专题二_滑动窗口_串联所有单词的子串
前提:
此题难度较大,但是和上一道题有极大的相似!所以看了上一道题,会更易理解!专题二_滑动窗口_找到字符串中所有字母异位词-CSDN博客!
一:题目

解释:上一道题异位词的单位是字符,此题异位词单位是字符串罢了!
二:算法
和上一题的区别:
1:哈希表的类型<string,int>
解释:我们不能再用数组模拟哈希表了,上一道题能是因为字符可以通过减去'a'得到0~25的下标,但此题是字符串,我们无法将其转换为下标,所以直接用哈希表,哈希表中含有哈希函数,将字符串转换为下标!int则代表该字符串的个数!
2:left和right的移动步长为len个
解释:因为异位词的单位字符串,所以双指针的步长为一个字符串的长度。而题目中已经说清楚了words字符串数组中的每个字符串长度相同,这样步长len一开始就可以固定了!
3:滑动窗口不再只执行一次
Q1:为什么不再只执行一次?
A1:
输入:s = "barfoothefoobarman", words = ["foo","bar"] 输出:[0,9]
情况1:仅单词滑动窗口:

这种情况单词滑动窗口就已经足够了,但是有些情况,不止一次
情况2:需多次滑动窗口:
输入:s = "barfoothefoobarman", words = ["arf","oot"] 输出:[1]
此时,我们仍然进行从下标为0的滑动窗口:

我们再从下标为1开始:
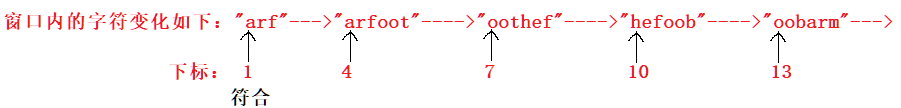
解释:此时才检索到了正确的答案!所以要从不同起点开始滑动窗口才能够检测到所有的单词!
Q2:为什么窗口一会是3个字符,一会是6个字符?
A2:无论是2还是4,都不会影响什么,因为我们只会从right开始向后读取和words中元素等长的字符来判断时候是有效的单词,比如"arf",此时right位于a,"arfoot",此时right位于o,所以只用保证窗口内的单词的个数不会超过words的元素个数即可!
类比上道题:我们只会保证窗口内的字符个数不会超过目标字符串的长度,只不过此题的单位不同罢了,单词的长度是固定的,所以保证窗口被单词的个数,不超过words中的即可!
Q3:那应该执行几次滑动窗口?
A3:words中的单个单词有多长,则应该执行多少次,如果words中的单词长度为3,则应该从s字符串的下标0,下标1,下标2,开始执行三次滑动窗口,这样才能获取到所有可能!而从下标3开始执行互动窗口,其实就是从下标0执行滑动窗口的第二步罢了!
如下图:

解释:所以从3开始本质就是从0开始,从4开始本质就是从1开始,从5开始本质就是从2开始....。所以执行多少次,根据words中的单词的长度而定!!
①:暴力
暴力解法就是没有用滑动窗口,这意味着每次left要以不同的元素作为下标,然后right向右遍历,列举出所有的结果可能:

解释:left从0,1,2,3,4...开始作为起点,每次内部都向右划分6个字符作为一种可能去判断,其次每次有了新的可能,会把旧可能从哈希表中剔除,然后放进新的可能,所以很麻烦!
②:滑动窗口
而滑动窗口,本质就是我们发现双指针可以同向移动,当你right向右遍历想进窗口的时候,则你左面从left开始截取一个单词长度取出窗口即可,所以双指针同向移动,使用滑动窗口!
但是滑动窗口有很多注意的点!
1:哈希表的选择
我们选择的是unodered_map,首先存储的是kv值,所以选择map,其次我们不关心是否有序,所以选择unodered,其次我们会经常插入删除哈希表,而unodered_map的底层是哈希,map的底层是红黑树,哈希不换是删除还是插入的速度都远高于红黑树!所以选择unodered_map!
2:滑动窗口for循环上限
在上道题中right的上限<n(字符串的元素个数)即可,但是此题不再是了!
我们的right代表的从s字符串中,从right处开始向右面取一个单词长度,去进窗口,所以我们一定要考虑right+len和n的关系,要让不同起点的滑动窗口,最后一次也能安全得取到一个完整的单词!
所以right+len应该最多刚好等于n,也就是right+len<=n!
Q1:为什么<=n,n代表的是字符串的元素个数,==n不是会越界吗?
A1:等于n的确会越界,但是如果right=5,现在单词长度为3,则我们应该从下标5开始向右取到7,则现在下标567这三个字符作为一个单词,但是我们的写法是right+len--->5+3=8,所以我们的写法就多加了一个!所以才会写作<=,当然你也可以写成:right+len-1 < s.size()
所以写法为两种:right+len-1 < s.size(); 和 right+len <= s.size();
Q2:那right < s.size()len+1; 和 right<= s.size()-len;呢?
A2:万万不可,这样写必错!
报错如下:
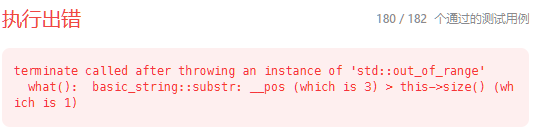
含义为:调用 substr() 方法时发生了越界访问,也就是使用substr()的时候,要么参数就已经越距了,要么取截取字符的时候,某些字符越距!
这是因为:right < s.size()len+1; 和 right<= s.size()-len;的写法具有潜在风险!
以 right<= s.size()-len为例:
假设:
s.size() = 5(字符串长度)
len = 10(单词长度)
right = 0(初始位置)危险写法:
right <= s.size() - len → 0 <= 5 - 10 → 0 <= 4294967291(因为 size()函数返回的是size_t,其是是无符号整数,-5会变成正数) → 结果为 true(错误判断!)导致会继续调用substr(right,len),导致越界!
三:代码
①:最优版本
class Solution {
public:vector<int> findSubstring(string s, vector<string>& words) {vector<int> ret;//返回值unordered_map<string, int> hash2;//存储words的哈希表for (auto& str : words)//将words存储进hash2中hash2[str]++;int len = words[0].size();//words中单词的长度int num = words.size();//words中单词的个数for (int i = 0; i < len; i++) //滑动窗口的次数{unordered_map<string, int> hash1;//每次滑动窗口适应的哈希表for (int left = i, right = i, count = 0; right + len <= s.size(); right += len) {//进窗口string in = s.substr(right, len);//先得到进窗口的元素hash1[in]++;//存储进哈希表if (hash2.count(in) && hash1[in] <= hash2[in]) //进窗口后,窗口哈希表的v值<=存储words哈希表的v值 代表是是有效频次!count++;//窗口长度长处words数组的长度(数组元素*数组个数)while (right - left + len > len * num) {//出窗口string out = s.substr(left, len);//先得到出窗口的元素if (hash2.count(out) && hash1[out] <= hash2[out])//存储进哈希表之后后,窗口哈希表的v值<=存储words哈希表的v值 代表是是有效频次!count--;hash1[out]--;//从哈希表中移除left += len;//移动步长为len}if (count == num)//判断存储结果ret.push_back(left);}}return ret;}
};解释:最优版本,不仅采取了unordered_map和滑动窗口,还在每次比较两个哈希表元素的v值之前,先判断了hash2(存储words元素)是否存在该元素,不存在,则直接不用比较
易错:hash1作为每次滑动窗口使用的哈希表,应该在两层for循环之间定义,这样才能保证每次滑动窗口用的哈希表是新创建的,所以是干净的,hash1放在两层for外定义,则每次滑动窗口会被一轮滑动窗口残留在哈希表中的数据影响!
②:一般版本
下面是你选择map 和 直接比较两个哈希表的代码,也是可以通过的,但不够优秀!
class Solution {
public:vector<int> findSubstring(string s, vector<string>& words) {vector<int> ret;//返回值map<string, int> hash2;//存储words的哈希表for (auto& str : words)//将words存储进hash2中hash2[str]++;int len = words[0].size();//words中单词的长度int num = words.size();//words中单词的个数for (int i = 0; i < len; i++) //滑动窗口的次数{map<string, int> hash1;//每次滑动窗口适应的哈希表for (int left = i, right = i, count = 0; right + len <= s.size(); right += len) {//进窗口string in = s.substr(right, len);//先得到进窗口的元素hash1[in]++;//存储进哈希表if (hash1[in] <= hash2[in]) //进窗口后,窗口哈希表的v值<=存储words哈希表的v值 代表是是有效频次!count++;//窗口长度长处words数组的长度(数组元素*数组个数)while (right - left + len > len * num) {//出窗口string out = s.substr(left, len);//先得到出窗口的元素if (hash1[out] <= hash2[out])//存储进哈希表之后后,窗口哈希表的v值<=存储words哈希表的v值 代表是是有效频次!count--;hash1[out]--;//从哈希表中移除left += len;//移动步长为len}if (count == num)//判断存储结果ret.push_back(left);}}return ret;}
};