DevOps:从GitLab .gitlab-ci.yml 配置文件到CI/CD
引言
在现代软件开发中,持续集成(CI)和持续部署(CD)是不可或缺的一环。它不仅能自动化测试和部署流程,还能显著提升开发效率和软件质量。GitLab CI/CD 是 GitLab 内置的强大工具,它通过一个名为 .gitlab-ci.yml 的配置文件,让开发者能够轻松定义、管理和执行自己的 CI/CD Pipeline。
本文将带大家从零开始,深入了解 GitLab CI/CD 的核心概念,并通过一个实际案例,手把手教大家如何构建一个从代码提交到自动化部署的完整流程。
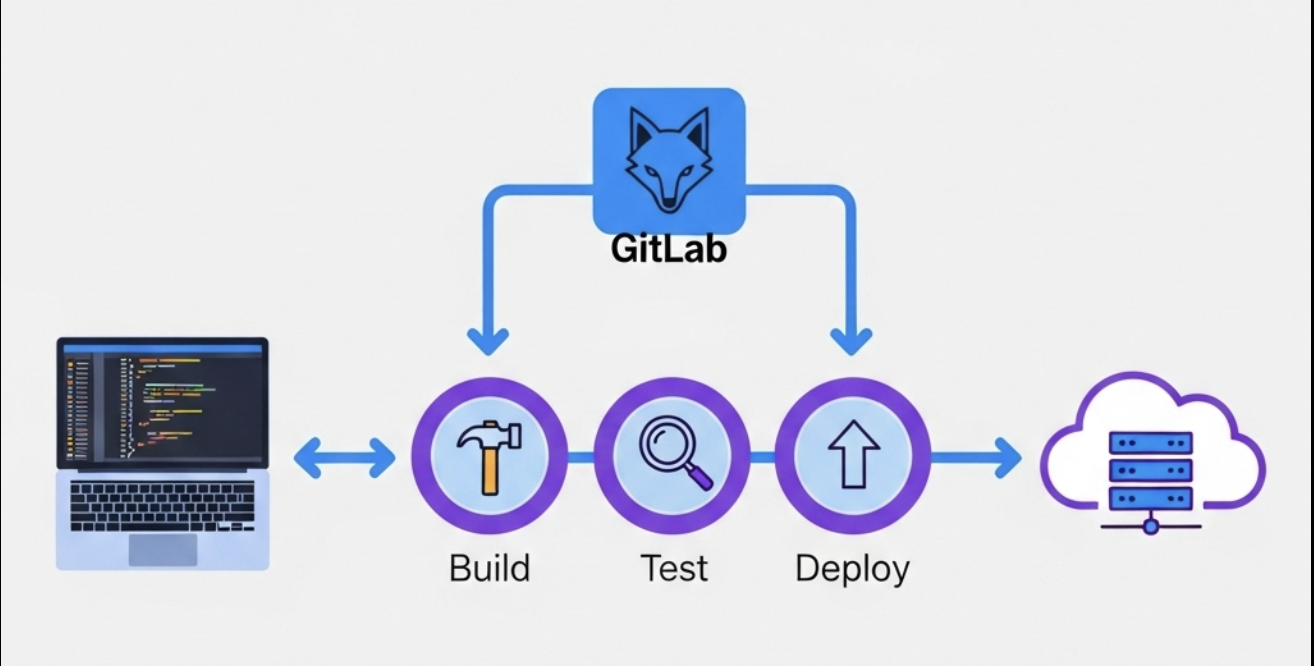
GitLab CI/CD 的核心基石
.gitlab-ci.yml 文件
这是 GitLab CI/CD 的心脏。每个项目根目录下的 .gitlab-ci.yml 文件定义了该项目的 CI/CD 流程。GitLab 会自动检测这个文件,并根据其内容执行相应的任务。
Pipeline(流水线)
Pipeline 是 CI/CD 的最高层级概念,代表了一次完整的构建、测试和部署过程。它由多个 Stage(阶段)和 Job(任务)组成。当开发者向仓库推送代码时,通常会自动触发一个新的 Pipeline。
Stage(阶段)
Stage 表示 Pipeline 中的一个环节,例如 build(构建)、test(测试)、deploy(部署)。同一 Stage 中的所有 Job 会并行执行,只有当前一个 Stage 的所有 Job 都成功完成后,下一个 Stage 才会开始执行。
Job(任务)
Job 是具体执行的任务,例如编译代码、运行单元测试、打包应用等。Job 是 CI/CD 流程中的最小执行单元,它运行在 GitLab Runner 之上。
GitLab Runner
Runner 是实际执行 Job 的代理程序。大家可以将其安装在任何机器上(物理机、虚拟机或容器)。Runner 会从 GitLab CI/CD 拉取待处理的 Job,并在其所在的环境中执行。Runner 分为三种类型:
- Shared Runners:由 GitLab 官方维护,可供所有项目使用。
- Specific Runners:由用户自己搭建,并指定给特定的项目。
- Group Runners:可供一个 GitLab Group 下的所有项目使用。
实践案例:构建一个 Node.js 应用的 CI/CD 流程
理论讲完了,让我们通过一个具体的例子来实践一下。假设我们有一个简单的 Node.js Express 应用,我们希望实现以下自动化流程:
- 代码构建:安装项目依赖。
- 代码测试:运行单元测试。
- 部署:将应用部署到服务器(这里我们仅作模拟)。
步骤一:创建 .gitlab-ci.yml
在我们的项目根目录下,创建一个名为 .gitlab-ci.yml 的文件,并填入以下内容:
# 定义 Stages
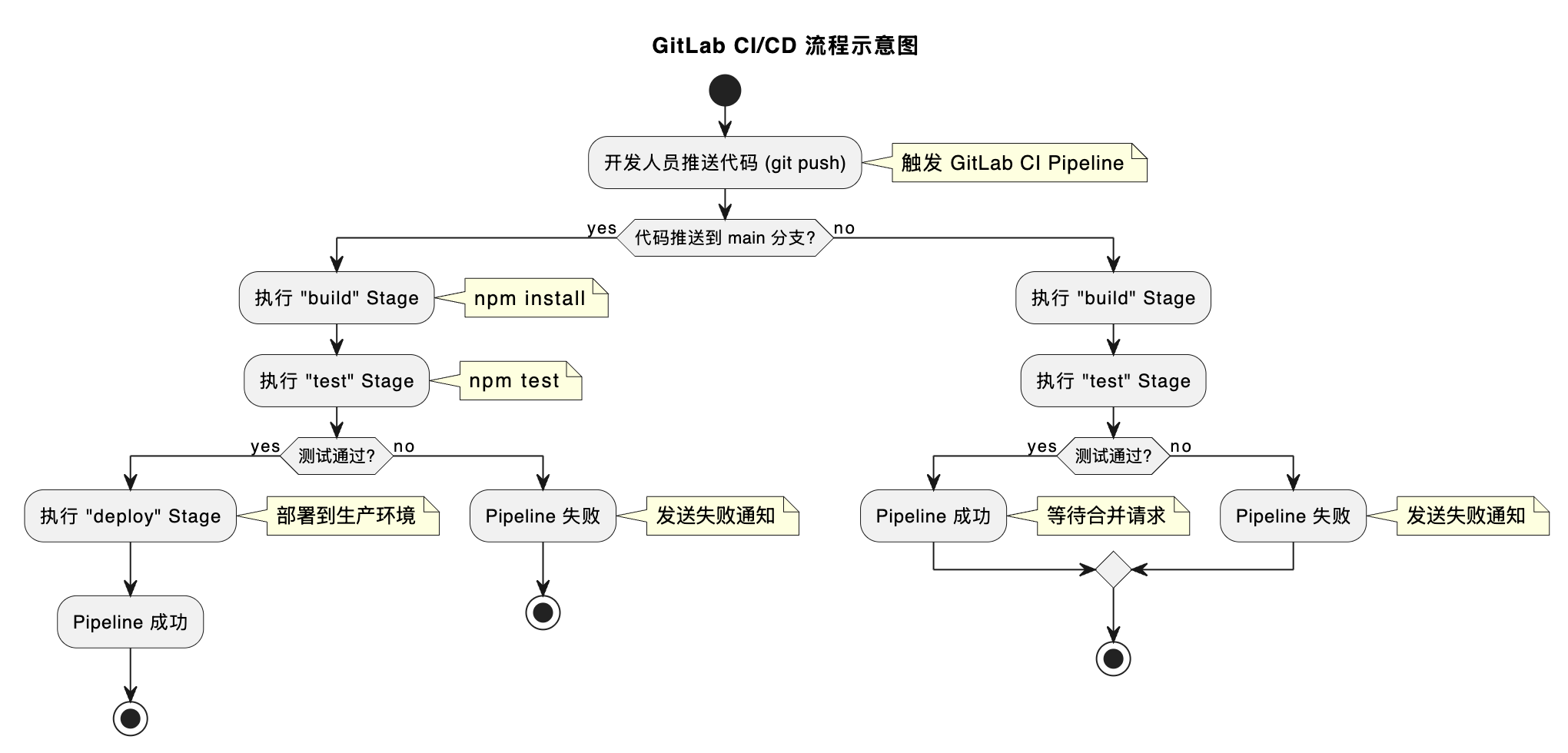
stages:- build- test- deploy# 缓存 node_modules 以加速后续 Job
cache:key: ${CI_COMMIT_REF_SLUG}paths:- node_modules/# Build Stage 的 Job
build_job:stage: buildimage: node:22 # 指定运行环境的 Docker 镜像script:- echo "Installing dependencies..."- npm installartifacts:paths:- node_modules/ # 将 node_modules 作为产物传递给下一个 Stage# Test Stage 的 Job
test_job:stage: testimage: node:18script:- echo "Running tests..."- npm test # 假设我们的 package.json 中定义了 test 命令# Deploy Stage 的 Job
deploy_job:stage: deployimage: node:18script:- echo "Deploying application..."# 在真实场景中,这里会是部署脚本,例如:# - ssh user@server "cd /path/to/app && git pull && npm install && pm2 restart app"- echo "Application successfully deployed."environment:name: productiononly:- main # 仅在 main 分支上执行此 Job
步骤二:代码解读与分析
- stages: 定义了 Pipeline 的三个阶段:
build,test,deploy。它们会按顺序执行。 - cache:
cache指令用于缓存node_modules目录。这样,在不同的 Job 之间就不需要重复下载依赖,大大加快了 Pipeline 的执行速度。 - image:
image关键字指定了运行 Job 所需的 Docker 镜像。这里我们使用了官方的node:18镜像。 - script:
script部分包含了需要执行的 shell 命令。 - artifacts:
build_job使用artifacts将node_modules目录保存为“构建产物”。这样,后续的test_job就可以直接使用这些依赖,而无需重新安装。 - environment:
deploy_job中的environment关键字用于声明该 Job 会将代码部署到哪个环境。这在 GitLab 的操作界面上会有直观的展示。 - only:
only: - main表示deploy_job只会在代码被推送到main分支时才会执行,防止在开发分支上触发生产部署。
流程可视化
为了更直观地理解这个 CI/CD 流程,我们可以使用 UML 将其建模。
实用建议与最佳实践
- 使用变量管理敏感信息:不要将 API 密钥、密码等硬编码在
.gitlab-ci.yml中。使用 GitLab CI/CD 的变量功能(Settings > CI/CD > Variables)来安全地存储和使用它们。 - 利用
include拆分配置:对于复杂的项目,.gitlab-ci.yml文件可能会变得非常庞大。使用include关键字可以将配置拆分到多个文件中,提高可读性和可维护性。 - 优化 Docker 镜像:选择体积更小、更专注的基础镜像(如
node:18-alpine),可以减少 Job 的启动时间。 - 并行执行:将耗时但互不依赖的 Job 放在同一个 Stage 中,让它们并行执行,可以有效缩短整个 Pipeline 的运行时间。
结论
GitLab CI/CD 是一个功能强大且易于上手的自动化工具。通过一个简单的 .gitlab-ci.yml 文件,我们就可以为我们的项目插上自动化的翅膀,将繁琐的构建、测试和部署工作交给机器,让开发者能更专注于创造性的编码工作。