【机器学习深度学习】模型选型:如何根据现有设备选择合适的训练模型
目录
前言
一、为什么设备决定了你的训练上限
二、显卡类型与兼容性
三、显存与训练方法的对应关系
四、不同显存下的微调方法解析
4.1 全参数微调
4.2 LoRA(Low-Rank Adaptation)
4.3 QLoRA(Quantized LoRA)
五、可视化决策图
六、选型建议
七、模型选型流程
7.1 评估你的设备性能
1. 计算能力(GPU/CPU/TPU)
2. 内存(RAM)
3. 存储空间
4. 能耗与散热
7.2 明确你的任务需求
1. 自然语言处理(NLP)
2. 计算机视觉(CV)
3. 多模态任务
实用建议
7.3 平衡性能与效率
1. 模型压缩
2. 预训练模型
3. 分布式训练
4. 推理优化
实用工具
7.4 匹配数据与模型
实用建议
7.5 实践流程
八、示例场景:让选择更直观
场景1:低端设备(Raspberry Pi,4GB RAM,无GPU)
场景2:中端设备(RTX 3060,12GB显存,16GB RAM)
场景3:高端服务器(4x A100 GPU,128GB RAM)
总结

前言
在AI开发的旅途中,选择合适的训练模型就像为一次旅行挑选交通工具:你需要根据“路况”(任务需求)和“马力”(设备性能)来决定是骑自行车、开轿车还是租用货运飞机。选错模型可能导致资源浪费或性能不足,而选对模型则能让你的AI项目高效运行。本文将以清晰的结构、直观的类比和实用的建议,带你一步步了解如何根据现有设备选择最适合的AI训练模型,打造一个高效且易懂的指南。
一、为什么设备决定了你的训练上限
深度学习训练本质上就是大量的矩阵运算,显卡的显存和算力直接决定了:
能否加载模型
一次能处理多少数据
能否高效训练
一句话总结:
💡 显存像是训练的桌子,桌子太小,你的菜(模型+数据+梯度)就摆不下。
类比理解
【设备与模型匹配的重要性】
想象你要去超市买菜:如果超市就在隔壁,步行就够了;但如果目的地是另一个城市,步行显然不现实。AI模型的选择也是如此。高端服务器可以轻松训练大型模型如LLaMA 70B,而低端设备(如Raspberry Pi)更适合轻量模型如MobileNet。选错模型可能导致:
资源超载:像用自行车拉货车,设备崩溃或训练时间过长。
性能不足:像用飞机送外卖,浪费资源且成本高昂。
通过评估设备能力、任务需求和优化策略,你可以找到最佳匹配的模型,就像为旅途选择最合适的交通工具。
二、显卡类型与兼容性
目前深度学习训练主要依赖 GPU,尤其是 NVIDIA(N 卡),原因:
CUDA + cuDNN 生态成熟
PyTorch、TensorFlow、DeepSpeed 等深度优化
bitsandbytes、xformers、flash-attn 等显存优化插件几乎只支持 N 卡
AMD(A 卡)与 Intel GPU 虽然有 ROCm / oneAPI 支持,但生态不完善,新手容易踩坑。
📌 建议:
如果要长期训练模型,优先选 N 卡,至少 RTX 3060(12GB)起步。
AMD 卡更适合推理或小规模实验。
三、显存与训练方法的对应关系
| 显存大小 | 可做任务 | 推荐微调方法 | 备注 |
|---|---|---|---|
| 4GB–6GB | 小模型推理 / 轻量级微调 | LoRA / QLoRA / Prefix Tuning | 常见显卡:GTX 1650, RTX 3050 |
| 8GB–12GB | 中小模型 LoRA 微调 | LoRA + 8bit/4bit 量化 | RTX 3060、3070 级别 |
| 16GB–24GB | 全参数微调中型模型 | 全参微调 / LoRA | RTX 3090、4080 |
| 32GB+ | 大模型(7B~13B)全参微调 | 全参微调 + 混合精度 | A6000, 4090, H100 |
四、不同显存下的微调方法解析
4.1 全参数微调
需求:显存 ≥ 模型大小 × 2–3 倍
优点:灵活,精度高
缺点:显存吃紧,训练慢
适用:16GB+ N 卡
4.2 LoRA(Low-Rank Adaptation)
需求:4GB–8GB
优点:显存占用小,只训练 adapter 层
缺点:模型结构固定
适用:绝大多数中低端 GPU
4.3 QLoRA(Quantized LoRA)
需求:4GB–6GB
原理:8bit/4bit 量化主模型 + LoRA 训练
优点:能在消费级显卡上微调大模型
缺点:量化可能损失精度(小模型损失影响大,模型越大影响越小)
五、可视化决策图
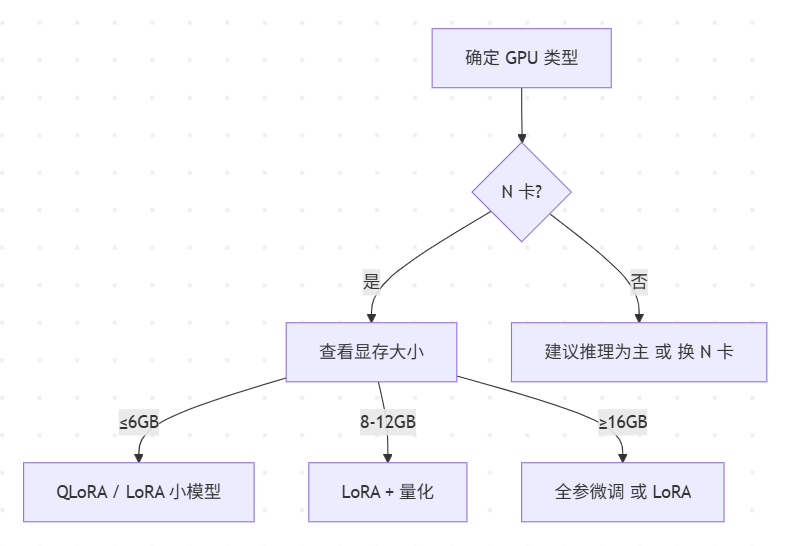
六、选型建议
-
先测显卡显存:
nvidia-smi -
先试 LoRA:从低显存方法起步,熟悉流程后再尝试全参微调
-
存储别忽视:模型权重动辄几十 GB,磁盘也要留足
七、模型选型流程
7.1 评估你的设备性能
设备性能是选择模型的基础,就像检查你的交通工具有多少“马力”。以下是需要评估的关键硬件指标:
1. 计算能力(GPU/CPU/TPU)
高端GPU/TPU(如NVIDIA A100、Google TPU):适合训练大型模型(如BERT-large、LLaMA 13B),擅长并行计算。
中端GPU(如RTX 3060):适合中型模型(如BERT-base、YOLOv5-medium)。
CPU或低端设备(如Intel i7、Raspberry Pi):适合轻量模型(如DistilBERT、MobileNet)。
类比:GPU像跑车,速度快但耗能高;CPU像自行车,省力但适合短途。
2. 内存(RAM)
大型模型需要大内存。例如,训练一个10亿参数模型可能需要32GB RAM,而100M参数的模型可能只需8GB。
多GPU或分布式训练可分担内存压力。
类比:RAM像行李箱,容量越大,能装的“模型行李”越多。
3. 存储空间
模型权重和数据集需要充足存储。例如,一个10亿参数模型的权重可能占几十GB,数据集可能需要TB级空间。
SSD比HDD更快,适合频繁读写。
类比:存储像货仓,决定了能携带多少“食材”。
4. 能耗与散热
高性能设备耗电量大,散热要求高。家用笔记本可能因过热限制长时间训练,当然更推荐的训练方法是直接租用云服务器,训练起来更加高效。
类比:设备像马匹,跑得快需要更多“饲料”和“休息”。
实用工具:
-
用nvidia-smi检查GPU利用率,用htop查看CPU和内存。
-
如果设备不足,考虑云服务(如AWS EC2、Google Colab Pro)。
7.2 明确你的任务需求
任务需求决定了模型的类型,就像旅行的目的决定你需要轿车还是货车。以下是常见任务类型和推荐模型:
1. 自然语言处理(NLP)
-
任务:文本分类、问答、翻译等。
-
推荐模型:
-
轻量级(CPU/边缘设备):DistilBERT、MobileBERT(<100M参数)。
-
中型(中端GPU):BERT-base、RoBERTa-base(100M-300M参数)。
-
大型(高端GPU):LLaMA 7B、T5-large(需要多GPU)。
-
-
类比:轻量模型像电动自行车,省力但功能有限;大型模型像高铁,功能强大但需强大支持。
2. 计算机视觉(CV)
-
任务:图像分类、目标检测、图像生成。
-
推荐模型:
-
轻量级:MobileNet、EfficientNet-B0(适合边缘设备)。
-
中型:ResNet-50、YOLOv5-small(需要中端GPU)。
-
大型:Vision Transformer (ViT)、Stable Diffusion(需要高端GPU)。
-
-
类比:轻量模型像小型无人机,灵活但视野有限;大型模型像卫星,覆盖广但需强大支持。
3. 多模态任务
-
任务:图文结合、语音处理等。
-
推荐模型:
-
轻量级:CLIP-ViT-B-32(中端设备)。
-
大型:DALL-E、Whisper(高端GPU/TPU)。
-
-
类比:多模态模型像全能越野车,适应多种地形但耗能高。
实用建议
简单任务(如文本分类)用轻量模型,复杂任务(如生成式AI)选大型模型。
如果需要实时推理(如手机端应用),优先轻量模型。
7.3 平衡性能与效率
选择模型需要在性能(准确性)和效率(速度、资源占用)间权衡,就像挑选既省油又跑得快的车。以下是优化策略:
1. 模型压缩
量化:将模型从32位浮点数压缩到16位或8位(如INT8),降低内存需求。例如,量化后的BERT可在CPU高效运行。
剪枝:去除不重要参数,减少计算量。例如,剪枝后的ResNet-50可节省30%计算。
蒸馏:用大模型(教师)训练小模型(学生),如从BERT蒸馏出DistilBERT。
类比:压缩像把大行李箱换成背包,轻便但功能稍减。
2. 预训练模型
使用预训练模型(如Hugging Face的BERT、LLaMA)可减少训练时间和资源。
低端设备选MobileNet,高性能设备选LLaMA 7B。
类比:预训练模型像租来的跑车,省去自己造车的麻烦。
3. 分布式训练
多GPU或多节点设备可使用PyTorch DDP或Horovod分担训练负载。
类比:分布式训练像车队运输,分担负载但需协调。
4. 推理优化
使用ONNX或TensorRT加速推理,适合实时应用。
类比:推理优化像给车装涡轮增压器,提升速度。
实用工具
Hugging Face Optimum、ONNX Runtime可优化模型。
测试压缩模型的性能,确保精度损失可接受。
7.4 匹配数据与模型
训练数据的规模和质量影响模型选择,就像食材量决定能做多大的菜:
小数据集(<1万条):适合轻量模型(如DistilBERT),避免过拟合。
大数据集(>10万条):支持大型模型(如LLaMA 13B)。
高质量数据:干净、相关的数据让小模型也能发挥大作用。
类比:小数据集像小份食材,适合小菜;大数据集像整头牛,适合大餐。
实用建议
数据量少时,优先预训练模型+少量微调。
使用数据增强(如文本改写、图像翻转)弥补数据不足。
7.5 实践流程
-
检查硬件:用nvidia-smi或htop评估GPU/CPU、RAM、存储。
-
定义任务:明确任务类型(NLP、CV等)和性能要求(实时性、准确率)。
-
筛选模型:从Hugging Face、TensorFlow Hub选择候选模型,参考参数量和推理速度。
-
测试优化:在设备上测试训练/推理性能,必要时量化或剪枝。
-
云端选择:如果本地设备不足,考虑AWS、Google Cloud,比较成本与性能。
八、示例场景:让选择更直观
场景1:低端设备(Raspberry Pi,4GB RAM,无GPU)
任务:文本情感分析。
模型:DistilBERT(66M参数,量化后适合CPU)。
优化:ONNX加速推理,数据量<1万条。
类比:像用自行车送外卖,轻便但适合短途。
场景2:中端设备(RTX 3060,12GB显存,16GB RAM)
任务:目标检测。
模型:YOLOv5-medium或EfficientNet-B3。
优化:FP16半精度训练,批量大小16。
类比:像用SUV跑长途,兼顾速度和负载。
场景3:高端服务器(4x A100 GPU,128GB RAM)
任务:多模态图文生成。
模型:CLIP + Stable Diffusion。
优化:分布式训练,数据量百万级。
类比:像用货运飞机,适合大规模任务。
总结
训练模型的第一步,不是写代码,而是看你手里的硬件。
显存和显卡类型决定了能走多远。
不要死磕全参微调,LoRA / QLoRA 是大多数人的性价比之选。
选择适合的AI训练模型就像为旅途挑选最佳交通工具。通过评估设备性能(GPU、RAM、存储)、明确任务需求(NLP、CV等)、平衡性能与效率(压缩、预训练)、匹配数据规模,并结合优化策略,你可以找到最合适的模型。无论是轻量级的DistilBERT还是强大的LLaMA,关键是让模型与设备和任务无缝衔接,就像选一辆既省油又跑得快的车,带你顺利抵达AI项目的终点!