论文略读:Mitigating Catastrophic Forgetting in Language Transfer via Model Merging
EMNLP 2025
- 大型语言模型(LLMs)在诸多任务中展现出了令人瞩目的能力,尤其是在英文上表现尤为出色。
- 然而,对于一些使用频率较低的语言,模型性能往往显著较差,因此额外的适配工作显得至关重要
- 不幸的是,大多数语言适配技术往往会带来灾难性遗忘,即模型在学习新语言时会严重丧失原有能力
- 例如,在英文中学到的数学和编程技能,可能对其他语言中的通用问题求解或推理任务极为有用。
- 为了缓解这种遗忘现象,研究人员提出了经验重放方法,即在目标语言的训练集中混入部分源语言数据。
- 然而,经验重放本身仍不足以完全避免遗忘。特别是当源语言数据不可得(如在一些最先进的大模型中),经验重放只能以近似方式实现,从而降低了其效果
- 论文基于**持续学习(continual learning)**的思想,提出了一种新的语言适配方法:Branch-and-Merge(BaM)
- BaM 能够将预训练语言模型适配到那些在其原始训练数据中严重低资源的新语言,同时尽可能保留原有已学习的能力。
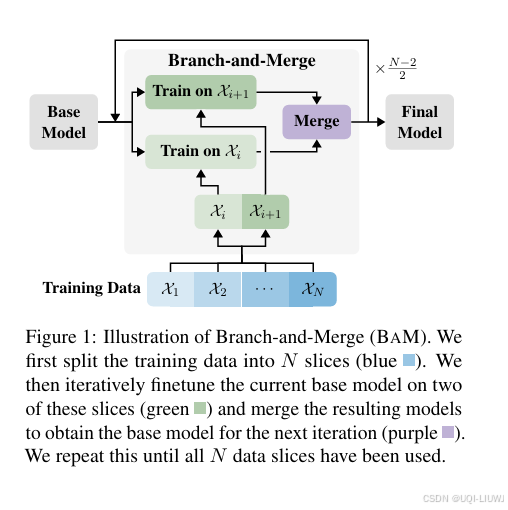
- 具体而言,BaM 首先将训练数据划分为 N 个数据片段(图 1 中蓝色),然后在每轮中将当前的基础模型分别在 K 个(如图中为两个)数据子集上并行微调(绿色),最后将这些模型进行合并(紫色),得到下一轮迭代的起始模型。
- 这种做法能显著减少模型整体的权重变动幅度,从而有效降低遗忘,同时又能保留来自并行训练的学习成果。
- 虽然与标准持续训练相比,目标语言的困惑度(perplexity)可能略有上升,但由于保留了原模型技能,最终在目标语言下游任务上取得了更高的实际性能
- 论文将 BaM 应用于将 MISTRAL-7B和 LLAMA-3-8B从以英文为主的模型适配到两种新语言上:
一种与英文共享字母系统的语言(德语);
一种不共享字母系统的语言(保加利亚语);
实验表明,BaM 能在目标语言和源语言上都显著提升性能,且不引入额外的数据或计算开销。
例如,在指令微调任务中,使用 BaM 训练的 LLAMA-3-8B(保加利亚语)不仅在保加利亚语上超越了 LLAMA-3-8B-Instruct 10.9%,甚至在英文任务上也提升了 1.3%,这得益于 BaM 所带来的幅度更小但更有效的权重变化。
2 模型合并
- 论文实验了以下几种方法:
LINEAR 合并(Wortsman 等,2022)
SLERP 合并(Goddard 等,2024;Shoemake, 1985)
MODEL STOCK 合并(Jang 等,2024)

2.1 LINEAR 合并方法

2.2 SLERP 合并方法

3 使用 Branch-and-Merge 缓解语言迁移中的遗忘、

3.1 直觉(Intuition)


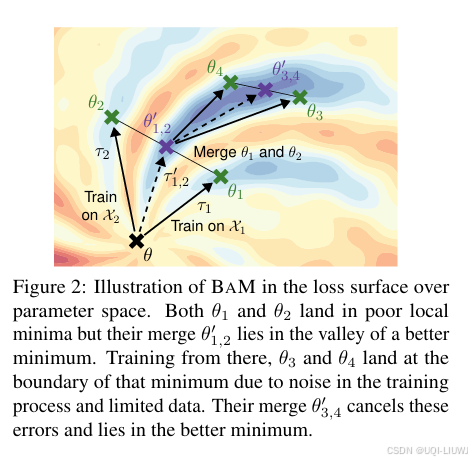

3.2 实现细节

