【完整源码+数据集+部署教程】医学报告图像分割系统源码和数据集:改进yolo11-HGNetV2
背景意义
研究背景与意义
随着医学影像技术的快速发展,医学图像的分析与处理在临床诊断、疾病预防和治疗方案制定中扮演着越来越重要的角色。医学图像分割作为计算机视觉领域的一项关键技术,旨在从复杂的医学图像中提取出感兴趣的区域,帮助医生更准确地识别病变、评估病情和制定治疗方案。近年来,深度学习技术的进步,尤其是目标检测和分割模型的不断演化,为医学图像分割提供了新的解决方案。
YOLO(You Only Look Once)系列模型因其高效的实时处理能力和良好的准确性,已成为医学图像分割领域的重要工具。尤其是YOLOv11的改进版本,结合了更先进的网络结构和训练策略,能够在处理复杂的医学图像时实现更高的精度和更快的速度。通过对医学图像进行精确的分割,能够有效提高临床医生的工作效率,减少误诊率,从而提升患者的治疗效果。
本研究旨在基于改进的YOLOv11模型,构建一个高效的医学报告图像分割系统。该系统将利用一个包含2000幅医学图像的数据集,专注于单一类别的医学标签(medicine-label-gZ4c),为医学图像分析提供精准的分割结果。通过对数据集的深度学习训练,系统将不断优化其分割性能,力求在实际应用中实现更高的准确性和可靠性。
此外,随着医学影像数据的日益增长,传统的手动标注和分析方法已难以满足需求。基于深度学习的自动化分割系统不仅能够减轻医生的工作负担,还能为医学研究提供更为丰富的数据支持。通过本项目的实施,期望能够推动医学图像分割技术的发展,促进其在临床应用中的广泛普及,为提升医疗服务质量贡献力量。
图片效果
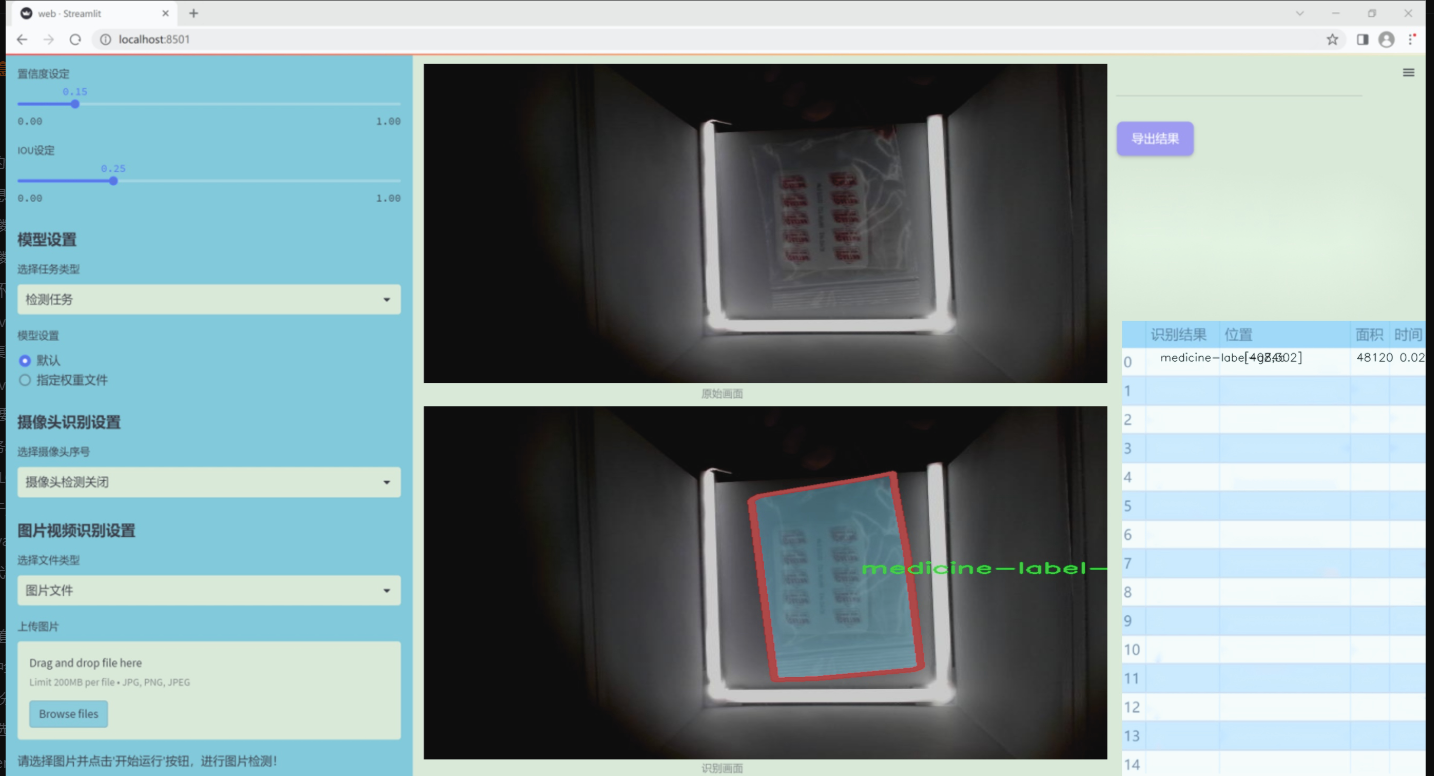
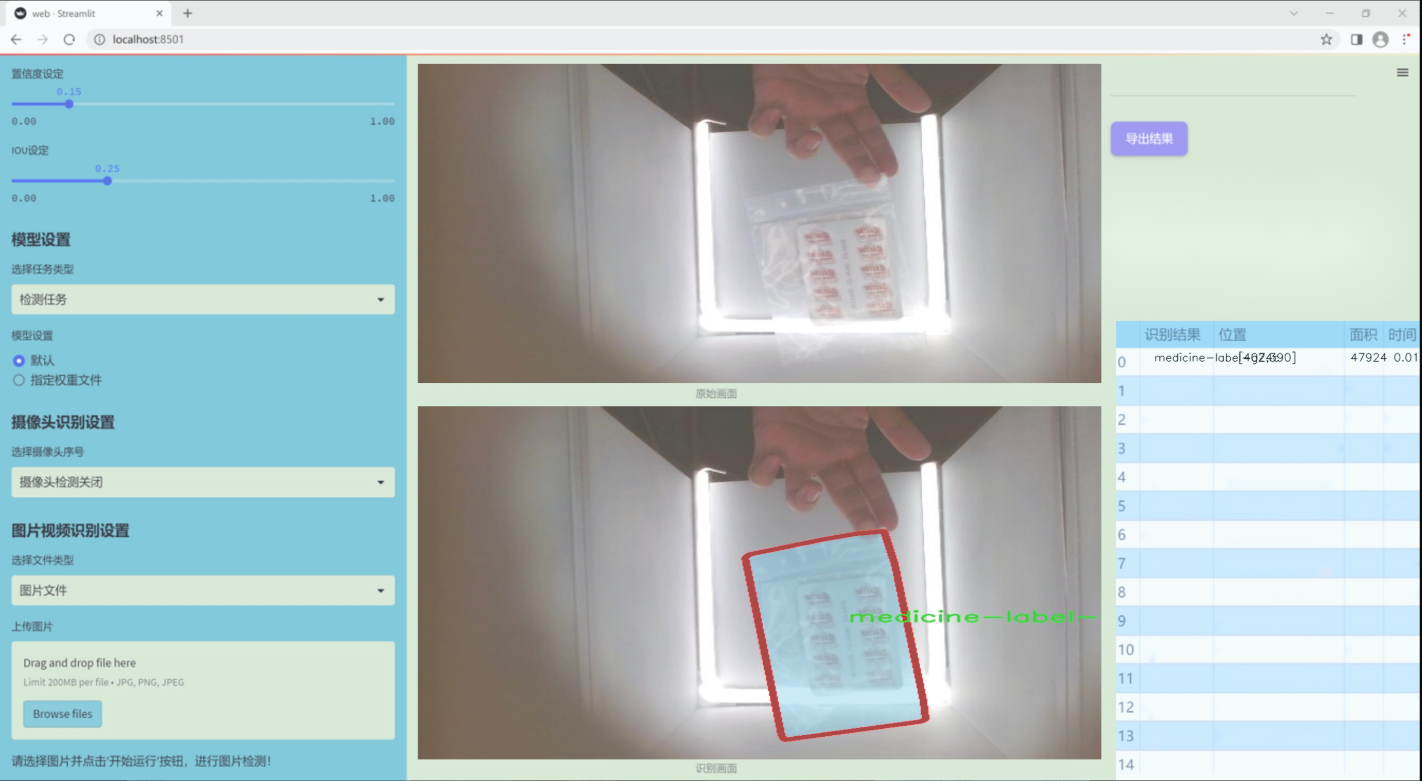
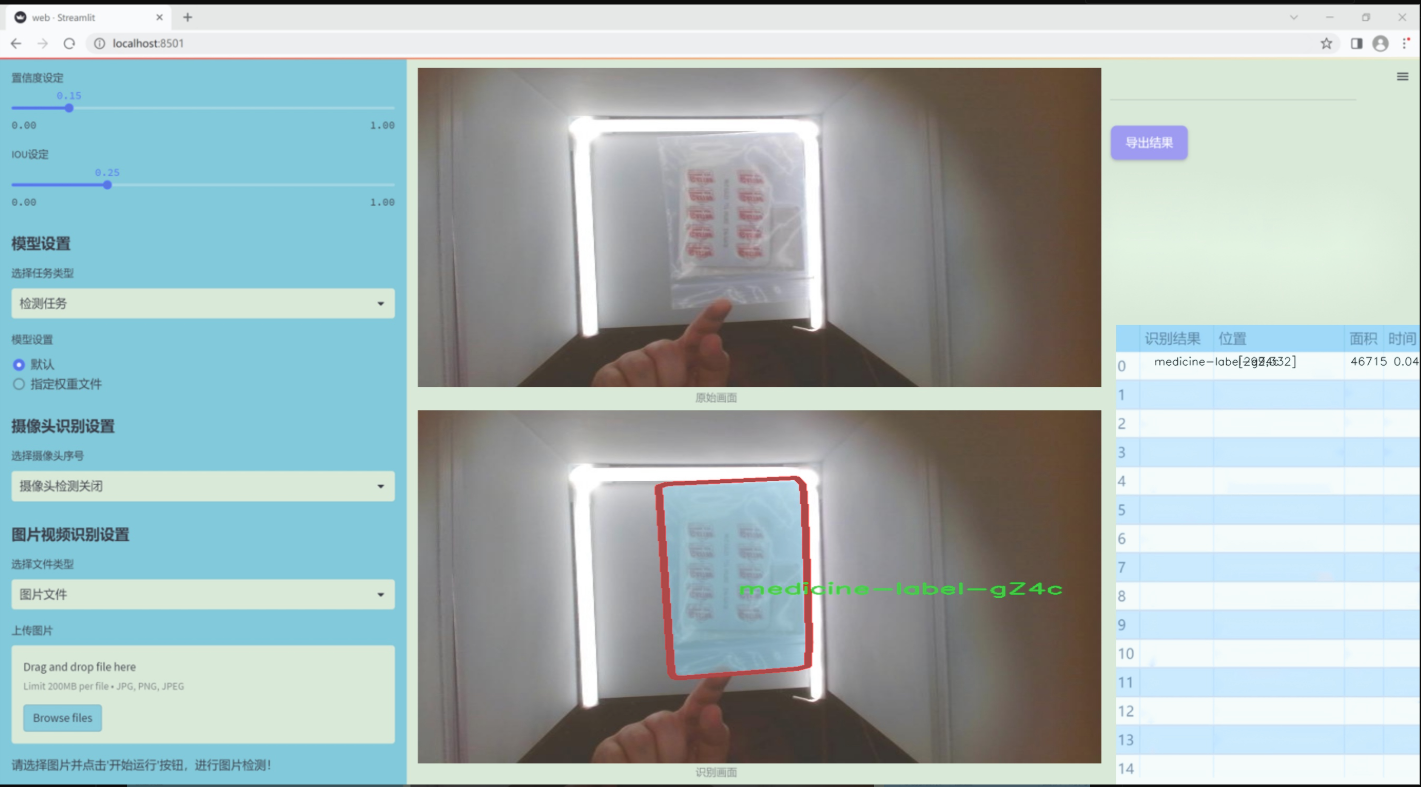
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的医学报告图像分割系统,为此我们构建了一个专门针对医学图像分割的高质量数据集,命名为“MedicineSegmentation”。该数据集的设计目标是为医学图像分析提供强有力的支持,尤其是在对医学报告中关键区域的自动分割和识别方面。数据集中包含的类别数量为1,具体类别为“medicine-label-gZ4c”,这一类别涵盖了医学图像中所需分割的特定区域,确保模型能够有效识别和处理医学图像中的重要信息。
在数据集的构建过程中,我们收集了大量的医学图像,涵盖了不同类型的医学报告和成像技术,包括但不限于X光片、CT扫描和MRI图像。每幅图像都经过精心标注,确保其标签的准确性和一致性,以便为YOLOv11模型的训练提供高质量的输入数据。这种高质量的标注不仅有助于提高模型的分割精度,还能增强其在实际应用中的可靠性。
数据集的多样性和丰富性使其成为医学图像分割研究的重要资源。通过对不同类型医学图像的分析,模型能够学习到多种特征和模式,从而提高其在复杂场景下的适应能力。此外,我们还注重数据集的平衡性,确保不同图像类型的样本数量相对均衡,以避免模型在训练过程中出现偏倚现象。
总之,本项目的“MedicineSegmentation”数据集为改进YOLOv11的医学报告图像分割系统提供了坚实的基础,期待通过这一数据集的应用,推动医学图像分析技术的发展,为临床诊断和治疗提供更为精准的辅助工具。





核心代码
以下是经过简化和注释的核心代码部分:
导入必要的模块
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
“”"
DetectionPredictor类用于基于检测模型进行预测,继承自BasePredictor类。
“”"
def postprocess(self, preds, img, orig_imgs):"""对预测结果进行后处理,并返回Results对象的列表。参数:preds: 模型的预测结果img: 输入图像orig_imgs: 原始图像(可能是torch.Tensor或numpy数组)返回:results: 包含处理后结果的Results对象列表"""# 应用非极大值抑制(NMS)来过滤预测框preds = ops.non_max_suppression(preds,self.args.conf, # 置信度阈值self.args.iou, # IOU阈值agnostic=self.args.agnostic_nms, # 是否使用类别无关的NMSmax_det=self.args.max_det, # 最大检测框数量classes=self.args.classes, # 需要检测的类别)# 如果输入的原始图像不是列表,则将其转换为numpy数组if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = [] # 存储处理后的结果for i, pred in enumerate(preds):orig_img = orig_imgs[i] # 获取对应的原始图像# 将预测框的坐标缩放到原始图像的尺寸pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i] # 获取图像路径# 创建Results对象并添加到结果列表中results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results # 返回处理后的结果列表
代码说明:
导入模块:导入了进行预测和结果处理所需的模块。
DetectionPredictor类:该类继承自BasePredictor,用于实现基于YOLO模型的目标检测预测。
postprocess方法:该方法对模型的预测结果进行后处理,包括应用非极大值抑制(NMS)来过滤重叠的预测框,并将预测框的坐标缩放到原始图像的尺寸。
结果存储:处理后的结果被存储在Results对象中,并最终返回一个包含所有结果的列表。
这个程序文件 predict.py 是一个用于目标检测的预测类,继承自 BasePredictor 类,属于 Ultralytics YOLO 框架的一部分。该类的主要功能是处理目标检测模型的预测结果,并将其后处理为可用的格式。
在文件开头,导入了必要的模块,包括 BasePredictor、Results 和 ops,这些模块提供了基础的预测功能、结果处理以及一些操作函数。
DetectionPredictor 类中定义了一个 postprocess 方法,该方法用于对模型的预测结果进行后处理。具体来说,它接收三个参数:preds(模型的预测结果)、img(输入图像)和 orig_imgs(原始图像)。在方法内部,首先调用 ops.non_max_suppression 函数对预测结果进行非极大值抑制,以去除冗余的框,并根据给定的置信度阈值、IoU 阈值等参数进行过滤。
接下来,代码检查 orig_imgs 是否为列表类型。如果不是,说明输入的图像是一个 PyTorch 张量,此时需要将其转换为 NumPy 数组。转换后,程序会创建一个空的 results 列表,用于存储每个图像的处理结果。
然后,程序遍历每个预测结果,获取对应的原始图像,并对预测框进行缩放,以适应原始图像的尺寸。最后,将处理后的结果封装成 Results 对象,包括原始图像、图像路径、模型名称和预测框信息,并将其添加到 results 列表中。
最终,postprocess 方法返回包含所有处理结果的列表,供后续使用。这段代码展示了如何将目标检测模型的输出结果进行有效处理,以便于后续的分析和展示。
10.4 deconv.py
以下是经过简化和注释的核心代码部分:
import math
import torch
from torch import nn
from einops.layers.torch import Rearrange
定义一个自定义的卷积层类 Conv2d_cd
class Conv2d_cd(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=1,
padding=1, dilation=1, groups=1, bias=False, theta=1.0):
super(Conv2d_cd, self).init()
# 初始化标准的2D卷积层
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.theta = theta # 可调参数 theta
def get_weight(self):# 获取卷积层的权重conv_weight = self.conv.weightconv_shape = conv_weight.shape # 获取权重的形状# 将权重重排为 (c_in, c_out, k1*k2) 的形状conv_weight = Rearrange('c_in c_out k1 k2 -> c_in c_out (k1 k2)')(conv_weight)# 创建一个新的权重张量并初始化为0conv_weight_cd = torch.zeros(conv_shape[0], conv_shape[1], 3 * 3, device=conv_weight.device, dtype=conv_weight.dtype)# 将原权重复制到新权重张量conv_weight_cd[:, :, :] = conv_weight[:, :, :]# 计算新的权重conv_weight_cd[:, :, 4] = conv_weight[:, :, 4] - conv_weight[:, :, :].sum(2)# 重排回原来的形状conv_weight_cd = Rearrange('c_in c_out (k1 k2) -> c_in c_out k1 k2', k1=conv_shape[2], k2=conv_shape[3])(conv_weight_cd)return conv_weight_cd, self.conv.bias # 返回新的权重和偏置
定义一个自定义的卷积层类 Conv2d_ad
class Conv2d_ad(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=1,
padding=1, dilation=1, groups=1, bias=False, theta=1.0):
super(Conv2d_ad, self).init()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.theta = theta
def get_weight(self):# 获取卷积层的权重conv_weight = self.conv.weightconv_shape = conv_weight.shape# 重排权重conv_weight = Rearrange('c_in c_out k1 k2 -> c_in c_out (k1 k2)')(conv_weight)# 计算新的权重conv_weight_ad = conv_weight - self.theta * conv_weight[:, :, [3, 0, 1, 6, 4, 2, 7, 8, 5]]# 重排回原来的形状conv_weight_ad = Rearrange('c_in c_out (k1 k2) -> c_in c_out k1 k2', k1=conv_shape[2], k2=conv_shape[3])(conv_weight_ad)return conv_weight_ad, self.conv.bias # 返回新的权重和偏置
定义一个自定义的卷积层类 DEConv
class DEConv(nn.Module):
def init(self, dim):
super(DEConv, self).init()
# 初始化多个自定义卷积层
self.conv1_1 = Conv2d_cd(dim, dim, 3, bias=True)
self.conv1_2 = Conv2d_ad(dim, dim, 3, bias=True)
self.conv1_5 = nn.Conv2d(dim, dim, 3, padding=1, bias=True)
self.bn = nn.BatchNorm2d(dim) # 批归一化层self.act = nn.ReLU() # 激活函数def forward(self, x):# 前向传播w1, b1 = self.conv1_1.get_weight() # 获取第一个卷积层的权重和偏置w2, b2 = self.conv1_2.get_weight() # 获取第二个卷积层的权重和偏置w5, b5 = self.conv1_5.weight, self.conv1_5.bias # 获取最后一个卷积层的权重和偏置# 将所有权重和偏置相加w = w1 + w2 + w5b = b1 + b2 + b5# 使用加权后的卷积层进行卷积操作res = nn.functional.conv2d(input=x, weight=w, bias=b, stride=1, padding=1, groups=1)# 应用批归一化和激活函数res = self.bn(res)return self.act(res)def switch_to_deploy(self):# 部署模式下,合并卷积层的权重和偏置w1, b1 = self.conv1_1.get_weight()w2, b2 = self.conv1_2.get_weight()w5, b5 = self.conv1_5.weight, self.conv1_5.biasself.conv1_5.weight = torch.nn.Parameter(w1 + w2 + w5) # 合并权重self.conv1_5.bias = torch.nn.Parameter(b1 + b2 + b5) # 合并偏置# 删除不再需要的卷积层del self.conv1_1del self.conv1_2
下面的代码用于测试模型
if name == ‘main’:
data = torch.randn((1, 128, 64, 64)).cuda() # 创建一个随机输入数据
model = DEConv(128).cuda() # 初始化模型
output1 = model(data) # 前向传播得到输出
model.switch_to_deploy() # 切换到部署模式
output2 = model(data) # 再次前向传播得到输出
print(torch.allclose(output1, output2)) # 检查两个输出是否相近
代码说明:
Conv2d_cd 和 Conv2d_ad:这两个类实现了自定义的卷积层,分别用于不同的权重计算方式。get_weight 方法用于获取调整后的卷积权重。
DEConv:这个类组合了多个卷积层,并在前向传播中计算它们的输出。switch_to_deploy 方法用于合并卷积层的权重和偏置,以便在推理时减少计算量。
测试部分:在 main 中创建了一个随机输入并测试模型的输出是否一致,验证了模型的正确性。
这个程序文件 deconv.py 定义了一些自定义的卷积层以及一个组合这些卷积层的模块 DEConv。主要功能是实现一些特定的卷积操作,可能用于深度学习中的图像处理任务。
首先,文件导入了必要的库,包括 math、torch 和 torch.nn,以及一些用于张量重排的工具 Rearrange 和自定义的卷积模块 Conv。接着,定义了多个卷积类,每个类都继承自 nn.Module。
Conv2d_cd 类实现了一种特定的卷积操作。它在初始化时创建了一个标准的 2D 卷积层,并定义了一个 get_weight 方法,该方法对卷积权重进行重排和处理,返回处理后的权重和偏置。
Conv2d_ad 类类似,但在 get_weight 方法中进行了不同的权重调整,使用了一个参数 theta 来影响权重的计算。
Conv2d_rd 类则在前向传播中实现了条件逻辑,如果 theta 接近零,则执行标准卷积;否则,使用处理后的权重进行卷积操作。
Conv2d_hd 和 Conv2d_vd 类分别实现了不同的卷积权重处理逻辑,都是通过 get_weight 方法返回处理后的权重和偏置。
DEConv 类是一个更复杂的模块,它组合了前面定义的多个卷积层。它在初始化时创建了多个卷积层,并在 forward 方法中将这些卷积层的权重和偏置进行相加,最终通过一个标准的卷积操作得到输出。该类还包含了批归一化和激活函数的应用。
switch_to_deploy 方法用于将模型切换到部署模式,它将所有卷积层的权重和偏置合并到最后一个卷积层中,并删除前面的卷积层,以减少模型的复杂性和提高推理速度。
在文件的最后部分,提供了一个简单的测试示例,创建了一个随机输入数据并通过 DEConv 模型进行前向传播,随后切换到部署模式并再次进行前向传播,最后检查两次输出是否相等。
整体来看,这个文件实现了一些自定义的卷积操作,主要用于深度学习模型中的特定需求,可能涉及到图像处理或特征提取等任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻