MySQL数据库索引及底层数据结构
MySQL默认使用的索引底层数据结构是B+树,默认存储引擎是InnoDB引擎。
这是MySQL文档,有需要的自己浏览。
https://dev.mysql.com/doc/refman/8.0/en/
接下来我们步入今天的正题:
1. 什么是索引
- 索引(index)是帮助MySQL高效获取数据的数据结构(有序)。可以快速定位数据位置而不必扫描整个表。
- 在数据之外,数据库系统还维护着满足特定査找算法的数据结构(B+树),这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法这种数据结构就是索引。
索引的优缺点:
优点
-
提高查询速度:索引可以大大加快数据检索速度,特别是对于大型表
-
加速排序和分组操作:ORDER BY和GROUP BY操作在有索引时会更快
-
优化连接操作:表连接时如果有适当的索引会显著提高性能
-
保证数据唯一性:唯一索引可以确保列中数据的唯一性
-
减少服务器扫描的数据量:MySQL可以使用索引直接定位到所需数据,而不必扫描整个表
缺点
-
占用额外存储空间:索引需要额外的磁盘空间
-
降低写入性能:
-
INSERT操作需要同时更新索引
-
UPDATE操作如果修改了索引列需要更新索引
-
DELETE操作也需要更新索引
-
-
维护成本:索引需要定期维护,特别是在数据频繁变更的情况下
-
优化器可能不使用索引:在某些情况下,MySQL优化器可能决定不使用索引
-
索引选择过多可能导致性能下降:过多的索引会增加优化器选择执行计划的时间
索引的数据类型:
MySQL支持多种索引类型,每种类型适用于不同的场景和需求。
1. 普通索引 (INDEX / KEY)
-
最基本的索引类型,没有特殊限制
-
语法:
CREATE INDEX index_name ON table_name(column_name) -
适用于大多数查询场景
2. 唯一索引 (UNIQUE INDEX)
-
确保索引列的值唯一,但允许NULL值
-
语法:
CREATE UNIQUE INDEX index_name ON table_name(column_name) -
常用于主键或需要唯一约束的列
3. 主键索引 (PRIMARY KEY)
-
特殊的唯一索引,不允许NULL值
-
每个表只能有一个主键
-
语法:
ALTER TABLE table_name ADD PRIMARY KEY (column_name)
4. 全文索引 (FULLTEXT INDEX)
-
专门用于全文搜索,仅适用于MyISAM和InnoDB(MySQL 5.6+)引擎
-
语法:
CREATE FULLTEXT INDEX index_name ON table_name(column_name) -
支持MATCH AGAINST操作
5. 组合索引 (复合索引)
-
在多个列上创建的索引
-
语法:
CREATE INDEX index_name ON table_name(col1, col2, col3) -
遵循最左前缀原则
6. 空间索引 (SPATIAL INDEX)
-
用于地理空间数据类型(GEOMETRY, POINT, LINESTRING, POLYGON等)
-
仅MyISAM表支持
-
语法:
CREATE SPATIAL INDEX index_name ON table_name(column_name)
7. 前缀索引
-
对列值的前N个字符建立索引
-
语法:
CREATE INDEX index_name ON table_name(column_name(N)) -
适用于长字符串列
8. 哈希索引
-
Memory存储引擎默认使用哈希索引
-
InnoDB有自适应哈希索引功能(自动管理)
-
仅支持等值查询(=, IN),不支持范围查询
9. 覆盖索引
-
不是一种单独的索引类型,而是一种使用方式
-
当查询的所有列都包含在索引中时,MySQL可以直接从索引获取数据而无需回表
注意一点:聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)虽然也称之为索引,但和这些分类有很大的区别。
核心原因还是因为:分类维度不同
MySQL官方按功能分类(开发者视角)
这些主键索引、唯一索引、普通索引、全文索引等,主要关注索引的逻辑功能和约束条件聚簇/非聚簇是存储实现分类(引擎内部视角)
描述数据与索引的物理存储关系,属于底层实现机制而非用户可配置选项。未单独列为类型的其他原因:
引擎相关性:
是否聚簇取决于存储引擎实现,比如:InnoDB有聚簇索引,MyISAM则没有。用户不可选择性:
开发者不能直接选择创建聚簇/非聚簇索引,而是由主键定义和引擎特性自动决定。透明性考虑:
对大多数应用开发是底层实现细节,功能分类对开发者更实用。历史兼容性:
不同引擎行为差异大,统一分类会引发混淆。
2. 索引的底层数据结构
MySQL索引使用多种数据结构实现,不同的存储引擎采用不同的索引结构来优化查询性能。
常用的数据结构有:
B树(B-Tree)
B+树(B+Tree)(InnoDB实际采用)
Hash
R-Tree(空间索引)
MySQL主要就是使用B+树。
在了解B树和B+树之前,我们先来了解一下二叉树:
二叉树(二叉搜索树)
二叉搜索树(Binary Search Tree, BST)是一种特殊的二叉树:
左子树所有节点值 < 根节点值
右子树所有节点值 > 根节点值
左右子树也分别是BST
优点:
逻辑简单:易于理解和实现
有序性:中序遍历可得有序序列
二分查找:理想情况下查询效率高
缺点:
不平衡风险:可能退化成链表(复杂度→O(n))
不适合磁盘存储:节点随机分布导致大量磁盘I/O
下面就是最坏情况下的二叉树,直接演化为了一个链表形式。

B树(B-Tree)
B-Tree,B树是一种自平衡的树数据结构,相对于二叉树,B树每个节点可以有多个分支,即多叉。它保持数据有序,并允许进行高效的搜索、顺序访问、插入和删除操作。
以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key
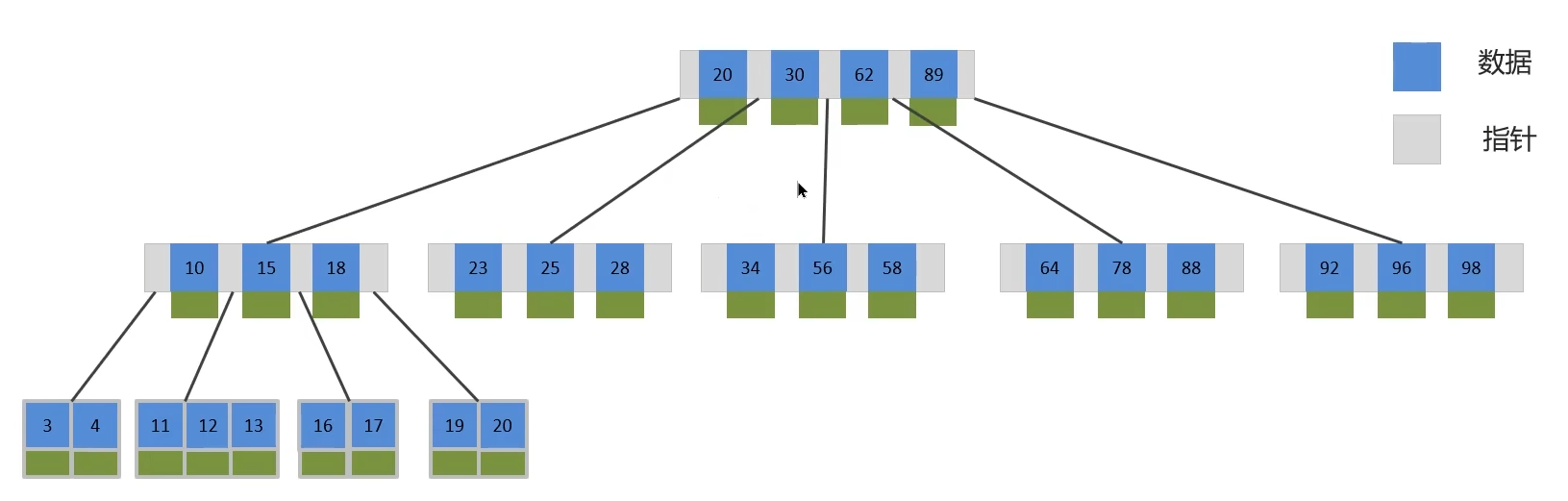
B树的主要特性:
-
多路平衡搜索树:每个节点可以有多个子节点。
-
自平衡:树始终保持平衡状态。
-
有序存储:节点中的键(key)按顺序排列。
-
适合外存:设计用于减少磁盘访问次数。
B+树(B+Tree)
B+Tree是在BTree基础上的一种优化,具有比B树更适合外部存储的特性,InnoDB存储引擎就是用B+Tree实现其索引结构。
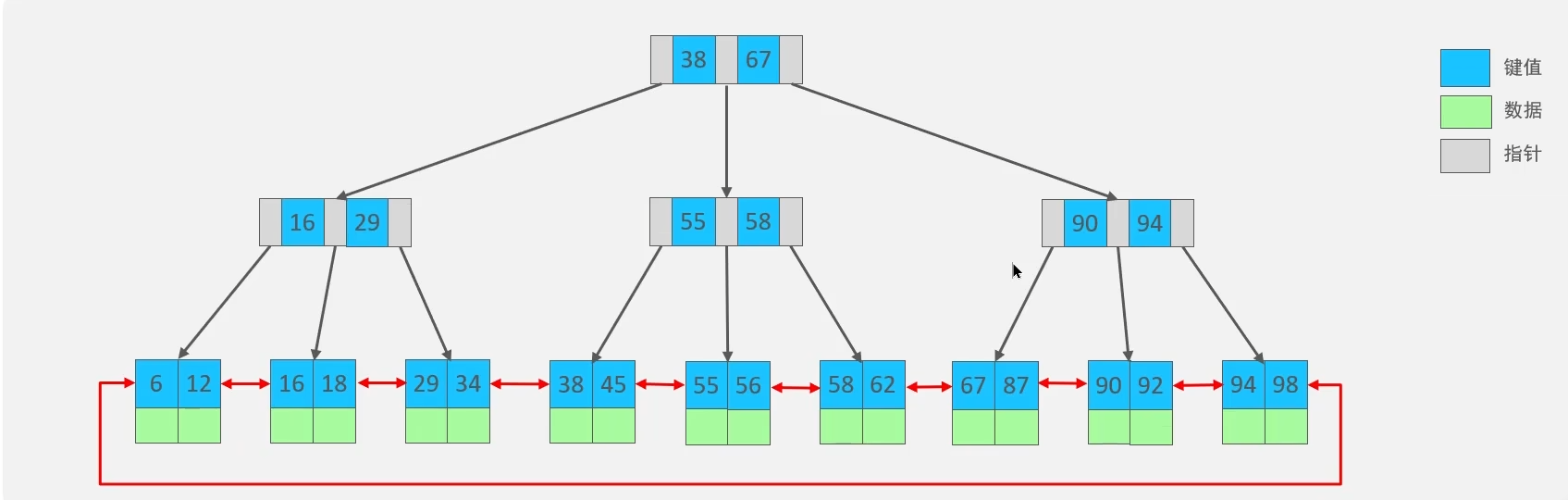
B+树的主要特点:
-
多路平衡:每个节点可以有多个子节点,保持树的平衡
-
分层存储:数据只存储在叶子节点,内部节点只存储键值(索引)
-
顺序访问:所有叶子节点通过指针连接成一个有序链表
B+树与B树的比较
| 特性 | B树 | B+树 |
|---|---|---|
| 数据存储 | 所有节点都可存储数据 | 仅叶子节点存储数据 |
| 查找性能 | 可能提前终止(非叶子节点找到) | 必须到达叶子节点 |
| 范围查询 | 需要中序遍历 | 通过叶子链表高效扫描 |
| 空间利用率 | 内部节点存储数据占用更多空间 | 内部节点更紧凑 |
| 稳定性 | 查询路径长度不一致 | 所有查询路径长度相同 |
| 实现复杂度 | 相对简单 | 相对复杂(需维护叶子链表) |
总的来说,由于B+树独特的数据存储方式:
- B+树的磁盘读写代价更低。
- B+树的查询效率更加稳定。
- B+树更便于扫库和区间查询。
3.总结
3.1 什么是索引?
- 索引(index)是帮助MySQL高效获取数据的数据结构(有序)。
- 提高数据检索的效率,降低数据库的IO成本(不需要全表扫描)。
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
3.2 索引的底层数据结构?
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
- 阶数更多,路径更短。
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据。
- B+树便于扫库和区间查询,叶子节点是一个双向链表。
3.3 为什么 B+Tree 是主流?
磁盘友好:减少 I/O 次数(矮胖的树形结构)。
范围查询高效:叶子节点链表避免回溯。
缓存利用率高:非叶子节点仅存键值,可缓存更多索引。