Redis String全方位指南:命令、编码、时间复杂度与应用场景
前言
Redis 作为一个高性能的键值数据库,其核心在于提供了丰富的数据类型来满足各种业务场景的需求。在所有数据类型中,String(字符串)是最基础也是最核心的一种。无论是简单的键值缓存,还是复杂的计数器、分布式锁,都离不开 String 类型的支持。本文将深入探讨 Redis 中 String 类型的底层原理、常用命令以及多样化的应用场景,帮助你彻底掌握这一关键数据结构,为高效使用 Redis 打下坚实的基础。
redis所有的key都是字符串
value的类型都是存在差异的
redis中的字符串,直接就是按照二进制的方式存储的
(不会做任何的编码转换,存的是啥,取出来的就是啥)
JSON、xml、二进制数据(音频、视频、图片)
音视频的大小体积可能比较大
redis对于string类型限制了最大的大小是512MB
redis单线程模型,希望进行的操作都能比较快速
Mysql默认的字符集是拉丁文,插入中文就会失败的
但是redis不会出现这种情况的,存啥形式取出来的就是啥
一般来说redis遇到乱码问题的概率较小
set 和get
set格式
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]
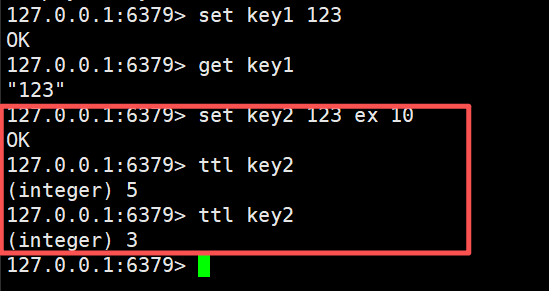
通过一个命令创建键值对并且设置超时时间
set key value ex 10转换为
set key value 创建键值对
expire key 10 设置过期时间为10
除了上面使用ex设置超时时间为秒
还可以使用px设置超时时间为毫秒
set key value px 10
后面的
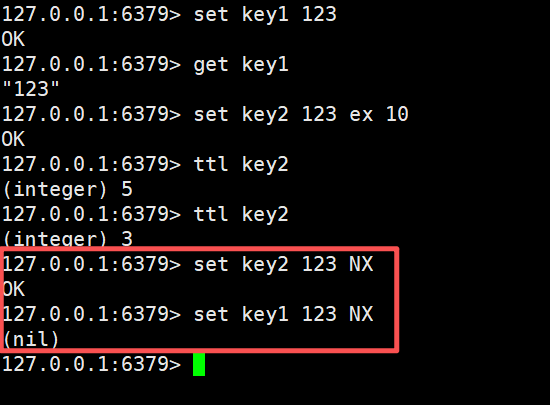
NX和XXNX表示的是如果Key不存在的话,才设置
如果key存在的话,则不设置(返回nil)XX则相反
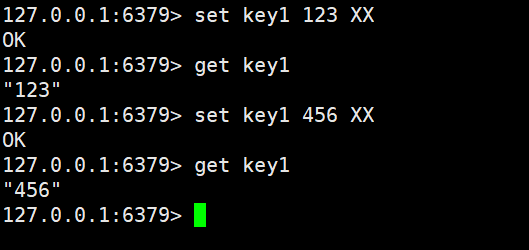
如果key存在才设置(相当于更新key的value,可能会更改原来的数据类型,原来的key的ttl(生存时间)也会失效的)
如果key不存在的话,则不设置(返回nil)这里的两个选项是互斥的,所以二者只能存在一个
redis文档说明
[]相当于一个独立的单元,表示选项(可有可无)
其中的 | 表示或者的意思,多个只能出现一个
一次性将命令完成,这样可以减少网络开销
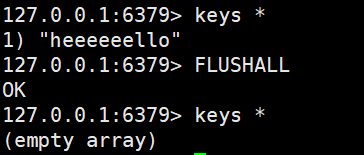
删库命令,将redis上所有的键值对都删除
FLUSHALL
在后面加上NX,如果不存在的话才进行设置,如果存在的话就返回nil
这里我们的key2已经消失了,因为我们上面设置了过期时间了
这里在后面加上XX,如果key存在的话就进行value的更新
对于GET来说,只是支持字符串类型的value
如果value是其他的类型的话,使用GET获取就会出错了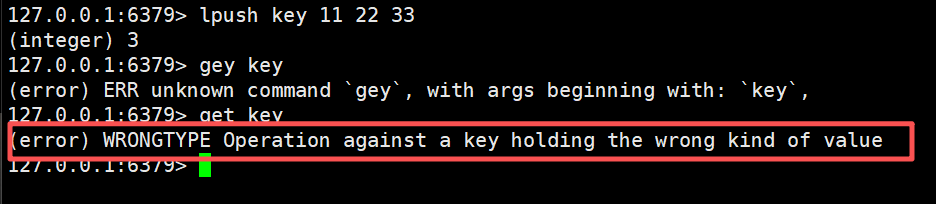
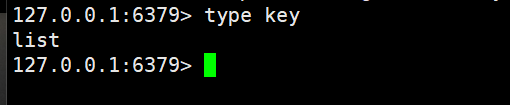
我们这里的key类型是list,所以我们这里使用GET是不能获取value的
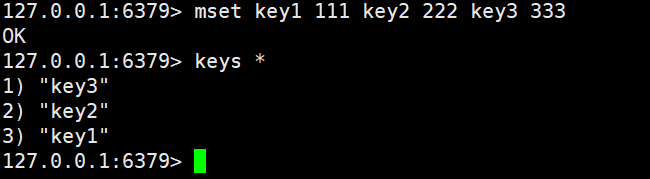
mset 和mget
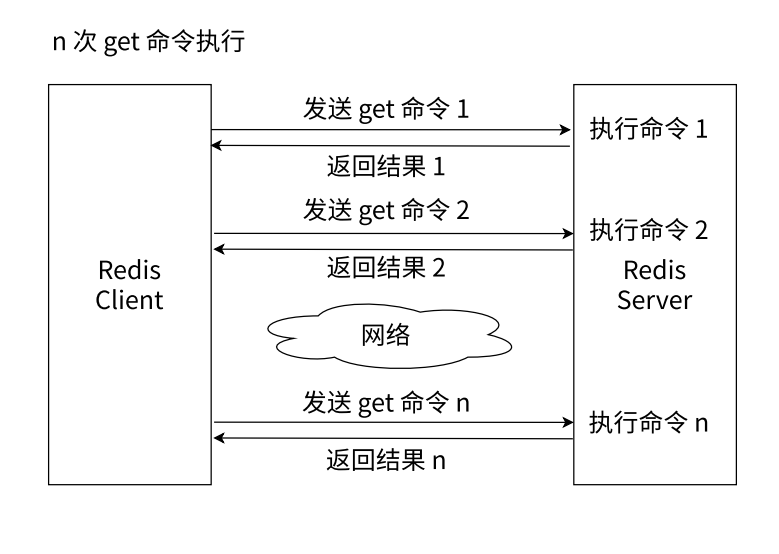
一次可以操作多组键值对的
执行N次get命令会进行多次网络传输的
执行一次get命令的话只进行一次get传输的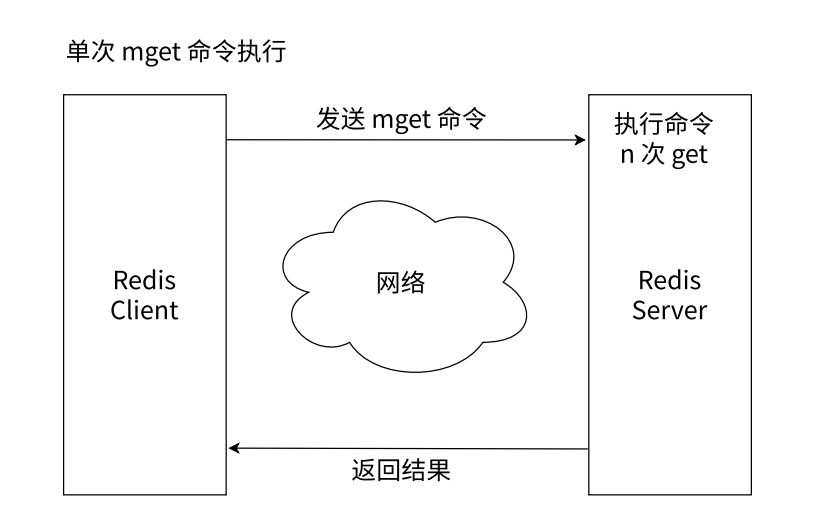
MSET key value [key value ...]
一次性创建多个键值对
虽然可以设置多个键值对,但是不要太多了,如果这个命令执行时间太长了的话,会造成阻塞其他的命令
使用mget可以一次查询多个key的value的值
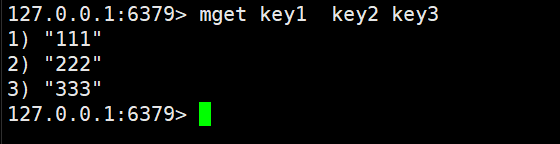
时间复杂度是O(N)
这个N是key的数量
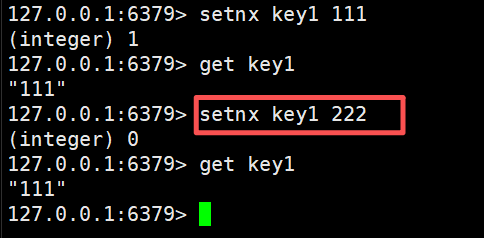
SETNX 、SETEX、PSETEX
SETNX 不存在才能设置,存在则设置失败
被框出来的这个命令没有生效,因为key1的值是没有改变的
setex的使用方法
setex key time value
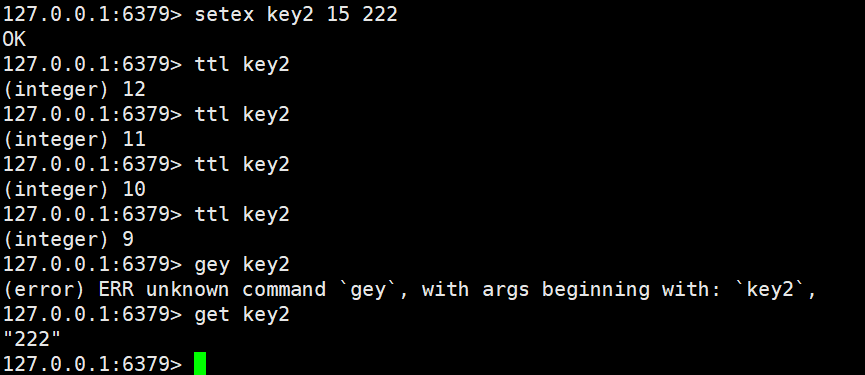
setex和psetex都是设置key的过期时间,前者的单位是秒,后者的单位是毫秒
上面都是针对set的一些常见用法,进行了缩写
这样使用者的门槛就越低了
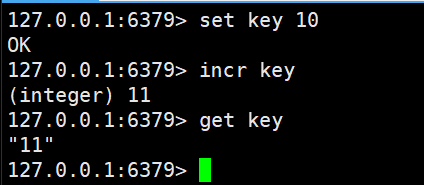
incr和incrby
incr 针对value+1
#此时key对应的value必须是整数,进行这个命令后的返回值是+1后的值incrby 针对value+n
#此时key对应的value必须是整数,进行这个命令后的返回值是+n后的值
如果value不是整数的话,这里进行incr的话会出现报错的
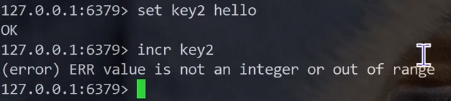
小数也是不行的,也是会出现报错的

并且如果值过大的话也是会报错的

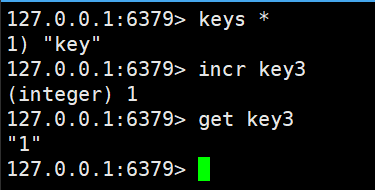
我们这里原本是没有key3的,然后使用incr key3
incr操作的Key如果是不存在的话,就会将这个key的value当做0
针对某个key的value加上n,返回加上后的值
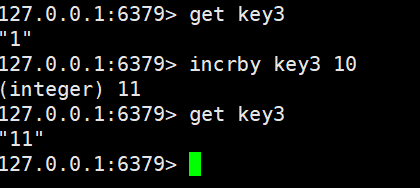
incrby加上正数和负数都是可以的
decr 、decrby 和incrbyfloat
decr 针对value-1decrby 针对value-nincrbyfloat 针对value +/- 小数
key对应的value必须是整数,在64位的范围内,如果这个Key对应的value不存在,都是当做0的
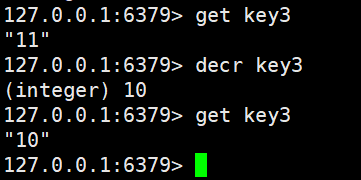
这个操作方法和incr一样的
incrbyfloat针对浮点数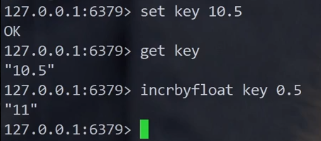

append
如果Key已经存在并且是一个string,命令会将value追加到原有string的后边,如果Key不存在,则效果等同于SET命令创建一个新的键值对
append key value
返回值是追加完字符串的长度
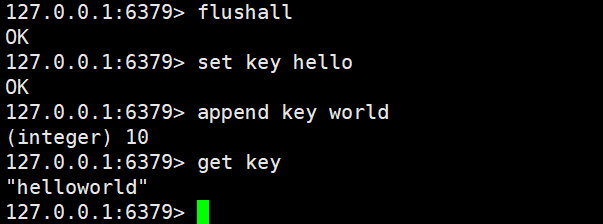
在已经存在的Key后面追加一个字符串
如果不存在对应的key的话就会新建一个键值对
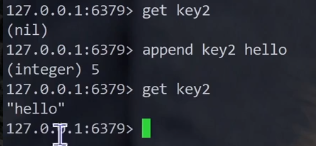
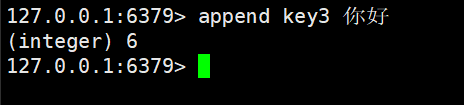
这里返回的是6个字节
append返回值,长度的单位是字节
redis的字符串,不户籍对字符编码做任何处理(redis不认识字符,只认识字节)
当前xshell终端,默认的字符编码是utf8
在终端输入汉字之后,也是按照utf8编码的
一个汉字在utf8字符集中,通常是3个字节的
这里我们使用get查看key3的内容
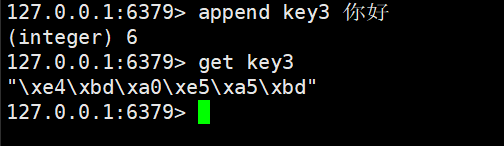
- 返回
"\xe4\xbd\xa0\xe5\xa5\xbd"→ 这是你好的 UTF-8 字节序列的转义表示。
那么我们如何在使用get查看的时候,显示的是中文呢?
那么我们得在启动redis客户端的时候,加上一个 --raw这样的选项
就可以使redis客户端能够自动的把二进制数据尝试翻译了
getrange
在C++中的std::string substr
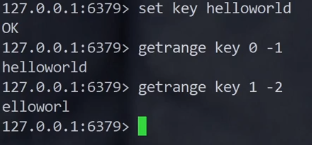
返回key对应的子串,由start和end确定(左闭右闭)
getrange key start end
redis中指定的区间是闭区间
redis的下标是可以支持负数的
-1倒数第一个元素
下标为len-1的元素
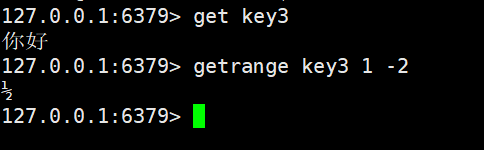
但是如果是汉字的话,那么此时进行子串切分,我们查询到的可能就不准了

setrange
将范围中的子串进行修改
setrange key offset value
offset表示的是偏移量,从第几个字节开始进行替换的
value表示的是替换的字符
结束就看value的长度了
从第4个字符开始进行更新字符串,更新为qq
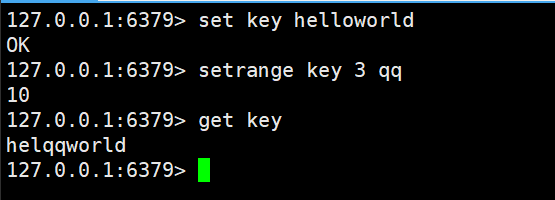
返回值是替换之后新的字符串的长度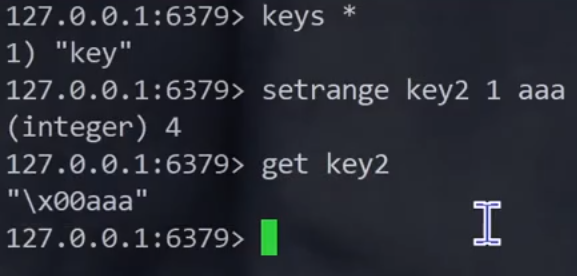
\x表示当前是一个16进制的数字
凭空生成一个字节,这个字节里面的内容就是0x00
aaa就被追加到了0x00的后面了
setrange针对不存在的key也是可以操作的,不过会把offset之前的内容填充乘0x00的
strlen
获取字符串的长度的,单位是字节
strlen key
如果key中存放的类型不是key的话就会报错的

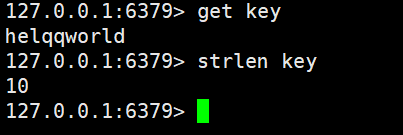
返回的是key的长度,如果key不存在的话,返回0
命令总结
好的,这是根据图片内容生成的表格:
| 命令 | 执行效果 | 时间复杂度 |
|---|---|---|
| set key value [key value…] | 设置 key 的值是 value | O(k), k 是键个数 |
| get key | 获取 key 的值 | O(1) |
| del key [key …] | 删除指定的 key | O(k), k 是键个数 |
| mset key value [key value …] | 批量设置指定的 key 和 value | O(k), k 是键个数 |
| mget key [key …] | 批量获取 key 的值 | O(k), k 是键个数 |
| incr key | 指定的 key 的值 +1 | O(1) |
| decr key | 指定的 key 的值 -1 | O(1) |
| incrby key n | 指定的 key 的值 +n | O(1) |
| decrby key n | 指定的 key 的值 -n | O(1) |
| incrbyfloat key n | 指定的 key 的值 +n | O(1) |
| append key value | 指定的 key 的值追加 value | O(1) |
| strlen key | 获取指定 key 的值的长度 | O(1) |
| setrange key offset value | 覆盖指定 key 的从 offset 开始的部分值 | O(n), n 是字符串长度, 通常视为 O(1) |
| getrange key start end | 获取指定 key 的从 start 到 end 的部分值 | O(n), n 是字符串长度, 通常视为 O(1) |
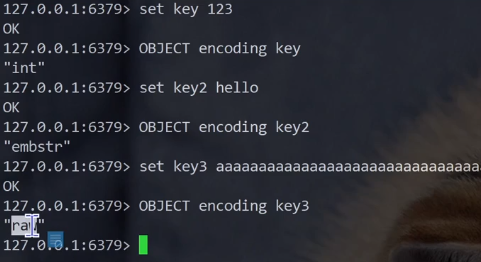
string内部编码方式
字符串类型的内部编码有3种
- int:8个字节的长整形
- embstr:小于等于39个字节的字符串(压缩字符串)
- raw:大于39个字节的字符串(普通字符串)
redis会根据当前值的类型和长度动态决定使用哪种内部编码实现
我们可以使用命令查看对应key的编码方式
object encoding key
开源的组件,往往考虑的是通用型,大厂的话可能会遇到一些极端的业务场景,往往就需要根据当前的极端业务,针对上述的开源组件进行定制化
使用redis存储小数的时候,显示的编码格式是embstr,本质上还是当做字符串来存储的
string类型应用场景
作为缓存
整体的思路:应用服务器访问数据的时候,先查询redis,如果redis存在该数据,就直接取数据交给应用服务器,不继续访问数据库了
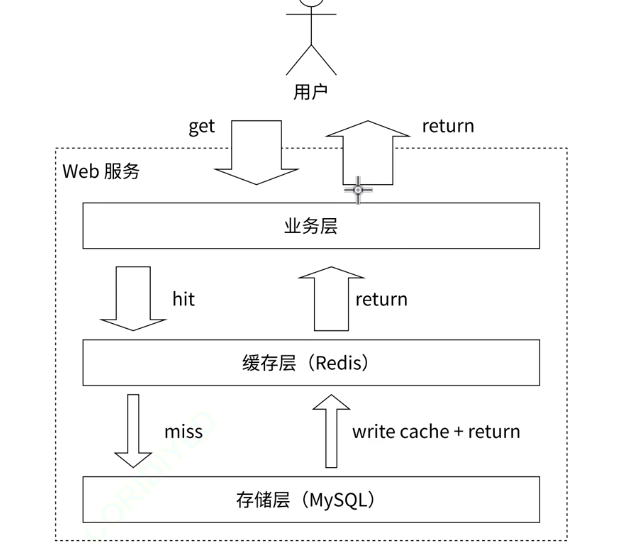
如果redis上数据不存在的话,再去去读mysql,把读到的结构,返回给应用服务器,同时,把这个数据也写到redis中
redis这样的缓存,经常来存储热点数据
高频被使用的数据,这个定义方式结合业务场景有很多种方式
这就相当于将最近使用到的数据作为热点数据
上述策略存在一个明显的问题,随着时间的推移,肯定会有越来越多的Key在redis上访问不到,从而从mysql中去读并写入redis了,此时redis中的数据不是越来越多了么
解决方案
1、在把数据写给redis的同时,给这个key设置一个过期时间
2、redis也在内存不足的时候,提供了淘汰策略
计数功能
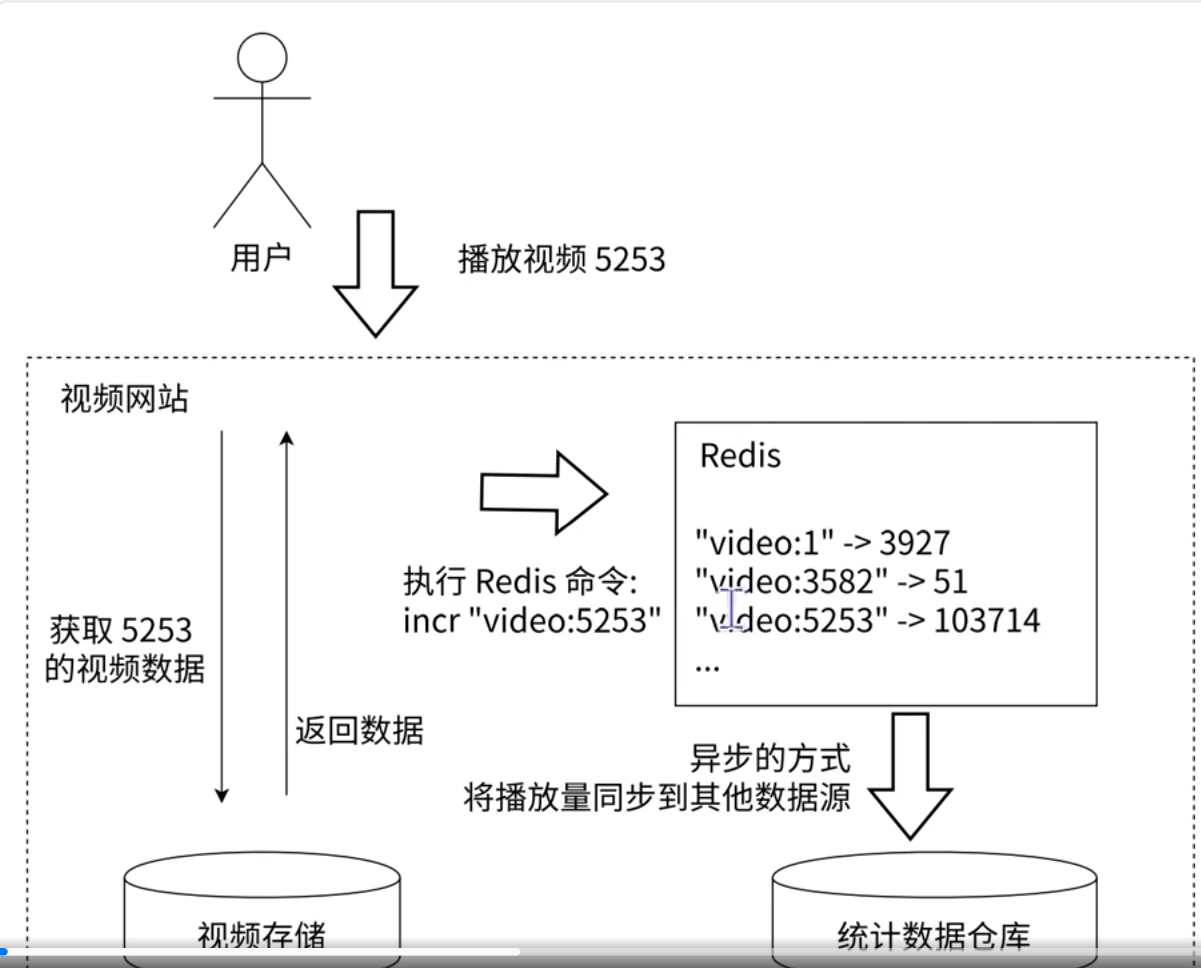
通过redis统计到数据,然后给其他统计数据仓库进行数据的统计
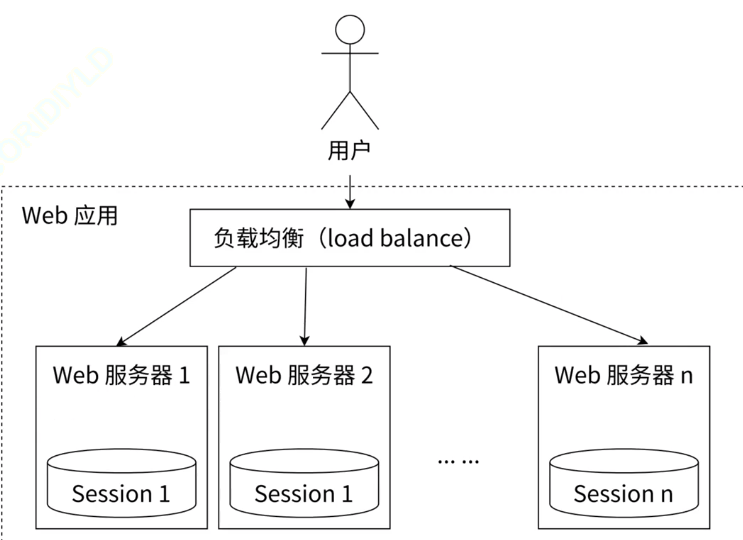
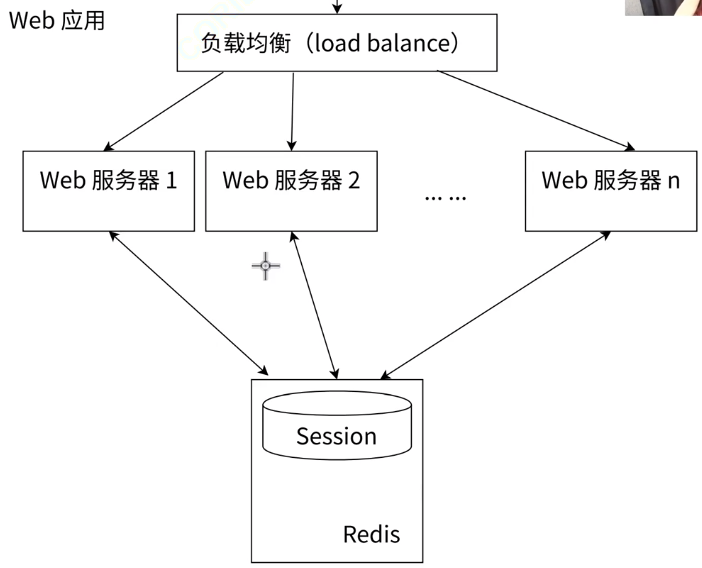
共享对话

手机验证码
在当今的互联网应用中,手机验证码是验证用户身份、确保账户安全的重要环节。利用 Redis 的 String 类型,我们可以轻松、高效地实现这一功能。
其核心思路是:
-
当用户请求发送验证码时,后端服务器会生成一个随机的数字(例如6位数)。
-
将用户的手机号作为 key,生成的随机验证码作为 value,存入 Redis 中。
-
同时,为这个 key 设置一个较短的过期时间,例如 5 分钟。这可以通过 SETEX 命令或者 SET 命令配合 EX 选项一步完成,确保了操作的原子性。
示例命令:
codeBash
# 设置手机号为 188xxxxxxxx 的验证码为 123456,并设置5分钟(300秒)后过期
SETEX 188xxxxxxxx 300 123456
当用户输入验证码进行校验时,服务器只需从 Redis 中根据手机号这个 key 来获取 value,并与用户提交的验证码进行比对。
-
如果能获取到值,并且与用户输入的一致,则验证通过。
-
如果获取不到值(返回 nil),则说明验证码已经过期或不存在,验证失败。
使用 Redis 存储手机验证码的优势:
-
高性能:Redis 基于内存操作,读写速度极快,可以轻松应对高并发的验证码请求。
-
自带过期策略:使用 SETEX 或 EX 选项可以非常方便地管理验证码的生命周期,无需手动删除,有效节约了存储空间并简化了业务逻辑。
-
简化数据库压力:将验证码这类临时性、高频读写的数据从关系型数据库(如 MySQL)中剥离出来,可以显著降低主数据库的负载。
总结
本文详细介绍了 Redis 中最基础、最核心的 String 数据类型。我们了解到,Redis 的 key 均为字符串,而 String 类型的 value 以二进制安全的方式存储,不会进行任何编码转换,这使其能够存储包括 JSON、图片、音视频在内的任意二进制数据,最大支持 512MB。
核心命令回顾:
-
基础操作:SET 和 GET 是最基本的读写命令,而 MSET 和 MGET 提供了批量操作的能力,能有效减少网络开销。
-
原子操作与选项:SET 命令的 NX(不存在才设置)和 XX(存在才设置)选项,以及 SETNX、SETEX 等命令,为实现分布式锁、缓存管理等功能提供了原子性保障。
-
计数器功能:INCR、DECR、INCRBY 等一系列命令使 String 类型可以作为高性能的原子计数器使用,且能处理整数和浮点数。
-
字符串处理:APPEND、GETRANGE、SETRANGE 和 STRLEN 等命令提供了对字符串值进行追加、截取、覆盖和长度计算等细粒度操作的能力。
内部编码:
Redis 会根据存储内容和长度,动态选择 int、embstr 或 raw 三种内部编码方式,以优化内存使用和执行效率。
典型应用场景:
最后,我们探讨了 String 类型的四大典型应用场景:
-
数据缓存:作为热点数据的缓存层,降低后端数据库压力。
-
计数功能:适用于文章阅读量、用户点赞数等统计场景。
-
共享会话(Session):在分布式系统中存储和共享用户登录信息。
-
手机验证码:利用其高性能和过期策略,安全、高效地处理临时验证信息。
总而言之,深入理解并熟练运用 String 类型是精通 Redis 的基石,其灵活性和高性能使其在各种技术方案中都扮演着不可或缺的角色。