论文略读:Knowledge is a Region in Weight Space for Finetuned Language Models
EMNLP 2023
- 神经网络研究长期以来主要聚焦于单个模型在单个数据集上的行为与特性,但对于不同模型之间的关系,我们知之甚少。
- 本文试图弥补这一空白,探索模型之间在权重空间和损失函数景观中的联系。
- 研究发现:
权重空间中的聚集性
在同一个数据集上微调的,架构相同的语言模型,在权重空间中形成紧密的聚类(tight cluster);
对于来自同一任务但不同数据集的微调模型,它们在权重空间中也形成一个相对较松散的聚类(looser cluster);
换言之,模型的“几何位置”能够反映出它们的任务相似性和数据分布。
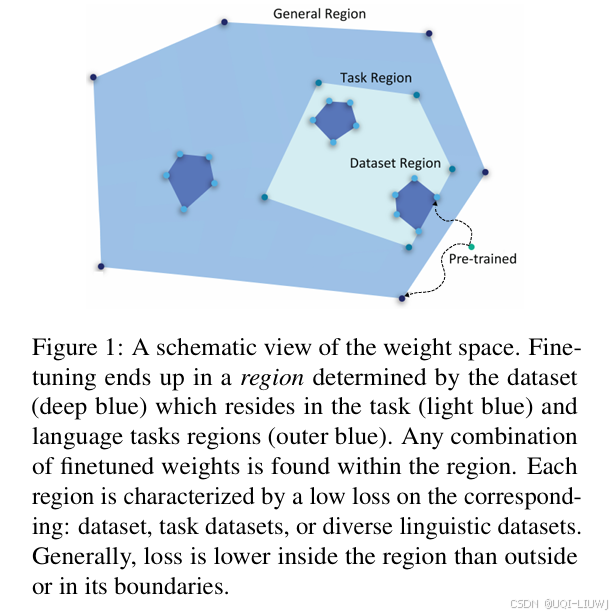

- 性能区域的连通性
所有在同一任务上表现良好的模型,集中分布在权重空间的某一特定区域;
更重要的是,该区域内任意位置的模型都具有较高性能;
即使这些模型未在某个特定任务上微调过,只要它们处于“好模型”之间的区域,也可能在该任务上表现良好。
基于以上观察,作者设计了一种高效微调的起点选择策略:
不再直接使用预训练模型,而是从多个微调模型形成区域的中心点开始微调;