Qwen2.5-vl源码解读系列:ImageProcessor
参考视频:Qwen2.5-VL源码解读-Qwen2VLImageProcessor_哔哩哔哩_bilibili
前文:Qwen2.5-vl源码解读系列:图片预处理部分-CSDN博客
在上一篇博客中,输入原图经过process_vision_info做了resize处理。现在将预处理后的图像传入processor中做进一步的处理得到模型输入需要的形态(pixel和image_grid)。
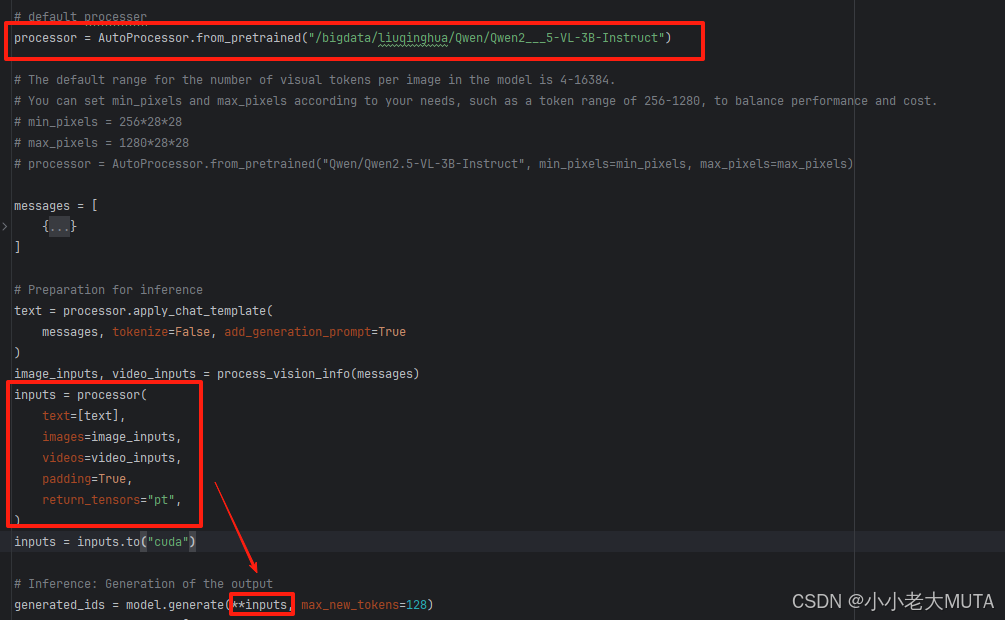
这里的AutoProcessor,在图像部分实际进入的是QwenVLImageProcessor,继承的BaseImageProcessor。

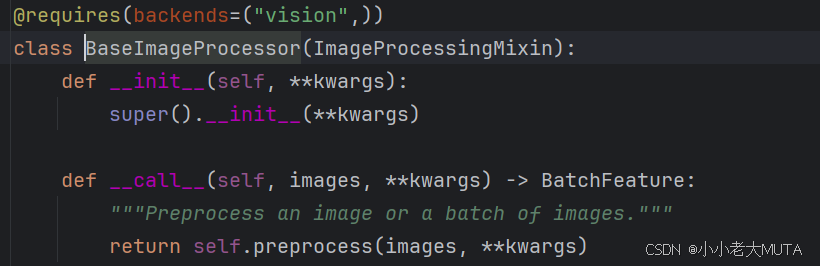
在BaseImageProcessor中使用了__call__函数,使得创建了类的实例后(BaseImageProcessor/QwenVLImageProcessor),能够直接像调用函数一样直接执行__call__函数中的内容,也就是preprocess部分。
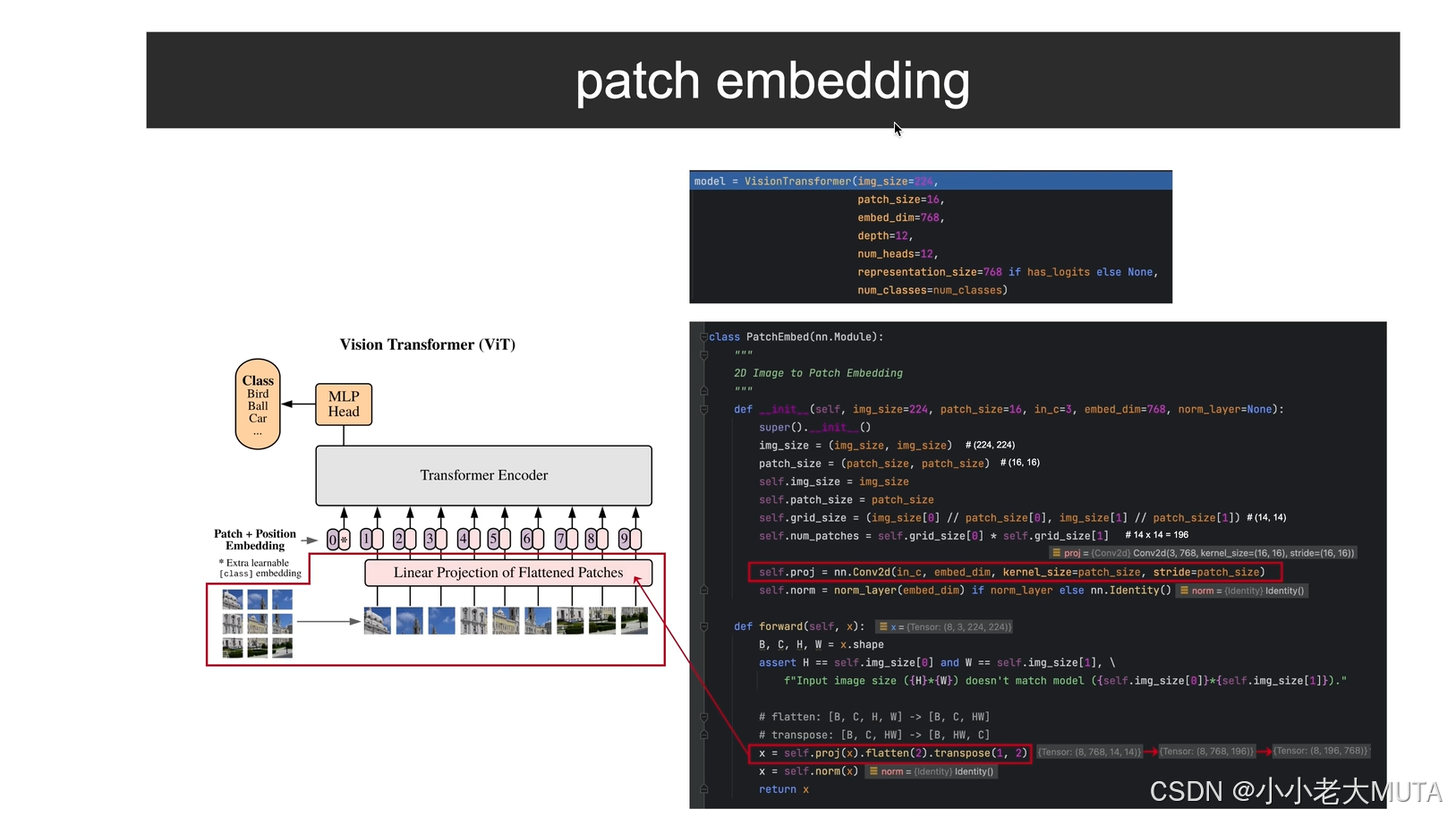
在prerocess中,实际执行了三部分操作,最初得到能够传入模型的flatten_patch和img_grid:

(1) do_resize/do_scale/do_normalize/channel_dimension_format
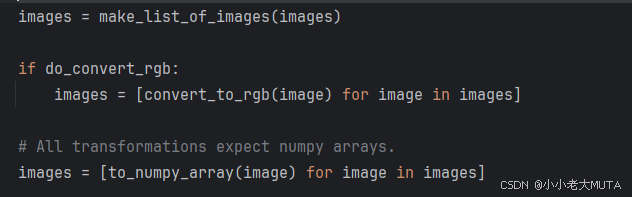
首先需要执行:输入图像转换为列表格式;图像转RGB格式;图像转numpy格式。
然后根据do_resize/do_rescale/do_normalize决定是否进行操作。
在之前的process_vision_info中已经进行了smart_resize的操作,所以这里不需要。
resize部分就是使得图像尽可能保留原生分辨率,避免额外缩放或失真;
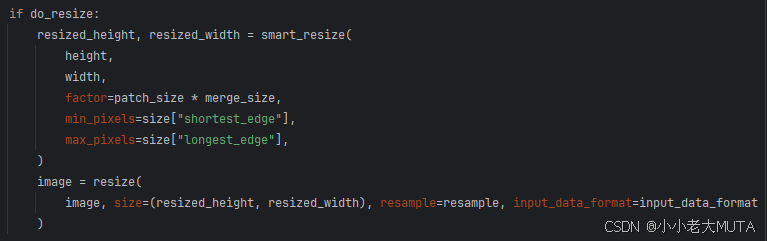
rescale部分就是是对图像像素值进行缩放,即将[0,255]转换到[0,1];
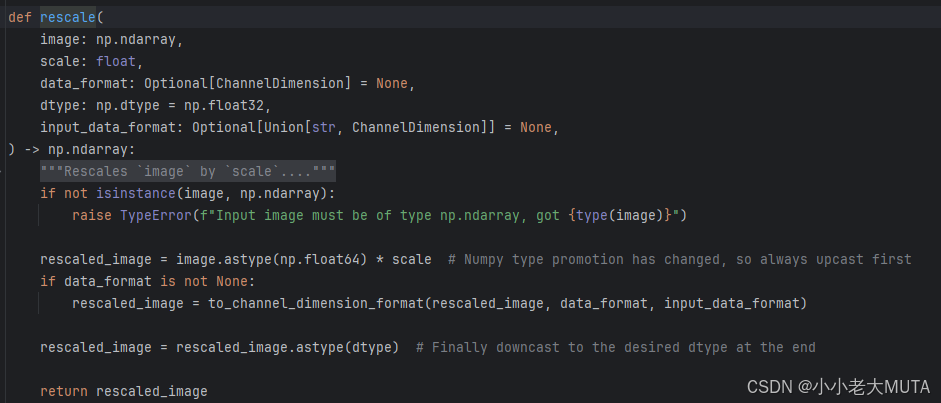
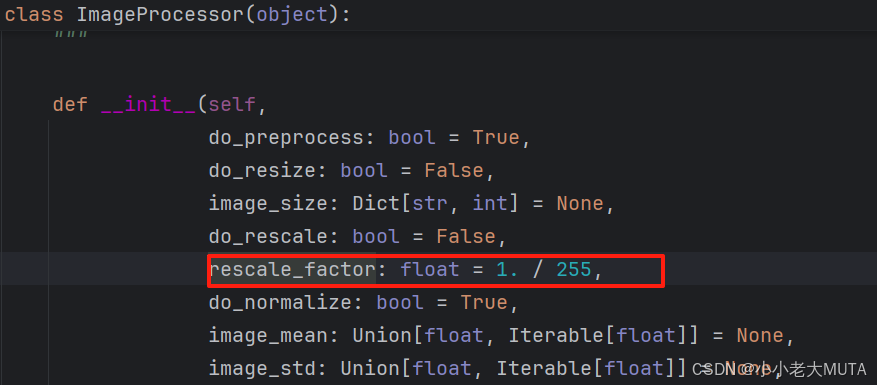
normalize部分就是归一化:
归一化后像素值=(原像素值-均值mean)/ 标准差std
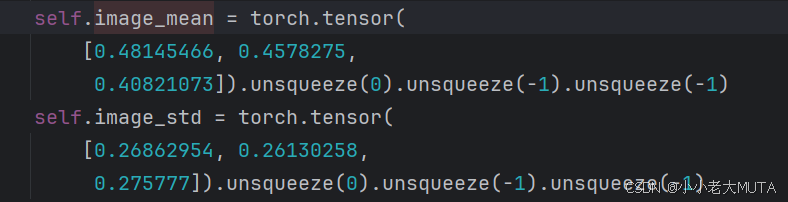
图像均值和标准差是通过对训练的数据集的所有图像像素进行统一计算求得,目的是让预处理符合数据的真实分布特性。
归一化的目的是使得图像数据分布更加稳定(让均值接近0,标准差接近1),使得模型更快收敛,避免梯度异常。

channel_dimmension_format主要是保证输入模型的维度一致,在这里对image的维度进行操作,将[h,w,c]的维度转换为了[c,h,w]
将所有图片堆叠,最后process_images的维度就是[N,c,h,w],N是图像数量。


(2) 每张图片复制temporal_patch_size次(默认2)
先确保patches的维度是[N,c,h,w];
然后判断N也就是图片个数是否是temporal_patch_size(2)的倍数;
如果不是就要执行复制操作;

这里执行repeat操作是因为想让图片和视频的处理逻辑相同,而在视频中是将连续两帧的图片组合成一组;所以对单独的图片则是直接复制为2个。
可以把temporal_patch_size理解为时间维度。
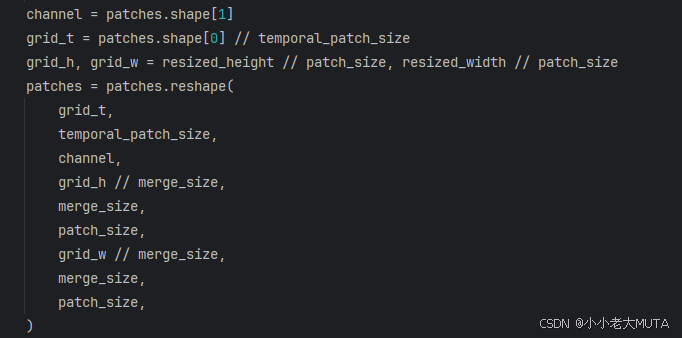
(3) patch展平(不是直接展平,而是由窗口展平)
先计算需要channel,grid_t,grid_h,grid_w(temporal_path_size=2;patch_size=14);
然后直接reshape成9维的向量:
然后经过维度顺序的调整:
再次reshape,得到最终想要的形态:

先简单画一下,有空再美化😊。
可以理解为积木,把一个pixel像素理解为一块积木,pixel是一个固定标量;
原本resize后的image是3*224*358,然后为了和视频一样的处理方式,所以重复了一次,也就是现在是2*3*224*358,然后就是各种打乱重新排列的操作。
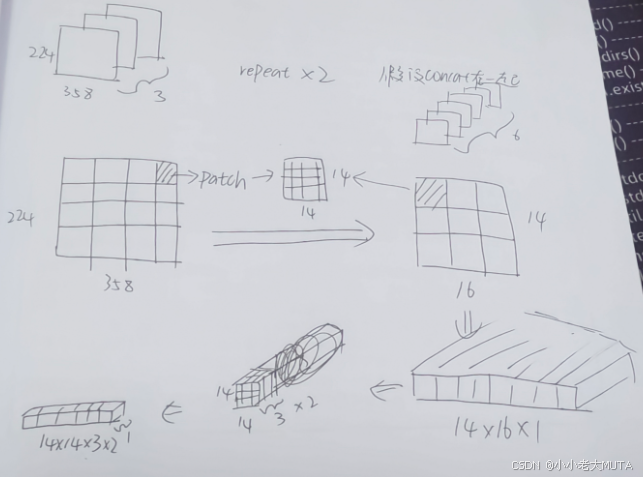
不过注意这里展平并不是直接展平,而是先在2*2的窗口中展平,然后再按照窗口依次展平。(参考视频中的讲解)
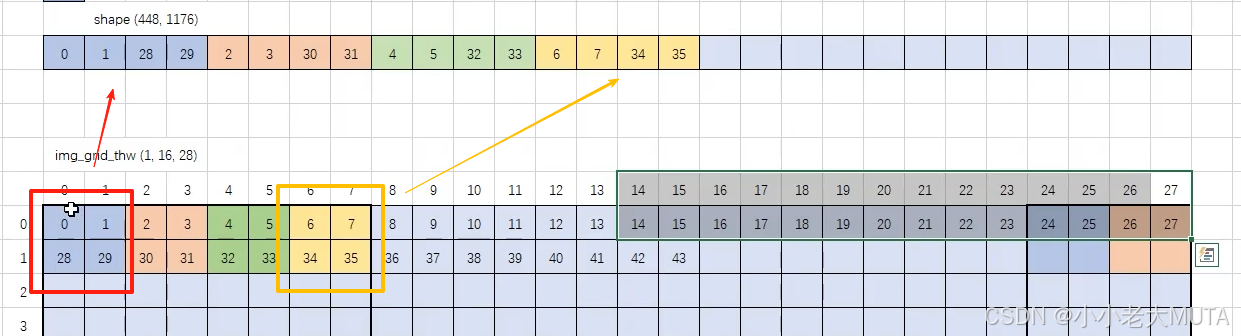
这里维度的变化并不涉及到投影之类的操作,和VIT中的操作其实不一样。
在vit中输入图像[3,h,w]原始维度是3,然后经过线性映射得到的hidden_dim的维度。