Pytorch-07 如何快速把已经有的视觉模型权重扒拉过来为己所用
下载,保存,加载,使用模型权重
在这一节里面我们会过一遍对模型权重的常用操作,比如:
- 如何下载常用模型的预训练权重
- 如何下载常用模型的无训练权重(只下载网络结构)
- 如何加载模型权重
- 如何保存权重
- 加载模型权重后进行推理的注意事项
写在开头:权重是以什么形式存在的?
光用,是肯定够的,但是如果你能稍微懂一点原理,那么你很有可能在某一日突然融会贯通,做出非常牛逼的优化。
Pytorch模型会将学习到的参数存储在称为state_dict的内部状态字典中。为了深入探究,我们可以创建一个单线性层简单模型,然后看看它的状态字典长啥样:

import torch
import torch.nn as nn
import jsonclass SimpleLinearModel(nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(5, 2) # 五个输入,两个输出def forward(self, x):return self.linear(x)model = SimpleLinearModel()
model_state_dict = model.state_dict()
print(model_state_dict)
以上代码块的输出如下:

虽然它是个字典,但是由于张量的存在让他不是一个友好的键值对结构,而是元组结构,但是我们还是可以把他转换JSON来直观感受一下:
{"linear.weight": [[0.1941000074148178,0.22420001029968262,-0.3236999809741974,-0.1558000087738037,0.2337000072002411],[0.15130000114440918,0.11470000594854355,0.3953999876976013,-0.33970001339912415,-0.20650000870227814]],"linear.bias": [0.046799998730421066,-0.03530000150203705]
}
这下直观多了,可以看到,state_dict存储了两个学习的参数,其中包括了一个W2×5W_{2\times5}W2×5的全连接矩阵和一个长度为2的偏置向量bbb。
不过需要注意的是这是一个有序字典,这样才能保证数据在流经权重文件的时候才能一层一层的被处理。
下载并保存常用预训练模型权重
torchvision.models包内置了很多的不同任务模型权重,包括但不限于图像分类,语义分割,实例分割,关键点检测,视频分类,光流等等,你可以逛逛这个权重菜市场,这里我就不放图介绍了。
一般情况下,你可能要使用这些预训练的模型来进行 迁移学习, pytorch加载这些权重相当简单,一般的调用公式为:
model = model.模型名(weights='用什么数据集预训练的')
举个例子,我们加载一下vgg的在IMAGENET1K_V1上的权重,看看它结构如何
model = models.vgg16(weights='IMAGENET1K_V1')
print(model)
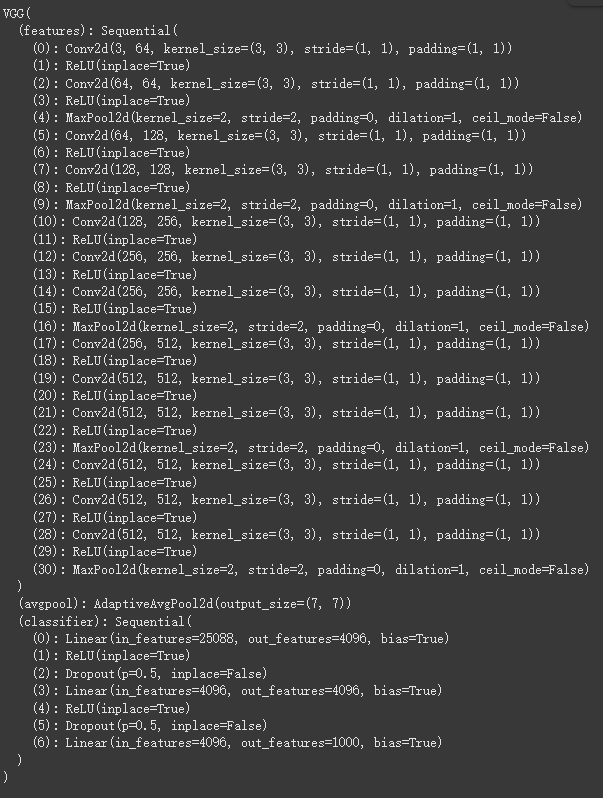
可以看到这个包含预训练权重的网络模型已经被我们保存到state_dict中了,但是它目前还只是在内存里面,没有写入外存(硬盘),如果你想把它保存到本地,你可以这样做:
torch.save(model.state_dict(), 'vgg1-_model_weights.pth')
这样就会把你当前的权重保存为一个.pth文件。
加载模型权重-仅加载权重
OK, 现在你已经有了一个vgg模型权重,那你要怎么把它加载到对应的网络上呢?
正常的步骤是这样的:
- 创建同一模型的实例 (不指定数据集的时候说明只要结构不要预训练权重)
- 使用
load_state_dict()方法加载参数
model = models.vgg16() # 这里没有指定数据集,说明只要结构
model.load_state_dict(torch.load('model_weights.pth', weights_only=True)) # 这里加载权重,该.pth文件只包含权重,不包含结构。
注意,如果你使用
torch.save(model.state_dict(), 'path'),只有权重会被保存!如果你想在保存权重的同时也保存模型结构,你可以这么做:torch.save(model, 'model.pth')这个做法的优点是可以在加载被这样保存的权重的时候无需初始化对应的网络:
model = torch.load('model.pth', weights_only=False) # 说明这个model.pth并不是只保存了权重,还有模型架构,所以不需要先实例化再加载权重
但是,模型和权重一起加载并不是pytorch官方推荐的最佳实践! pytorch官方推荐的方式还是只保存模型权重,要加载的时候先实例化网络再加载权重(后一段就是讲这个的)。这是因为.pth文件的解析基于pickle协议实现,而pickle文件不仅仅是数据存储,它还可以包含可执行代码。当 torch.load() 反序列化一个 pickle 文件时,它会执行文件中的字节码来重新创建对象。
这代表:如果一个 .pth 文件是恶意创建的,它可能包含恶意代码。当你在不知情的情况下加载这个文件时,这些恶意代码会被执行,从而导致你的系统受到攻击,例如被植入病毒、窃取数据等。weights_only=True 的作用就是切断这个风险链。它告诉 PyTorch:“我只信任文件中的张量数据。不要执行任何其他的 Python 对象代码,即使它们存在于文件中。”这样就有效地防止了潜在的恶意代码被执行。
使用预训练权重进行推理
这里要说的不多,用预训练权重加载好模型之后记得打开.eval评估模式再开始推理:
model.eval()
.eval() 方法的作用是将模型切换到评估(evaluation)模式。这个模式会关闭一些在训练时才需要的特殊层,以确保模型在推理时能够产生一致且可预测的结果。
具体来说,他会关闭这两个层的以下作用:
.eval() 是 PyTorch 模型推理时一个非常重要的步骤,你提到的这一点非常关键。
为什么需要在推理前调用 model.eval()?
.eval() 方法的作用是将模型切换到评估(evaluation)模式。这个模式会关闭一些在训练时才需要的特殊层,以确保模型在推理时能够产生一致且可预测的结果。
具体来说,.eval() 主要影响以下两种类型的层:
-
Dropout层- 训练模式 (
model.train()):Dropout层会以一定的概率随机“丢弃”一些神经元的输出,以防止模型过拟合。这意味着每次前向传播(forward pass)时,网络结构都是不一样的。 - 评估模式 (
model.eval()):Dropout层会被关闭。所有神经元都参与计算,不再随机丢弃。这确保了在推理时,每次对同一输入进行预测,都会得到完全相同的结果。
- 训练模式 (
-
BatchNorm(批量归一化)层- 训练模式 (
model.train()):BatchNorm层会根据当前批次(batch)的输入数据来计算均值和方差,并用这些统计量进行归一化。 - 评估模式 (
model.eval()):BatchNorm层会停止更新均值和方差。它会使用在训练阶段已经学到的、全局的、固定的均值和方差来进行归一化。这同样是为了确保推理结果的稳定性,因为在推理时,我们通常只处理单个样本或小批量的样本,它们的统计量没有代表性。
- 训练模式 (
如果没有调用 model.eval(),模型将保持在训练模式。这将导致:
- 结果不稳定:因为
Dropout层会随机丢弃神经元,即使输入相同,每次推理的结果也可能不同。 - 结果不准确:
BatchNorm层会使用不稳定的批次统计量进行归一化,而不是使用训练时学到的稳定统计量,这会导致推理结果的准确性下降。
所以,为了得到稳定、准确且可复现的推理结果,在使用预训练模型进行预测时,必须在推理循环之前调用 model.eval()。