C#、C++、Go、JavaScript、Java、Python)中的漏洞修复性能。研究发现,GPT-4o在指令微调结合少样本提示策略下,Exact Match(EM)分数达28.71%,与最优AVR方法VulMaster(28.94%)相当;LLM方法在修复独特漏洞和最危险漏洞上更具优势,对未见过的编程语言(如TypeScript)泛化能力更强;所有模型在Go语言上修复效果最佳,C/C++ 最差。该研究为LLMs在多语言漏洞修复中的应用提供了关键 insights。
研究背景
想象一下,你手机里的APP、电脑上的软件,就像一座座复杂的城堡,而“软件漏洞”就是城堡墙上的裂缝——黑客可能通过这些裂缝闯入,窃取你的信息、操控设备,甚至造成巨大损失。比如2021年的Log4Shell漏洞,堪称“十年一遇的大裂缝”,攻击者能在任何受影响的系统上执行恶意代码,导致无数用户遭殃。
随着软件越来越复杂,漏洞数量也在飙升。2023年报告的软件漏洞多达28961个,比2022年猛增15.57%。但修复这些漏洞可不是件容易事:一方面,需要专业知识;另一方面,手动修复平均要45天以上,远跟不上漏洞出现的速度。
过去,研究者们开发了不少基于深度学习的“自动漏洞修复工具”,但这些工具大多只擅长修复C/C++语言的漏洞。可现在的软件开发早已是“多国部队”——Python、Java、Go等语言都广泛使用,它们的漏洞同样需要关注。这就像只给消防员配备了扑灭木房火灾的工具,却面对的是钢筋水泥建筑的火灾,显然不够用。
而近年来大火的大型语言模型(LLMs),比如GPT系列,号称能理解多种语言,甚至能写代码。那么,它们能不能成为“多语言漏洞修复”的万能灭火器?这正是这篇论文要探究的问题。
主要作者及单位信息
- DONG WANG,天津大学智能与计算学部
- JUNJI YU,天津大学智能与计算学部
- HONGLIN SHU,九州大学(日本)
- MICHAEL FU,墨尔本大学(澳大利亚)
- CHAKKRIT TANTITHAMTHAVORN,莫纳什大学(澳大利亚)
- YASUTAKA KAMEI,九州大学(日本)
- JUNJIE CHEN(通讯作者),天津大学智能与计算学部
创新点
这篇论文的“独特亮点”主要有三个:
-
首次全面对比:是首个系统评估“传统自动修复方法”和“大型语言模型”在多语言漏洞修复中表现的研究,覆盖了7种主流编程语言(C、C#、C++、Go、JavaScript、Java、Python)。
-
策略深挖:不仅测试了LLMs的基础能力,还设计了“零样本提示”“少样本提示”“指令微调”等多种策略,找到让LLMs发挥最佳效果的方式。
-
泛化能力验证:专门测试了模型对“从未见过的编程语言”(如TypeScript)的漏洞修复能力,这对实际应用至关重要——毕竟软件世界总有新语言出现。
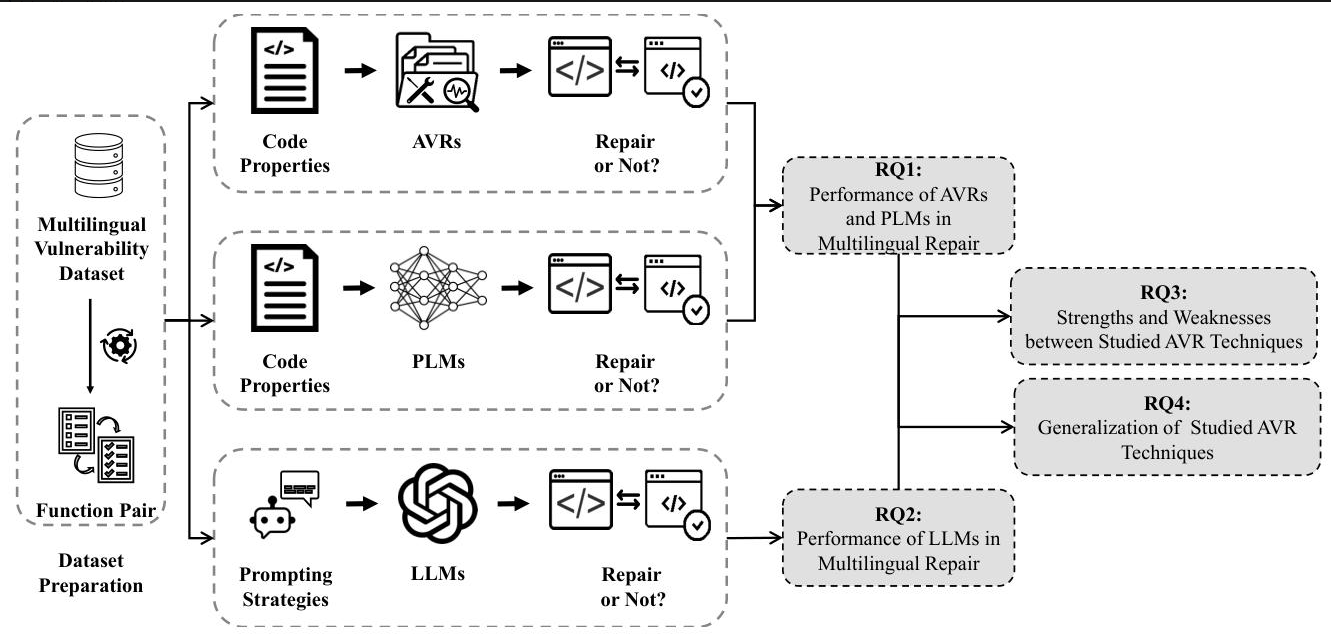
研究方法和思路
研究团队就像一场“漏洞修复大赛”的组织者,设计了一套严谨的“比赛规则”,步骤如下:
-
选数据集:用了目前最新的多语言漏洞数据集REEF,里面有4466个真实漏洞案例(CVE),30987个修复补丁,覆盖7种语言。相当于给参赛者准备了丰富的“练习题”。
-
确定参赛选手:
- 传统自动修复工具(AVR):比如VulMaster、VulRepair等5种,都是该领域的佼佼者。
- 预训练语言模型(PLM):比如CodeBERT、CodeT5等7种,擅长处理代码的AI模型。
- 大型语言模型(LLMs):包括DeepSeek-Coder、Code Llama、Llama 3、GPT-3.5-Turbo、GPT-4o,既有开源的,也有闭源的。
-
设计比赛项目:
- 基础能力测试(RQ1):传统工具和PLM在多语言修复中表现如何?
- LLM专项测试(RQ2):不同LLM用不同策略(零样本、少样本、指令微调)时,谁修复得最好?
- 优劣势分析(RQ3):哪种方法擅长修复独特漏洞?哪种更能处理危险漏洞?
- 泛化能力测试(RQ4):对没学过的语言(如TypeScript),模型还能修复漏洞吗?
-
评分标准:用三个指标打分:
- Exact Match(EM):修复结果和正确答案完全一样的比例,相当于“全对”。
- BLEU-4:生成代码和正确答案的相似度,看“意思对不对”。
- ROUGE:评估修复内容的覆盖度,看“关键部分有没有修到”。
主要贡献
这篇论文的成果就像给“漏洞修复界”投下了一颗重磅炸弹,带来了三个关键价值:
-
找到了当前最佳选手:GPT-4o在“指令微调+少样本提示”策略下,EM分数达28.71%,和传统工具中最强的VulMaster(28.94%)几乎打平。这意味着LLMs已经具备挑战传统方法的实力。
-
揭示了LLMs的独特优势:
- 更擅长修复“独特漏洞”:LLM能修复169个传统工具修不了的漏洞,比VulMaster多24%。
- 更能处理危险漏洞:在2023年最危险的25种漏洞中,LLM修复成功率32.48%,高于传统工具的31.15%。
- 泛化能力强:对没学过的TypeScript语言,GPT-4o修复成功率28.57%,而VulMaster只有5.88%。
-
指明了语言差异:所有模型在Go语言上修复效果最好(平均EM 31.59%),在C/C++上最差(C++仅6.73%)。这可能和Go语法简洁、C/C++复杂有关,为后续优化指明方向。
2. 思维导图
3. 详细总结
1. 研究背景与目的
- 背景:现有基于深度学习的自动漏洞修复(AVR)方法局限于特定语言(如C/C++),而大型语言模型(LLMs)具备跨语言能力,但在多语言漏洞修复中的有效性尚未明确。
- 目的:通过大规模实证研究,对比现有AVR方法、预训练语言模型(PLMs)和LLMs在七种编程语言中的漏洞修复性能,探索LLMs的潜力与局限。
2. 实验设计
- 数据集:采用REEF多语言漏洞数据集,包含4466个CVE、30987个补丁,覆盖7种语言(C、C#、C++、Go、JavaScript、Java、Python),经处理后得到10649个函数对(训练集7448、验证集1059、测试集2142)。
- 模型:
- AVR方法:VulMaster、VulRepair等5种;
- PLMs:CodeBERT、CodeT5等7种;
- LLMs:DeepSeek-Coder、Code Llama、Llama 3、GPT-3.5-Turbo、GPT-4o共5种。
- LLM策略:零样本提示、少样本提示(BM25选3个示例)、指令微调(结合LoRA)。
- 评估指标:Exact Match(EM)、BLEU-4、ROUGE-1/2/L。
3. 研究结果(RQ1-RQ4)
| 研究问题 | 关键发现 | 关键数据 |
|---|---|---|
| RQ1:现有方法表现 | VulMaster最优,Encoder-decoder PLMs(如CodeT5)优于其他PLMs;Go效果最好,C/C++最差 | VulMaster的EM(beam 1)为28.94%,CodeT5为14.33% |
| RQ2:LLMs表现 | 指令微调+少样本策略最优,GPT-4o的EM达28.71%,与VulMaster无统计差异;Go最佳,C/C++最差 | GPT-4o(指令微调+少样本)EM 28.71%,McNemar检验p=0.8314 |
| RQ3:方法优劣势 | LLM(GPT-4o)修复169个独特漏洞,多于VulMaster(136个);在2023年Top25危险CWE中修复率32.48%,高于AVR(31.15%) | 独特正确修复:LLM 169 > AVR 136 > PLM 8 |
| RQ4:泛化能力 | GPT-4o对未见过的TypeScript漏洞EM达28.57%,远超VulMaster(5.88%) | TypeScript修复:GPT-4o 28.57% vs VulMaster 5.88% |
4. 结论与贡献
- 首次系统评估多语言漏洞修复中的AVR、PLM和LLMs;
- 验证了LLMs(尤其指令微调+少样本策略)在多语言修复中的潜力;
- 揭示了LLMs的能力与局限,为未来研究提供指导;
- 开源数据、代码和分析细节。
4. 关键问题
-
问题:在多语言漏洞修复中,LLMs与现有最优AVR方法(如VulMaster)的核心差异是什么?
答案:LLMs(如GPT-4o,指令微调+少样本)在EM分数上与VulMaster接近(28.71% vs 28.94%),但在修复独特漏洞(169个 vs 136个)和2023年Top25危险CWE(32.48% vs 31.15%)上表现更优,且对未见过的语言(如TypeScript)泛化能力更强(28.57% vs 5.88%)。 -
问题:哪种LLM策略对多语言漏洞修复最有效?其性能如何?
答案:指令微调结合少样本提示策略最有效。其中,GPT-4o在该策略下EM达28.71%,BLEU-4为0.8448,ROUGE-1为0.9232,显著优于零样本(0.33%)和单纯少样本(26.89%)策略,且在7种语言中对Go修复效果最好(41.02%),C/C++最差(13.82%)。 -
问题:不同编程语言的漏洞修复效果有何差异?原因可能是什么?
答案:所有模型在Go语言上修复效果最佳( median EM 31.59%),C/C++ 最差(C:8.03%,C++:6.73%)。可能原因是Go语言较新、语法简洁,而C/C++语法复杂、内存操作等漏洞类型更难修复。
总结
这篇论文通过大规模实验,全面对比了传统自动修复工具、预训练模型和大型语言模型在多语言漏洞修复中的表现。结果显示:
- 传统工具中,VulMaster表现最佳(EM 28.94%);
- 大型语言模型中,GPT-4o在“指令微调+少样本提示”策略下表现最优(EM 28.71%),与VulMaster不相上下;
- LLMs在修复独特漏洞、危险漏洞和未见过的语言漏洞上更有优势;
- 所有模型在Go语言上修复效果最好,C/C++最差。
这项研究证明了LLMs在多语言漏洞修复中的巨大潜力,为未来开发更通用、更高效的漏洞修复工具提供了重要参考。
解决的主要问题/成果
- 解决了“传统工具语言局限”的问题,证明LLMs能跨语言修复漏洞。
- 找到了LLMs的最佳使用策略(指令微调+少样本提示),为实际应用提供指导。
- 揭示了不同语言修复难度的差异,帮助研究者针对性优化模型。
- 开源了所有数据和代码,方便其他研究者继续探索。