Enhancing Long Video Question Answering with Scene-Localized Frame Grouping
Enhancing Long Video Question Answering with Scene-Localized Frame Grouping
Authors: Xuyi Yang, Wenhao Zhang, Hongbo Jin, Lin Liu, Hongbo Xu, Yongwei Nie, Fei Yu, Fei Ma
Deep-Dive Summary:
1 引言
多模态大型语言模型(MLLMs)(Liu 等人 2023;Cheng 等人 2024;OpenAI 2024;Liu 等人 2024)在理解复杂视觉输入(如视频)方面展现了强大的能力,其中视频问答(VideoQA)(Dai 等人 2025;Chang 等人 2024)作为一种关键的评估方法。尽管像 LLaVA-Video(Li 等人 2024a;Zhang 等人 2024b)和 InternVL(Chen 等人 2024b)等模型取得了进展,但有效处理长视频仍然是一个核心挑战。当前的研究和基准测试(Wu 等人 2024;Zhou 等人 2024;Wang 等人 2024b)往往通过从大量无关帧中识别包含核心对象的特定帧来加剧这一问题。我们认为,这种评估范式与现实世界的应用需求不符,后者要求在更广泛的场景中感知细节和事件。这突显了一个关键差距:现有的视频问答任务过于简化问题,忽视了真正的场景级理解。

为了开发更通用和高效的解决方案,我们重新思考了人类处理长视频的方式。人类通常不是逐帧分析视频,而是快速浏览,同时对场景转换保持敏感(Wang 等人 2023)。一旦检测到相关场景,他们会专注于检查该特定片段的细节。受这一认知过程的启发,我们认为要让模型真正理解长视频,分析的基本单位应从单个帧转向语义连贯的场景。
基于这一理念,我们引入了一个新任务——SceneQA,这是一个场景定位的长视频问答任务。SceneQA 旨在评估模型在长视频中准确识别并聚焦于与给定问题相关的关键场景的能力,从而对模型在场景级感知细节的能力提出更高要求。
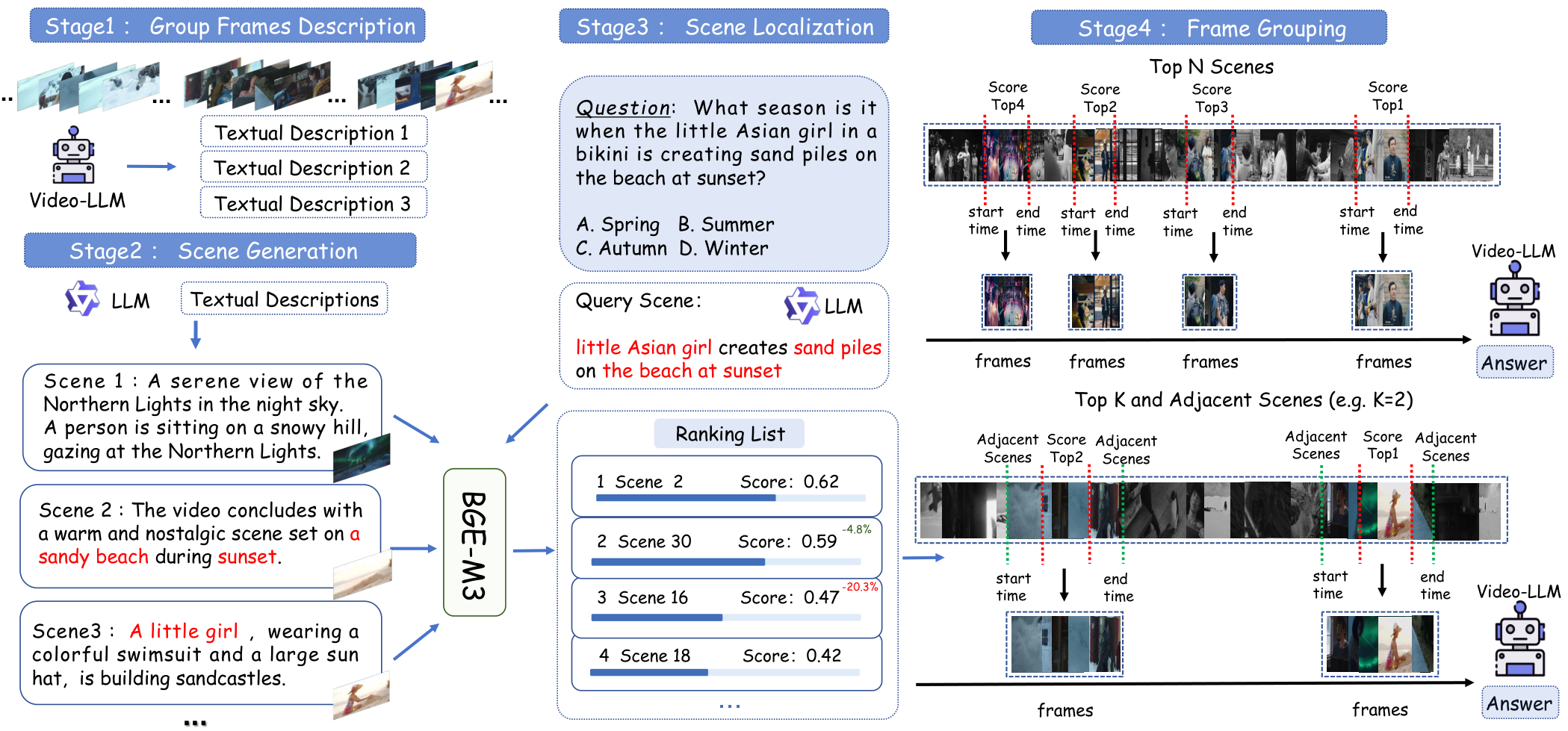
为了有效应对 SceneQA 带来的挑战,我们进一步提出了 SLFG(场景定位帧分组)方法,旨在通过场景定位过滤帧,在更高的语义层面减少帧冗余。首先,通过对视频进行密集采样并将连续帧聚合成固定粒度的帧组,我们使用大型语言模型生成场景级的语义表示,有效压缩输入同时保留关键视觉信息。接下来,我们从问题中提取场景描述,并计算其与每个帧组的场景描述的语义相似度,实现问题与相关内容的精确对齐。最后,我们引入了一个动态帧组重组模块,根据相似度分数调整帧组结构,合并高相关性组,丢弃低相关性组,并扩展关键片段的时间窗口,以在有限上下文中提升信息密度和推理效果。整体方法无需修改原始模型架构,具有出色的即插即用兼容性和通用性,适用于增强现有 MLLMs 在长视频理解任务中的性能。
为了支持 SceneQA 的研究和评估,我们开发了一个数据集:LVSQA(长视频场景级问答数据集)。我们从 LVBench(Wang 等人 2024b)中精心挑选了 100 个长视频(每个超过 30 分钟),过滤掉严重依赖字幕的视频,并由人类专家从纯视觉角度重新设计和扩展任务。我们通过结合 MLLM 辅助生成与大量人工优化的协作流程,构建了 500 个高质量的问答对。这些问答对聚焦于详细的视觉理解,为评估模型在长视频中的场景级定位和细粒度视觉推理提供了一个具有挑战性和针对性的测试平台。
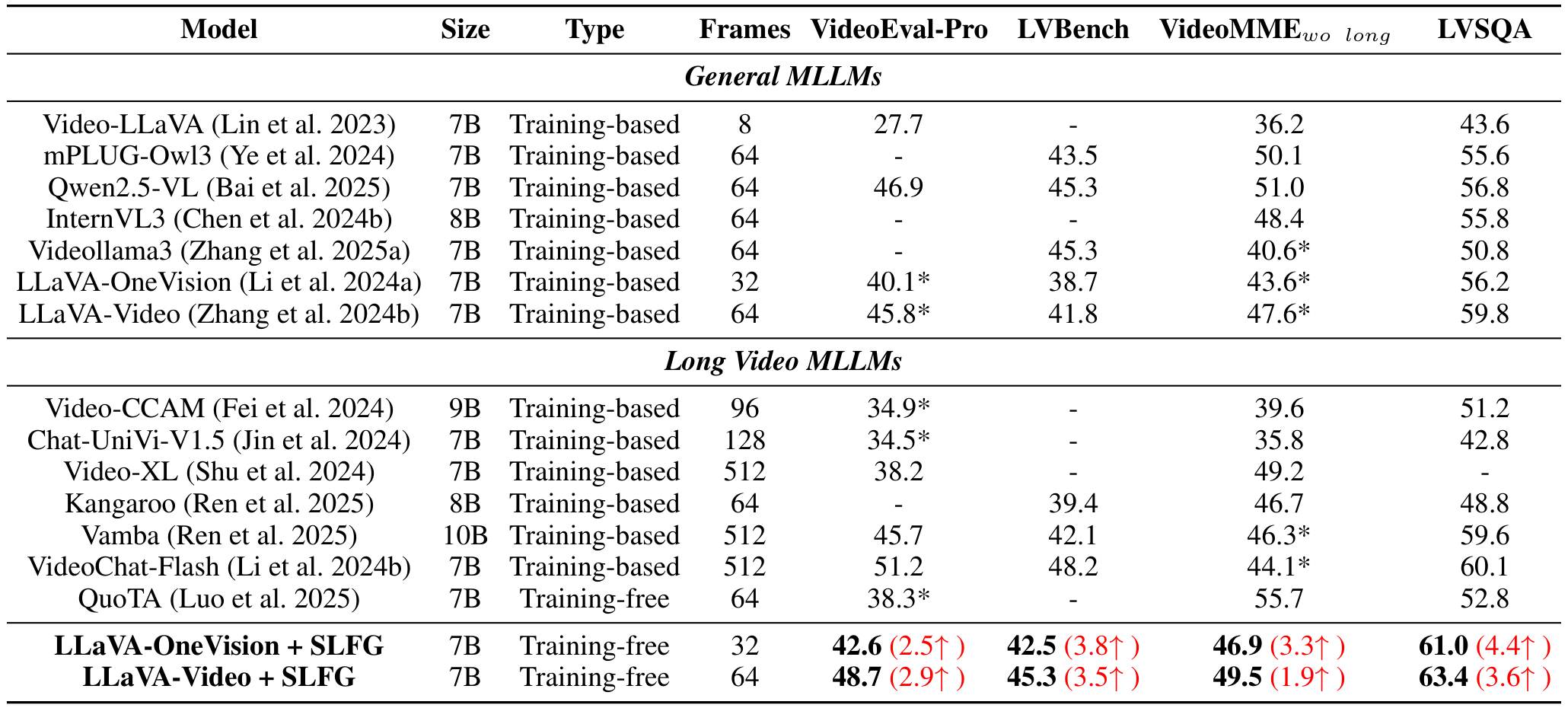
由于我们的方法具有可插拔性,我们选择了 LLaVA-OneVision(Li 等人 2024a)和 LLaVA-Video(Zhang 等人 2024b)作为基础模型。应用我们的方法后,两个模型在各种评估集上均取得了显著的准确率提升。具体而言,在 VideoMME w/o long(Fu 等人 2024)上,我们的方法将 LLaVA-OneVision 的性能从 43.6% 提升至 46.9%,将 LLaVA-Video 的性能从 47.6% 提升至 49.5%。在 LVBench 上,LLaVA-OneVision 与 SLFG 结合后相对提升了 9.8%,LLaVA-Video 与 SLFG 结合后相对提升了 8.4%。同时,我们还在 LVSQA 上评估了主流 MLLMs,加入我们的方法后也取得了显著改进。我们认为,实验结果表明,一个精心设计的任务可以更好地评估 MLLM 捕捉长视频中详细视觉信息的能力,为未来在长视频理解领域探索各种策略奠定了基础。
我们的贡献可以总结如下:
- 我们提出了一个新的长视频问答任务——SceneQA,强调场景定位的视频理解,并构建了一个专用基准数据集 LVSQA 以支持该任务,推动长视频理解研究。
- 我们提出了 SLFG(场景定位帧分组),通过分组聚合帧,并在更高层次的场景语义空间中理解长视频中的关键信息。
- 在主流长视频基准测试上的实验表明,我们的方法可以显著增强现有 MLLMs 感知长视频细节的能力。
2 相关工作
2.1 长视频理解
与短视频相比,理解长视频带来了更大的挑战,需要在较长时间内处理大量信息。一些现有方法主要通过压缩视觉令牌和增强外部模块来解决这一挑战。例如,Video-XL(Shu 等人,2024)引入了视觉摘要令牌和动态压缩策略,以提高长视频理解的效率。MovieChat(Song 等人,2024)和 MA-LMM(He 等人,2024)集成了具有长期记忆库的记忆模块,以实现对长视频的准确预测;Video-RAG(Luo 等人,2024)则利用 ASR 等工具增强外部信息。在这其中,基于训练的方法如 VideoChat-Flash(Li 等人,2024b)和 SEAL(Wang 等人,2024a)在这一领域取得了进展。在无训练方法中,探索高效的帧选择成为一个新的研究领域。Tang(Tang 等人,2025)提出了自适应关键帧采样(AKS)算法;Video-Tree(Wang 等人,2024c)设计了一种策略,自适应地从输入视频中提取与查询相关的关键帧。Zhang 等人提出了 Q-Frame(Zhang 等人,2025b)框架,用于查询感知的帧选择和多分辨率适应。然而,这些方法往往专注于定位与查询直接相关的短片段,忽视了对语义连贯场景进行综合推理的需求。
2.2 长视频基准
随着对评估多模态大语言模型(MLLMs)长视频理解能力的需求增加,出现了几个包含较长视频的基准数据集。Long VideoBench(Wu 等人,2024)、LVBench(Wang 等人,2024b)、MLVU(Zhou 等人,2024)、VideoEval-Pro(Ma 等人,2025)、MovieChat(Song 等人,2024)、MoVQA(Tapaswi 等人,2016)和 Video-MME(Fu 等人,2024)开始使用较长的视频来测试模型。此外,研究正转向更详细的评估。例如,大海捞针任务(Needle-in-a-Haystack,Ye 等人,2025)测试对特定项目的精确识别,而像 NExT-QA(Xiao 等人,2024)这样的接地问答任务则要求将答案定位到视频的特定区域。这些发展表明了对细节导向和基于证据的理解的日益关注。
其中,VideoEval-Pro 提供了一个广泛的分类体系,包括 4 个主要类型和 15 个子类型。Video-MME 包含 900 个带有字幕和音频的视频,但其平均视频长度(约 1018 秒)仍然有限。LVBench 提供了更长且更多样化的视频(平均约 4101 秒),更好地反映了长视频场景。然而,在当前的几个长视频基准测试中,部分视频的任务设计过于笼统或依赖于叙述,缺乏必要的细节。这使得它们不太适合视频细节分析任务。相比之下,我们的 LVSQA 数据集专为 SceneQA 设计,专注于长视频中的场景级细节理解,为 MLLMs 提供了更有效的评估平台。
3.1 框架概述
在本文中,我们提出了一种针对长视频问答任务的有效方法,该方法包含四个阶段。我们提出的框架概述如图2所示。
在第3.2节中,我们将详细介绍“组帧描述”,阐述如何对帧进行采样和分组,以及如何使用多模态大语言模型(MLLMs)从这些帧组中提取细粒度的视觉描述。在第3.3节中,我们将介绍“场景生成”,解释大语言模型(LLM)如何从详细的视觉描述中抽象出场景级表示。在第3.4节中,我们将介绍“场景定位”,详细说明计算视频场景描述与问题场景之间语义相似度的方法。在第3.5节中,我们将介绍“组帧重组”,重点说明如何基于相似度分数重新排列和调整帧组,以进行最终的推理过程。
3.2 组帧描述
基于全面视觉信息的重要性,我们首先通过执行密集帧采样来确保从视频中一致且系统地提取帧。采样率由固定的时间间隔 $ \Delta t $ 定义,因此第 $ i $ 个采样帧表示为:
fi=F(t0+i⋅Δt),i=0,1,2,...f_{i}=F(t_{0}+i\cdot\Delta t),\;\;\;\;\;i\ =0,1,2,..\ . fi=F(t0+i⋅Δt),i =0,1,2,.. .
其中 $ F(t) $ 表示时间 $ t $ 处的视频帧,$ t_0 $ 是初始时间戳。
然后,我们引入分组粒度 $ N $。每组连续采样的 $ N $ 个帧组成一个帧组:
Gk={fk,fk+1,…,fk+N−1},k=0,1,2,⋅⋅⋅G_{k}=\{f_{k},f_{k+1},\ldots,f_{k+N-1}\},\quad k=0,1,2,\cdot\cdot\cdot Gk={fk,fk+1,…,fk+N−1},k=0,1,2,⋅⋅⋅
这种分组策略有助于视频帧的结构化组织,从而辅助下游处理任务,如语义分析。
对于每个帧组 $ G_k $,我们使用多模态大语言模型(MLLMs),表示为 $ M $,从视觉数据中提取丰富的语义内容。这一过程表示为:
Dk=N(Gk)={objecti,actionj,relationij,…},D_{k}=\mathcal{N}(G_{k})=\left\{\mathrm{object}_{i},\mathrm{action}_{j},\mathrm{relation}_{i j},\ldots\right\}, Dk=N(Gk)={objecti,actionj,relationij,…},
其中 $ D $ 表示描述性输出(以文本形式),传达从帧组 $ G_k $ 中提取的关键信息。描述包括帧组中观察到的对象、动作和空间关系的详细信息。
通过这种方式,MLLMs 处理帧组 $ G_k $,生成捕捉基本视觉元素的文本描述,从而进行更深入的分析并生成场景级表示。
3.3 场景生成
在这一部分中,我们使用了一个大型语言模型(LLM,在我们的实验中为 Qwen2.5-7B-Instruct)来从前一步生成的详细视觉描述中提取场景级别的表示。尽管每个帧组可能包含多个场景,但 LLM 能够有效地聚合描述中的信息。它识别并提取关键场景,将详细的描述提炼成更简洁且信息丰富的场景级别摘要。
场景生成的过程可以形式化如下。给定所有帧组 sGksG_ksGk 的描述输出集合 D={D1,D2,…,Dk}D = \{D_1, D_2, \dots, D_k\}D={D1,D2,…,Dk},LLM 将这些描述聚合并浓缩成多个场景级别的表示。具体来说,LLM 从描述中识别并提取第 mmm 个场景表示:
Sm=L(D1,D2,⋅⋅⋅,Dk),m=1,2,⋅⋅⋅,M,S_{m}={\mathcal{L}}(D_{1},D_{2},\cdot\cdot\cdot,D_{k}),\quad m=1,2,\cdot\cdot\cdot,M, Sm=L(D1,D2,⋅⋅⋅,Dk),m=1,2,⋅⋅⋅,M,
其中 SmS_mSm 表示第 mmm 个场景级别表示,L\mathcal{L}L 是 LLM 函数,用于聚合和抽象帧组的描述输出 DDD。函数 L\mathcal{L}L 能够在描述集合中识别多个场景,每个 SmS_mSm 捕获一个独特的场景级别表示。场景级别表示 SmS_mSm 更加简洁且信息丰富,包含了用于更高层次任务所必需的基本信息。
生成场景级别表示的动机在于减少低级别描述中的噪声和冗余。虽然 DkD_kDk 捕获了细粒度的内容,但可能包含重叠或无关的细节。LLM 将这些内容聚合为简洁的摘要,更好地反映整体语义结构。这些场景级别摘要 SmS_mSm 对于在后续步骤中将视频内容与问题意图联系起来至关重要。因此,该过程遵循以下结构化映射:
figrouping⟶∥ΩGk⟶Dk⟶ZSm.f_{i}\qquad{\underset{\Vert\Omega}{\operatorname{grouping}_{\longrightarrow}}}\qquad G_{k}\qquad{\underset{}{\longrightarrow}}\qquad{\mathcal{D}}_{k}\qquad{\overset{\mathbb{Z}}{\longrightarrow}}\qquad S_{m}. fi∥Ωgrouping⟶Gk⟶Dk⟶ZSm.
每一步都导致更抽象的表示,最终这些场景级别表示作为后续处理的关键基础,有助于在视频中精确定位特定场景信息。
3.4 场景定位 (Scene Localization)
通过上述步骤,我们已经获得了多组对应的场景描述。接下来,我们希望找到与问题最相关的场景,在该组场景中更有可能获得正确答案。在我们的工作中,可以使用一个开源的文本嵌入模型(BGE-M3,Chen 等人,2024a)来计算每个视频场景描述与问题场景之间的语义相似度。具体来说,我们将视频场景描述和问题场景描述编码为密集嵌入向量,并通过计算余弦相似度来衡量语义相似度。
KaTeX parse error: Expected 'EOF', got '\right' at position 221: …omega}}}\right)\̲r̲i̲g̲h̲t̲)\mathrm{,}
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: …t\frac{\bigg.}
在这里,B 表示查询场景描述,A 表示组内的场景描述。我们从每组中选取最高分数作为该组的分数,用于排序。
3.5 组帧重组 (Group Frames Reorganization)
在获得每组的分数后,所有组按降序排列。排序结果反映了每个场景的重要性,分数越高表示该组包含与回答问题相关片段的可能性越大。下一步是将排名靠前的组的场景帧重新组合,作为推理模块的输入。
随后,我们应用了一个阈值(在我们的实验中为 10%)。如果连续两组之间的分数差异小于该阈值,则认为这两组都可能是潜在的答案片段,并将其合并。如果分数差异超过阈值,则当前组及所有排名较低的组将被丢弃。
接下来,我们确保总帧数不超过模型的最大上下文窗口大小。如果所选组的总帧数小于限制,则剩余帧将平均分配到所选组中,以扩展其上下文。假设所选场景组的数量为 N,每组的帧数为 F,目标最大帧数为 T,剩余帧预算为 R,则分配给每组的额外帧数为:
ΔFi=∣RN∣foralli∈[1,N].\Delta F_{i}=\left|\frac{R}{N}\right|\mathrm{\quad~for\,all\,}i\in[1,N]. ΔFi=NR foralli∈[1,N].
如果 R 除以 N 的余数不等于 0,则剩余帧将根据每组的时间跨度进行分配。假设采样间隔为 △t,每组的时间窗口为 [t, t + F△t],则额外帧将在该时间范围之前和之后相应地进行采样。
最后,所有扩展的场景帧被输入到模型中进行推理,以产生最终答案:
Output=N(G1+Δf,G2+Δf,…,Gk+Δf)\mathrm{Output}=\mathcal{N}\left(G_{1}+\Delta f,\ G_{2}+\Delta f,\ldots,\ G_{k}+\Delta f\right) Output=N(G1+Δf, G2+Δf,…, Gk+Δf)
其中,若未应用组帧重组策略,则 △f = 0。
4 数据集 (Dataset)
4.1 SceneQA 任务
SceneQA 是一种新提出的任务,旨在弥补当前视频问答(VideoQA)任务在评估模型理解长视频中特定场景能力方面的不足。尽管视频问答领域近期取得了进展,但现有任务设计仍无法有效评估模型对长视频中特定场景的理解能力。为此,我们提出了 SceneQA 任务,专注于场景定位的理解。在 SceneQA 中,被评估的模型需要分析特定的场景片段,并基于详细的视觉线索(如角色动作、对象互动或场景转换)回答问题。这种设置在上下文感知和细粒度感知之间取得了平衡,使得视频理解的评估更加精准。SceneQA 模拟了人类观看长视频的方式:我们关注关键场景并提取有意义的细节。该任务遵循三步流程——场景定位、详细感知和问题回答,为推动多模态长视频理解提供了一个新的框架。

SceneQA 与传统 VideoQA 的对比:传统 VideoQA 任务通常基于短片段或孤立的片段,问题往往可以通过有限的上下文回答。在许多情况下,模型甚至可能依赖字幕或文本线索来推断答案,而非真正理解视觉内容。这种设置虽然简化了推理,但无法评估模型是否能理解较长叙事的时间和语义结构。相比之下,SceneQA 要求模型首先识别特定场景,然后对场景内的细粒度视觉细节进行推理。
SceneQA 与大海捞针任务(Needle-in-a-Haystack Task)的对比:两者都需要在长视频中定位相关片段,但大海捞针任务聚焦于短促、孤立的事件并要求精确定位。而 SceneQA 针对的是语义连贯的场景,要求在场景内对细粒度细节进行综合推理。
SceneQA 与接地问答(Grounded QA)的对比:接地问答(如 NExT-GQA (Xiao et al. 2024))将答案与支持的时间片段相关联,但 SceneQA 以整个场景为理解单位。它要求在长视频中区分场景边界,并综合场景范围内的信息进行推理,超越了接地问答对答案与片段一致性的关注。
4.2 LVSQA 数据集
为了支持 SceneQA 的研究,我们构建了 LVSQA(长视频场景级问答)数据集,该数据集专门设计用于评估长视频中局部场景内的细粒度视觉理解能力。
核心问题类型
我们在 LVSQA 中将核心问题类型分为两大类:
- 基于场景的细节识别:这类问题聚焦于特定场景内的细粒度视觉细节,例如角色行为、对象状态、短期视觉变化或微妙互动。解决这些问题需要模型在帧或子片段级别准确识别和解释局部视觉线索。这类任务测试模型在受限时间窗口内的精确感知能力。
- 基于场景的因果推理:在细节识别的基础上,这类问题要求模型在同一场景内推断因果关系——理解特定行为的原因或特定事件导致的后果。例如,模型可能需要推断角色行为背后的动机,或识别场景内互动的结果。与细节识别相比,因果推理任务更强调动态事件结构的建模,并要求更深入的场景级推理。
这两类问题共同定义了 LVSQA 的核心挑战:模型不仅需要高质量地感知局部视觉信息,还必须在受限的上下文范围内进行有意义的推理。
构建流程
LVSQA 的构建遵循严格的多阶段流程,结合自动化生成和大规模人工精炼,以确保生成的问答对的质量、有效性和任务一致性。
我们的数据集构建遵循细致的五阶段流程:
- 视频分割:我们首先从 LVBench 数据集中选择 100 个超过 30 分钟的长视频,然后将它们均匀分割成片段,并手动过滤掉损坏或不相关的内容。
- 视觉描述生成:对于每个保留的片段,我们应用多模态大语言模型(MLLM)生成细粒度的视觉描述,捕捉对象、动作、属性和空间关系,提供丰富的语义基础。
- 问答生成:基于这些描述,我们提示语言模型生成针对场景定位的特定视觉细节的初始问答对(QA v1)。
- 多轮人工精炼:QA v1 随后经历多轮双盲人工精炼过程,耗时超过 200 小时,以提高清晰度、逻辑一致性和确保问答对严格基于视觉内容,最终生成更高质量的 QA v2 集合。
- 专家过滤:在最后阶段,领域专家对每个 QA v2 对与其视频片段进行严格的交叉验证,这一最终审查耗时超过 300 小时,确保每个问题完全可回答、连贯且无歧义,最终筛选出 500 个高质量的 SceneQA 风格问答对,构成最终的 LVSQA 数据集。
5 实验评估
5.1 实验设置与细节
为了评估我们提出的SLFG方法的有效性,我们在多个长视频理解基准数据集上进行了实验,包括VideoEval-Pro、LVBench等,测试了多模态理解、视频问答以及细粒度时间推理等能力。我们还在我们的LVSQA任务上评估了主流的多模态大语言模型(MLLMs)。
SLFG被实现为一个模块化组件,与多种开源MLLMs兼容。我们选择了LLaVA-OneVision和LLaVA-Video作为基础模型。实验设置与原始实验(Li et al. 2024a)保持一致。
我们首先以10秒为间隔进行密集采样。分组的粒度设置为N=16。对于每个组,使用MLLM生成详细的视觉描述,然后通过Qwen2.5-7B-Instruct(Yang et al. 2024)将这些描述抽象为场景表示。重组策略采用10%的阈值。
为了确保与我们方法的公平比较,我们没有采用lmms-eval(Zhang et al. 2024a)框架。相反,我们直接基于提供的推理代码实现了评估脚本,这可能导致结果的可重复性略低。
所有实验均在80G A800 GPU上进行。
5.2 实验结果
表1展示了在流行视频基准数据集上的定量结果。在VideoEval-Pro上,我们的方法将LLaVA-Video的性能从40.1%提升到42.6%,将LLaVA-OneVision的性能从45.8%提升到48.7%,证明了其在增强通用MLLMs方面的有效性。在VideoMMEw/olong基准上,我们的方法将LLaVA-OneVision的性能从43.6%提升到46.9%,将LLaVA-Video的性能从47.6%提升到49.5%。
我们在长视频MLLMs和通用MLLMs上评估了LVSQA任务。根据结果,在LVsQA基准上表现最好的基线模型包括VideoChat-Flash,得分为60.1%;LLaVA-Video,得分为59.8%;以及Vamba,得分为59.6%。相比之下,Chat-UniVi-V1.5和Kangaroo的得分较低,分别为42.8%和48.8%。
这种性能差距表明,LVsQA中的问题设计有效地区分了模型在长视频中捕捉和跟踪细粒度信息的能力,展示了该基准在评估维度上的合理性和强大的区分能力。这不仅验证了LVsQA任务在长视频理解中的实用价值,还强调了关键层次抽象在提升模型复杂视频理解任务性能中的重要性。我们将把更多模型纳入LVsQA任务的评估中。为了避免因我们自身重现导致的准确性差异,我们还将维护一个排行榜,并欢迎社区提交自己的答案。
5.3 探索性实验
不同检索方法的比较
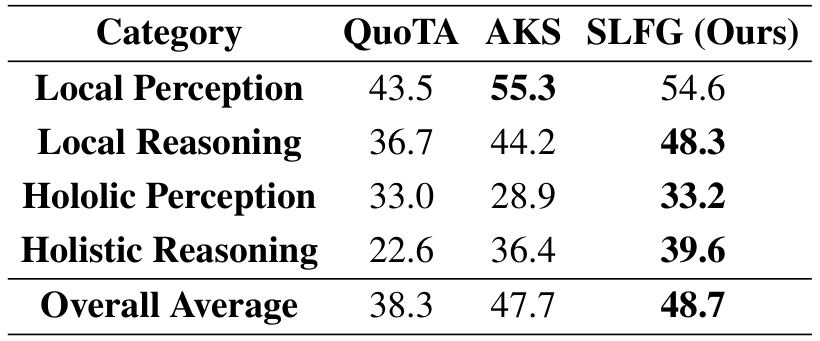
我们的实验结果揭示了长视频理解中不同范式的明显区别。本次比较主要聚焦于两个基线方法:关键帧检索(以自适应关键帧采样 AKS 为代表)和面向查询的令牌分配(以 QuoTA 为代表)。AKS 使用类似 CLIP 的视觉-语言模型来找到与查询相关的帧。QuoTA 是一种无需训练的方法,它通过思维链(Chain-of-Thought)理解查询,然后将固定的令牌预算更多地分配给最相关的帧。
我们的分析得出了一个核心结论:像 AKS 这样的基于检索的方法在“查找事物”方面非常有效,而我们以场景为中心的 SLFG 对于“理解故事”至关重要。对于简单的实事查找任务(例如 VideoEval-Pro 中的局部感知任务),AKS 通过直接匹配文本与视觉特征表现出较强的竞争力。然而,对于复杂的叙事推理任务(例如整体推理),这种专注于孤立帧的方法是一个根本性的局限。
这就是我们场景级理解优势的体现。SLFG 并不将视频视为帧的集合,而是将其视为一系列连贯的场景。这保留了理解情节和因果关系所需的上下文和逻辑。我们认为,长视频理解的核心挑战在于这种叙事理解能力。因此,SLFG 在推理任务中的优越表现证明了它更适合该领域的基本挑战。
SLFG 的时间效率
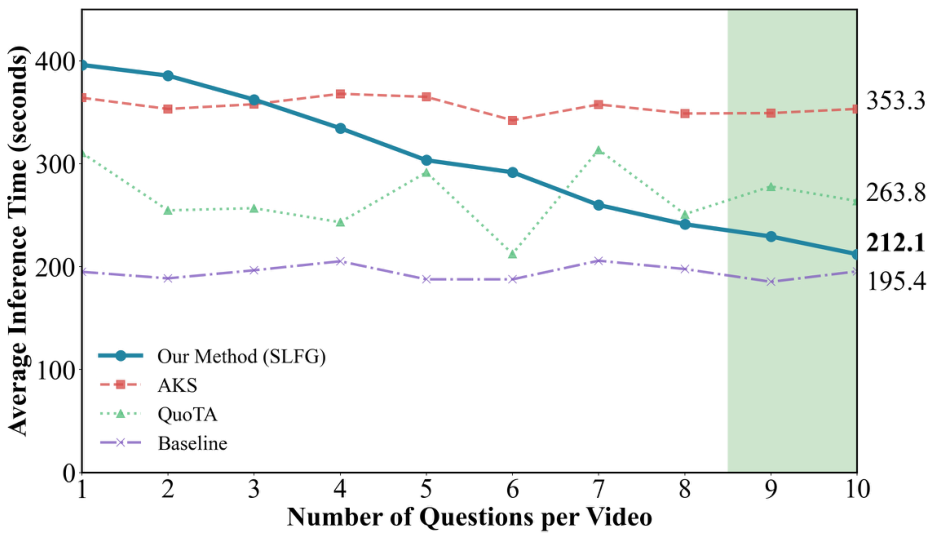
在效率方面,随着针对同一视频的问题数量增加,我们的方法展现出显著优势。这是因为分组帧描述和场景生成阶段只需执行一次,并且可以跨与单个视频相关的所有问题重复使用。通过避免对每个新查询进行冗余计算,我们的框架大大缩短了总体处理时间。
我们在一部选自 LVSQA 数据集的 30 分钟视频上进行了实验,分组粒度固定为 16 帧。由于数据集中大多数视频仅包含五个问题,我们通过重复推理过程两次模拟了更密集的交互场景,实际上每个视频产生了十个问题。我们将我们的方法与三种配置进行了比较:原始的 LLaVA-Video 基线、结合 AKS 的 LLaVA-Video 以及结合 QuoTA 的 LLaVA-Video。我们记录了每种设置下每个问题的平均推理时间。
实验结果显示,当视频包含多个问题时,使用我们的方法处理每个问题的平均时间接近于不进行任何预处理的直接推理。随着问题数量进一步增加,每个问题的平均时间持续减少,表明我们的方法对于包含大量问题视频的可扩展性和效率。如图 4 所示,随着问题数量的增加,我们方法的效率不断提高。
分组帧重组策略的效果
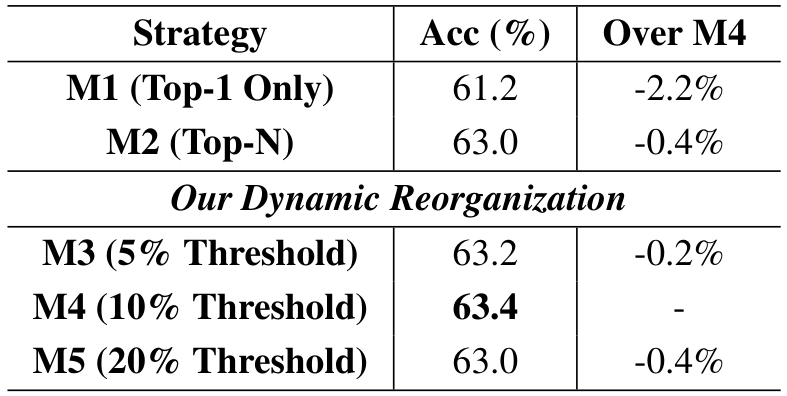
为了评估我们提出的分组帧重组策略的有效性,我们设计了一个消融研究,包含三种实验设置:
我们比较了几种场景选择策略:① M1(仅选 Top-1):仅选择得分最高的分组进行推理,不进行任何合并或扩展,代表最简单的方法。② M2(Top-N 无合并):选择得分最高的 N 个分组,不应用任何合并或时间填充,可能会引入冗余信息。③ M3-M5(动态重组):我们提出的策略,合并相似分组并扩展时间窗口以包含周围的帧。具体来说,M3 使用 5% 阈值,M4 使用 10% 阈值,M5 使用 20% 阈值进行合并。
我们在 LVSQA 数据集上使用 LLaVA-Video 进行了实验。如表 3 所示,不同阈值的策略显示 10% 阈值取得了最佳性能,其次是 20% 阈值。5% 阈值虽然仍然有效,但在保留相关语义信息方面的效率较低。我们的方法实现了优越的性能,最佳阈值结果比 M1 高出 2.2 个百分点,比 M2 高出 0.4 个百分点。
6 结论
在本文中,我们提出了一个新的场景 SceneQA,针对视频问答任务,重点关注多模态大语言模型(MLLMs)在长视频场景级别上的细节感知能力。在此基础上,我们引入了 SLFG 方法,其核心思想是利用场景级别的语义信息并模仿人类的推理模式来减少信息冗余。这为视频理解领域开辟了一个新的探索方向。为了更公平地评估多模态大语言模型在长视频场景中的细节感知能力,我们进一步扩展了 LVBench,增加了新的场景级评估问答对,称为 LVsQA。我们将维护一个排行榜,为长视频任务中的各种策略比较提供一个新的数据集。
Original Abstract: Current Multimodal Large Language Models (MLLMs) often perform poorly in long
video understanding, primarily due to resource limitations that prevent them
from processing all video frames and their associated information. Efficiently
extracting relevant information becomes a challenging task. Existing frameworks
and evaluation tasks focus on identifying specific frames containing core
objects from a large number of irrelevant frames, which does not align with the
practical needs of real-world applications. To address this issue, we propose a
new scenario under the video question-answering task, SceneQA, which emphasizes
scene-based detail perception and reasoning abilities. And we develop the LVSQA
dataset to support the SceneQA task, which is built upon carefully selected
videos from LVBench and contains a new collection of question-answer pairs to
promote a more fair evaluation of MLLMs’ scene perception abilities in long
videos. Inspired by human cognition, we introduce a novel method called SLFG.
The core idea of SLFG is to combine individual frames into semantically
coherent scene frames. By leveraging scene localization methods and dynamic
frame reassembly mechanisms, SLFG significantly enhances the understanding
capabilities of existing MLLMs in long videos. SLFG requires no modification to
the original model architecture and boasts excellent plug-and-play usability.
Experimental results show that this method performs exceptionally well in
several long video benchmark tests. Code and dataset will be released at
http://www.slfg.pkuzwh.cn.
PDF Link: 2508.03009v1
部分平台可能图片显示异常,请以我的博客内容为准
