【LLM】Openai之gpt-oss模型和GPT5模型
note
- gpt-oss模型代理能力:使用模型的原生功能进行函数调用、网页浏览(https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser)、Python 代码执行(https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python) 和结构化输出。
- gpt-oss模型,原生 MXFP4 量化:模型使用原生 MXFP4 精度训练 MoE 层,使得 gpt-oss-120b 可以在单个 H100 GPU 上运行,而 gpt-oss-20b 模型可以在 16GB 内存内运行。
- GPT5模型在文本、网页开发、视觉、复杂提示词、编程、数学、创造成、长查询等方面,都是第一名。全面超越Gemini-2.5-pro、Grok4等一众竞品。
- GPT-5 是一个一体化系统,包含三个核心部分:一个智能高效的基础模型,可解答大多数问题;一个深度推理模型(即GPT-5思维模块),用于处理更复杂的难题;以及一个实时路由模块,能够基于对话类型、问题复杂度、工具需求及用户显式指令(如prompt含“仔细思考这个问题”)智能调度模型。
- Openai目前面向普通用户,GPT-5提供免费、plus和Pro三种模式。同时在API平台上,推出了GPT-5、GPT-5 nano、GPT-5 mini三种模型选择。
文章目录
- note
- 一、gpt-oss模型
- 1、gpt-oss-120b和gpt-oss-20b模型
- 2、gpt-oss模型特点
- 1、模型定位与开放策略
- 2、核心架构亮点与量化策略
- 3、模型微调训练
- 二、GPT5模型
- Reference
一、gpt-oss模型
1、gpt-oss-120b和gpt-oss-20b模型
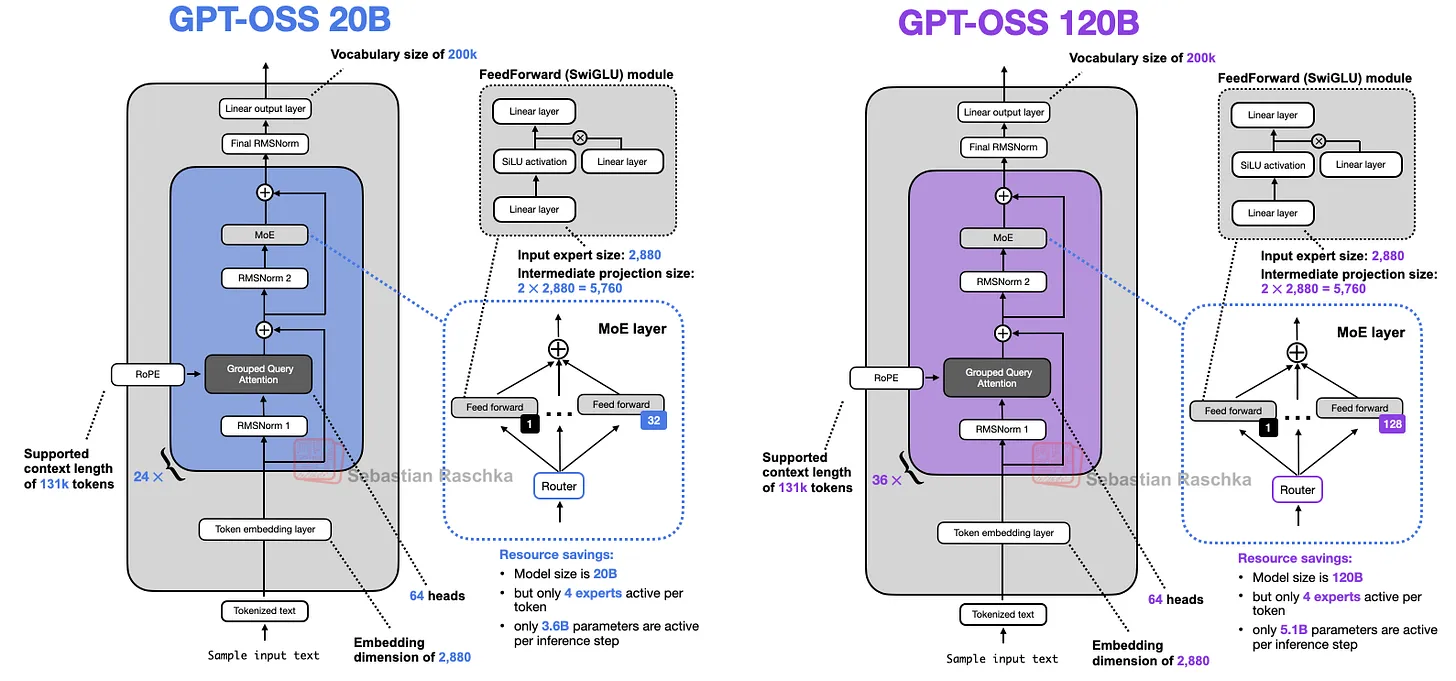
Openai开源两个模型:gpt-oss-120b,对标 o4-mini,117B 参数,5.1B 激活量,运行该模型,需要 80G 内存,单卡 H100 GPU 可运行。gpt-oss-20b,对标 o4-mini,21B 参数,3.6B 激活量,运行该模型,需要 16G 内存,单卡 4060 Ti 可运行。原生MXFP4量化,模型采用原生MXFP4精度训练MoE层。
关于部署,https://github.com/openai/gpt-oss,主页中写了多种不同方案,包括vllm, ollama、PyTorch / Triton / Metal、LM Studio等。https://gpt-oss.com/,可以直接体验openai开源的gpt-oss-120b 和 gpt-oss-20b
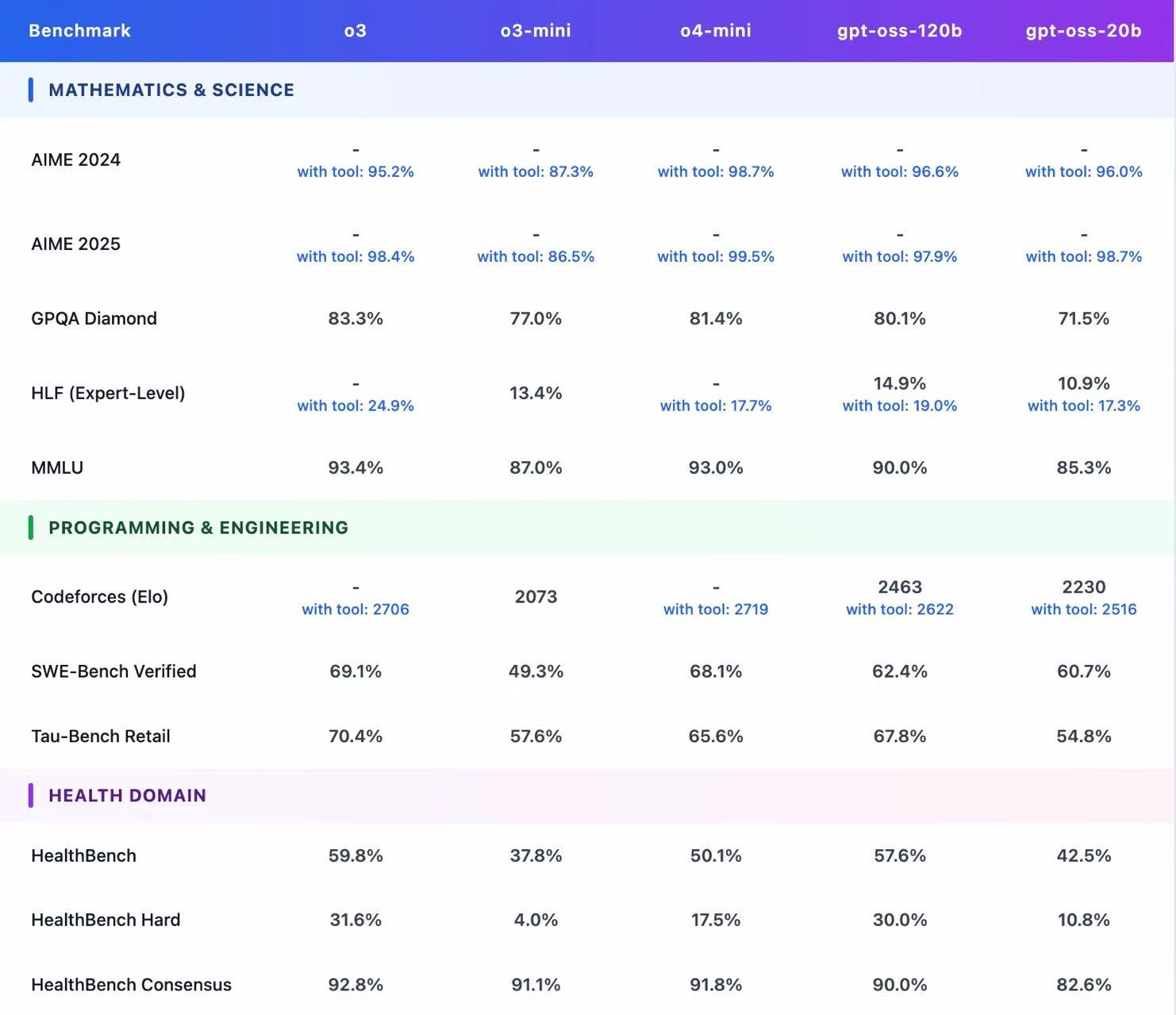
2、gpt-oss模型特点
2025 年 8 月 5 日,OpenAI 正式发布其自 GPT‑2 以来的首款开源权重模型系列——gpt‑oss‑120b 与 gpt‑oss‑20b
1、模型定位与开放策略
1、gpt‑oss‑120b (~116.8B 参数):与 OpenAI 自研的 o4‑mini 相当,可在单卡 NVIDIA H100(80GB)上运行,并以 Apache 2.0 协议免费开源 。
2、gpt‑oss‑20b (~20.9B 参数):性能接近 o3‑mini,可在仅 16GB 显存的消费级机器上运行,适配本地 PC 环境 。
2、核心架构亮点与量化策略
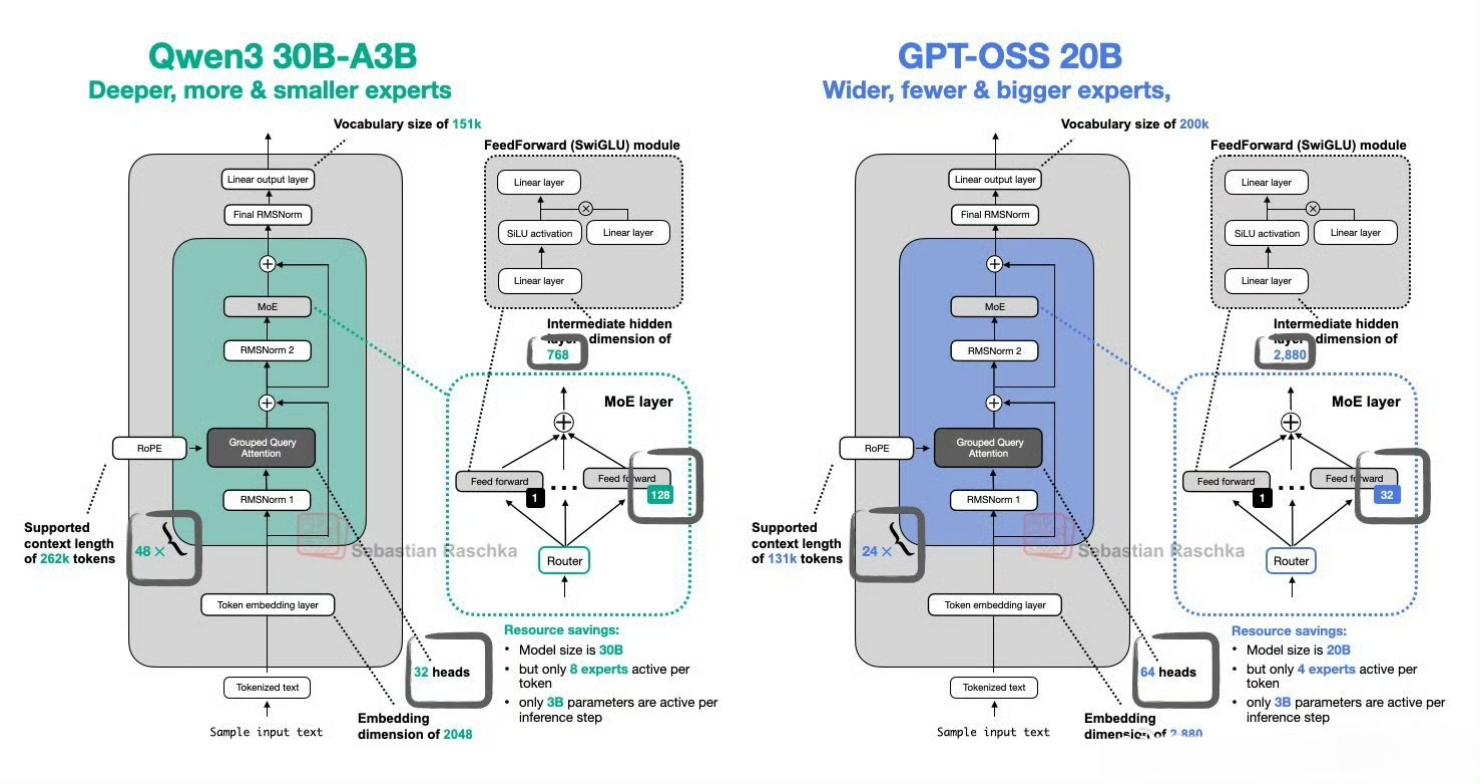
1、Mixture-of-Experts 架构:gpt‑oss‑120b 配备 128 个专家,gpt‑oss‑20b 则具有 32 个专家;每个 token 调度 top‑4 专家并使用 gated SwiGLU 激活函数 。
2、MXFP4 量化:对 MoE 权重采用 4.25-bit 量化;使得大模型在单卡可运行,小模型可在 16GB 环境中部署,显著降低推理资源门槛 。
3、长上下文支持:使用 YaRN 技术实现最高 131,072 token 上下文窗口,对结构化任务与复杂推理尤为有益 。
您可以根据任务需求调整三个级别的推理水平:
- 低: 适用于一般对话的快速响应。
- 中: 平衡速度与细节。
- 高: 深入且详细的分析。推理级别可以在系统提示中设置,例如,“Reasoning: high”。
3、模型微调训练
可以使用swift框架进行微调:
# 42GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \--model openai-mirror/gpt-oss-20b \--train_type lora \--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \'AI-ModelScope/alpaca-gpt4-data-en#500' \'swift/self-cognition#500' \--torch_dtype bfloat16 \--num_train_epochs 1 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--router_aux_loss_coef 1e-3 \--learning_rate 1e-4 \--lora_rank 8 \--lora_alpha 32 \--target_modules all-linear \--gradient_accumulation_steps 16 \--eval_steps 50 \--save_steps 50 \--save_total_limit 2 \--logging_steps 5 \--max_length 2048 \--output_dir output \--warmup_ratio 0.05 \--dataloader_num_workers 4 \--model_author swift \--model_name swift-robot
相关训练参数:
warmup_ratio:学习率预热比例(在整个训练的前 5% 步数内线性从 0 增至 learning_rate),随后进入 线性衰减。5% 通常足够,若数据极少可以调大至 0.1;若训练步数很长(>10k)可保留 0.05。router_aux_loss_coef:路由辅助损失系数(针对 Mixture‑of‑Experts / MoE 模型的路由平衡损失)
lora训练参数:
| 参数 | 解释 | 推荐范围 |
|---|---|---|
| –lora_rank | LoRA 中低秩矩阵的秩rank,决定适配层的参数规模。默认 8。 | 4‑16 常见;更大 rank 增加适配能力但显存也随之上升。 |
| –lora_alpha | LoRA 中的缩放系数(α),通常设置为 rank × 4(这里 8×4=32),用于保持 LoRA 参数对原模型梯度的比例。 | 经验值:α = 4 × rank;如 rank=4 → α=16,rank=16 → α=64。 |
| –target_modules | 要插入 LoRA 的模块。all-linear 表示把 LoRA 应用于 LoRA 模型中所有 Linear(全连接)层(包括投影层、FFN、中间层等)。也可以指定具体层名或正则表达式(如 q_proj, v_proj, v_proj)。 | 对大多数 LLM,all-linear 已足够;如果想只微调注意力投影可改成 q_proj,k_proj,v_proj。 |
相关训练经验:
| 场景 | 建议的改动 |
|---|---|
| 显存不足 | 把 per_device_train_batch_size 降到1(已经是1),再把 gradient_accumulation_steps 增大(如 32-64),或把 torch_dtype 改成 float16(如果 GPU 支持)。 |
| 收敛慢 | 把 learning_rate 调高到 2e-4 或 5e-4(注意观察 loss 曲线是否出现震荡),或延长 warmup (warmup_ratio=0.1)。 |
| 验证不够频繁 | 把 eval_steps 缩小到 20,或把 logging_steps 设为1,及时捕捉训练过程异常。 |
| 想要更高质量的 LoRA | 增大 lora_rank(例如 16)并相应把 lora_alpha 设为 64;若显存仍足够,也可以把 target_modules 从 all-linear 改成只在 attention 投影上(q_proj,k_proj,v_proj),这样参数更集中。 |
| 多卡训练 | 把 CUDA_VISIBLE_DEVICES=0,1,2,3(或不写),并把 --tensor_parallel_size 参数(Swift 自动解析)设为 GPU 数量,例如 --tensor_parallel_size 4;此时 per_device_train_batch_size 仍然指每卡的大小,整体有效 batch = per_device_train_batch_size × gradient_accumulation_steps × num_gpus。 |
| 想快速实验 | 把 --num_train_epochs 改成 0.1(只跑少量 steps),配合 --max_steps 200(自行添加)来做 smoke test,确认 pipeline 正常后再正式跑。 |
| 使用混合精度 | --torch_dtype bfloat16 已经是混合精度;若 GPU 不支持 BF16,可改为 float16,并确保 torch.backends.cudnn.benchmark = True(Swift 默认开启)。 |
二、GPT5模型
- GPT5模型在文本、网页开发、视觉、复杂提示词、编程、数学、创造成、长查询等方面,都是第一名。全面超越Gemini-2.5-pro、Grok4等一众竞品。
- GPT-5 是一个一体化系统,包含三个核心部分:一个智能高效的基础模型,可解答大多数问题;一个深度推理模型(即GPT-5思维模块),用于处理更复杂的难题;以及一个实时路由模块,能够基于对话类型、问题复杂度、工具需求及用户显式指令(如prompt含“仔细思考这个问题”)智能调度模型。
- Openai目前面向普通用户,GPT-5提供免费、plus和Pro三种模式。同时在API平台上,推出了GPT-5、GPT-5 nano、GPT-5 mini三种模型选择。
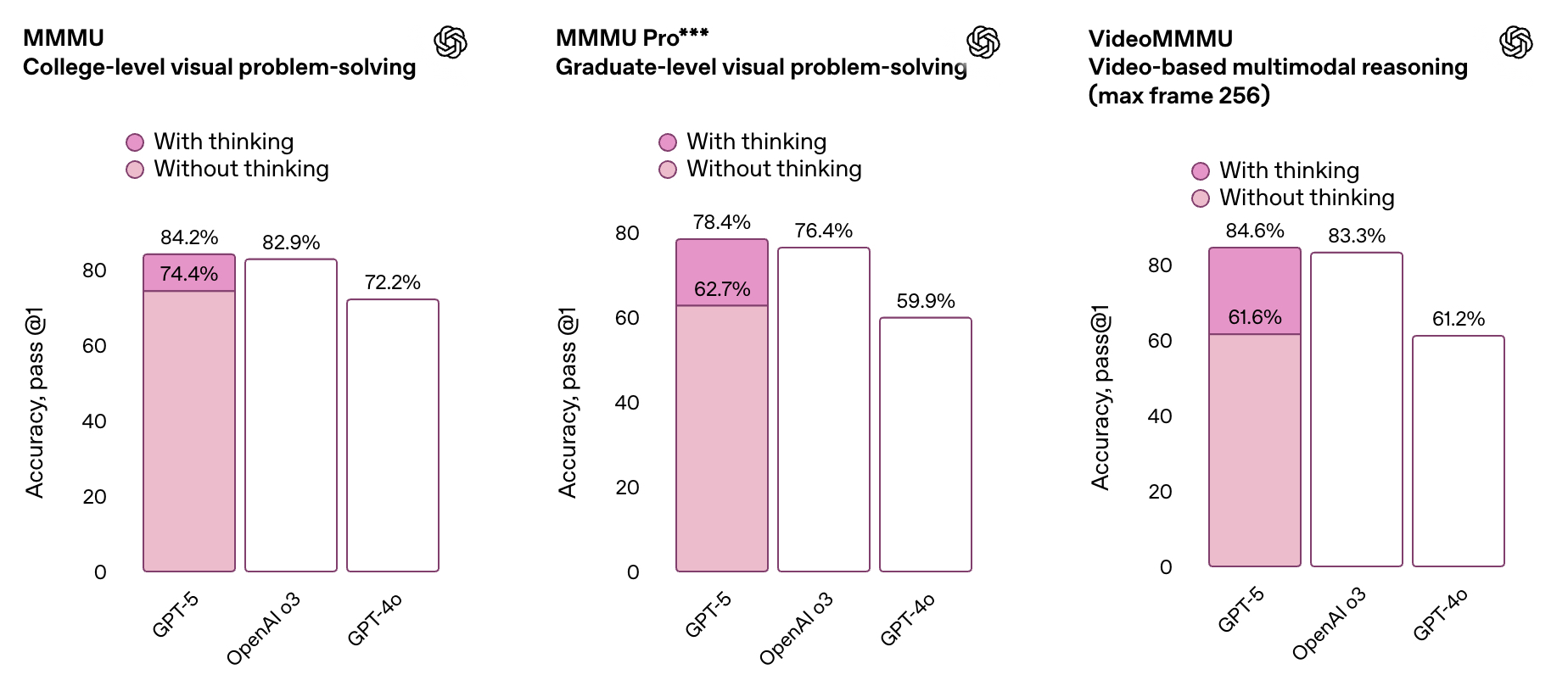
GPT5在多模态榜单的效果:
相关展示demo:
1、GPT-5能够自适应推理,会根据问题的复杂程度,自动启用深度思考功能。比如,一个中学生上物理课,想了解什么是伯努利效应以及飞机为何被设计成现在的形状。
当进一步要求它生成一个动态SVG动画演示时,GPT-5进入深度思考模式。此时,用户可以点开查看其内部推理过程,清楚知道每一步是如何形成的。约两分钟,它完成了近400行代码的编写。最终生成一个可交互的动画展示,形象地模拟原理。
2、要求在其中套一个贪吃蛇游戏,每吃掉一个物品就学一个单词,再要求把蛇替换成老鼠,苹果换成奶酪
3、在展示中,研究员让GPT-5构建一个“学法语”的APP,允许自定义词汇、修改界面设计。成品功能很成熟,答对题目还会积累经验值,甚至有标准发音可以跟着练习
4、比如将某公司大量数据给它,模型在5分钟内就能创建了一个可视化财务仪表盘,据开发人员估计,这项工作原本需要好几个小时。
5、想制作一款融入城堡元素的3D游戏
6、记忆能力也进一步提升,支持链接外部服务,比如Gmail、谷歌日历等。看到日程后GPT-5可以自动进行一些助理级工作,比如发现未回复的邮件等。
Reference
[1] GPT5发布,毫无新意,AGI没有盼头了
[2] https://huggingface.co/blog/zh/welcome-openai-gpt-oss
[3] https://openai.com/index/introducing-gpt-5/
[4] grok、genmini模型
[5] OpenAI 重返开源!gpt-oss系列社区推理、微调实战教程到!
[6] LLM评测榜单:https://lmarena.ai/leaderboard