Linux上MySql CPU 占用异常
早上用户反馈系统很卡,一直转圈圈,然后去复现一下,确实存在。然后马上去服务器上一看,cpu跑满,太夸张了,之前也没有出现过这样的情况。
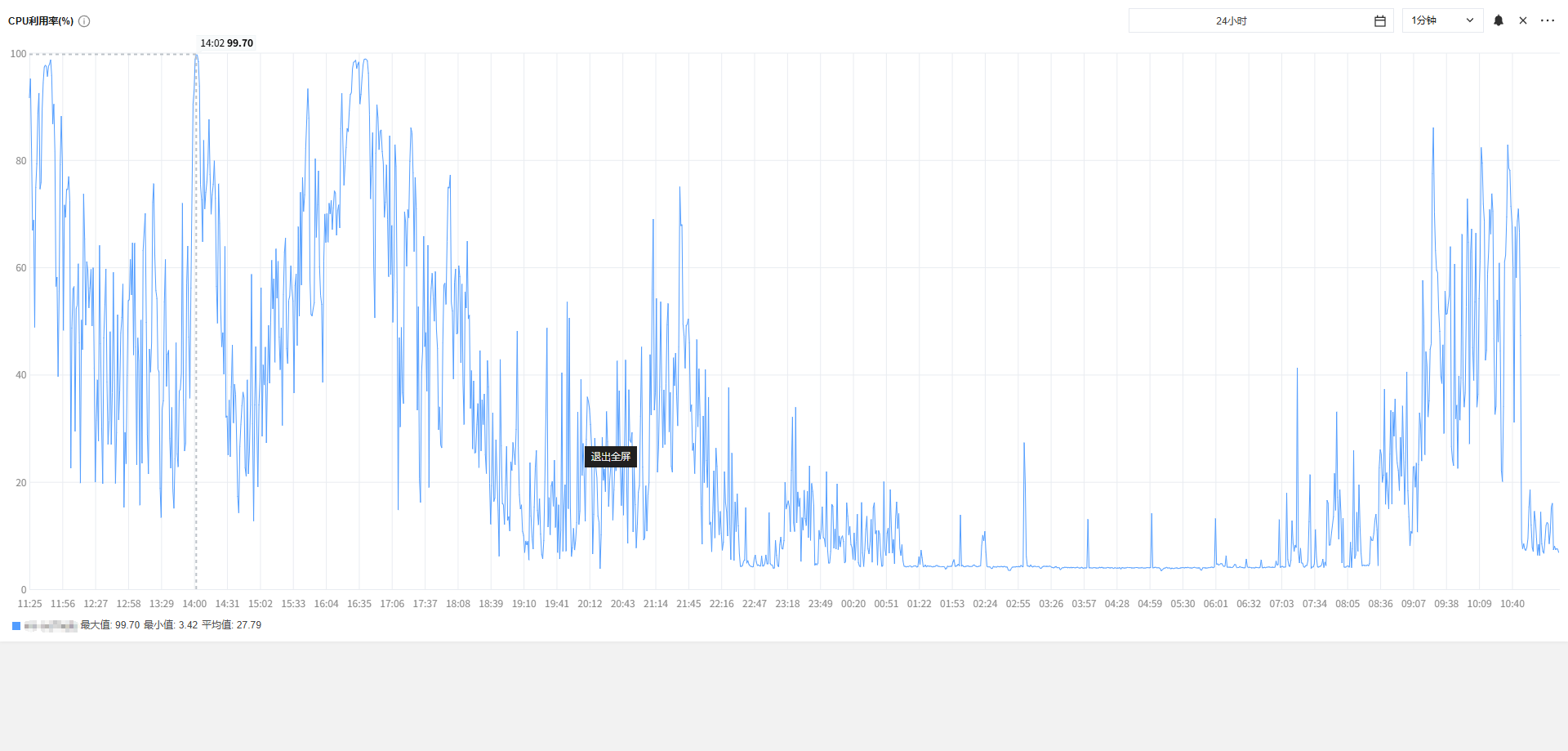
首先 进入服务器后,使用命令:top -c,查看系统资源使用情况。
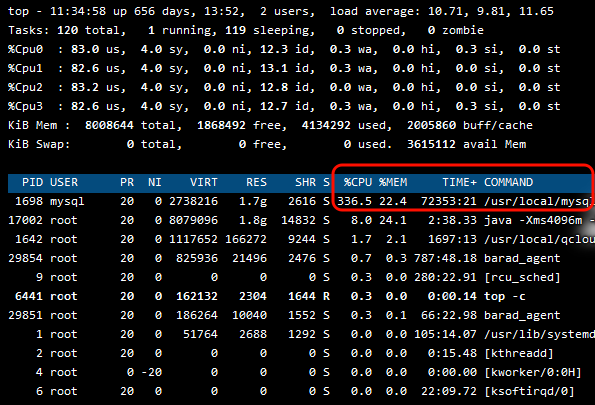
直接爆满了,这不卡死才怪。
mysql跑满还是第一次,心想前面也没有更新过服务,怎么今天突然卡住了,还以为是哪块代码有问题,直接重启服务了(大家不要学我),发现没有用。
去mysql里面找问题所在:
- 使用 mysql -uroot -p 然后再输入密码,进入mysql服务

- 使用:show processlist; 去查看MySQL实时线程状态
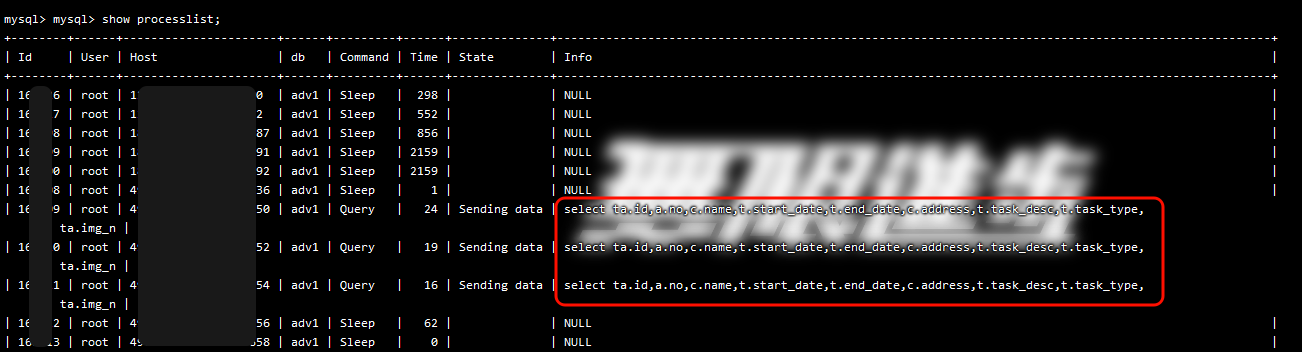 发现大量重复SQL以及阻塞线程(
发现大量重复SQL以及阻塞线程(State含Locked、Sending data、Sorting result),并且Time时间长达几时秒 - 马上去找代码和完整sql,本地运行也很慢,首先想到的优化sql本身,有效果但不明显。后想起来索引有没有生效,使用 EXPLAIN (放在sql前面)发现也是生效的。不过,又发现检索的行数据异常

- 索引确实生效,但访问类型为 ref,表示使用了非唯一索引扫描,扫描行数高达 580,564 行(rows 列),过滤后仅保留 2.42% 的数据(约 14,000 行),Using where 表示索引未能完全覆盖查询,需要回表检查数据。
- 针对该sql,考虑使用复合索引,能够覆盖查询中的三个条件:
del_flag=0、executor_status IN (1,2)、(NOW() >= execute_time OR execute_time IS NULL),减少回表操作(从 580k 行 → 直接定位有效数据)实测从之前的4-5秒,缩短至0.几秒。 - 若之前该字段有索引,可以将其删除(不删除也行),然后添加复合索引:
- ALTER TABLE tb_task_adv
- DROP INDEX del_flag
- ADD INDEX idx_adv_core (del_flag, executor_status, execute_time);
最后,不要觉得索引好用添加过多索引,索引太多,添加数据的时候会多耗时间的。