基于Hadoop的股票大数据分析可视化及多模型的股票预测研究与实现
文章目录
- ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==
- 项目介绍
- 一、项目背景与研究意义
- 二、项目目标
- 三、系统架构与技术路线
- 1. 数据采集模块
- 2. 大数据处理模块(Hadoop生态)
- 3. 可视化分析模块(Pyecharts)
- 4. 股票价格预测模块(深度学习)
- 四、项目创新点
- 五、项目应用与推广价值
- 六、结语与展望
- 每文一语
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
项目介绍
一、项目背景与研究意义
在数字经济迅速发展的背景下,金融数据尤其是股票市场数据的规模呈指数级增长。如何从海量的股票交易数据中提取有价值的信息,并实现对未来价格的有效预测,成为当前金融技术研究和实际应用中的重要课题。传统的数据分析方法在处理TB级甚至PB级金融数据时效率低下,无法满足实时性、稳定性与可扩展性的需求。因此,构建一个基于大数据平台的股票数据分析与预测系统,不仅具备重大的学术研究意义,也能为证券公司、投资者和金融监管机构提供决策支持。
本项目聚焦于新能源汽车板块的股票数据,通过整合大数据处理技术与深度学习模型,完成从数据采集、清洗、存储、分析、可视化到价格预测的全流程系统设计与实现。项目以Hadoop为核心构建数据处理平台,通过Flume、Hive、Sqoop等组件搭建稳定的数据处理链,并结合Pyecharts实现可视化展示。同时,针对股票价格走势的非线性、高波动性特点,采用LSTM与GRU等深度学习模型进行预测,取得了优异的效果。
二、项目目标
本项目的目标是实现一个面向新能源汽车板块股票数据的多功能大数据分析与预测平台,主要包括以下几点:
- 实现对新能源汽车行业股票数据的自动化采集;
- 构建基于Hadoop生态的大数据处理流程;
- 设计完整的数据仓库结构(ODS、DWD、DWS、ADS);
- 实现多维度的股票数据可视化分析;
- 基于LSTM与GRU神经网络构建多模型股票价格预测框架;
- 对比各模型效果,优化预测性能。
三、系统架构与技术路线
1. 数据采集模块
项目首先从东方财富网采集新能源汽车相关股票的历史交易数据,内容包括每日开盘价、收盘价、最高价、最低价、成交量、换手率等关键指标。爬虫采用Python编写,利用requests和BeautifulSoup模块定期采集并存储为CSV格式,便于后续处理。
2. 大数据处理模块(Hadoop生态)
本项目大数据平台构建基于Hadoop生态,涵盖以下核心组件:
-
Flume数据采集与上传
使用Flume将本地采集到的CSV数据实时上传至HDFS,支持断点续传和批量处理,保障数据传输的稳定性和完整性。 -
Hive数据仓库设计
数据上传至HDFS后,利用Hive构建多层次数据仓库,具体分为以下四层:- ODS层(原始数据层):存储未经处理的原始股票交易数据。
- DWD层(数据明细层):对数据进行字段解析、时间维度拆分、缺失值处理、标准化命名。
- DWS层(汇总层):按时间、股票代码等维度进行聚合计算,提取日均波动、成交量趋势、行业涨跌幅对比等指标。
- ADS层(应用层):存储可视化所需的最终结果,如热点股票排行、异常波动分析、K线形态特征等。
-
Sqoop数据导出
将ADS层的关键业务数据通过Sqoop导出到本地MySQL数据库,方便业务查询和前端图表展示。
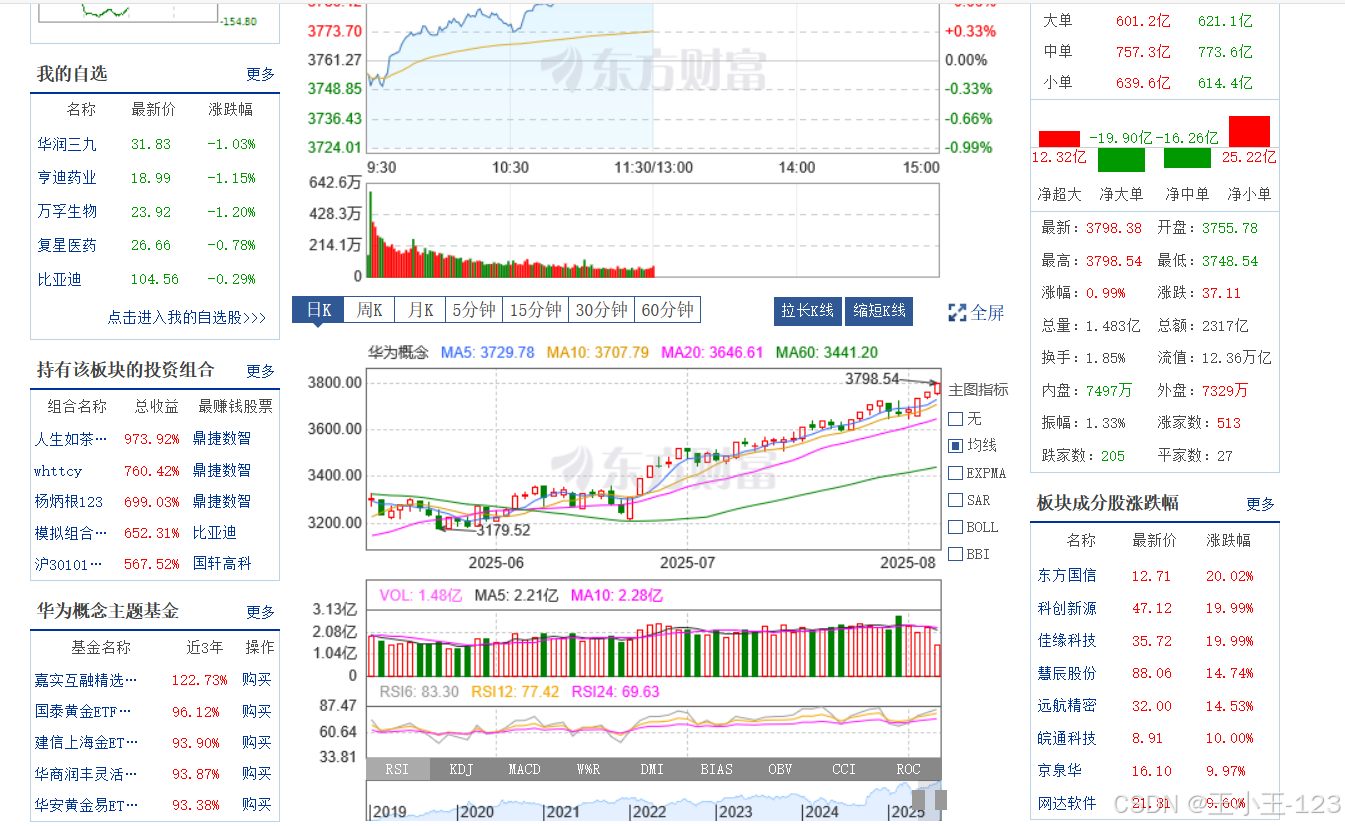
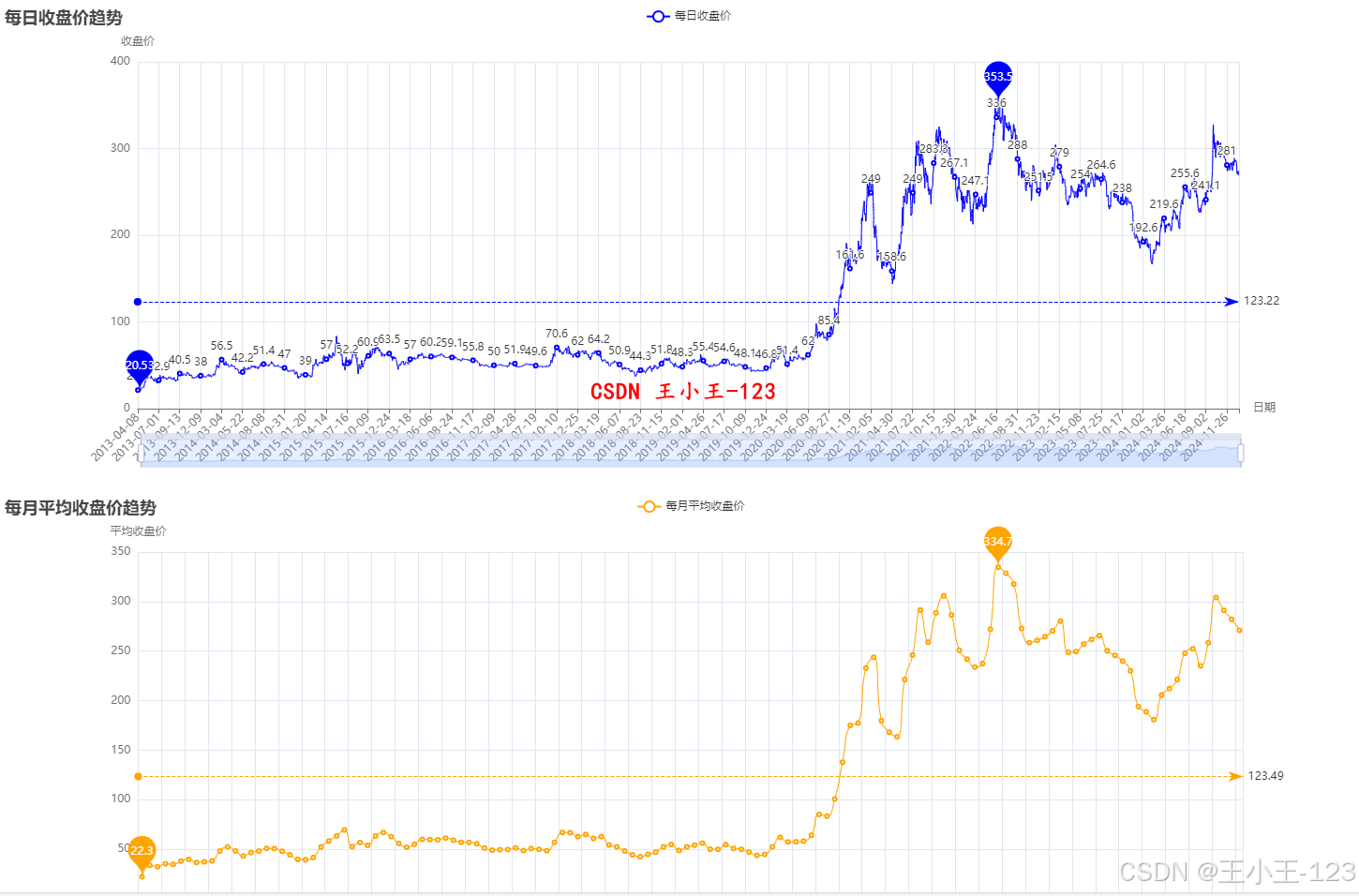
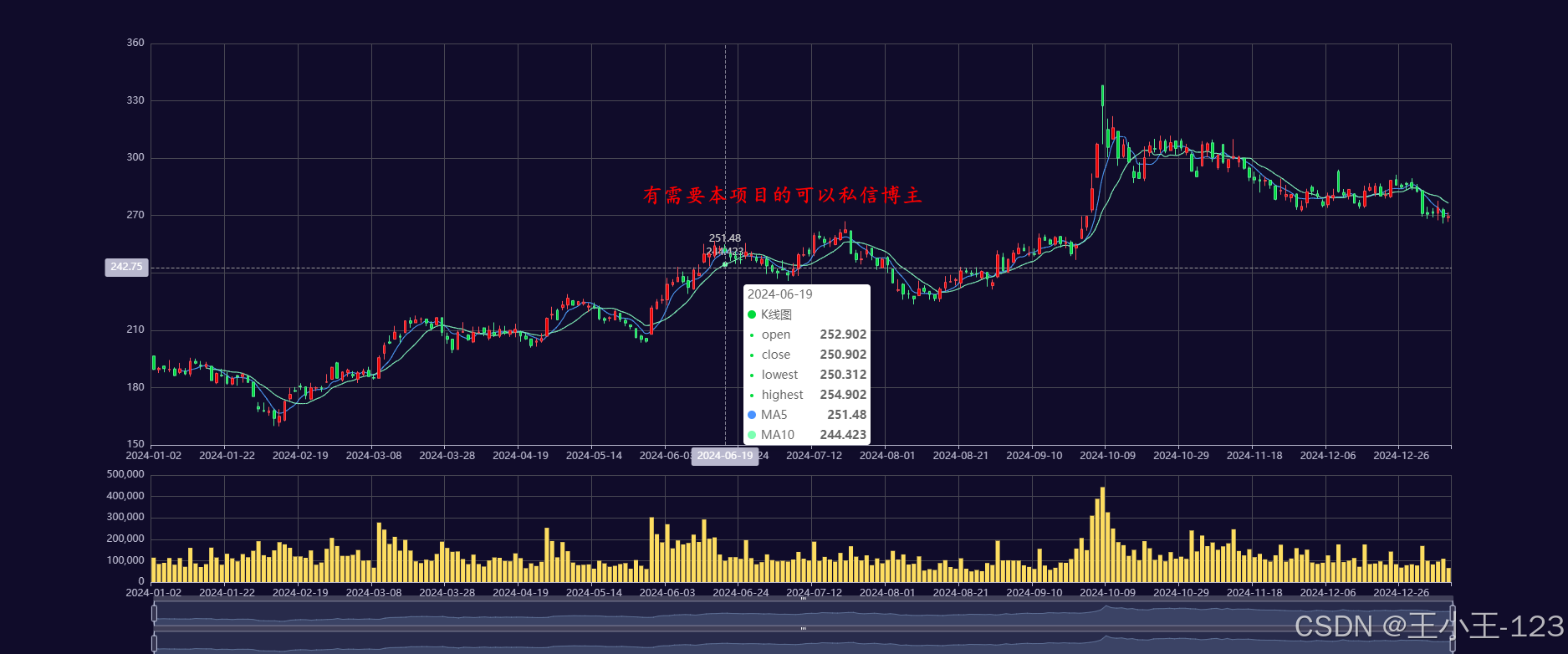
3. 可视化分析模块(Pyecharts)
利用Pyecharts框架对Hive与MySQL中的数据进行可视化展示。主要可视化内容包括:
- 行业涨跌幅趋势图;
- 新能源股票个股涨跌波动折线图;
- 股票活跃度热力图;
- 每日交易量柱状图;
- 股票价格K线图。
可视化图表不仅为数据解读提供直观支持,也为后续模型设计与评估提供辅助依据。
4. 股票价格预测模块(深度学习)
为提升系统的智能化水平,项目进一步引入深度学习模型进行股票价格预测。
-
数据准备:将Hive中的价格数据清洗后,提取关键特征变量(开盘价、收盘价、最高、最低、成交量等),构建时间序列样本;
-
模型设计:
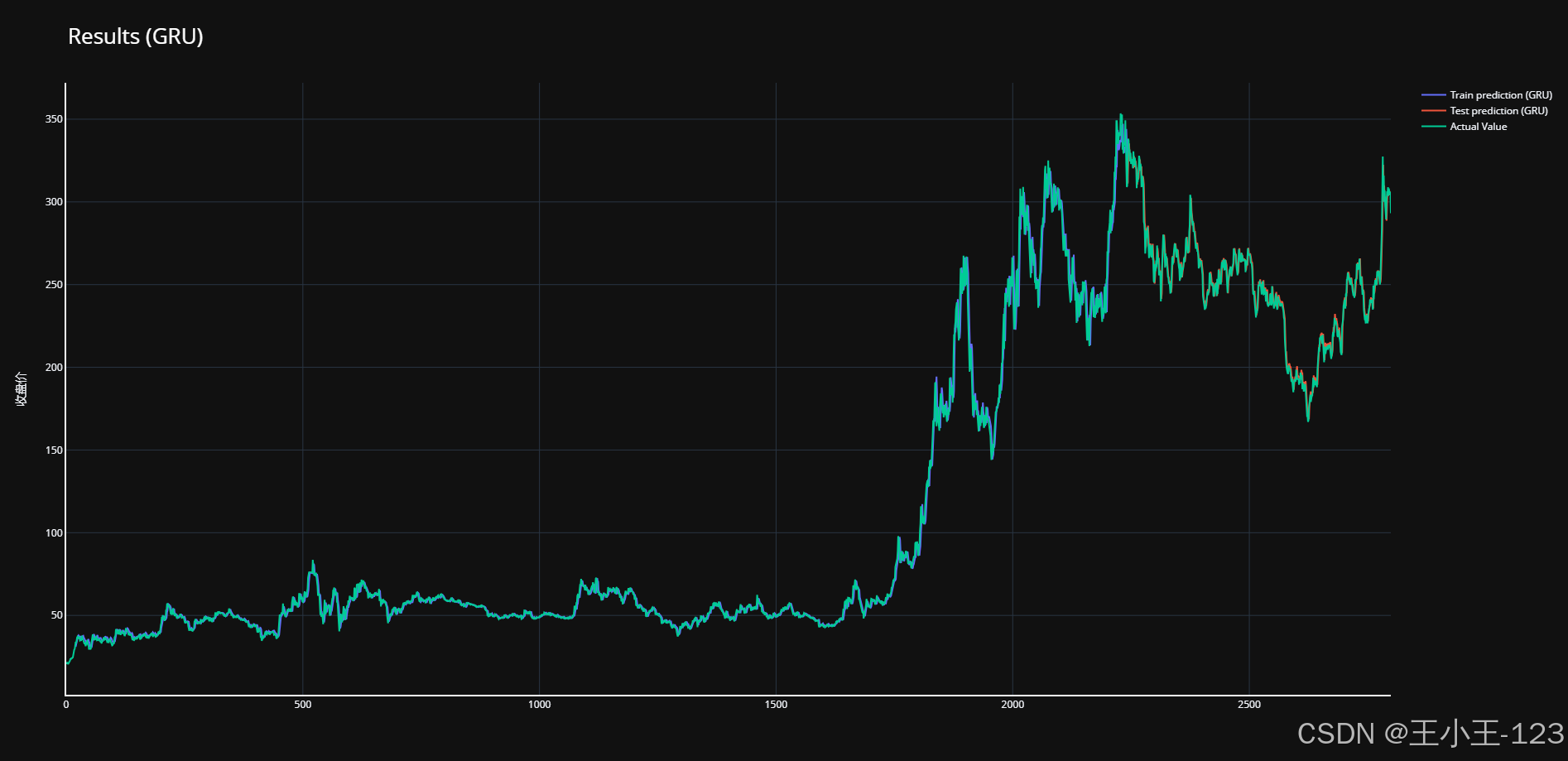
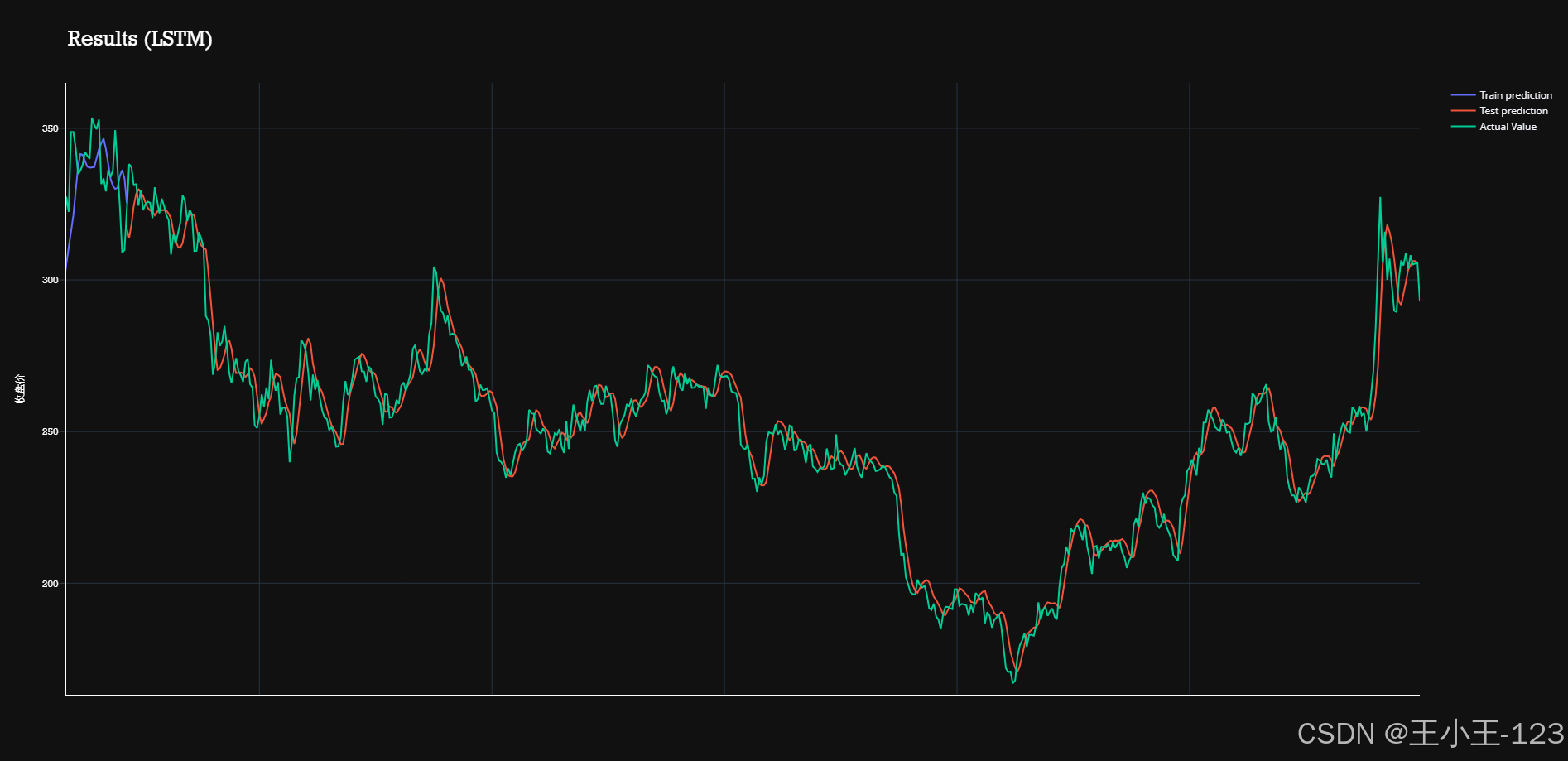
- LSTM模型:利用其在长时序依赖建模中的优势,对股票价格走势进行预测;
- GRU模型:作为LSTM的轻量版本,减少参数,提高模型效率;
- 对比分析:对比两种模型在相同数据集下的预测效果,使用RMSE、MAE、R²等评价指标进行定量评估;
-
训练与调优:采用滑动窗口方式生成训练样本,使用归一化技术优化模型收敛速度。实验发现,LSTM在长期趋势预测上更优,而GRU在短期波动中表现更敏捷。
-
预测结果展示:将预测结果与真实数据对比,通过折线图、误差曲线进行展示,直观体现模型的准确性。
四、项目创新点
-
完整的数据处理流程
项目覆盖了从数据采集、清洗、存储、分析、可视化到模型预测的全过程,技术路线完整、模块清晰,可复制性强。 -
结合Hadoop与深度学习
将大数据处理与人工智能模型有效结合,既满足高性能处理需求,又提升了预测的智能化水平。 -
多模型对比分析
同时采用LSTM与GRU模型进行预测,并通过实验验证其各自优势,为实际应用提供选择依据。 -
数据仓库结构规范化
采用ODS、DWD、DWS、ADS四层设计模式,使数据逻辑结构清晰,便于管理与维护。 -
可视化呈现数据价值
借助Pyecharts进行多角度、交互式可视化,便于决策者快速掌握市场行情与个股动向。
五、项目应用与推广价值
该系统可广泛应用于以下场景:
- 证券投资机构:提供数据分析平台,辅助技术面选股与风险控制;
- 金融科技企业:为智能投顾系统提供基础数据处理与预测模块;
- 高校金融实训平台:作为教学案例用于大数据分析、数据挖掘、机器学习等课程;
- 散户投资者:通过Web端展示股票行情和预测结果,提升投资参考依据。
系统具备良好的拓展性,未来可接入更多股票板块数据,支持多指标联合预测、情感分析、图神经网络等模块的加入。
六、结语与展望
本项目在大数据处理与金融预测融合方面做出了积极探索,构建了一个可用、可视、可扩展的股票数据分析与预测平台,既体现了对当前大数据分析技术的深度应用,也展示了AI在金融领域的广阔前景。
每文一语
人的最佳状态是什么,是工作的时候的快乐还是玩耍时的尽兴