工业相机使用 YOLOv8深度学习模型 及 OpenCV 实现目标检测简单介绍

工工业相机使用 YOLOv8深度学习模型 及 OpenCV 实现目标检测
- Yolo深度学习模型YOLOv8进行目标检测
- 深度学习的目标检测常用算法
- 一、R-CNN 家族系列算法
- 二、单发检测器(SSD)
- 三、YOLO 算法
- YOLO应用于图像对象检测
- YOLO应用于视频检测
- YOLO目标检测器的限制
Yolo深度学习模型YOLOv8进行目标检测
在计算机视觉领域,目标检测是工业应用中既热门又成熟的方向,涵盖人脸识别、行人检测等众多场景,国内的旷视科技、商汤科技等企业在该领域处于行业领先地位。相较于图像分类任务,目标检测更为复杂 —— 它不仅需要判断图像的类别,还需明确图像中包含的目标及其位置信息,因此在工业场景中应用广泛。
在目标检测领域,“你只需要看一次”(You Only Look Once,YOLO)算法表现卓越,而 Ultralytics YOLOv8 更是其中的前沿标杆,属于最先进(SOTA)的模型。它在先前 YOLO 版本的成功基础上,融入了新功能与改进,进一步提升了性能与灵活性。凭借快速、准确且易用的特性,YOLOv8 成为物体检测与跟踪、实例分割、图像分类及姿态估计等各类任务的理想选择。
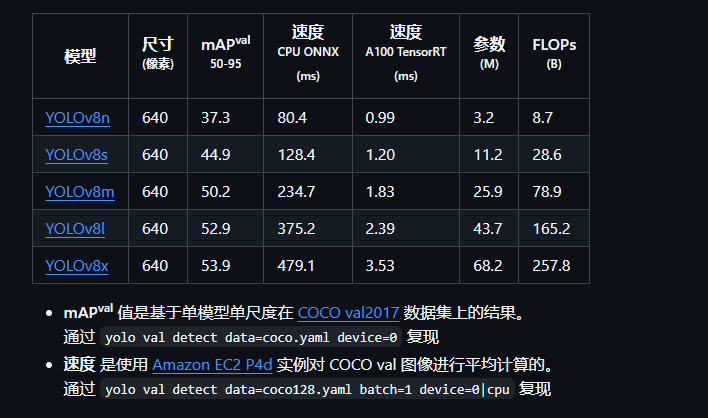
YOLOv8 系列包含 YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l、YOLOv8x 五种模型,它们基于同一架构,主要通过网络深度与宽度(通道数) 的差异来平衡检测精度、速度和计算成本,以适应不同场景的需求。

在本博客中,将简单介绍演示下如何使用YOLO、OpenCV和Python检测图像和视频流中的对象。
主要内容有:
简要讨论YOLO算法;
使用YOLO、OpenCV、Python进行图像检测;
使用YOLO、OpenCV、Python进行视频流检测;
讨论YOLO算法的优点和缺点;

深度学习的目标检测常用算法
在基于深度学习的目标检测领域,常用算法主要分为以下三类:
一、R-CNN 家族系列算法
该系列包括 R-CNN、Fast R-CNN 和 Faster R-CNN,是目标检测领域具有重要影响力的算法体系。
R-CNN:作为最早的基于深度学习的目标检测器之一,采用两级网络结构。其工作流程为:首先借助选择性搜索等算法生成可能包含目标的候选边界框,再将这些区域输入 CNN 进行分类。不过,该算法存在明显缺陷,不仅运行速度慢,而且并非完整的端到端目标检测器。
Fast R-CNN:对原始 R-CNN 进行了大幅改进,在提高检测准确度的同时,缩短了正向传递所需时间。但遗憾的是,该模型仍依赖外部区域搜索算法,未能实现真正的端到端检测。
Faster R-CNN:2015 年推出的 Faster R-CNN 成为真正的端到端深度学习目标检测器。它摒弃了对选择性搜索的依赖,核心在于引入了两个关键部分:一是完全卷积的区域提议网络(RPN),二是能预测对象边界框和 “对象” 分数(用于量化区域包含对象的可能性)的组件。RPN 的输出会被传递到 R-CNN 组件,以完成最终的分类和标记。
R-CNN 系列算法的检测结果通常具有较高的准确性,但该系列最大的问题是运行速度极慢,即便在 GPU 上,帧率也仅为 5 FPS。
二、单发检测器(SSD)
为提升基于深度学习的目标检测器的速度,单发检测器(SSD)采用单级检测器策略(one stage)。这类算法将对象检测视为回归问题,接收输入图像后,可同时学习边界框坐标和相应的类标签概率。与两级检测器相比,单级检测器虽然在准确性上往往稍逊一筹,但速度明显更快。
三、YOLO 算法
YOLO 同样属于单级检测器,是该类别中表现出色的算法。它采用与 SSD 类似的单级检测策略,将目标检测转化为回归问题,能够同时处理边界框预测和类别判断,在保证一定检测效果的前提下,拥有较快的运行速度。
总体而言,两级检测器(如 R-CNN 家族)在准确性上更具优势,而单级检测器(SSD 和 YOLO)则以速度见长,适用于对实时性要求较高的场景。
YOLO应用于图像对象检测
将YOLO应用于图像对象检测


YOLO算法并没有应用非最大值抑制,这里需要说明一下。应用非最大值抑制可以抑制明显重叠的边界框,只保留最自信的边界框,NMS还确保我们没有任何冗余或无关的边界框。
利用OpenCV内置的NMS DNN模块实现即可实现非最大值抑制 ,所需要的参数是边界框、 置信度、以及置信度阈值和NMS阈值。
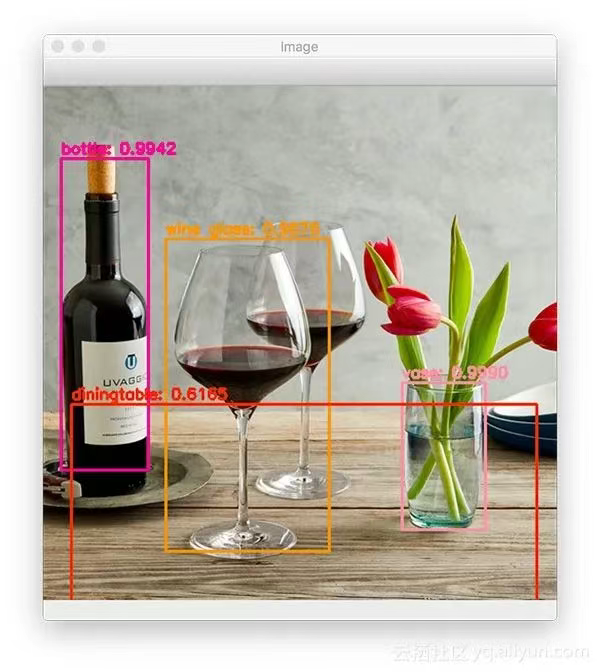
假设存在至少一个检测结果,就循环用非最大值抑制确定idx 。然后,我们使用随机类颜色在图像上绘制边界框和文本 。最后,显示结果图像,直到用户按下键盘上的任意键。
下面进入测试环节,打开一个终端并执行以下命令:
python demo.py --config-file configs/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.yaml --input desk.jpg --output out2.jpg --vocabulary custom --custom_vocabulary headphone,webcam,paper,coffe --confidence-threshold 0.3 --opts MODEL.WEIGHTS models/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.pth


YOLO应用于视频检测
那么在学会检测单张图像后,我们也可以利用YOLO算法实现视频流中的目标检测。



同样,首先从导入相关数据包和命令行参数开始。与之前不同的是,此脚本没有-- image参数,取而代之的是量个视频路径:
– input :输入视频文件的路径;
– output :输出视频文件的路径;
视频的输入可以是手机拍摄的短视频或者是网上搜索到的视频。另外,也可以通过将多张照片合成为一个短视频也可以。本博客使用的是在PyImageSearch上找到来自imutils的VideoStream类的 示例。
代码与处理图形时候相同:

YOLO目标检测器的限制
YOLO目标检测器的最大限制和缺点是:
它并不总能很好地处理小物体;
它尤其不适合处理密集的对象;
限制的原因是由于YOLO算法其本身:
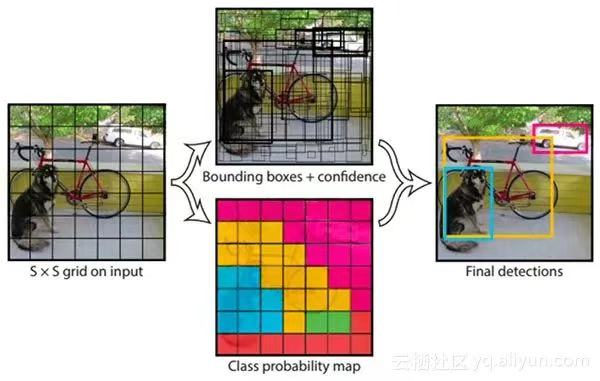
YOLO对象检测器将输入图像划分为SxS网格,其中网格中的每个单元格仅预测单个对象;
如果单个单元格中存在多个小对象,则YOLO将无法检测到它们,最终导致错过对象检测;
因此,如果你的数据集是由许多靠近在一起的小对象组成时,那么就不应该使用YOLO算法。就小物体而言,更快的R-CNN往往效果最好,但是其速度也最慢。在这里也可以使用SSD算法, SSD通常在速度和准确性方面也有很好的权衡。
值得注意的是,在本教程中,YOLO比SSD运行速度慢,大约慢一个数量级。因此,如果你正在使用预先训练的深度学习对象检测器供OpenCV使用,可能需要考虑使用SSD算法而不是YOLO算法。
因此,在针对给定问题选择对象检测器时,我倾向于使用以下准则:
如果知道需要检测的是小物体并且速度方面不作求,我倾向于使用faster R-CNN算法;
如果速度是最重要的,我倾向于使用YOLO算法;
如果需要一个平衡的表现,我倾向于使用SSD算法;
