【论文阅读】DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
DETR3D: 3D Object Detectionfrom Multi-view Images via 3D-to-2D Queries网络模型
DETR3D介绍了一个用于多相机 3D 物体检测的框架。与直接从单目图像估计 3D 边界框或使用深度预测网络从 2D 信息生成 3D 对象检测输入的现有工作相比,直接在 3D 空间中预测。架构从多个相机图像中提取 2D 特征,然后使用一组稀疏的 3D 对象查询来索引这些 2D 特征,使用相机变换矩阵将 3D 位置链接到多视图图像。最后,模型对每个对象查询进行边界框预测,使用set-to-set损失来衡量基本事实和预测之间的差异。这种自上而下的方法优于自下而上的方法,其中对象边界框预测遵循每像素深度估计,因为它不会受到深度预测模型引入的复合误差的影响。此外,方法不需要非最大抑制等后处理,从而大大提高了推理速度。
1. 核心思想
- 提出了一个流线型的RGB图像三维目标检测模型。 现有的工作在最后一个阶段结合来自不同摄像机视图的目标预测,而DETR3D的方法融合了来自每一层计算的所有摄像机视图的信息。 据我们所知,这是首次尝试将多摄像机检测作为三维集对集预测(3D set-to-set prediction)。
- 引入了一个模块,通过向后几何投影(backward geometric projection)连接二维特征提取和三维包围盒预测。 它不会受到来自二级网络的不准确深度预测的影响,并通过将3D信息反投影到所有可用帧上来, 无缝地使用来自多个相机的信息。
- 类似于对象DGCNN, 不需要像每幅图像或全局NMS这样的后处理,它与现有的基于NMS的方法不相上下。 在相机重叠区域,我们的方法比其他方法有很大的优势。
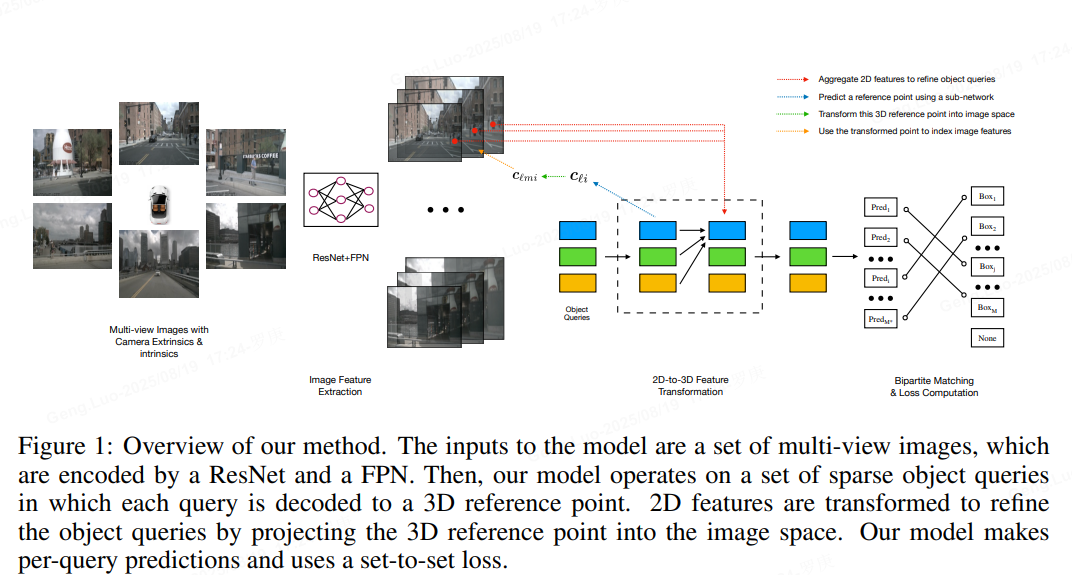
Sparse的代表作。
2. 网络架构
DETR3D的架构分为三个主要阶段:特征提取、Transformer编码器-解码器和预测头。整体流程如下:
-
输入层:处理原始点云数据。点云通常表示为P={pi∈Rd∣i=1,2,…,N}P = \{p_i \in \mathbb{R}^d \mid i=1,2,\dots,N\}P={pi∈Rd∣i=1,2,…,N},其中ddd是特征维度(如坐标、反射强度等)。模型使用点云采样和分组技术(如Farthest Point Sampling)来减少计算量。
-
特征提取器:采用类似PointNet++的模块提取局部特征。输入点云经过多层感知机(MLP)生成特征图:
Ffeat=MLP(P) F_{\text{feat}} = \text{MLP}(P) Ffeat=MLP(P)
其中Ffeat∈RN×CF_{\text{feat}} \in \mathbb{R}^{N \times C}Ffeat∈RN×C,CCC是特征通道数。 -
Transformer编码器:处理特征图以捕获全局上下文。编码器由多个自注意力层组成:
Fenc=TransformerEncoder(Ffeat) F_{\text{enc}} = \text{TransformerEncoder}(F_{\text{feat}}) Fenc=TransformerEncoder(Ffeat)
每个自注意力层计算:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中QQQ、KKK、VVV是查询、键和值矩阵,dkd_kdk是维度缩放因子。 -
Transformer解码器:使用一组可学习的查询生成预测。查询是随机初始化的向量Qquery∈RM×CQ_{\text{query}} \in \mathbb{R}^{M \times C}Qquery∈RM×C,MMM是查询数量(通常为100)。解码器通过交叉注意力机制融合编码器输出:
Fdec=TransformerDecoder(Qquery,Fenc) F_{\text{dec}} = \text{TransformerDecoder}(Q_{\text{query}}, F_{\text{enc}}) Fdec=TransformerDecoder(Qquery,Fenc)
输出Fdec∈RM×CF_{\text{dec}} \in \mathbb{R}^{M \times C}Fdec∈RM×C对应MMM个预测候选。 -
预测头:将解码器输出转换为3D边界框预测。每个查询对应一个预测:
- 分类分支:预测物体类别概率,使用全连接层(FC):
Pcls=softmax(FC(Fdec)) P_{\text{cls}} = \text{softmax}(\text{FC}(F_{\text{dec}})) Pcls=softmax(FC(Fdec)) - 回归分支:预测边界框参数b=(x,y,z,w,h,l,θ)\mathbf{b} = (x,y,z,w,h,l,\theta)b=(x,y,z,w,h,l,θ),其中(x,y,z)(x,y,z)(x,y,z)是中心坐标,(w,h,l)(w,h,l)(w,h,l)是尺寸,θ\thetaθ是朝向角。使用FC层:
b=FC(Fdec) \mathbf{b} = \text{FC}(F_{\text{dec}}) b=FC(Fdec)
- 分类分支:预测物体类别概率,使用全连接层(FC):
3. 关键组件详解
- 查询机制:查询是模型的核心,每个查询学习代表一个潜在物体。训练时,模型通过匈牙利匹配算法将预测与真实框配对,确保一对一预测,避免NMS。
- 位置编码:为点云特征添加位置信息,使用正弦编码:
PE(p)=[sin(2πpλ),cos(2πpλ)] \text{PE}(p) = \left[\sin\left(\frac{2\pi p}{\lambda}\right), \cos\left(\frac{2\pi p}{\lambda}\right)\right] PE(p)=[sin(λ2πp),cos(λ2πp)]
其中ppp是点坐标,λ\lambdaλ是波长参数。 - 多视图融合:DETR3D可扩展为多传感器输入(如相机+LiDAR)。特征提取后,通过注意力机制融合不同视图的特征。
4. 损失函数
训练时使用多任务损失函数,包括分类损失和边界框回归损失:
Ltotal=λclsLcls+λboxLbox
L_{\text{total}} = \lambda_{\text{cls}} L_{\text{cls}} + \lambda_{\text{box}} L_{\text{box}}
Ltotal=λclsLcls+λboxLbox
其中λcls\lambda_{\text{cls}}λcls和λbox\lambda_{\text{box}}λbox是权重系数。
- 分类损失LclsL_{\text{cls}}Lcls:采用Focal Loss处理类别不平衡:
Lcls=−αt(1−pt)γlog(pt) L_{\text{cls}} = -\alpha_t (1-p_t)^\gamma \log(p_t) Lcls=−αt(1−pt)γlog(pt)
其中ptp_tpt是预测概率,αt\alpha_tαt和γ\gammaγ是超参数。 - 边界框损失LboxL_{\text{box}}Lbox:使用Smooth L1损失回归位置和尺寸:
Lbox=∑ismoothL1(bi−b^i) L_{\text{box}} = \sum_{i} \text{smooth}_{L1}(b_i - \hat{b}_i) Lbox=i∑smoothL1(bi−b^i)
其中bib_ibi是预测框参数,b^i\hat{b}_ib^i是真实框参数。朝向角θ\thetaθ用正弦损失处理。
5. 优缺点
- 优点:
- 端到端训练:无需手工设计锚框或NMS,简化流程。
- 全局上下文:Transformer建模长距离依赖,提升小物体检测。
- 灵活性:可适配点云、图像或多模态输入。
- 缺点:
- 计算开销大:Transformer层导致较高内存和计算需求。
- 训练不稳定:查询初始化影响收敛,需仔细调参。
- 对小物体敏感:点云稀疏时,检测精度可能下降。
6. 应用与性能
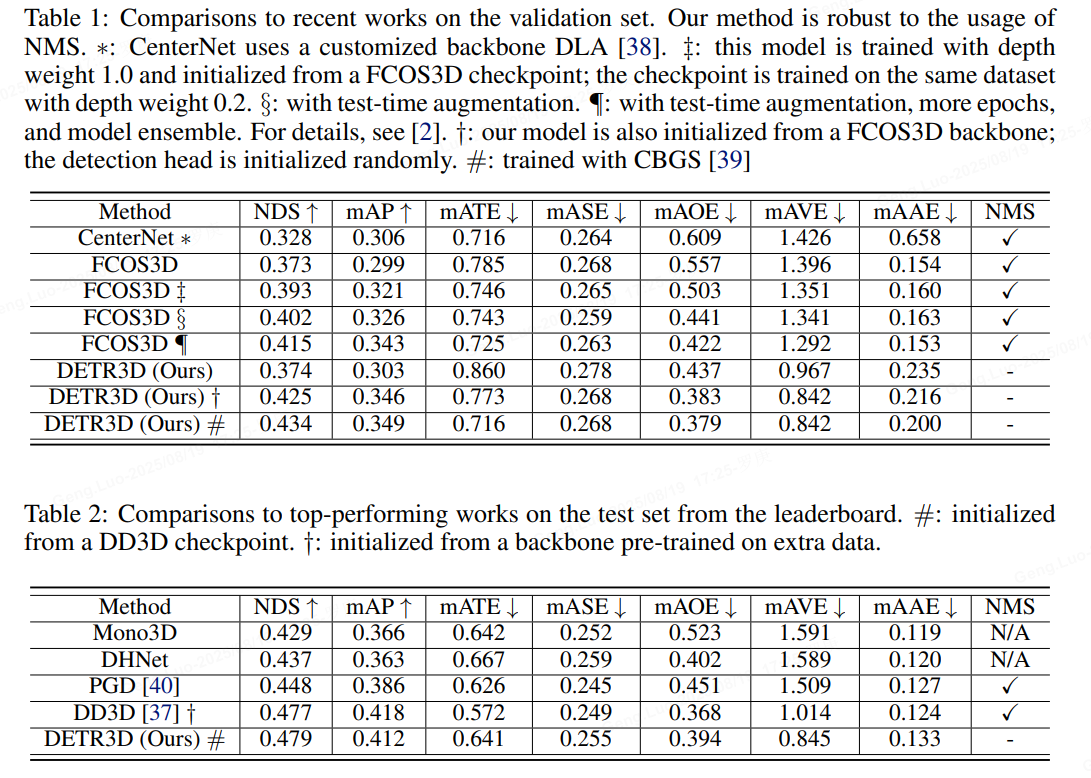
DETR3D在标准数据集如nuScenes和KITTI上表现优异。例如,在nuScenes 3D检测任务中,NDS可达40%以上。典型应用包括:
- 自动驾驶:实时检测车辆、行人。
- 机器人导航:环境感知和避障。
- AR/VR:场景重建。
总之,DETR3D通过Transformer架构实现了高效3D物体检测,但实际部署时需优化计算效率。