SpringBoot 整合 Langchain4j RAG 技术深度使用解析
目录
一、前言
二、Langchain4j RAG介绍
2.1 什么是LangChain4j
2.2 LangChain4j RAG技术介绍
2.2.1 RAG技术原理
2.2.2 LangChain4j中的RAG实现
2.2.3 LangChain4j RAG技术优势
2.2.4 LangChain4j RAG技术应用场景
三、LangChain4j RAG 技术深度使用
3.1 文档加载与解析过程
3.2 文档加载器介绍
3.2.1 加载文档案例
3.3 文档解析器介绍
3.3.1 文档解析器案例
3.4 文档分割介绍
3.4.1 常用的文档分割器
3.4.2 向量转换与向量存储
3.4.3 案例操作代码
3.4.4 自定义文档分割
3.5 向量模型与向量存储
3.5.1 前置准备
3.5.2 文本向量化演示
3.6 基于Redis实现向量数据的存储与检索
3.6.1 搭建Redis向量数据库
3.6.2 添加依赖
3.6.3 添加配置文件
3.6.4 添加自定义EmbeddingStore
3.6.5 改造Assistant
3.6.6 增加测试接口
四、写在文末
一、前言
LangChain 是一个强大的框架,旨在简化构建基于大型语言模型(LLMs)的应用程序的过程。在 LangChain 中,RAG(Retrieval-Augmented Generation)技术是一种结合检索增强生成的方法,它通过将外部数据检索技术与生成式人工智能相结合,来提高生成文本的准确性和相关性。
尽管AI大模型在自然语言处理任务中表现出色,但仍然存在一些局限性。而RAG - 检索增强生成技术,则很好的弥补了这些不足。举例来说,如果企业或个人都希望拥有一款属于自己的AI助手,能够帮自己随时解决一些特定场景或特定领域的问题,很明显,这些领域的知识和内容都不是互联网上面可以搜到的。
在这种场景下,AI大模型中RAG技术就派上用场了,简单来说,它就是一款可以问你量身打造的大模型知识库,当你需要某个知识的时候为你提供更贴合实际业务场景的回答。本篇将深入探讨Langchain4j 中的RAG技术。
二、Langchain4j RAG介绍
2.1 什么是LangChain4j
LangChain4j 是一个专注于AI大模型集成的开源库,近年来受到了广泛关注。它旨在为开发者提供一种简单且高效的方式来接入和利用各种AI大模型,从而提升应用程序的智能化水平。LangChain4j的核心优势在于其高度的灵活性和易用性,使得开发者可以在不改变现有架构的前提下,快速实现AI功能的集成。
开发者文档:Introduction | LangChain4j

2.2 LangChain4j RAG技术介绍
LangChain4j 的 RAG(Retrieval-Augmented Generation,检索增强生成)技术是一种将信息检索与生成式大模型相结合的智能问答系统构建方法,旨在通过检索外部知识库来增强大模型的回答准确性和时效性。
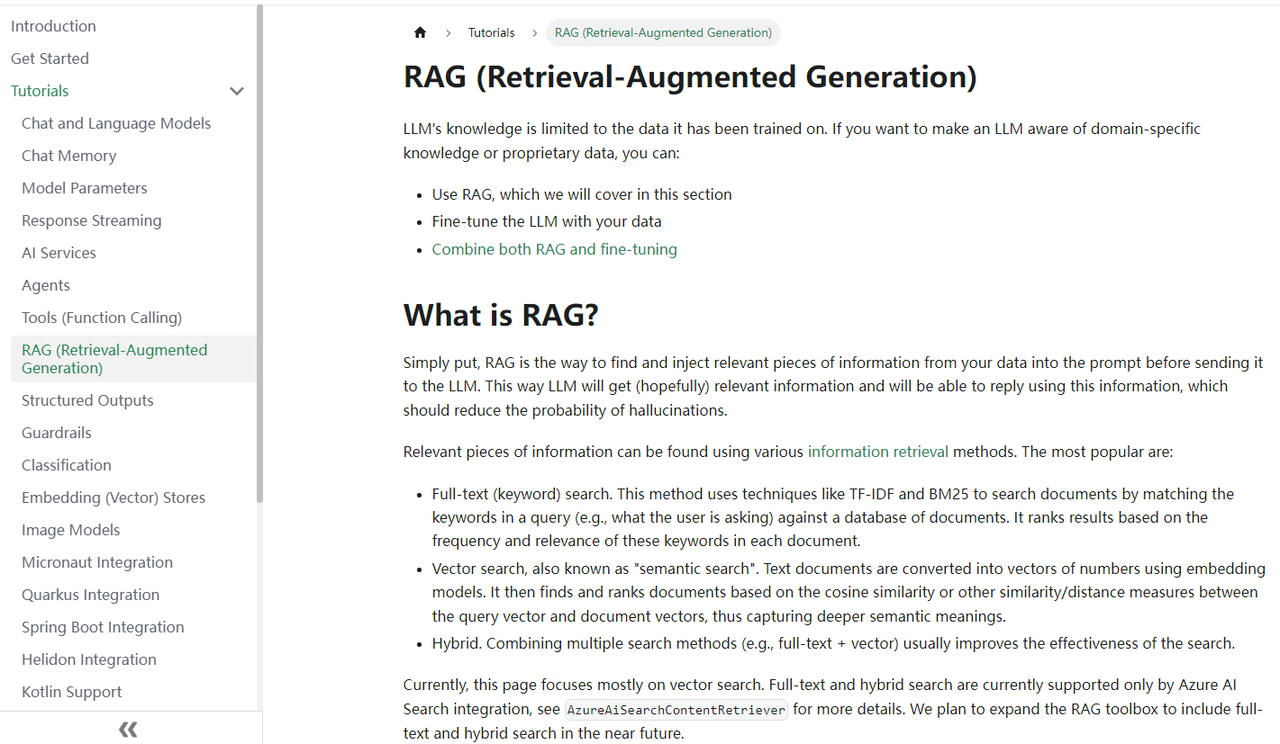
2.2.1 RAG技术原理
RAG技术的核心思想是在将数据发送给大模型之前,先从外部知识库中检索相关信息,并将这些信息注入到提示(prompt)中,使大模型在生成回答时能够利用这些检索到的信息,从而降低幻觉(即生成不准确或无关信息)的可能性。这一过程通常包括两个主要阶段:
1)索引阶段
对文档进行预处理,以便在检索阶段实现高效搜索。这一步骤可能包括清理文档、去除噪音数据、统一格式、使用额外数据及元数据增强文档(如增加文档来源、时间戳、作者等辅助信息)、分块(将长文档分割为更小的语义单元,以适配嵌入模型的上下文窗口限制)、向量化(使用嵌入模型将文本块转换为向量)以及向量存储(将向量存储到向量数据库中)。
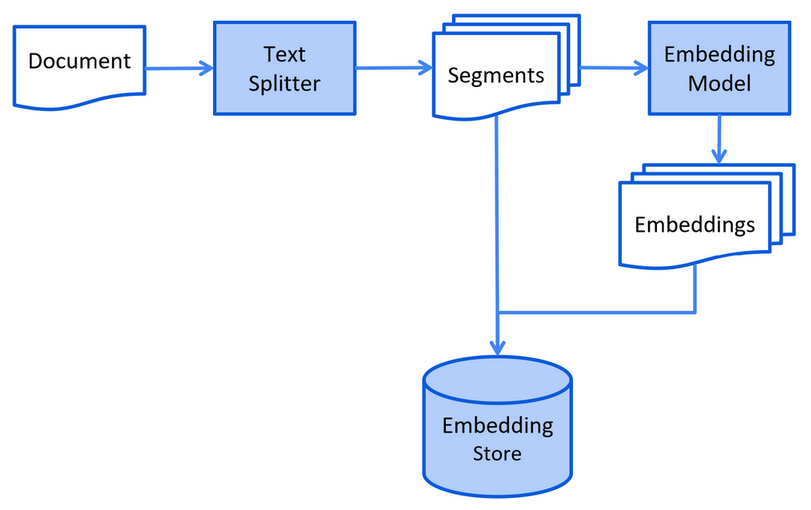
2)检索阶段
当用户提交一个问题时,系统将该问题嵌入到向量表示中,并在嵌入存储库中执行相似性搜索,找到与问题最相关的文档片段。然后,将这些相关片段注入到提示中,并发送给大模型进行生成式回答。
2.2.2 LangChain4j中的RAG实现
LangChain4j是一个Java版本的LangChain实现,提供了构建RAG应用的工具链。其核心组件包括:
-
文档加载与处理
-
支持从多种来源加载文档(文件、网页、数据库等)
-
文档分割器将大文档切分为小片段
-
嵌入模型(Embedding Model)将文本转换为向量
-
-
向量存储
-
支持多种向量数据库(如Azure AI Search、Chroma、Elasticsearch等)
-
存储文档嵌入向量以便高效检索
-
-
检索器
-
根据用户查询从向量库中检索最相关的文档片段
-
支持相似度搜索和混合搜索策略
-
-
生成模型
-
集成大语言模型(如OpenAI、DeepSeek等)
-
将检索到的内容与用户问题结合生成最终回答
-
2.2.3 LangChain4j RAG技术优势
LangChain4j 的RAG实现具有如下优势:
-
提高回答准确性:
-
通过检索外部知识库,RAG技术能够为大模型提供更丰富的上下文信息,从而生成更准确的回答。
-
-
降低幻觉:
-
由于大模型在生成回答时能够利用检索到的信息,因此降低了生成不准确或无关信息的可能性。
-
-
灵活性和可定制性:
-
LangChain4j提供了丰富的工具和API,允许用户根据自己的需求进行定制和优化。例如,用户可以选择不同的嵌入模型、向量存储方式以及检索算法等。
-
-
易于上手:
-
通过Easy RAG功能,初学者可以快速上手RAG技术,而无需深入了解其背后的复杂细节。
-
2.2.4 LangChain4j RAG技术应用场景
LangChain4j RAG技术具有丰富的应用场景,具体来说包括:
-
智能问答系统:
-
利用RAG技术构建智能问答系统,能够回答用户关于特定领域的问题,提供准确和有用的信息。
-
-
知识库更新频繁的场景:
-
对于知识库更新频繁的场景(如外部客服、新闻资讯等),RAG技术能够随时引用最新文档,确保回答的时效性和准确性。
-
-
私有知识库应用:
-
对于公司内部的私有数据,为了数据安全、商业利益考虑,不能放到互联网上的数据。RAG技术能够基于这部分私有的知识进行回答,满足企业的特定需求。
-
三、LangChain4j RAG 技术深度使用
3.1 文档加载与解析过程
在前面讲解RAG技术原理时,通过下图不难看出,最终要实现结合大模型完成RAG 的流程,需要先对文档完成下面几个核心步骤:
-
加载知识库文档
-
文档中文本内容分段
-
利用向量大模型将分段后的文本转换成向量
-
将向量存入向量数据库
一句话总结就是,在这个阶段要做的就是:将文档的文本内容向量化存储数据库
3.2 文档加载器介绍
顾名思义,就是一个文档加载的组件,可以将系统的文档资源进行解析并加载,常用的文档加载器如下:
-
langchain4j 模块的文件系统文档加载器(FileSystemDocumentLoader)
-
langchain4j 模块的类路径文档加载器(ClassPathDocumentLoader)
-
langchain4j 模块的网址文档加载器(UrlDocumentLoader)
-
langchain4j-document-loader-amazon-s3 模块的亚马逊 S3 文档加载器(AmazonS3DocumentLoader)
-
langchain4j-document-loader-azure-storage-blob 模块的 Azure Blob 存储文档加载器(AzureBlobStorageDocumentLoader)
-
langchain4j-document-loader-github 模块的 GitHub 文档加载器(GitHubDocumentLoader)
-
langchain4j-document-loader-google-cloud-storage 模块的谷歌云存储文档加载器(GoogleCloudStorageDocumentLoader)
-
langchain4j-document-loader-selenium 模块的 Selenium 文档加载器(SeleniumDocumentLoader)
-
langchain4j-document-loader-tencent-cos 模块的腾讯云对象存储文档加载器(TencentCosDocumentLoader)
3.2.1 加载文档案例
在下面这段测试代码中,通过FileSystemDocumentLoader这个默认的文件系统文档加载器,加载本地的一个文档
package com.congge.test;import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
public class RagTest {@Testpublic void testReadDocument() {String path = "D:\\data\\RAG.txt";//使用FileSystemDocumentLoader读取指定目录下的知识库文档//并使用默认的文档解析器TextDocumentParser对文档进行解析Document document = FileSystemDocumentLoader.loadDocument(path);System.out.println(document.text());}}运行上面的代码,通过控制台输出,可以看到本地的文档内容被加载出来
基于默认的文档加载器,还有其他的用法,这里一并汇总如下:
// 加载单个文档
Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/file.txt", new
TextDocumentParser()); // 从一个目录中加载所有文档,适合批量处理的情况
List<Document> documents = FileSystemDocumentLoader.loadDocuments("E:/knowledge", new
TextDocumentParser()); // 从一个目录中加载所有的.txt文档 ,适合批量处理的情况
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.txt");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("E:/knowledge",
pathMatcher, new TextDocumentParser()); // 从一个目录及其子目录中加载所有文档 ,适合批量处理的情况
List<Document> documents =
FileSystemDocumentLoader.loadDocumentsRecursively("E:/knowledge", new
TextDocumentParser());3.3 文档解析器介绍
文档加载进来之后,需要对文档的内容进行解析。在实际应用中,文档的格式会非常多,比如PDF、DOC、TXT 等等。为了解析这些不同格式的文件,有一个 “文档解析器”(DocumentParser)接口,并且我们的库中包含了该接口的几种实现方式:
-
langchain4j 模块的文本文档解析器(TextDocumentParser),它能够解析纯文本格式的文件(例如 TXT、HTML、MD 等)。
-
langchain4j-document-parser-apache-pdfbox 模块的 Apache PDFBox 文档解析器(ApachePdfBoxDocumentParser),它可以解析 PDF 文件。
-
langchain4j-document-parser-apache-poi 模块的 Apache POI 文档解析器(ApachePoiDocumentParser),它能够解析微软办公软件的文件格式(例如 DOC、DOCX、PPT、PPTX、XLS、XLSX 等)。
-
langchain4j-document-parser-apache-tika 模块的 Apache Tika 文档解析器(ApacheTikaDocumentParser),它可以自动检测并解析几乎所有现有的文件格式。
假设如果想解析PDF文档,那么原有的 TextDocumentParser 就无法工作了,我们需要引入外部的文档解析器,比如:langchain4j-document-parser-apache-pdfbox ,因此首先需要在pom中导入下这个依赖。
<!--解析pdf文档-->
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
</dependency>3.3.1 文档解析器案例
如下,在本地有一个PDF文件

通过下面的代码,使用文档解析器将上面的文档进行解析
package com.congge.test;import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.apache.pdfbox.ApachePdfBoxDocumentParser;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
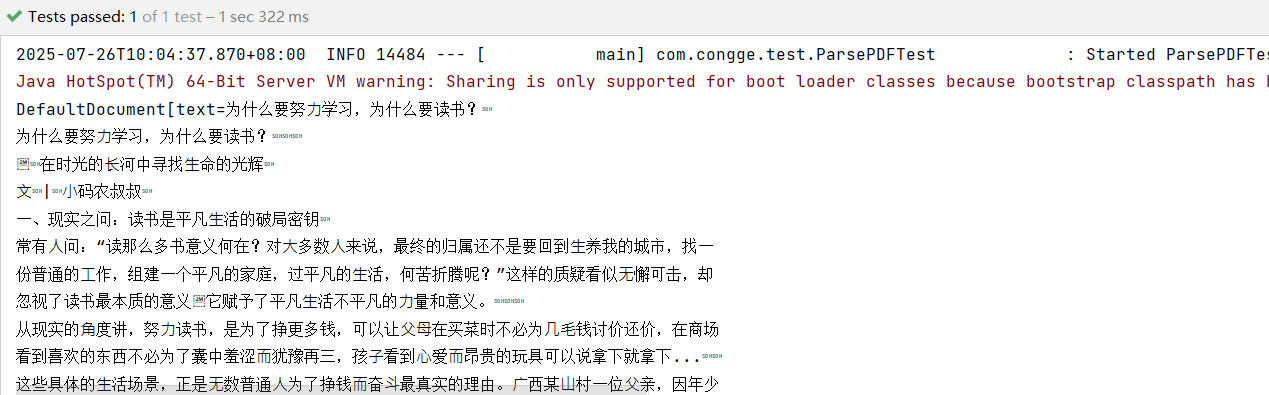
public class ParsePDFTest {@Testpublic void testParsePDF() {String path = "D:\\data\\为什么要努力学习,为什么要读书?.pdf";Document document = FileSystemDocumentLoader.loadDocument(path,new ApachePdfBoxDocumentParser());System.out.println(document);}}运行上面的代码,可以看到PDF文档的内容就被解析成功了
3.4 文档分割介绍
文档加载并解析之后,在真正存储到向量数据库之前还有一步,那就是需要对解析出来的文档进行分割,将一个大的文档分割成小的文本片段。为什么要进行文本分段呢?
-
大语言模型(LLM)的上下文窗口有限,所以整个知识库可能无法全部容纳其中。
-
你在提问中提供的信息越多,大语言模型处理并做出回应所需的时间就越长。
-
你在提问中提供的信息越多,花费也就越多。
-
提问中的无关信息可能会干扰大语言模型,增加产生幻觉(生成错误信息)的几率。
-
我们可以通过将知识库分割成更小、更易于理解的片段来解决这些问题。
3.4.1 常用的文档分割器
LangChain4j 有一个 “文档分割器”(DocumentSplitter)接口,并且提供了几种开箱即用的实现方式:
-
按段落文档分割器(DocumentByParagraphSplitter)
-
按行文档分割器(DocumentByLineSplitter)
-
按句子文档分割器(DocumentBySentenceSplitter)
-
按单词文档分割器(DocumentByWordSplitter)
-
按字符文档分割器(DocumentByCharacterSplitter)
-
按正则表达式文档分割器(DocumentByRegexSplitter)
-
递归分割:DocumentSplitters.recursive (...)
-
默认情况下每个文本片段最多不能超过300个token
3.4.2 向量转换与向量存储
这一步也叫文本向量化,文本只有做了向量化处理之后,存储到向量数据库中。向量化,也叫Embedding。
-
Embedding (Vector) Stores 常见的意思是 “嵌入(向量)存储” 。
-
在机器学习和自然语言处理领域,Embedding 指的是将数据(如文本、图像等)转换为低维稠密向量表示的过程,这些向量能够保留数据的关键特征。
-
而 Stores 表示存储,即用于存储这些嵌入向量的系统或工具。它们可以高效地存储和检索向量数据,支持向量相似性搜索,在文本检索、推荐系统、图像识别等任务中发挥着重要作用。
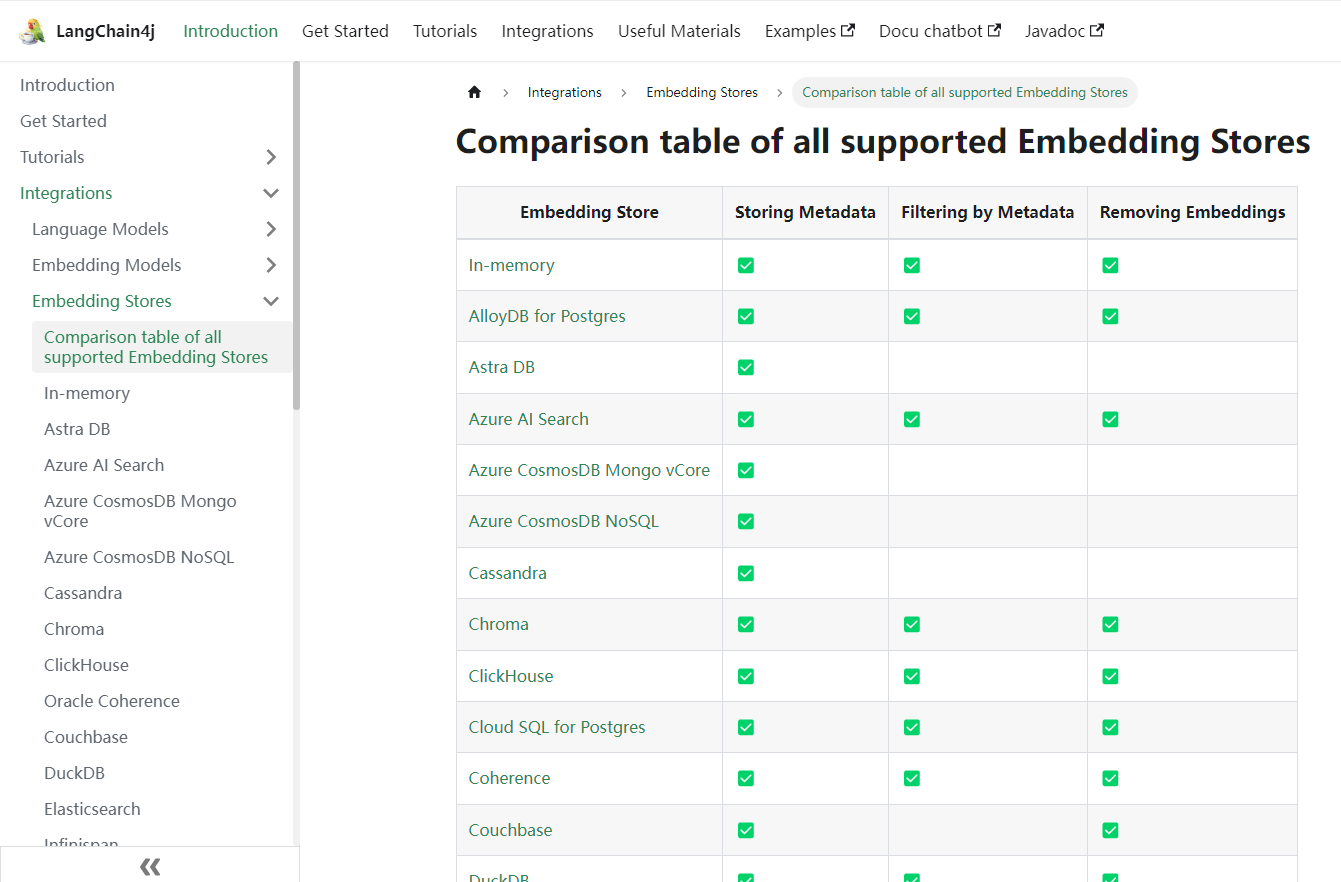
如下,在Langchain4j中支持丰富的向量存储 ,https://docs.langchain4j.dev/integrations/embedding-stores/
在开始使用向量转换之前,需要在pom中添加下面的依赖,这里使用了一个比较简单的实现,即easy-rag组件
<!--简单的rag实现-->
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-easy-rag</artifactId>
</dependency>3.4.3 案例操作代码
在本地有一个md文件,下面通过代码将这个md文件进行向量化

参考下面的代码
package com.congge.test;import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
public class ParseAndStoreTest {@Testpublic void testReadDocumentAndStore() {String path = "D:\\data\\大语言模型(LLM)简介.md";//使用FileSystemDocumentLoader读取指定目录下的知识库文档//并使用默认的文档解析器对文档进行解析(TextDocumentParser)Document document = FileSystemDocumentLoader.loadDocument(path);//简单起见,暂时使用基于内存的向量存储InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();/*** ingest 做的事情* 1、分割文档:默认使用递归分割器,将文档分割为多个文本片段,每个片段包含不超过 300个token,并且有 30个token的重叠部分保证连贯性* 2、文本向量化:使用一个LangChain4j内置的轻量化向量模型对每个文本片段进行向量化* 3、将原始文本和向量存储到向量数据库中(InMemoryEmbeddingStore)**/EmbeddingStoreIngestor.ingest(document, embeddingStore);System.out.println(embeddingStore);}}3.4.4 自定义文档分割
在实际应用开发中,为了最终让RAG的检索效果更好,需要在对文档分割时进行优化控制,合理的文档片段长度可以让大模型在处理时达到一个比较好的效果,基于上面的代码,可以在代码中添加自定义切分文档的部分,从而实现这个效果,参考下面的完整代码
package com.congge.test;import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.splitter.DocumentByParagraphSplitter;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.onnx.HuggingFaceTokenizer;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
public class ParseAndStoreTest {@Testpublic void testReadDocumentAndStore() {String path = "D:\\data\\大语言模型(LLM)简介.md";//使用FileSystemDocumentLoader读取指定目录下的知识库文档//并使用默认的文档解析器对文档进行解析(TextDocumentParser)Document document = FileSystemDocumentLoader.loadDocument(path);//简单起见,暂时使用基于内存的向量存储InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();//自定义文档分割器//按段落分割文档:每个片段包含不超过 300个token,并且有 30个token的重叠部分保证连贯性//注意:当段落长度总和小于设定的最大长度时,就不会有重叠的必要。DocumentByParagraphSplitter documentSplitter = new DocumentByParagraphSplitter(300,30,//token分词器:按token计算new HuggingFaceTokenizer());/*** ingest 做的事情* 1、分割文档:默认使用递归分割器,将文档分割为多个文本片段,每个片段包含不超过 300个token,并且有 30个token的重叠部分保证连贯性* 2、文本向量化:使用一个LangChain4j内置的轻量化向量模型对每个文本片段进行向量化* 3、将原始文本和向量存储到向量数据库中(InMemoryEmbeddingStore)**///EmbeddingStoreIngestor.ingest(document, embeddingStore);EmbeddingStoreIngestor.builder().embeddingStore(embeddingStore).documentSplitter(documentSplitter).build().ingest(document);System.out.println(embeddingStore);}}3.5 向量模型与向量存储
3.5.1 前置准备
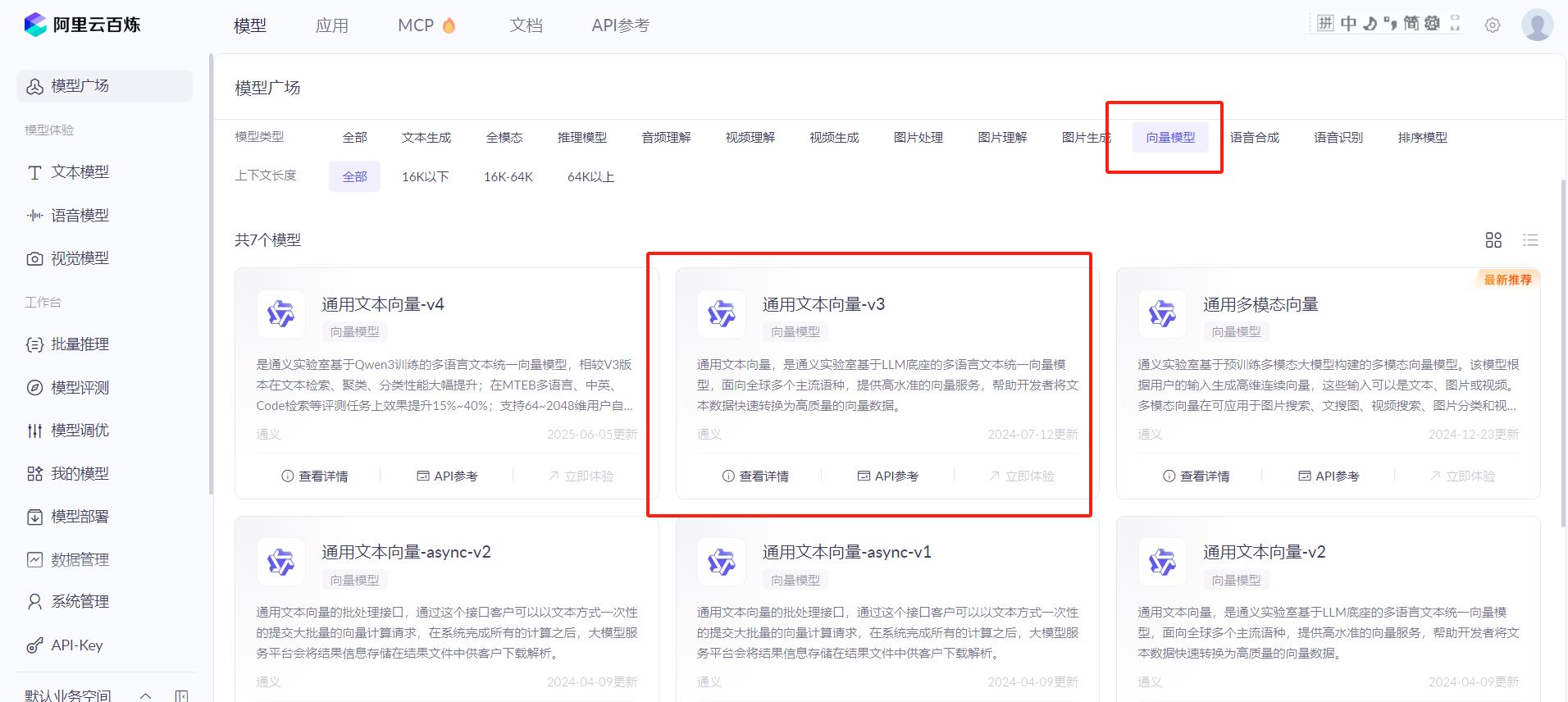
文本在真正存储到向量数据库之前,需要进行向量化,向量化的概念有兴趣的同学可以查阅相关资料进行学习。在实际应用开发中,本地的知识库,一般借助三方大模型或其他的向量化技术将分割后的文本进行向量化之后存储到向量数据库。在下面的代码演示中,将使用通义大模型 text-embedding-v3这个通用文本向量进行说明。
在配置文件中添加向量模型的配置
langchain4j:#阿里百炼平台的模型community:dashscope:chat-model:api-key: 你的apikey #这个是白炼平台的apikeymodel-name: qwen-maxembedding-model:api-key: 你的apikeymodel: text-embedding-v33.5.2 文本向量化演示
通过下面的测试代码,将一段字符串文本进行向量化输出
package com.congge.test;import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
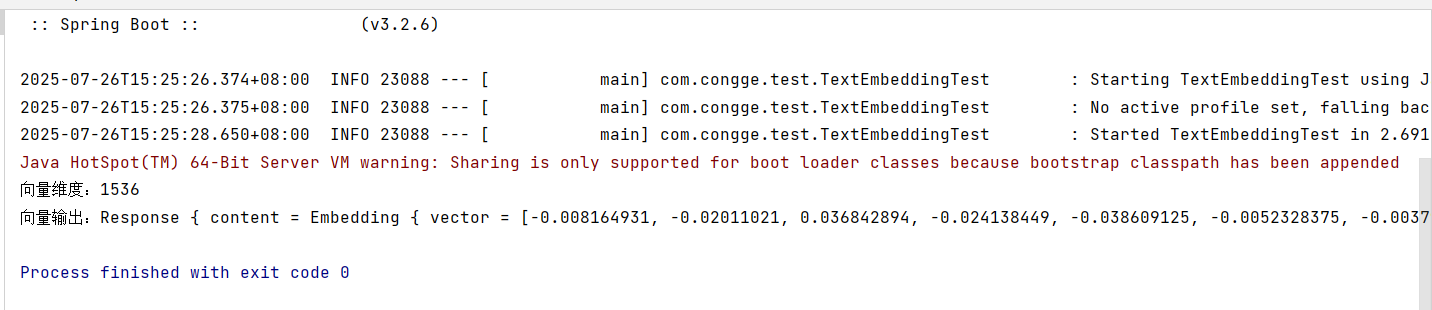
public class TextEmbeddingTest {@Autowiredprivate EmbeddingModel embeddingModel;@Testpublic void testEmbeddingModel(){Response<Embedding> response = embeddingModel.embed("你好,我是小王");System.out.println("向量维度:" + response.content().vector().length);System.out.println("向量输出:" + response.toString());}}输出如下的结果
3.6 基于Redis实现向量数据的存储与检索
之前采用InMemoryEmbeddingStore ,是 LangChain4j 提供的一个内存型向量存储实现。所有数据存储在 JVM 堆内存中,不持久化道磁盘中,适合开发测试和小规模应用。如果我们需要将数据存储到外部的话,就需要自己安装一个向量数据库,这里我们采用 redis-vector 数据库,在 redis 的基础上支持了向量数据。
3.6.1 搭建Redis向量数据库
使用下面的命令搭建向量数据库
docker run --name redis-vector -d -p 6379:6379 redislabs/redisearch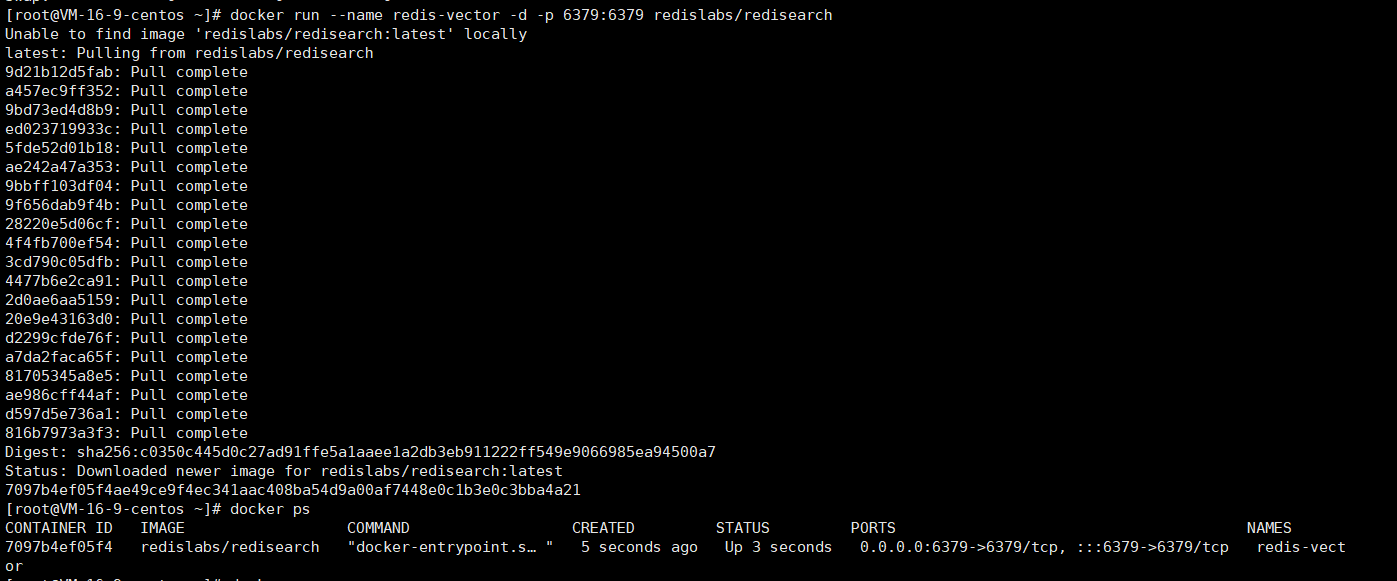
3.6.2 添加依赖
在pom中添加redis的向量数据库依赖,版本可以根据自己的大版本选择合适的
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-community-redis-spring-boot-starter</artifactId><version>1.0.1-beta6</version>
</dependency>3.6.3 添加配置文件
在配置文件中添加下面的配置信息
langchain4j:#阿里百炼平台的模型community:dashscope:chat-model:api-key: 你的apikey #这个是白炼平台的apikeymodel-name: qwen-maxembedding-model:api-key: 你的apikeymodel: text-embedding-v3redis:host: redis 地址port: 6379logging:level:root: info3.6.4 添加自定义EmbeddingStore
增加一个类,配置EmbeddingStore,这里面的EmbeddingStore 具体配置时使用redisEmbeddingStore
package com.congge.config;import dev.langchain4j.community.store.embedding.redis.RedisEmbeddingStore;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.loader.ClassPathDocumentLoader;
import dev.langchain4j.data.document.parser.apache.pdfbox.ApachePdfBoxDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.List;@Configuration
public class RedisStoreConfig {@Autowiredprivate EmbeddingModel embeddingModel;@Autowiredprivate RedisEmbeddingStore redisEmbeddingStore;/*** 构建向量数据库操作对象*/@Beanpublic EmbeddingStore store(){// 加载文档进内存// List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");List<Document> documents = ClassPathDocumentLoader.loadDocuments("content", new ApachePdfBoxDocumentParser());//List<Document> documents = FileSystemDocumentLoader.loadDocuments("D:\\data\\为什么要努力学习,为什么要读书?.pdf");// 构建向量数据库操作对象,操作的是内存版本的向量数据库// InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();// 构建文档分割器对象DocumentSplitter ds = DocumentSplitters.recursive(500, 100);// 构建EmbeddingStoreIngestor对象,完成文本数据切割、向量化、存储EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()//.embeddingStore(store).embeddingStore(redisEmbeddingStore).documentSplitter(ds).embeddingModel(embeddingModel).build();ingestor.ingest(documents);return redisEmbeddingStore;}/*** 构建向量数据库检索对象*/@Beanpublic ContentRetriever contentRetriever(){return EmbeddingStoreContentRetriever.builder().embeddingStore(redisEmbeddingStore).minScore(0.5).maxResults(3).embeddingModel(embeddingModel).build();}}启动项目后,登录redis客户端可视化工具,可以看到本地的文档被切分成小块的文档,最终存储到redis的向量数据库,每一段文本都有对应的向量数据,以及完整的文本内容

3.6.5 改造Assistant
在自定义的Assistant中,在接口的注解中增加一个contentRetriever的属性值,即为上面的那个contentRetriever,然后增加一个chatV3的方法用于接下来的测试
package com.congge.assistant;import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.V;
import dev.langchain4j.service.spring.AiService;
import dev.langchain4j.service.spring.AiServiceWiringMode;@AiService(wiringMode = AiServiceWiringMode.EXPLICIT,chatModel = "qwenChatModel",chatMemory = "chatMemory",contentRetriever = "contentRetriever"
)
public interface ChatMemoryAssistant {@UserMessage("你是我的好朋友,请用东北话回答问题,并且回答的时候添加一些表情符号。 {{it}}")String chat(String userMessage);@UserMessage("你是我的好朋友,请用东北话回答问题,并且回答的时候添加一些表情符号。 {{userMessage}}")String chatV(@V("userMessage") String userMessage);String chatV3(String userMessage);}3.6.6 增加测试接口
为验证效果,增加一个测试接口,如下
package com.congge.controller;import com.congge.assistant.ChatMemoryAssistant;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/rag")
public class RagController {@Resourceprivate ChatMemoryAssistant chatMemoryAssistant;//localhost:8082/rag/chat/v3?userMessage=如何对抗庸常的诗意?@GetMapping("/chat/v3")public String chatSystemV3(@RequestParam("userMessage") String userMessage) {String answer3 = chatMemoryAssistant.chatV3(userMessage);return answer3;}}启动工程后,调用接口,可以看到下面的内容正是从存储到redis向量数据库中检索到的

四、写在文末
本文通过较大的篇幅详细介绍了Langchain4j中RAG技术的使用,希望对看到的同学有用哦,本篇到此结束,感谢观看。