应用层模拟面试题
模拟面试-C++
第一题(开发音视频处理模块)
在开发音视频处理模块时,FFmpeg资源(AVFrame*)需要自动释放。如何用unique_ptr定制删除器替代手动av_frame_free()?写出代码并解释RAII优势。
参考答案:
auto frame_deleter=[](AVFrame* ptr){av_frame_free(&ptr);}; std::unique_ptr<AVFrame,decltypt(frame_deleter)>frame(av_frame_alloc(),frame_deleter);优势:
异常安全:函数提前退出时自动释放资源
所有权明确:禁止拷贝,转移需用std::move
第二题(日志系统需要创建LogEntry对象)
日志系统需要创建LogEntry对象,其构造函数含std::string初始化。为何用emplace_back替代push_back可提升性能?移动语义在此过程如何生效?
=====================================================================参考答案:
push_back问题:先构造临时对象,再移动/拷贝到容器
emplace_back优化:直接在容器内存构造对象(完美转发参数)
//性能对比 std::vector<LogEntry> logs; logs.push_back(LogEntry("Error", 404)); // 1次构造+1次移动 logs.emplace_back("Error", 404); // 仅1次构造
第三题(两个类Device和Controller互相持有shared_ptr)
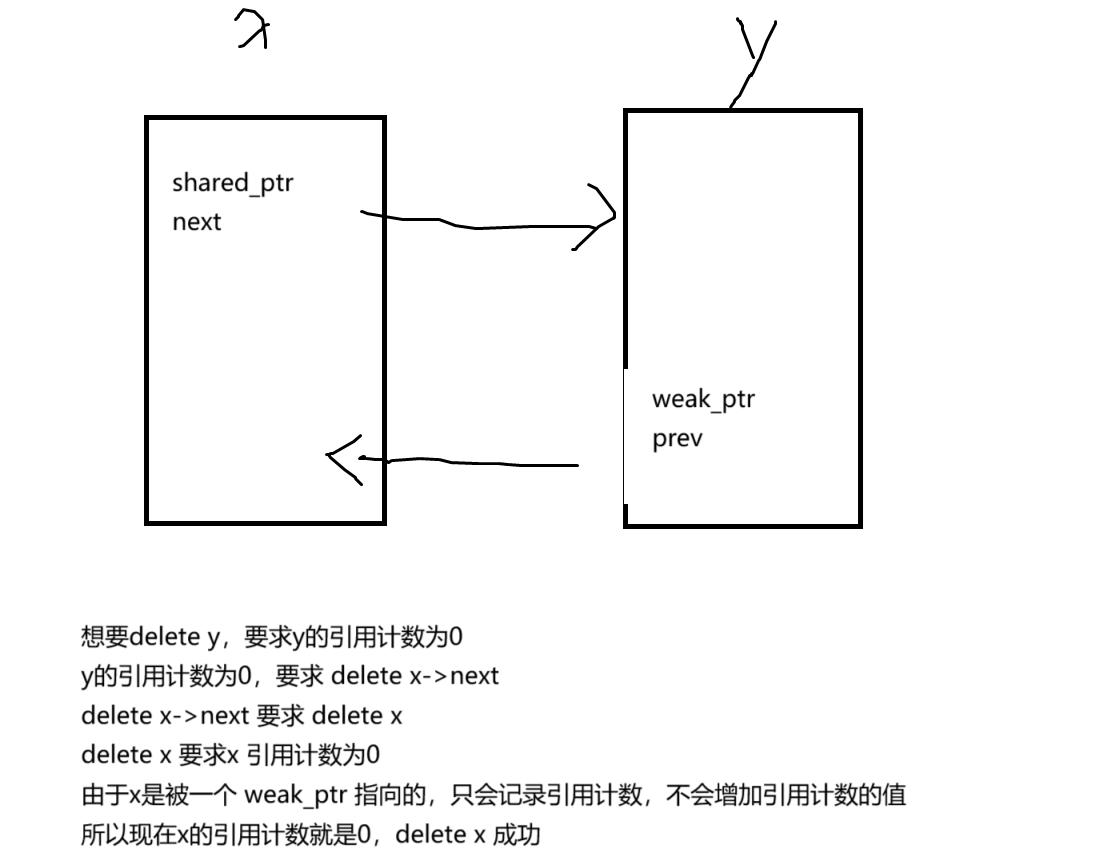
两个类Device和Controller互相持有shared_ptr,导致内存泄漏。如何用weak_ptr打破循环引用?画出引用计数变化图。
=====================================================================
参考答案:
class Controller { public:std::shared_ptr<Device> dev; // 强引用 };class Device { public:std::weak_ptr<Controller> ctrl; // 弱引用不增加计数 };弱智能指针:专门用来解决循环引用问题的一个智能指针
weak_ptr 虽然有引用计数,但是被 weak_ptr 指向的地址,仅仅会被 weak_ptr 观察并记录引用计数的值,并不会增加
weak_ptr 的特点
weak_ptr 是专门、也只能用来解决 shared_ptr 循环引用的问题
所以 weak_ptr 是没有任何针对指针的操作
说人话就是:weak_ptr 没有重载 operator* 和 operator-> 函数使用时候,将weak_ptr 临时转换成 shared_ptr
使用 weak_ptr 里面一个叫做 lock的函数
通过lokc函数转换出来的shared_ptr也是一个临时的shared_ptr,用完就会被释放,不影响引用计数weak_ptr<int> p2=p1;//弱智能指针可以直接指向共享智能指针,并获取该共享智能指针的引用计数,但是不会+1; cout<<*p2.lock()<<endl;
第四题(游戏引擎需频繁创建/销毁Enemy对象)
游戏引擎需频繁创建/销毁Enemy对象,直接new/delete导致内存碎片。如何用placement new和内存池优化?说明避免malloc次数统计的方法。
=====================================================================
参考答案:
核心步骤: 01.预分配大块内存:char* pool = new char[POOL_SIZE] 02.对象构造:Enemy* e = new (pool + offset) Enemy() 03.手动析构:e->~Enemy() 04.统计技巧:重载类专属operator new/delete
第五题(实现高性能网络服务器)
在实现高性能网络服务器时,接收到的数据包Packet对象需要传递给处理线程。已知Packet包含大量数据(如std::vector<uint8_t> payload)。
问:
如何通过移动语义避免数据复制?请说明push_back时std::move的作用原理,并解释为何移动构造函数应声明为noexcept。// 使用场景 std::queue<Packet> packet_queue; Packet new_packet = receive_packet(); packet_queue.push_back(std::move(new_packet)); // 避免payload深拷贝关键点:
std::move将左值转为右值,触发移动构造
noexcept保证容器重分配时不回退到拷贝构造
移动后源对象处于有效但未定义状态(不应再使用)
自己的理解:int main(int argc,const char** argv){Stu zs;Stu ls = zs;// 拷贝构造 = 创建新对象ls,并且将zs里面的值赋值给lsStu ww = Stu();// 这里是一次普通构造,最终结果是,Stu()构建的临时对象,他内部所有数据的最终所有权,被编译器优化,变成了ww,即ww 的地址和 = 右侧 Stu() 临时对象地址是一样的 )return 0; }什么样的高效操作:临时对象管理的内存直接移交给 = 左侧的长生命周期对象进行管理
Stu zs; 普通构造 Stu ls = move(zs); 移动构造 move(zs)会创建一个新的临时对象,并让ls接管该对象 Stu ww = zs; 拷贝构造 ww会创建新的对象,并且去拷贝zs里面的所有数据所以从描述上来说,一定是移动构造效率更高
第六题(匿名函数)
在算法中使用自定义比较或操作逻辑时,定义完整的命名函数或仿函数 (functor) 类有时显得繁琐,尤其当逻辑很简单且只使用一次时。我们需要一种更简洁、更灵活的方式在调用点就地定义匿名函数。
参考答案:
=====================================================================
1:C++11 Lambda 表达式的基本语法结构是什么?[capture-list] (parameters) -> return-type { body } 各部分的作用是什么?(特别强调 capture-list)
2:捕获列表 (capture-list) 有几种主要捕获方式?解释 按值捕获 [=]、按引用捕获 [&]、捕获特定变量 [x, &y] 的含义和行为。按值捕获的变量在 Lambda 体内能被修改吗?如何使其可修改?(mutable)
3:Lambda 表达式在底层是如何实现的?(通常被编译器转换为一个匿名的函数对象类 (仿函数))。
4:以下代码中,Lambda 捕获了局部变量 factor 和 threshold。当 processData 函数返回后,存储了该 Lambda 的函数指针 func 还能被安全调用吗?为什么?
#include <functional> std::function<void(int&)> processData(int threshold){int factor=2;auto lambda=[factor,threshold](int& value) mutable{value=value*factor;if(value>threshold) value=threshold;};return lambda; } auto func=processData(100); int num=50; func(num);//安全吗?????技术考察点:
掌握 Lambda 的基本语法和核心组成部分。
深入理解捕获列表:这是 Lambda 的核心难点和易错点。清楚区分按值和按引用捕获的语义、生命周期影响以及 mutable 的作用。
理解 Lambda 的底层实现原理(仿函数),知道它是如何携带状态的(捕获的变量成为匿名类的成员)。
考察对 变量生命周期 和 悬空引用 问题的敏感度(按引用捕获局部变量后,局部变量销毁会导致 Lambda 内引用无效)。
第七题(自动推导变量类型)
C++ 类型系统强大但有时类型名非常冗长(如迭代器、模板实例化结果、复杂表达式结果),手动写出完整类型既繁琐又容易出错。我们需要编译器帮助我们自动推导变量类型。
参考答案:
=====================================================================
1:C++11 中 auto 关键字的主要用途是什么?
2:auto 的类型推导规则通常遵循什么原则?(与模板参数推导规则类似)
3:以下代码片段的推导结果是什么?为什么?
4:使用 auto 时,哪些情况可能导致意外或不直观的类型推导结果?(例如推导出 std::initializer_list 或代理对象类型如 vector<bool>::reference)
auto a=42;//a的类型是? const int ci=10; auto b=ci;//b的类型是什么?const属性还在吗? auto c=ci;//c的类型是? auto d=&ci;//d的类型是什么? std::vector<int> vec; auto it=vec.begin();//it的类型是什么?(迭代器类型通常很冗长)技术考察点:
理解 auto 的核心价值:简化代码、避免冗长类型名、提高可维护性、防止隐式类型转换错误。
掌握 auto 推导的基本规则:忽略顶层 const 和引用(除非显式指定 auto& 或 const auto&),推导表达式结果的类型。
理解 auto 与引用、指针、const 结合时的具体推导结果。
了解 auto 使用的潜在陷阱(如代理对象、initializer_list 推导),知道何时需要小心或显式指定类型。
第八题(遍历容器(如数组、vector、list、map)元素是常见操作)
遍历容器(如数组、vector、list、map)元素是常见操作,使用传统的迭代器或下标循环代码相对冗长且容易出错(如迭代器失效、下标越界)。我们需要一种更简洁、更安全的遍历语法。
考察点:
=====================================================================
1:C++11 范围 for 循环 (for (elem : container),自动迭代法) 的基本语法和优势是什么?
2:范围 for 循环在底层是如何实现的?(通常被编译器转换为基于迭代器的传统循环)
3:以下两种写法在遍历 std::vector<int> 时有何本质区别?哪种方式修改元素会影响原容器?哪种方式效率更高?
//写法1 for(auto value:vec){/*...*/} //写法2 for(auto& value:vec){/*...*/}(这题好像有问题,各位可以自己测试一下)
4:在范围 for 循环体内修改容器本身(如添加或删除元素)通常会发生什么?为什么?(引出 迭代器失效 问题)
参考答案:
=====================================================================
技术考察点:
理解范围 for 的核心优势:简洁、安全(避免手动管理迭代器/下标)、语义清晰。
了解其底层实现依赖于容器的 begin() 和 end() 成员函数或自由函数(ADL)。
深刻理解按值遍历 (auto elem) 与 按引用遍历 (auto& elem 或 const auto& elem) 的区别:前者是元素副本,后者是元素别名。按引用遍历才能修改原容器元素,且避免拷贝开销(对大型对象或容器重要)。
理解在循环体内修改容器结构(增删元素)极易导致迭代器失效,进而引发未定义行为 (UB)。知道范围 for 循环对此不提供额外保护。
第九题(空指针字面量 NULL 为什么修改为nullptr??)
C++ 中传统的空指针字面量 NULL 通常被定义为 0 或 (void*)0。这可能导致函数重载解析时的歧义(整型 0 vs 指针类型)和类型安全问题。
1:C++11 引入 nullptr 的主要动机是什么?它解决了 NULL 的什么问题?
2:nullptr 是什么类型?(std::nullptr_t,可以隐式转换为任何指针类型和成员指针类型,但不能转换为整数类型)
3:给出一个例子说明 NULL 可能导致重载解析歧义,而 nullptr 可以避免。
void func(int); void func(char*); func(NULL);//可能调用哪个???(通常是func(int),不符合预期) func(nullptr);//可以明确调用哪个???参考答案:
=====================================================================
技术考察点:
理解 NULL 的历史问题(本质是整数 0 而非真正的指针类型)。
理解 nullptr 的核心优势:具有明确的指针类型 (std::nullptr_t),消除了重载歧义,提高了类型安全。
知道 nullptr 应该成为表示空指针的首选方式。
第十题(利用多核处理器提高性能或响应性)
现代程序需要利用多核处理器提高性能或响应性,C++11 之前缺乏标准化的线程库,需要依赖平台特定 API (如 pthreads, Win32 Threads),代码可移植性差。
1:C++11 如何创建一个新线程?基本步骤是什么?(#include <thread>, std::thread t(func, args...))
2:为什么在多线程环境下访问共享数据通常需要同步?常见的同步原语有哪些?(引出 std::mutex)
3:如何使用 std::mutex 保护共享数据的访问?基本代码模式是怎样的?
std::mutex mtx; int shared_data; void safe_increment(){std::lock_guard<std::mutex> lock(mtx);//RAII 锁++shared_data; }4:std::lock_guard 的作用是什么?
参考答案:
=====================================================================
技术考察点 (初级要求):
知道 C++11 提供了标准化的线程库 <thread>。
理解创建线程的基本方法 (std::thread)。
理解 数据竞争 (Data Race) 的概念和危害。
知道最基本的同步机制是 互斥锁 (std::mutex)。
掌握 std::lock_guard 的 RAII 用法:这是初级开发者必须掌握的安全加锁模式,确保锁在作用域结束时自动释放,避免忘记解锁导致死锁。理解 RAII 在此处的应用。
第11题(override关键字作用,运行时多态计算薪资)
公司需要管理不同类型员工(普通员工Employee、经理Manager)的薪资计算。普通员工按月薪计算,经理有基本工资+奖金。要求统一接口计算薪资。
1:如何设计基类和派生类实现运行时多态计算薪资?
2:若不将基类的calculateSalary()声明为虚函数会怎样?
3:C++11的override关键字有什么作用?
4:以下代码输出什么?为什么?
Employee* emp=new Manager("Alice",5000,2000); std::cout<<emp->calculateSalary();//基类方法未声明virtual delete emp;参考答案:
=====================================================================
override作用:
显式标记重写虚函数
编译器检查签名是否匹配
避免隐藏(hide)错误
第11题(安全数组容器)
需要实现安全数组容器,支持不同类型数据,提供边界检查。
1:如何用类模板实现通用数组?
2:成员函数在类外定义时要注意什么?
3:C++11的using别名相比typedef有何优势?:
4:模板实例化过程是怎样的?
参考答案:
=====================================================================
using优势:
更清晰直观(类似变量赋值)
支持模板别名
//typedef旧语法 typedef SafeArray<int,10> IntArray;//C++11 using using IntArray=SafeArray<int,10>;//模板别名(typedef无法实现) template<typename T> using Vec=std::vector<T>;
第12题(函数模板实现)
需要实现获取两个值中最大值的通用函数。
1:如何用函数模板实现?:
2:调用时类型如何推导?
3:C++11的decltype和尾返回类型有什么用?
4:以下代码问题在哪?
template<typename T,typename U> auto max(T a,U b){return a>b?a:b;} auto result=max(3,4.5);//返回值类型是什么??decltype与尾返回类型 语法如下:
template<typename T,typename U> auto max(T a,U b)->decltype(a>b?a:b){return a>b?a:b; }解决返回类型依赖参数的问题
保持类型推导能力
第13题(多态机制对调试)
理解多态机制对调试和性能优化至关重要。
1:虚函数表(vtable)是什么?
2:动态绑定如何实现?
3:C++11的final关键字有什么用?:
4:+以下代码内存布局是怎样的
class Base{virtual void foo(){}int x; }; class Derived:public Base{void foo() override{}int y; }final作用:
禁止重写虚函数:virtual void foo() final;
禁止类被继承:class Base final {};
第14题(模板全特化)
通用打印函数需要对字符串类型特殊处理。
1:如何实现模板全特化?
2:部分特化在类模板中如何使用?
3:以下代码输出什么?
template<typename T> void print(T value){std::out<<"Generic:"<<value<<std::endl; }template<> void print<const char*>(const char* str){std::out<<"String:"<<str<<std::endl; }print(42); print("Hello");
模拟面试IO
第1题(文件 I/O 和标准 I/O 的区别)
“在开发订单系统时,内存中的交易数据需实时写入文件防止丢失。请解释文件 I/O 和标准 I/O 的区别,以及为何标准 I/O 更适合高频写入?”
参考答案:
=====================================================================
文件 I/O:直接使用 Linux 系统调用(如 open/read/write),无缓冲区,每次操作触发内核切换,适合低延迟场景。
标准 I/O:C 库函数(如 fopen/fprintf)自带缓冲区,减少系统调用次数。例如全缓冲模式填满缓冲区才写入磁盘,显著降低高频写入的磁盘压力。
选择依据:订单系统需频繁写小数据,标准 I/O 的缓冲机制可合并多次写入,避免频繁内核切换,提升吞吐量。
第2题(文件 I/O 和标准 I/O 的区别)
“用 lseek 跳过 1GB 后写入 1 字节,实际磁盘占用仅 4KB。请解释空洞文件的原理及应用场景。
参考答案:
=====================================================================
原理:文件偏移量超越物理存储时,内核记录“空洞”,实际磁盘块仅分配写入区域。du 命令显示逻辑大小,ls 显示物理占用。
应用:数据库预分配大文件避免碎片,下载工具创建占位文件。
第3题(守护进程)
“如何将 Web 服务转为守护进程?关键步骤为何要两次 fork?”
参考答案:
=====================================================================
首次 fork 后父进程退出,子进程成为孤儿进程(脱离终端控制)。
调用 setsid() 创建新会话,脱离终端关联。
二次 fork 避免子进程重新获取终端(非会话首领进程无法打开终端)。
关闭文件描述符、重定向标准流到 /dev/null
AI答案:
守护进程化的完整关键步骤:
首次fork:父进程退出,子进程成为孤儿进程并被init进程收养,脱离终端控制
调用setsid():创建新会话,子进程成为会话首领,彻底脱离原终端
二次fork:
避免子进程成为会话首领,防止其重新打开控制终端
确保进程不是会话首领,符合守护进程安全标准
文件处理:
关闭所有不必要的文件描述符(0,1,2等)
将标准输入/输出/错误重定向到/dev/null(修正您回答中的/dev/null15笔误)
环境清理:重置umask权限掩码,设置工作目录为根目录
两次fork的核心原因:
第一次fork:打破与父进程的关联,使进程成为后台进程
第二次fork:防止进程获得控制终端(会话首领会优先获取终端),确保严格的后台运行状态
这一标准流程遵循System V守护进程规范,可通过daemon(3)函数简化实现(部分系统提供)。
第4题(守护进程)
“fork() 后子进程是否复制父进程的 100MB 堆内存?写时复制(Copy-on-Write)如何解决此问题?”
参考答案:
=====================================================================
COW 机制:fork() 后子进程共享父进程内存页,仅当修改内存时触发缺页中断复制新页。避免立即复制大内存,提升创建效率18。
例外:线程栈、文件描述符表等需独立复制
第5题(多线程统计接口调用次数)
“多线程统计接口调用次数时,count++ 为何结果错误?如何用原子操作解决?,为什么能解决(工作原理)”??
参考答案:
=====================================================================
问题:count++ 非原子操作(包含读-改-写三步),多线程竞争导致计数丢失更新。
解决:
互斥锁或者信号量
第6题(用条件变量和互斥锁实现)
“异步日志系统中,生产者线程写日志到队列,消费者线程刷盘(写入操作)。如何用条件变量和互斥锁实现?”
参考答案:
=====================================================================
答:描述清楚生产者消费者模式
消费者循环读取队列中的数据,如果队列中数据为空,则使用条件变量wait阻塞
当生产者将数据写入队列中后,使用signal唤醒消费者
关键点:条件变量避免忙等待,互斥锁保护共享队列
第7题(共享内存比管道更合适)
“视频编辑进程需向编码进程发送 100MB 帧数据。为何共享内存比管道更合适?如何同步访问?”
参考答案:
=====================================================================
优势:共享内存直接映射到进程地址空间,避免管道的数据拷贝(内核-用户态切换)
同步:
信号量(如 sem_init)协调读写顺序。
第8题(微服务间频繁跨进程调用)
“微服务间频繁跨进程调用,Binder 为何用线程池处理请求?对比传统同步 IPC 的优势。”
参考答案:
=====================================================================
线程池:服务端预创建线程,并行处理多个请求,避免同步 IPC 的串行阻塞。
优势:
高并发:多请求同时处理。
资源复用:避免频繁创建/销毁线程
第9题(微服务间频繁跨进程调用)
“在金融交易系统中,日志必须确保崩溃后不丢失。调用 fwrite() 后立刻掉电,数据会丢失吗?如何用 fsync() 解决?代价是什么?”
参考答案:
=====================================================================
问题:fwrite() 写入标准 I/O 缓冲区,未刷盘时掉电导致丢失。
解决:定期调用 fsync(fd) 强制内核缓冲区落盘(同步磁盘写入)。
fflush():
作用于 用户空间缓冲区(C标准库的FILE*流缓冲区)。
将用户缓冲区中的数据刷新到操作系统内核的页面缓存(Page Cache)。
不保证数据写入物理磁盘。
fsync():
作用于 内核空间缓冲区(操作系统的页面缓存)。
将内核缓存中的数据强制写入物理存储设备(如磁盘)。
确保数据持久化到硬件。
学生如果回答fflush的话,需要跟他讲fsync和fflush的区别
代价:磁盘 I/O 阻塞线程,吞吐量下降(需权衡持久化级别与性能)。
第10题(sendfile())
用 read() 和 write() 拷贝 10GB 文件,为何性能不如 sendfile()?sendfile() 如何减少数据拷贝次数?”
参考答案:
=====================================================================
传统方式:read()(内核缓冲区→用户缓冲区) + write()(用户缓冲区→内核缓冲区),2 次拷贝 + 4 次上下文切换。
sendfile():内核直接在内核空间完成文件到套接字的拷贝(零拷贝技术),仅 2 次上下文切换,适合静态文件服务器。
第11题(为何要设置 SA_RESTART)
“父进程未调用 wait() 的子进程会变成僵尸。如何用信号处理 + waitpid() 自动回收?为何要设置 SA_RESTART?”
参考答案:
=====================================================================
void sigchld_handler(int sig){while(waitpid(-1,NULL,WNOHANG)>0);//非阻塞回收所有僵尸进程 } int main(){struct sigaction sa={.sa_handler=sigchld_handler,.sa_flags=SA_RESTART//避免系统调用被信号中断};sigaction(SIGCHLD,&sa,NULL);//...后续fork逻辑 }