CVPR 2025 | 具身智能 | HOLODECK:一句话召唤3D世界,智能体的“元宇宙练功房”来了
关注gongzhonghao【CVPR顶会精选】
1.导读
1.1 论文基本信息
论文标题:《HOLODECK: Language Guided Generation of 3D Embodied AI Environments》
作者:Yue Yang*1, Fan-Yun Sun*2, Luca Weihs*4, Eli Vanderbilt4, Alvaro Herrasti4,Winson Han4, Jiajun Wu2, Nick Haber2, Ranjay Krishna3,4, Lingjie Liu1,Chris Callison-Burch1, Mark Yatskar1, Aniruddha Kembhavi3,4, Christopher Clark4
作者单位:宾夕法尼亚大学、斯坦福大学、华盛顿大学、艾伦人工智能研究所等
发表会议:CVPR(计算机视觉与模式识别会议)
论文链接:https://arxiv.org/abs/2312.09067
图灵学术论文辅导
2.论文概述
2.1 问题与背景
该论文提出了一种名为HOLODECK的系统,旨在通过文本描述自动生成多样化、可定制且可交互的3D具身智能环境,以解决现有3D环境生成方法需要大量人工投入且多样性受限的问题。HOLODECK利用大型语言模型的常识知识来理解复杂的用户查询,并通过约束优化方法来合理布局场景中的物体,从而确保生成环境的物理合理性和语义一致性

2.2 系统模块核心
HOLODECK系统的核心在于其模块化设计,它将复杂的3D场景生成任务分解为四个子模块:楼层与墙体、门窗、物体选择和基于约束的布局设计。这种方法使其能够根据用户输入的提示词,自动生成符合特定风格或包含精细化需求的场景。论文通过大规模人类评估,证明HOLODECK生成的住宅场景优于现有的程序化基线方法,并且能够生成高质量的多样化场景。此外,研究还展示了HOLODECK在具身智能中的应用,证明了使用HOLODECK生成的新颖场景训练智能体,可以显著提升其在零样本物体导航任务中的泛化能力 。
3.研究背景及相关工作
3.1 具身智能环境的挑战
具身智能体的训练通常依赖于模拟器环境。然而,现有的3D环境生成方法面临着诸多挑战。传统方法如人工设计或3D扫描,需要耗费大量人力和专业知识,且难以大规模扩展和保证场景的多样性。虽然程序化生成框架能够生成大规模交互式环境,但其依赖于硬编码规则,限制了场景的丰富性和可定制性。
3.3 2D基础模型与3D场景生成
一些工作尝试将2D基础模型应用于文本驱动的3D场景生成。然而,这些方法通常会产生网格失真等明显伪影,且缺乏具身智能所需的交互性。另一些模型虽然专注于特定的任务,如平面图生成或物体排列,但它们通常缺乏整体场景的一致性,且严重依赖于特定任务的数据集。

3.3 文本驱动的3D生成
早期的文本驱动3D生成工作主要侧重于从类别特定的数据集中学习3D形状或纹理。随着大型视觉-语言模型的出现,实现了零样本的3D纹理和物体生成。但这些方法在生成复杂3D场景时表现不佳。与这些方法不同,HOLODECK利用了一个包含海量资产的3D数据库,以生成语义精确、空间高效且可交互的3D环境 。
4.实验设计和方法
4.1 总体架构设计
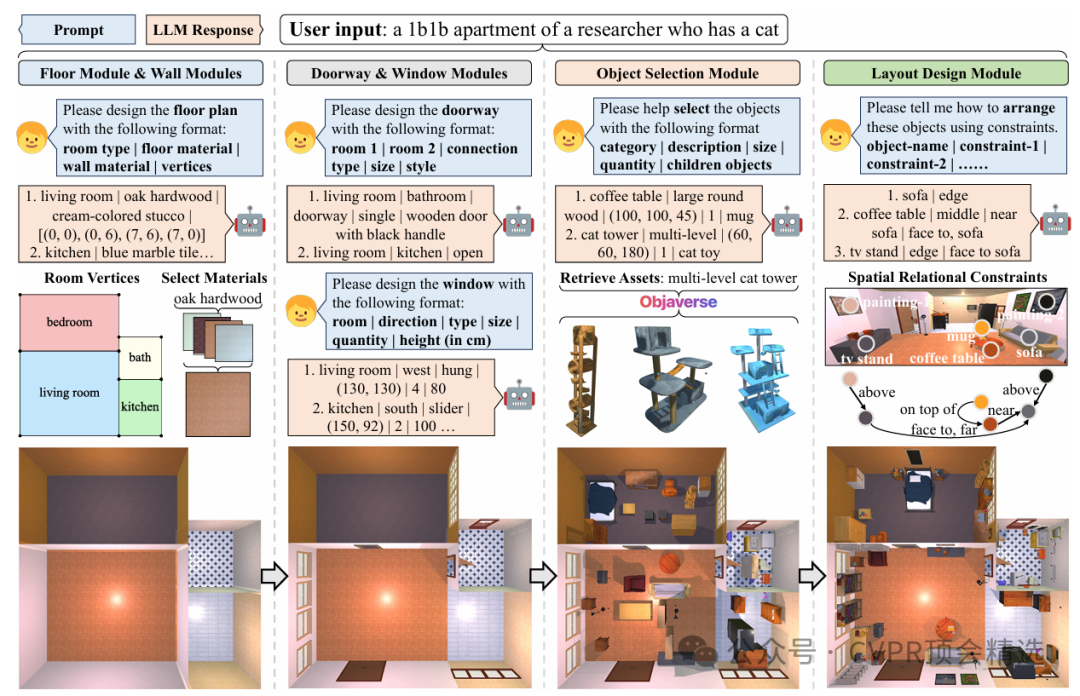
HOLODECK是一个基于A12-THOR框架并结合了Objaverse海量资产的系统,其核心思想是利用大型语言模型将高级别的自然语言描述转化为一系列用于构建3D场景的低级别指令。整个场景的生成过程被分解为四个相互协作的模块,每个模块都通过与LLM进行多轮对话来完成特定的任务。
楼层与墙体模块:
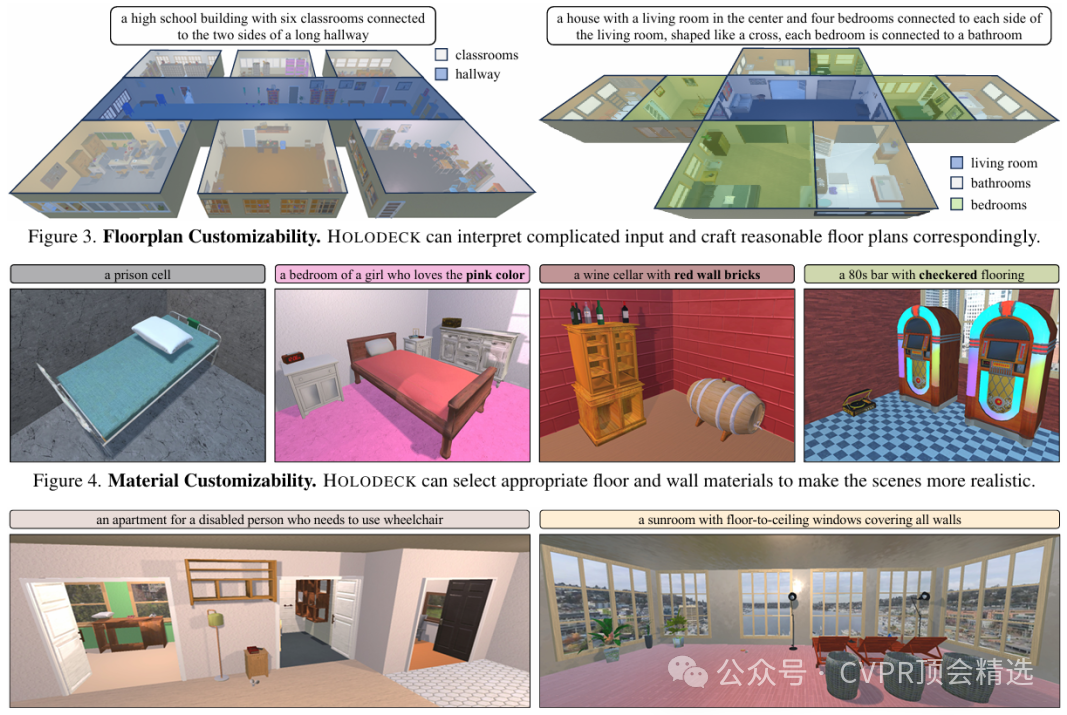
该模块负责创建房间的平面图、构建墙体结构,并为地板和墙壁选择合适的材料。LLM会直接生成房间的坐标和连接信息,每个房间被定义为由四个元组坐标确定的矩形。该模块能够根据复杂的输入生成精细的多房间平面图。此外,它还能从236种材料和148种颜色中进行匹配,以实现场景的语义定制化。
物体选择模块:
该模块允许LLM根据场景描述来选择合适的物体。HOLODECK利用庞大的Objaverse资产库,根据LLM建议的描述和尺寸来检索最佳的3D资产。
基于约束的布局设计模块:
HOLODECK预定义了十种空间关系约束,分为五类:全局、距离、位置、对齐和旋转。这些约束被视为软约束,并通过一个优化算法来解决,以找到满足最多约束的合理布局。同时,系统还强制执行硬约束,以防止物体碰撞并确保所有物体都在房间边界内。
图灵学术论文辅导
5. 实验结果分析
5.1 住宅场景的人类评估
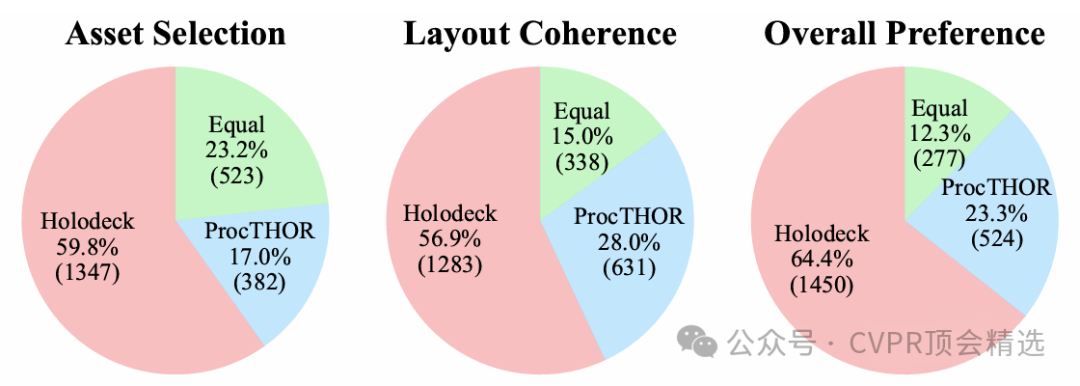
在一项与PROCTHOR的对比研究中,680名参与者对HOLODECK和PROCTHOR生成的住宅场景进行了评估。结果显示,在资产选择、布局一致性和整体偏好三个方面,人类评估者都明显偏向HOLODECK。
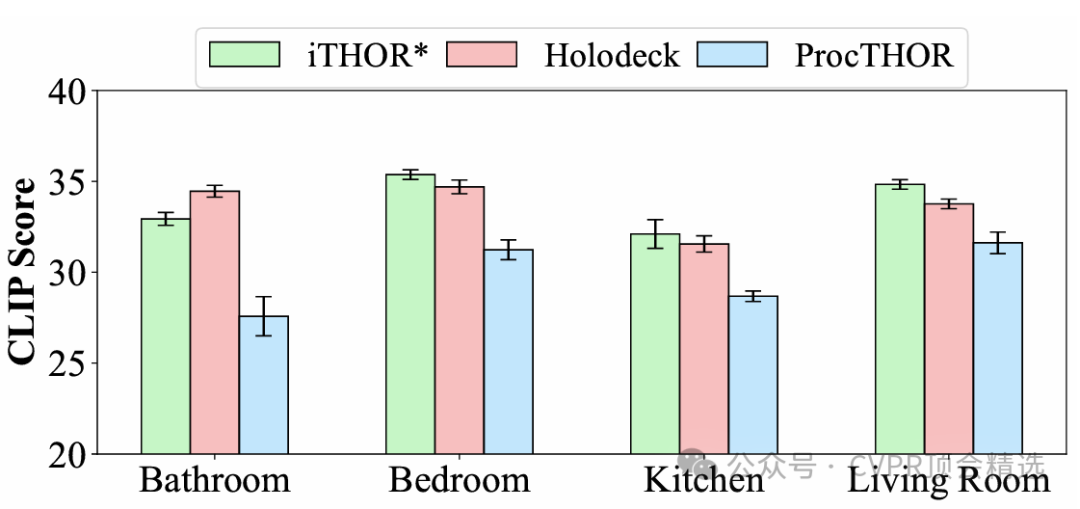
在整体偏好上,64.4%的评估者更喜欢HOLODECK,而只有23.3%的评估者更喜欢PROCTHOR。此外,使用CLIP分数进行的视觉一致性量化评估也显示,HOLODECK的得分显著高于PROCTHOR,且接近人类专家设计的场景,进一步证明了其生成视觉连贯场景的能力。
5.2 多样化场景的生成能力
为了评估HOLODECK在住宅场景之外的表现,研究人员让人类对52种不同类型的场景进行了评分。结果表明,HOLODECK在超过一半(28/52)的场景类型上获得了比PROCTHOR更高的平均偏好分数。

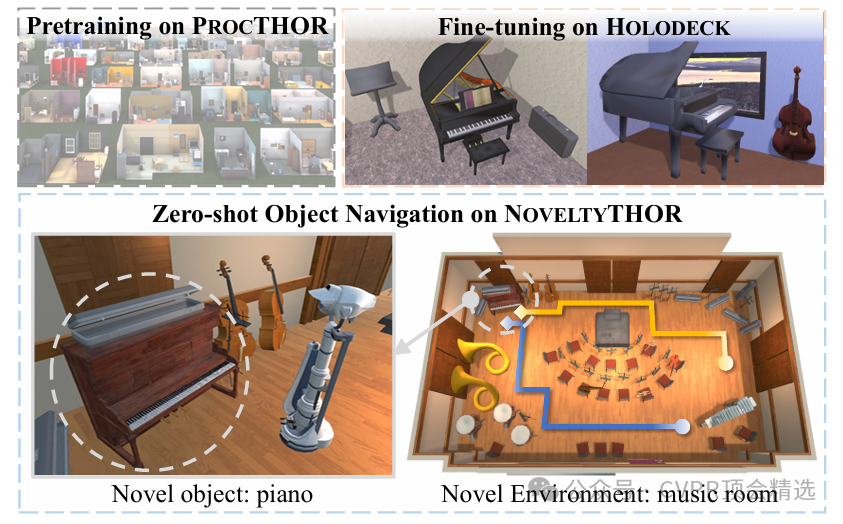
5.3 在具身智能中的应用
论文展示了HOLODECK在具身智能中的一个激动人心的应用:零样本物体导航。研究人员在一个名为NOVELTYTHOR的新颖基准上进行了实验。结果显示,使用HOLODECK生成的新场景进行微调的智能体,其零样本导航成功率和路径长度加权成功率都显著高于基线模型。这表明HOLODECK生成的训练环境能够帮助智能体更好地泛化到以前未见过的场景和物体类型。论文指出,HOLODECK在物体放置上的能力,是其优于基线的主要原因之一 。
6.论文总结展望
6.1 论文总结
该论文成功地提出了HOLODECK系统,一个由大型语言模型驱动的、能够从文本描述中生成多样化和可交互的3D具身智能环境的系统。
HOLODECK通过将生成过程分解为多个模块,并利用LLM的常识知识和一种新颖的基于空间关系约束的布局优化方法,克服了传统方法在多样性、可定制性和物理合理性方面的局限。
大规模的人类评估结果一致表明,HOLODECK生成的场景质量优于现有基线,且能够很好地泛化到各种场景类型。此外,通过零样本物体导航实验,研究还验证了HOLODECK生成的场景在训练具身智能体方面的实用性。

6.2 论文展望
尽管HOLODECK取得了显著成就,但论文也指出了一些局限性。目前,该系统在处理需要非常复杂布局或需要其资产库中不存在的独特物体(如牙科诊所的X光机)的场景时仍然面临挑战。未来工作的方向可以包括扩大资产库,并引入更复杂的布局算法来解决这些问题。此外,该系统为进一步探索文本驱动的3D交互式场景生成开辟了新的途径。
本文选自gongzhonghao【CVPR顶会精选】