从 VLA 到 VLM:低延迟RTSP|RTMP视频链路在多模态AI中的核心角色与工程实现
1. 引言:多模态浪潮下的“视频神经元”
随着人工智能从单一模态(仅文本或仅图像)逐步走向多模态融合,视频正成为视觉-语言模型(VLM)不可或缺的核心输入源。无论是在自动驾驶中对道路与环境的实时感知,工业巡检中对设备缺陷的快速识别,还是安防监控中对异常目标的精准定位,模型的推理与决策能力,都依赖于视频数据能否以低延迟、稳定且无损的方式进入多模态推理链路。
然而,当前多模态研究多集中于离线图片或短视频数据,这类方法在面对长时、连续、高码率且弱网波动明显的实时视频场景时,往往难以直接迁移与落地。
在这种背景下,大牛直播SDK发挥了关键作用——它不仅能够跨平台提供 RTSP / RTMP / GB28181 等多种协议的低延迟视频传输能力,还可以作为 VLA(视觉-语言对齐)→ VLM(视觉-语言模型) 演进路径中的前置数据通道,为多模态模型稳定输送高质量、实时可用的视频流,从而支撑工业级、安防级乃至医疗级的多模态 AI 应用。
2. 技术背景:VLA 与 VLM 的差异与联系
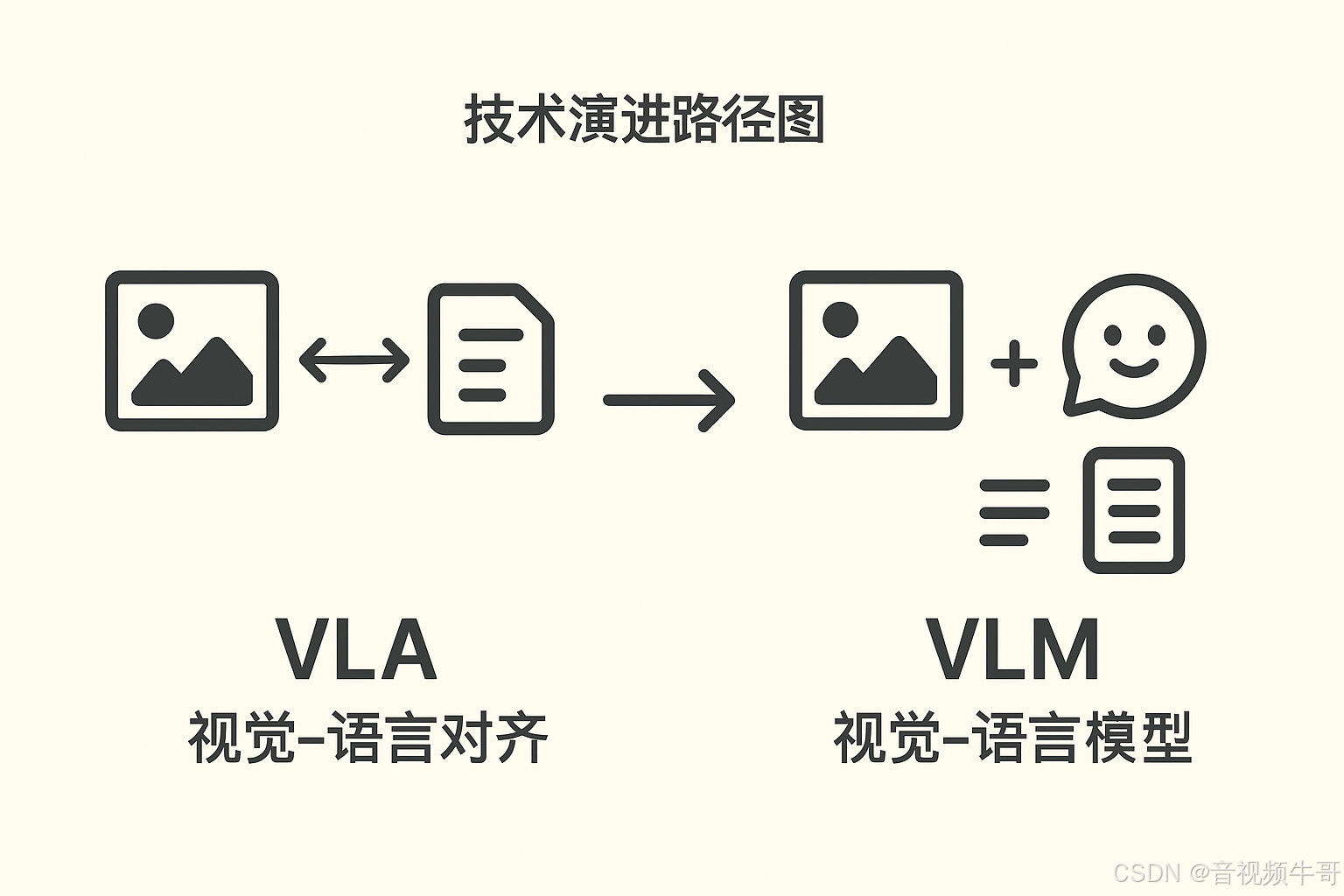
2.1 VLA(Vision-Language Alignment)
-
目标:将视觉特征与语言语义对齐到同一表示空间。
-
典型模型:CLIP、ALIGN、BLIP-2(对齐阶段)。
-
优势:可快速实现跨模态检索、标签预测、图文匹配。
-
不足:对时序视频和多轮推理支持有限。
2.2 VLM(Vision-Language Model)
-
目标:让语言模型直接理解、推理和生成基于视觉输入的内容。
-
典型模型:GPT-4V、Gemini、Qwen-VL、LLaVA。
-
优势:可处理多轮对话、复杂推理、多模态生成。
-
挑战:实时视频输入的带宽、延迟、稳定性要求极高。
关系:VLA 是 VLM 的基础,VLM 在 VLA 的对齐能力上增加了跨模态推理与生成。
3. 大牛直播SDK在 VLA→VLM 演进链路中的角色
在多模态视频推理的体系中,数据链路就像人体的神经系统:
-
VLA 相当于视觉神经与语言神经的信号对齐器,负责让来自不同模态的信号“说同一种语言”。
-
VLM 相当于大脑皮层,整合多模态信号并进行推理、决策与生成。
-
大牛直播SDK 则是视觉信号的高速神经通道,决定视觉信息能否以足够快、足够稳、足够干净的方式传输到“大脑”,从而发挥 VLA 与 VLM 的全部潜力。
换句话说,如果没有一个高质量、低延迟、稳定的实时视频通道,即便 VLA 和 VLM 再强大,也只能停留在实验室或离线数据集的层面,难以支撑工业级、安防级、医疗级的多模态落地场景。
3.1 核心特性
1. 超低延迟链路
-
RTSP / RTMP 实时传输延迟可稳定压缩至 100–250 ms。
-
支持弱网自适应、码率动态调节与丢包优化,保障画面连续性与时序稳定性。
2. 跨平台一致性
-
一套 SDK 覆盖 Windows / Linux / Android / iOS / Unity 等主流平台。
-
统一 API 设计,便于在多平台多终端部署同一套推理链路。
3. 多协议融合
-
原生支持 RTSP / RTMP / HTTP-FLV / GB28181 / 本地文件回放 等输入源。
-
可无缝对接 AI 推理框架(如 PyTorch / TensorRT / OpenVINO),支持直接将解码帧送入推理模块。
4. 边缘侧预处理能力
-
内置视频裁剪、缩放、转码、音画分离等处理管线。
-
可直接输出推理所需的帧数据格式(RGB、YUV、NV12),减少后端预处理负担,加快整体推理速度。
4. 工程实现:从摄像机到 VLM 的实时链路
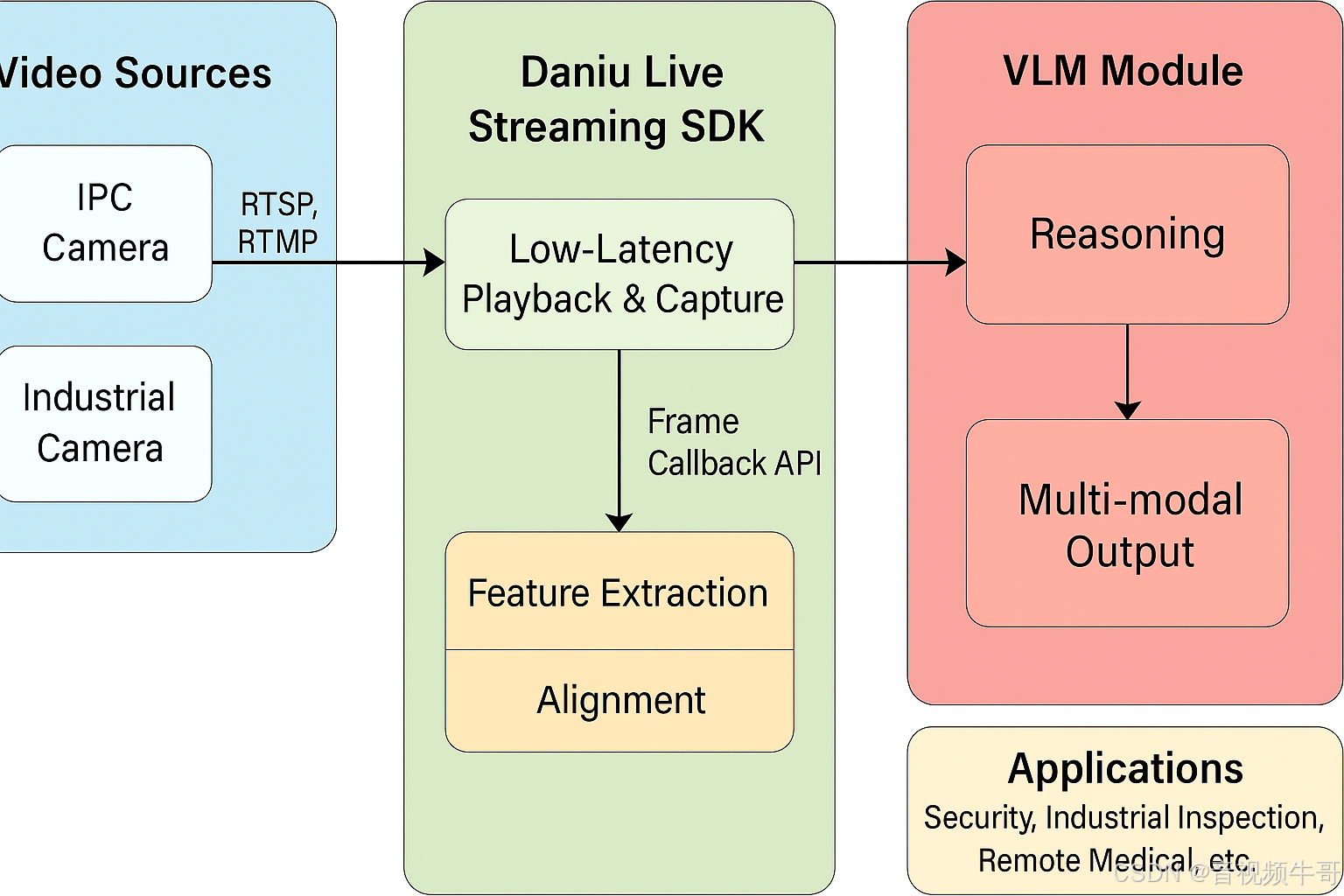
4.1 典型链路架构
IPC 摄像机 / 工业相机↓ (RTSP/RTMP/GB28181)
大牛直播SDK播放器/采集端↓ (低延迟解码 + 缓冲优化)
帧数据回调(RGB/YUV)↓
VLA 模块(特征提取 + 表示对齐)↓
VLM 推理(问答 / 检测 / 多模态对话)↓
结果分发(WebSocket / HTTP API / UI展示)
4.2 接口示例(C++)
RTSP|RTMP播放器播放之前,设置video frame回调,回调数据可以是YUV或RGB:
player_api_.SetVideoFrameCallBack(player_handle_, NT_SP_E_VIDEO_FRAME_FORMAT_RGB32,GetSafeHwnd(), SM_SDKVideoFrameHandle);回调处理:
extern "C" NT_VOID NT_CALLBACK SM_SDKVideoFrameHandle(NT_HANDLE handle, NT_PVOID userData, NT_UINT32 status,const NT_SP_VideoFrame* frame)
{if ( frame != NULL ){if ( NT_SP_E_VIDEO_FRAME_FORMAT_RGB32 == frame->format_&& frame->plane0_ != NULL&& frame->stride0_ > 0&& frame->height_ > 0 ){std::unique_ptr<nt_rgb32_image > pImage(new nt_rgb32_image());pImage->size_ = frame->stride0_* frame->height_;pImage->data_ = new NT_BYTE[pImage->size_];memcpy(pImage->data_, frame->plane0_, pImage->size_);pImage->width_ = frame->width_;pImage->height_ = frame->height_;pImage->stride_ = frame->stride0_;HWND hwnd = (HWND)userData;if ( hwnd != NULL && ::IsWindow(hwnd) ){::PostMessage(hwnd, WM_USER_SDK_RGB32_IMAGE, (WPARAM)handle, (LPARAM)pImage.release());}}}
}4.3 与 AI 模型对接
在多模态系统中,大牛直播SDK不仅负责将视频流稳定、低延迟地传入推理链路,还要为 VLA 与 VLM 模块提供结构化、可直接处理的视觉数据。具体对接方式如下:
-
VLA 阶段(特征对齐)
解码后的逐帧图像数据通过 SDK 的帧回调接口输出,直接送入如 CLIP、ALIGN、BLIP-2 等视觉-语言对齐模型进行特征编码,生成统一向量空间中的视觉 embedding。
这样可以实现高精度的跨模态检索、相似度匹配和语义理解,为后续推理提供高质量输入。 -
VLM 阶段(推理与生成)
将 VLA 输出的视觉 embedding 转换为可被大型语言模型(LLM)识别的多模态 token,并与用户的自然语言输入拼接在同一上下文中输入到 VLM(如 GPT-4V、Qwen-VL、LLaVA)。
在该阶段,VLM 可基于视觉信息进行多轮对话、情景推理、描述生成、任务规划等复杂操作,实现真正的视觉+语言融合推理。
5. 应用场景
5.1 安防监控 × 多模态告警
链路:实时摄像头 → 大牛直播SDK(低延迟传输) → VLA(特征提取) → VLM(语义分析与生成) → 告警系统
应用说明:
-
VLM 可根据摄像画面生成自然语言描述,如“检测到一名未授权人员进入A区”。
-
与告警平台集成后,可将告警信息推送至安保终端或值班室,实现实时监控与快速响应。
-
支持目标追踪、行为识别、区域越界等事件级触发。
5.2 工业巡检 × 缺陷问答
链路:巡检机器人摄像头 → 大牛直播SDK → VLA → VLM → 技术交互终端
应用说明:
-
技术人员可通过语音或文字直接询问系统:“这个焊点有没有裂缝?”
-
VLM 结合实时画面与历史巡检记录,给出精准回答,并可生成对应的缺陷定位截图或检测报告。
-
支持对不同零件、材料和工艺进行可视化对比分析。
5.3 远程医疗 × 智能辅诊
链路:手术室影像 → 大牛直播SDK → VLA → 医疗专用 VLM → 医疗信息系统
应用说明:
-
在手术过程中,VLM 可识别并标注关键步骤(如切口、缝合、止血等),并生成实时的结构化手术记录。
-
辅助医生对影像中可疑病灶进行分析,并给出初步诊断建议。
-
支持与远程专家进行多模态会诊,将实时视频与手术数据同步传输。
6. 总结与展望
在多模态 AI 系统中,VLA 决定了视觉与语言的语义对齐能力,VLM 决定了跨模态推理与生成的深度,而大牛直播SDK则决定了这些能力能否在真实业务中“实时落地”。
如果没有高质量、低延迟、稳定的视频输入链路,多模态推理就只能停留在离线实验室阶段,无法支撑安防、工业、医疗等对时效性要求极高的场景。
面向未来,大牛直播SDK将在以下方向持续演进:
-
原生集成 VLA 前处理
在视频解码阶段直接提取视觉特征(embedding),将结构化数据直接输送至 VLA 模块,减少重复计算,降低 GPU/CPU 压力,并提升端到端链路效率。 -
支持流式多模态推理协议
增强与主流多模态推理框架(如 OpenAI Realtime API、gRPC 流式接口、WebSocket)的无缝对接能力,实现帧级别的推理结果回传,将 VLM 延迟压缩到毫秒级。 -
边缘计算与事件过滤增强
在采集端或边缘节点内置轻量化 AI 模型,实现本地目标检测、行为识别、事件触发等前置处理,只将必要的视频或结构化信息传回中心 VLM,显著降低带宽消耗与中心计算压力。
这种演进路径,将使大牛直播SDK从“多模态输入通道”升级为“智能视频边缘节点”,为 VLA 与 VLM 提供更高效、更智能、更可控的实时数据支撑。
📎 CSDN官方博客:音视频牛哥-CSDN博客