RAG深入理解和简易实现
文章目录
- 参考资料
- 说明
- 一 RAG
- 1.1 RAG技术诞生的原因
- 1.2 更新大模型知识库设计
- 1.2.1 思路一:知识灌注
- 1.2.2 思路二:增加模型上下文长度
- 1.2.3 思路三:知识检索
- 1.3 通用RAG基础流程
- 1.4 RAG技术核心步骤和通用优化方法
- 1.5 RAG实践落地策略
- 1.6 RAG系统核心组件
- 二 环境准备和相似度理解
- 2.1 OpenAI 中转平台
- 2.2 代码总依赖
- 2.2.1 欧氏距离与余弦相似度计算公式
- 2.2.2 余弦相似度计算实现
- 三 向量化模块
- 3.1 向量化模块简介
- 3.2 向量化模块代码实现
- 四 文档加载与切分模块
- 4.1 文档格式化和切分函数
- 4.2 部分实现
- 4.3 完整实现
- 五 词向量数据库与向量检索模块
- 六 大模型问答模块
- 6.1 BaseModel类
- 6.2 GPT4o模型对话子类
- 七 RAG完整使用
- 7.1 简单使用测试
- 7.2 完整版使用测试
参考资料
- 从零到一快速搭建本地RAG引擎|大模型私有知识库问答技术快速实践|本地RAG引擎搭建流程
- 从零到一搭建一个小型RAG系统
说明
- 本文仅供学习和交流,感谢赋范空间的贡献和九天老师!
一 RAG
- 大模型挂载知识库核心技术:RAG(Retrieval Augmentation Generation)旨在为大模型灵活的提供外部知识库支持,以拓展大模型知识边界。
- RAG 通过先从数据库中检索与问题相关的信息,再基于检索到的内容进行回答生成,极大地提升了模型输出的准确性和相关性。RAG 不仅提高了知识更新的效率,还显著增强了生成内容的可追溯性,使其在实际应用中更具实用性和可信度。
1.1 RAG技术诞生的原因
- RAG技术产生的原因是大模型最大对话上下文限制,导致大模型可以处理的文本长度受限。此外,由于单次训练的成本高昂、训练文本具有时效性以及少量信息文本无法被模型学习,导致大模型本身对于专业性知识和实效性较强的知识响应能力很弱。
1.2 更新大模型知识库设计
1.2.1 思路一:知识灌注
- 借助模型训练进行知识灌注:在模型预训练、全量指令微调、或者高校微调阶段输入特定领域文本,从而让模型“永久的记住”某些信息。
- 存在的问题:
- 效果不稳定:若若只带入少量专业文本,模型无法表现出智能,若带入海量互联网文本,少量专业文本就会被“淹没”。
- 成本高昂:每次训练都需要耗费大量的成本时间,且效果不稳定。
1.2.2 思路二:增加模型上下文长度
- 增加模型上下文长度,从而每次问答时都将相关的文档一次性全部输入。典型代表GLM-4-long,最多可以支持1M上下文。
- Claude开创的提示词缓存技术,也可以变相增加模型上下文长度。
- 存在的问题:受限于大模型本身原理,模型上下文无法无限拓展,且每次输入大量文本也会导致算力消耗大幅增加。
1.2.3 思路三:知识检索
- RAG知识检索,希望找到一种方法,每次大模型回复之前,都可以把问题相关的文本内容输入给大模型,可以节省成本的同时提高模型的响应速度,而且具备极强的可拓展性。
- 存在的问题:如何有效,高效把相关的文档片段“检索出来”。
1.3 通用RAG基础流程
- 将文档按Token长度进行切分,设置一个最大的 Token 长度,然后按这个长度进行切分。在这个过程中,我们也会确保每个片段之间有一定的重叠,避免重要信息被切掉。
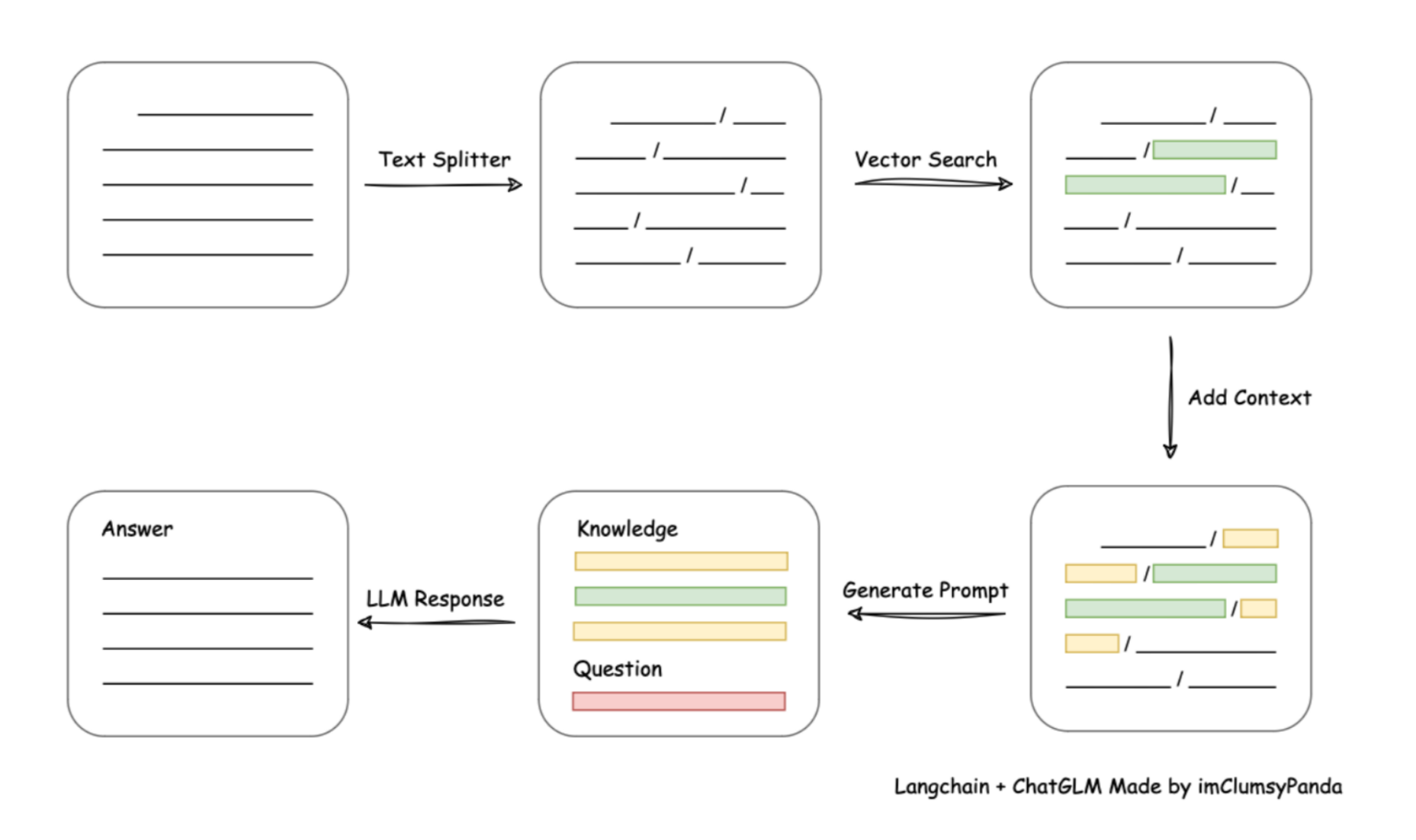
1.4 RAG技术核心步骤和通用优化方法
- 文档切分:优化方法包括根据关键字符切分或根据字符串长度切分、以及滑动窗口切分、围绕不同类型文本、选择不同的切分策略。文本数据清洗占据绝大部分时间,是本环节提效的关键。
- 文档匹配和输入:根据Embeding进行文本词向量化处理,并根据余弦相似度判断和问题相关的文档。选择更好的Embeding模型、以及匹配后文本增强、重拍等,是优化的关键。
- 模型问答:灵活判断文档段落内容是否可用,并根据文档进行回答。真实性检验、后处理、用户意图判断是本环节优化的关键。
1.5 RAG实践落地策略
- 手动搭建RAG引擎
- 使用LangChain、Llama-index、GraphRag等开源项目快速搭建
- 使用GLM、OpenAI Assistant API等进行快速实现。
1.6 RAG系统核心组件
RAG 模型,通常包含以下几个核心模块:
- 文档加载与切分模块:负责加载文档并将其切分为若干易于处理的文档片段。
- 向量化模块:用于将文档片段转换为向量表示,以便后续检索。
- 数据库模块:用于存储文档片段及其对应的向量表示。
- 检索模块:根据用户输入的查询,检索与其相关的文档片段。
- 生成模块:调用语言模型生成基于检索信息的回答。
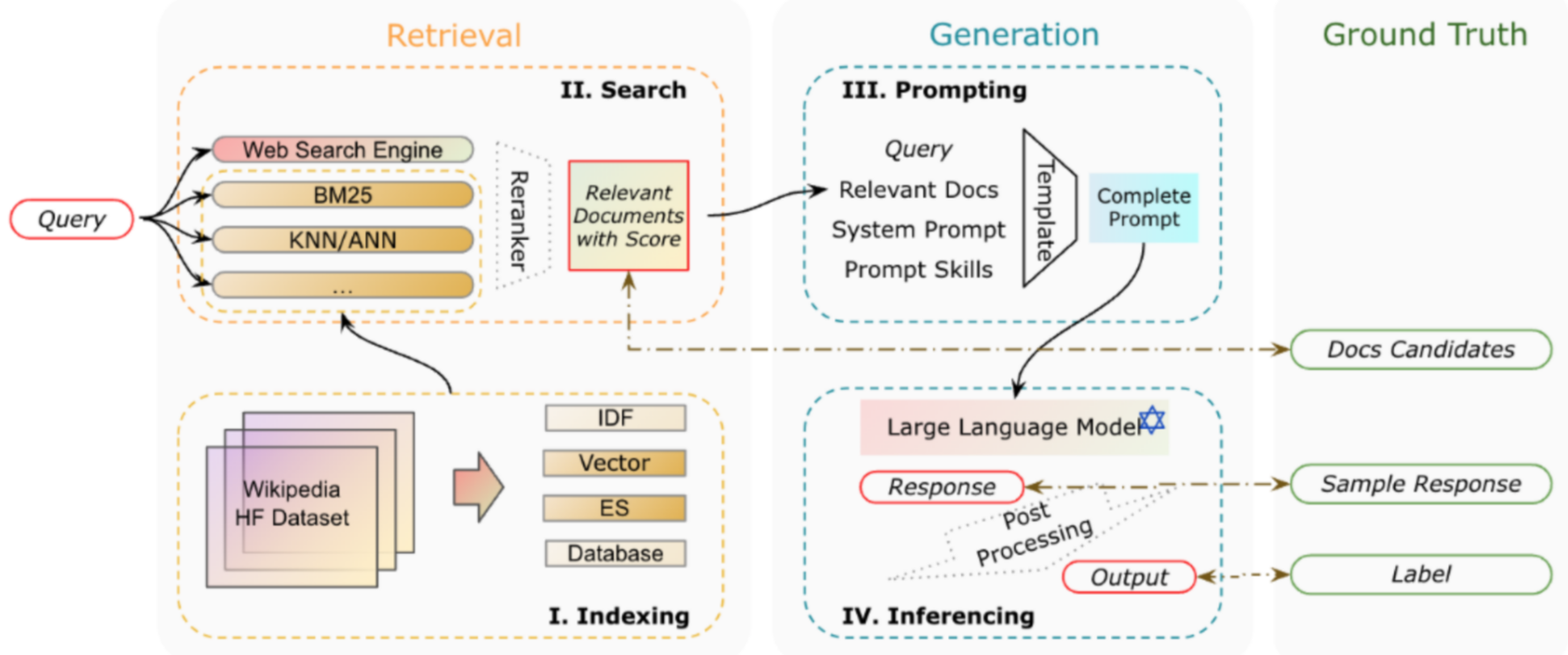
一个RAG系统的基本流程:
- 索引:将文档库分割成较短的 Chunk,并通过编码器构建向量索引。
- 检索:根据问题和 chunks 的相似度检索相关文档片段。
- 生成:以检索到的上下文为条件,生成问题的回答。
二 环境准备和相似度理解
2.1 OpenAI 中转平台
- openai-hk
2.2 代码总依赖
pip install PyPDF2 markdown html2text tiktoken
import os
from openai import OpenAI
import matplotlib.pyplot as plt
import numpy as np
from typing import Dict, List, Optional, Tuple, Unionimport PyPDF2
import markdown
import html2text
import json
from tqdm import tqdm
import tiktoken
import re
from bs4 import BeautifulSoup
from IPython.display import display, Code, Markdownapi_key="hk-xxx"
base_url="https://api.openai-hk.com/v1"
# 实例化客户端
client = OpenAI(api_key=api_key,base_url=base_url)
# 临时设置环境变量
os.environ["OPENAI_API_KEY"] = api_key
os.environ["OPENAI_BASE_URL"] = base_url
2.2.1 欧氏距离与余弦相似度计算公式
假设现有a、b两个向量:
a⃗=[a1,a2,a3,...]\vec{a} = [a_1, a_2, a_3, ...]a=[a1,a2,a3,...]
b⃗=[b1,b2,b3,...]\vec{b} = [b_1, b_2, b_3, ...]b=[b1,b2,b3,...]
余弦相似度计算公式为:
| Cosine Similarity(a⃗,b⃗)=a⃗⋅b⃗∣a⃗∣∣b⃗∣\text{Cosine Similarity} (\vec{a}, \vec{b}) = \frac{\vec{a} \cdot \vec{b}}{|\vec{a}| |\vec{b}|}Cosine Similarity(a,b)=∣a∣∣b∣a⋅b |
|---|
-
a⃗⋅b⃗\vec{a} \cdot \vec{b}a⋅b表示向量 a⃗\vec{a}a 和向量 b⃗\vec{b}b 的点积。
-
∥a⃗∥\|\vec{a}\|∥a∥ 和 ∥b⃗∥\|\vec{b}\|∥b∥ 分别是向量 a⃗\vec{a}a 和 b⃗\vec{b}b 的模(长度)。
-
点积 (Dot Product) 定义为:a⃗⋅b⃗=a1b1+a2b2+…+anbn\vec{a} \cdot \vec{b} = a_1b_1 + a_2b_2 + \ldots + a_nb_na⋅b=a1b1+a2b2+…+anbn
-
向量的模 (Magnitude) 定义为:
∥a⃗∥=a12+a22+…+an2\|\vec{a}\| = \sqrt{a_1^2 + a_2^2 + \ldots + a_n^2}∥a∥=a12+a22+…+an2
∥b⃗∥=b12+b22+…+bn2\|\vec{b}\| = \sqrt{b_1^2 + b_2^2 + \ldots + b_n^2}∥b∥=b12+b22+…+bn2
import matplotlib.pyplot as plt
import numpy as np# 创建两个向量
a = np.array([0, 1])
b = np.array([1, 1])# 计算两个向量的余弦相似度
cosine_similarity = np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))# 绘制向量
plt.quiver(0, 0, a[0], a[1], angles='xy', scale_units='xy', scale=1, color='r')
plt.quiver(0, 0, b[0], b[1], angles='xy', scale_units='xy', scale=1, color='b')# 设置图表属性
plt.xlim(-0.5, 1.5)
plt.ylim(-0.5, 1.5)
plt.grid()
plt.title(f'Cosine Similarity: {cosine_similarity:.2f}')
plt.xlabel('X axis')
plt.ylabel('Y axis')# 添加图例
plt.legend(['Vector a', 'Vector b'])# 显示图表
plt.show()
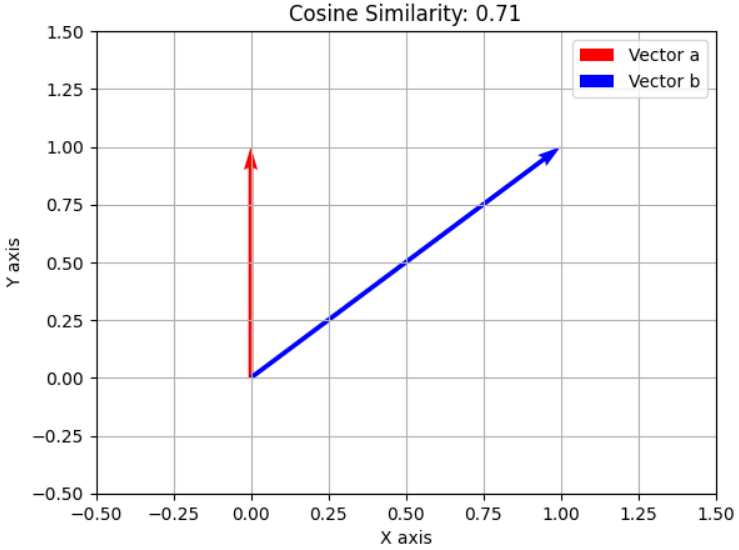
- 红色向量代表a⃗\vec{a}a ,蓝色向量代表 b⃗\vec{b}b 。它们之间的夹角表示了两个向量的余弦相似度。余弦相似度是通过计算两个向量的点积并除以它们各自的范数(即长度)来得到的。两个向量的余弦相似度大约为 0.71,意味着它们在方向上有一定程度的相似性。这个值越接近 1,表示两个向量的方向越相似。
2.2.2 余弦相似度计算实现
def cosine_sim(vector1: List[float], vector2: List[float]) -> float:"""计算两个向量之间的余弦相似度"""dot_product = np.dot(vector1, vector2)magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2)if not magnitude:return 0return dot_product / magnitudetext1 = '我喜欢吃苹果'
text2 = "苹果是我最喜欢吃的水果"
text3 = "我喜欢用苹果手机"vector1 = client.embeddings.create(input=text1, model="text-embedding-3-large"
).data[0].embeddingvector2 = client.embeddings.create(input=text2, model="text-embedding-3-large"
).data[0].embeddingvector3 = client.embeddings.create(input=text3, model="text-embedding-3-large"
).data[0].embeddingprint(np.float64(cosine_sim(vector1, vector2)))
print(np.float64(cosine_sim(vector1, vector3)))
print(np.float64(cosine_sim(vector2, vector3)))'''
0.7661800739633343
0.7224817543294454
0.6315437708887437
'''
- 通过计算余弦相似度计算结果,分析可知
text1和text2相似度结果之最高,两者语义最接近。
三 向量化模块
3.1 向量化模块简介
- Embedding 是将文本转化为数值向量的常用方法。通过这种方式,模型可以通过计算不同向量之间的余弦相似度衡量不同文本之间的相似性,进而应用于如搜索、分类、推荐等多个领域。
常见的 Embedding 应用包括:
- 搜索:根据文本查询的相关性对结果进行排序。
- 聚类:根据文本相似性将其分组。
- 推荐:根据相关文本字符串推荐项目。
- 异常检测:识别与其他内容相关性较低的异常点。
- 多样性测量:分析相似性分布。
- 分类:将文本字符串根据其最相似的标签进行分类。
- 这里使用OpenAI Embedding Embedding模型包括
text-embedding-3-small。可以使用openai-hk进行模型代理。
# 调用 embedding API 获取文本的向量表示
response = client.embeddings.create(input="测试文本", # 输入文本model="text-embedding-3-small" # 选择 Embedding 模型
)
# 打印返回的 embedding 向量
print(response.data[0].embedding)
len(response.data[0].embedding) # 1536
- 默认情况下,
text-embedding-3-small生成的向量长度为 1536,text-embedding-3-large的向量长度为 3072。
3.2 向量化模块代码实现
- 向量化是 RAG 的基础,它的作用是将文档片段转化为向量表示,便于后续的检索操作。在这个过程中,需要将实现一个向量化类,用来将文本片段映射成向量。
- 编写Embedding 基类,定义获取文本向量表示的方法,同时包含计算两个向量之间余弦相似度的函数,提高代码的复用性。
class BaseEmbeddings:"""向量化的基类,用于将文本转换为向量表示。不同的子类可以实现不同的向量获取方法。"""def __init__(self, path: str, is_api: bool) -> None:"""初始化基类参数:path (str) - 如果是本地模型,path 表示模型路径;如果是API模式,path可以为空is_api (bool) - 表示是否使用API调用,如果为True表示通过API获取Embedding"""self.path = pathself.is_api = is_apidef get_embedding(self, text: str, model: str) -> List[float]:"""抽象方法,用于获取文本的向量表示,具体实现需要在子类中定义。参数:text (str) - 需要转换为向量的文本model (str) - 所使用的模型名称返回:list[float] - 文本的向量表示"""raise NotImplementedError@classmethoddef cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:"""计算两个向量之间的余弦相似度,用于衡量它们的相似程度。参数:vector1 (list[float]) - 第一个向量vector2 (list[float]) - 第二个向量返回:float - 余弦相似度值,范围从 -1 到 1,越接近 1 表示向量越相似"""dot_product = np.dot(vector1, vector2) # 向量点积magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2) # 向量的模if not magnitude:return 0return dot_product / magnitude # 计算余弦相似度
- 创建
OpenAIEmbedding继承BaseEmbeddings基类,实现具体的向量化方法。
class OpenAIEmbedding(BaseEmbeddings):"""使用 OpenAI 的 Embedding API 来获取文本向量的类,继承自 BaseEmbeddings。"""def __init__(self, path: str = '', is_api: bool = True) -> None:"""初始化类,设置 OpenAI API 客户端,如果使用的是 API 调用。参数:path (str) - 本地模型的路径,使用API时可以为空is_api (bool) - 是否通过 API 获取 Embedding,默认为 True"""super().__init__(path, is_api)if self.is_api:# 初始化 OpenAI API 客户端from openai import OpenAIself.client = OpenAI()self.client.api_key = os.getenv("OPENAI_API_KEY") # 从环境变量中获取 API 密钥self.client.base_url = os.getenv("OPENAI_BASE_URL") # 从环境变量中获取 API 基础URLdef get_embedding(self, text: str, model: str = "text-embedding-3-large") -> List[float]:"""使用 OpenAI 的 Embedding API 获取文本的向量表示。参数:text (str) - 需要转化为向量的文本model (str) - 使用的 Embedding 模型名称,默认为 'text-embedding-3-large'返回:list[float] - 文本的向量表示"""if self.is_api:# 去掉文本中的换行符,保证输入格式规范text = text.replace("\n", " ")# 调用 OpenAI API 获取文本的向量表示return self.client.embeddings.create(input=[text], model=model).data[0].embeddingelse:raise NotImplementedError # 非 API 模式,这里未实现本地模型的处理
- 创建测试用例,并计算
# 初始化 Embedding 模型
embedding_model = OpenAIEmbedding()# 输入需要获取向量表示的文本
text = "愿世界充满善良和和平"# 获取文本的向量长度和表示
embedding_vector = embedding_model.get_embedding(text, model="text-embedding-3-large")
print("文本向量的长度为:",len(embedding_vector)) # 3072
# print("文本的向量表示为:", embedding_vector)
四 文档加载与切分模块
- 编写一个文档加载与切分模块,用于处理不同格式的文档并将其切分为小片段。为了确保每个文档片段都尽量保持简短且信息集中,以便于后续的向量化和检索。
4.1 文档格式化和切分函数
- 文档格式化支持:包括PDF、Markdown、TXT,每种文件格式都有不同的读取方式。
- 文档切分:将文档按Token长度进行切分,设置一个最大的 Token 长度,然后按这个长度进行切分,确保片段之间有一定的重叠,避免重要信息被切掉。
4.2 部分实现
- 文档格式化函数和文档切分函数的部分实现:
def read_file_content(cls, file_path: str):# 根据文件扩展名选择读取方法if file_path.endswith('.pdf'):return cls.read_pdf(file_path)elif file_path.endswith('.md'):return cls.read_markdown(file_path)elif file_path.endswith('.txt'):return cls.read_text(file_path)else:raise ValueError("Unsupported file type")def get_chunk(cls, text: str, max_token_len: int = 600, cover_content: int = 150):chunk_text = []curr_len = 0curr_chunk = ''lines = text.split('\n') # 以换行符为单位切分文本for line in lines:line = line.replace(' ', '')line_len = len(enc.encode(line)) # 计算当前行的 Token 长度if line_len > max_token_len:print('warning line_len = ', line_len)if curr_len + line_len <= max_token_len:curr_chunk += line + '\n'curr_len += line_len + 1else:chunk_text.append(curr_chunk)curr_chunk = curr_chunk[-cover_content:] + linecurr_len = line_len + cover_contentif curr_chunk:chunk_text.append(curr_chunk)return chunk_text
4.3 完整实现
- 文档加载与切分完整代码实现
class ReadFiles:"""读取文件的类,用于从指定路径读取支持的文件类型(如 .txt、.md、.pdf)并进行内容分割。"""def __init__(self, path: str) -> None:"""初始化函数,设定要读取的文件路径,并获取该路径下所有符合要求的文件。:param path: 文件夹路径"""self._path = pathself.file_list = self.get_files() # 获取文件列表def get_files(self):"""遍历指定文件夹,获取支持的文件类型列表(txt, md, pdf)。:return: 文件路径列表"""file_list = []for filepath, dirnames, filenames in os.walk(self._path):# os.walk 函数将递归遍历指定文件夹for filename in filenames:# 根据文件后缀筛选支持的文件类型if filename.endswith(".md"):file_list.append(os.path.join(filepath, filename))elif filename.endswith(".txt"):file_list.append(os.path.join(filepath, filename))elif filename.endswith(".pdf"):file_list.append(os.path.join(filepath, filename))return file_listdef get_content(self, max_token_len: int = 600, cover_content: int = 150):"""读取文件内容并进行分割,将长文本切分为多个块。:param max_token_len: 每个文档片段的最大 Token 长度:param cover_content: 在每个片段之间重叠的 Token 长度:return: 切分后的文档片段列表"""docs = []for file in self.file_list:content = self.read_file_content(file) # 读取文件内容# 分割文档为多个小块chunk_content = self.get_chunk(content, max_token_len=max_token_len, cover_content=cover_content)docs.extend(chunk_content)return docs@classmethoddef get_chunk(cls, text: str, max_token_len: int = 600, cover_content: int = 150):"""将文档内容按最大 Token 长度进行切分。:param text: 文档内容:param max_token_len: 每个片段的最大 Token 长度:param cover_content: 重叠的内容长度:return: 切分后的文档片段列表"""chunk_text = []curr_len = 0curr_chunk = ''token_len = max_token_len - cover_contentlines = text.splitlines() # 以换行符分割文本为行for line in lines:line = line.replace(' ', '') # 去除空格line_len = len(enc.encode(line)) # 计算当前行的 Token 长度if line_len > max_token_len:# 如果单行长度超过限制,将其分割为多个片段num_chunks = (line_len + token_len - 1) // token_lenfor i in range(num_chunks):start = i * token_lenend = start + token_len# 防止跨单词分割while not line[start:end].rstrip().isspace():start += 1end += 1if start >= line_len:breakcurr_chunk = curr_chunk[-cover_content:] + line[start:end]chunk_text.append(curr_chunk)start = (num_chunks - 1) * token_lencurr_chunk = curr_chunk[-cover_content:] + line[start:end]chunk_text.append(curr_chunk)elif curr_len + line_len <= token_len:# 当前片段长度未超过限制时,继续累加curr_chunk += line + '\n'curr_len += line_len + 1else:chunk_text.append(curr_chunk) # 保存当前片段curr_chunk = curr_chunk[-cover_content:] + linecurr_len = line_len + cover_contentif curr_chunk:chunk_text.append(curr_chunk)return chunk_text@classmethoddef read_file_content(cls, file_path: str):"""读取文件内容,根据文件类型选择不同的读取方式。:param file_path: 文件路径:return: 文件内容"""if file_path.endswith('.pdf'):return cls.read_pdf(file_path)elif file_path.endswith('.md'):return cls.read_markdown(file_path)elif file_path.endswith('.txt'):return cls.read_text(file_path)else:raise ValueError("Unsupported file type")@classmethoddef read_pdf(cls, file_path: str):"""读取 PDF 文件内容。:param file_path: PDF 文件路径:return: PDF 文件中的文本内容"""with open(file_path, 'rb') as file:reader = PyPDF2.PdfReader(file)text = ""for page_num in range(len(reader.pages)):text += reader.pages[page_num].extract_text()return text@classmethoddef read_markdown(cls, file_path: str):"""读取 Markdown 文件内容,并将其转换为纯文本。:param file_path: Markdown 文件路径:return: 纯文本内容"""with open(file_path, 'r', encoding='utf-8') as file:md_text = file.read()html_text = markdown.markdown(md_text)# 使用 BeautifulSoup 从 HTML 中提取纯文本soup = BeautifulSoup(html_text, 'html.parser')plain_text = soup.get_text()# 使用正则表达式移除网址链接text = re.sub(r'http\S+', '', plain_text) return text@classmethoddef read_text(cls, file_path: str):"""读取普通文本文件内容。:param file_path: 文本文件路径:return: 文件内容"""with open(file_path, 'r', encoding='utf-8') as file:return file.read()
- 测试运行
# 初始化 ReadFiles 类,指定文件目录路径
file_reader = ReadFiles(path="./data")# 获取目录下所有支持的文件类型
file_list = file_reader.get_files()
print("支持的文件列表:", file_list) # 支持的文件列表: ['./data\\凡人修仙传第一章.txt']# 将文件内容读取并分块
document_chunks = file_reader.get_content(max_token_len=600, cover_content=150)
# print("分块后的文档内容:", document_chunks)
print("分块后的文档分段长度:", len(document_chunks)) # 12
print(document_chunks[0])
'''
第一章山边小村二愣子睁大着双眼,直直望着茅草和烂泥糊成的黑屋顶,身上盖着的旧棉被,已呈深黄色,看不出原来的本来面目,还若有若无的散着淡淡的霉味。在他身边紧挨着的另一人,是二哥韩铸,酣睡的十分香甜,从他身上不时传来轻重不一的阵阵打呼声。离床大约半丈远的地方,是一堵黄泥糊成的土墙,因为时间过久,墙壁上裂开了几丝不起眼的细长口子,从这些裂纹中,隐隐约约的传来韩母唠唠叨叨的埋怨声,偶尔还掺杂着韩父,抽旱烟杆的“啪嗒”“啪嗒”吸允声。二愣子缓缓的闭上已有些涩的双目,迫使自己尽早进入深深的睡梦中。他心里非常清楚,再不老实入睡的话,明天就无法早起些了,也就无法和其他约好的同伴一起进山拣干柴。
'''
五 词向量数据库与向量检索模块
- 向量数据库用于存储文档片段及其对应的向量表示,而检索模块则根据用户提出的问题(Query)在数据库中检索相关的文档片段。通过这些功能,我们创建的简易 RAG 能够根据输入的查询快速找到最相关的文档片段。
向量数据库需要实现的关键功能:
- 获取向量表示(get_vector): 将文档转化为向量表示。
- 加载数据库(load_vector_content): 从本地文件加载已经存储的向量和文档。
- 持久化存储(persist): 将数据库存储到本地,便于下次加载使用。
- 检索(query): 根据用户的 Query,检索数据库中的相关文档片段。
- 创建基础的
VectorStore类,提供功能的框架,将文档片段转化为向量存储,加载本地数据库,进行检索。- get_vector 方法: 这个方法使用传入的 EmbeddingModel 对所有文档进行向量化,并将这些向量存储在 self.vectors 中。
- persist 方法: 该方法将文档片段及其向量表示保存到本地文件系统,便于持久化存储。
- load_vector_content 方法: 从本地文件系统加载已保存的文档片段和向量,供后续检索使用。
- get_similarity 方法: 计算两个向量之间的余弦相似度,用于比较查询和文档向量的相似度。
- query 方法: 接收用户输入的查询,通过向量化后在数据库中检索最相关的文档片段,并返回最匹配的文档。
class VectorStore:def __init__(self, document: List[str] = None) -> None:"""初始化向量存储类,存储文档和对应的向量表示。:param document: 文档列表,默认为空。"""if document is None:document = []self.document = document # 存储文档内容self.vectors = [] # 存储文档的向量表示def get_vector(self, EmbeddingModel: BaseEmbeddings) -> List[List[float]]:"""使用传入的 Embedding 模型将文档向量化。:param EmbeddingModel: 传入的用于生成向量的模型(需继承 BaseEmbeddings 类)。:return: 返回文档对应的向量列表。"""# 遍历所有文档,获取每个文档的向量表示self.vectors = [EmbeddingModel.get_embedding(doc) for doc in self.document]return self.vectorsdef persist(self, path: str = 'storage'):"""将文档和对应的向量表示持久化到本地目录中,以便后续加载使用。:param path: 存储路径,默认为 'storage'。"""if not os.path.exists(path):os.makedirs(path) # 如果路径不存在,创建路径# 保存向量为 numpy 文件np.save(os.path.join(path, 'vectors.npy'), self.vectors)# 将文档内容存储到文本文件中with open(os.path.join(path, 'documents.txt'), 'w') as f:for doc in self.document:f.write(f"{doc}\n")def load_vector_content(self, path: str = 'storage'):"""从本地加载之前保存的文档和向量数据。:param path: 存储路径,默认为 'storage'。"""# 加载保存的向量数据self.vectors = np.load(os.path.join(path, 'vectors.npy')).tolist()# 加载文档内容with open(os.path.join(path, 'documents.txt'), 'r') as f:self.document = [line.strip() for line in f.readlines()]def get_similarity(self, vector1: List[float], vector2: List[float]) -> float:"""计算两个向量的余弦相似度。:param vector1: 第一个向量。:param vector2: 第二个向量。:return: 返回两个向量的余弦相似度,范围从 -1 到 1。"""dot_product = np.dot(vector1, vector2)magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2)if not magnitude:return 0return dot_product / magnitudedef query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:"""根据用户的查询文本,检索最相关的文档片段。:param query: 用户的查询文本。:param EmbeddingModel: 用于将查询向量化的嵌入模型。:param k: 返回最相似的文档数量,默认为 1。:return: 返回最相似的文档列表。"""# 将查询文本向量化query_vector = EmbeddingModel.get_embedding(query)# 计算查询向量与每个文档向量的相似度similarities = [self.get_similarity(query_vector, vector) for vector in self.vectors]# 获取相似度最高的 k 个文档索引 默认为1top_k_indices = np.argsort(similarities)[-k:][::-1]# 返回对应的文档内容return [self.document[idx] for idx in top_k_indices]
- 测试用例
# 初始化文档列表
documents = ["机器学习是人工智能的一个分支。","深度学习是一种特殊的机器学习方法。","监督学习是一种训练模型的方式。","强化学习通过奖励和惩罚进行学习。","无监督学习不依赖标签数据。",
]# 创建向量数据库
vector_store = VectorStore(document=documents)# 使用 OpenAI Embedding 模型对文档进行向量化
embedding_model = OpenAIEmbedding()# 获取文档向量并存储
vector_store.get_vector(embedding_model)# 持久化存储到本地
vector_store.persist('storage')# 模拟用户查询
query = "什么是深度学习?"
result = vector_store.query(query, embedding_model)print("检索结果:", result)
# 检索结果: ['深度学习是一种特殊的机器学习方法。']
六 大模型问答模块
- 大模型模块,用于根据检索到的相关文档片段生成对用户问题的回答。为了简化和便于扩展,先实现一个基类
BaseModel类,再以 GPT4o 模型为例,使用大语言模型来完成问答任务。
6.1 BaseModel类
基类BaseModel,它包含两个主要方法:
chat:负责处理用户的输入并生成回答。load_model:如果使用本地模型,加载模型。如果使用 API 模型(如 OpenAI),可以不实现。
class BaseModel:"""基础模型类,作为所有模型的基类。包含一些通用的接口,如加载模型、生成回答等。"""def __init__(self, path: str = '') -> None:self.path = path # 用于存储模型文件的路径,默认为空。def chat(self, prompt: str, history: List[dict], content: str) -> str:"""使用模型生成回答的抽象方法。:param prompt: 用户的提问内容:param history: 之前的对话历史(字典列表):param content: 提供的上下文内容:return: 模型生成的答案"""pass # 具体的实现由子类提供def load_model(self):"""加载模型的方法,通常用于本地模型。"""pass # 如果是 API 模型,可能不需要实现
6.2 GPT4o模型对话子类
class GPT4oChat(BaseModel):"""基于 GPT-4o 模型的对话类,继承自 BaseModel。主要用于通过 OpenAI API 来生成对话回答。"""def __init__(self, api_key: str, base_url: str = "https://api.openai-hk.com/v1") -> None:"""初始化 GPT-4o 模型。:param api_key: OpenAI API 的密钥:param base_url: 用于访问 OpenAI API 的基础 URL,默认为代理 URL"""super().__init__()self.client = OpenAI(api_key=api_key, base_url=base_url) # 初始化 OpenAI 客户端def chat(self, prompt: str, history: List = [], content: str = '') -> str:"""使用 GPT-4o 生成回答。:param prompt: 用户的提问:param history: 之前的对话历史(可选):param content: 可参考的上下文信息(可选):return: 生成的回答"""# 构建包含问题和上下文的完整提示full_prompt = PROMPT_TEMPLATE['GPT4o_PROMPT_TEMPLATE'].format(question=prompt, context=content)# 调用 GPT-4o 模型进行推理response = self.client.chat.completions.create(model="gpt-4o-mini", # 使用 GPT-4o 小型模型messages=[{"role": "user", "content": full_prompt}])# 返回模型生成的第一个回答return response.choices[0].message.content# 提示词模板 方便维护和复用提示语,可以使用一个字典来保存不同模型的提示模板
PROMPT_TEMPLATE = dict(GPT4o_PROMPT_TEMPLATE="""下面有一个或许与这个问题相关的参考段落,若你觉得参考段落能和问题相关,则先总结参考段落的内容。若你觉得参考段落和问题无关,则使用你自己的原始知识来回答用户的问题,并且总是使用中文来进行回答。问题: {question}可参考的上下文:···{context}···有用的回答:"""
)
七 RAG完整使用
7.1 简单使用测试
# 加载并切分文档
docs = ReadFiles('./data').get_content(max_token_len=600, cover_content=150)
vector = VectorStore(docs)# 使用 OpenAI Embedding 模型进行向量化
embedding = OpenAIEmbedding()
vector.get_vector(EmbeddingModel=embedding)# 用户提出问题
question = '韩立有兄弟姐妹吗?'# 在数据库中检索最相关的文档片段
content = vector.query(question, EmbeddingModel=embedding, k=1)[0]
print(content)# 使用 GPT4oChat 模型生成答案
chat = GPT4oChat(api_key = os.getenv("OPENAI_API_KEY")) # 传入 OpenAI API 密钥
print(chat.chat(question, [], content))
- 输出结果:
“二愣子”好听了哪里去。
因此,韩立虽然并不喜欢这个称呼,但也只能这样一直的自我安慰着。
韩立外表长得很不起眼,皮肤黑黑的,就是一个普通的农家小孩模样。但他的内心深处,却比同龄人早熟了许多,他从小就向往外面世界的富饶繁华,梦想有一天,他能走出这个巴掌大的村子,去看看老张叔经常所说的外面世界。
当韩立的这个想法,一直没敢和其他人说起过。否则,一定会使村里人感到愕然,一个乳臭未干的小屁孩,竟然会有这么一个大人也不敢轻易想的念头。要知道,其他同韩立差不多大的小孩,都还只会满村的追鸡摸狗,更别说会有离开故土,这么一个古怪的念头。
韩立一家七口人,有两个兄长,一个姐姐,还有一个小妹,他在家里排行老四,今年刚十岁,家里的生活很清苦,一年也吃不上几顿带荤腥的饭菜,全家人一直在温饱线上徘徊着。
参考段落提到,韩立一家有七口人,韩立有两个兄长,一个姐姐和一个小妹,他在家里排行老四。因此可以确定,韩立有兄弟姐妹。
7.2 完整版使用测试
# 完整函数封装
def run_mini_rag(question: str, knowledge_base_path: str, k: int = 1) -> str:"""运行一个简化版的RAG项目。:param question: 用户提出的问题:param knowledge_base_path: 知识库的路径,包含文档的文件夹路径:param api_key: OpenAI API密钥,用于调用GPT-4o模型:param k: 返回与问题最相关的k个文档片段,默认为1:return: 返回GPT-4o模型生成的回答"""api_key = os.getenv("OPENAI_API_KEY")# 1. 加载并切分文档docs = ReadFiles(knowledge_base_path).get_content(max_token_len=600, cover_content=150)vector = VectorStore(docs)# 2. 使用 OpenAI Embedding 模型进行向量化embedding = OpenAIEmbedding()vector.get_vector(EmbeddingModel=embedding)# 3. 将向量和文档保存到本地(可选)vector.persist(path='storage')# 4. 在数据库中检索最相关的文档片段content = vector.query(question, EmbeddingModel=embedding, k=k)[0]# 5. 使用 GPT-4o 生成答案chat = GPT4oChat(api_key=api_key)answer = chat.chat(question, [], content)return answer# 测试运行
question = '韩立有兄弟姐妹吗?'
knowledge_base_path = './data'
answer = run_mini_rag(question, knowledge_base_path)
display(Markdown(answer))
- 测试运行结果:
参考段落提到韩立一家有七口人,包括两个兄长、一个姐姐和一个小妹,韩立在家中排行老四。因此,韩立确实有兄弟姐妹。