LLM表征的提取方式
LLM表征的提取方式
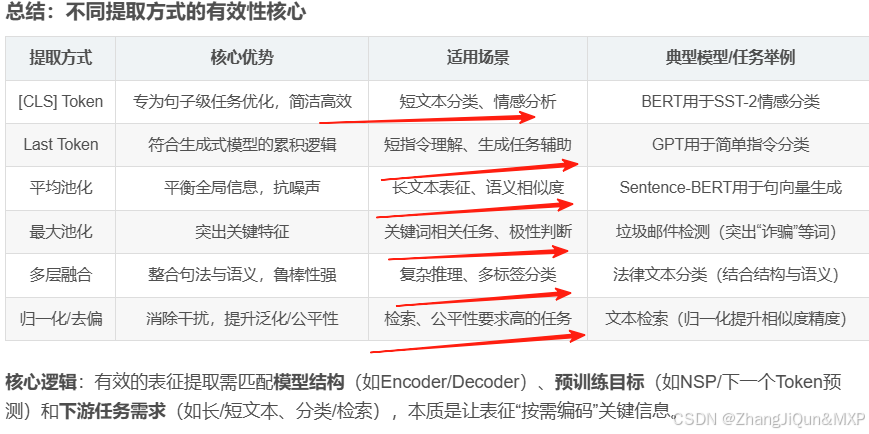
LLM(大语言模型)的表征是指模型处理文本后输出的向量(通常是高维实数向量),这些向量编码了文本的语义、语法、上下文关联等信息,是后续任务(如分类、检索、聚类、生成等)的核心输入。表征的提取方式直接影响其对下游任务的有效性,不同方式的设计与模型结构、预训练目标、下游任务需求密切相关。
一、基于特定Token的提取方式
LLM的输出通常是序列中每个Token的向量(如BERT的每个字/词向量,GPT的每个生成Token向量),但下游任务常需要单向量表征(如一句话的整体向量)。基于特定Token的提取方式,是从序列中选择一个“代表性Token”的向量作为整体表征。
1. [CLS] Token(适用于Encoder-only模型,如BERT)
- 原理:Encoder-only模型(如BERT)在预训练时,会在输入序列前强制添加一个特殊Token
[CLS](意为“Classification”)。该Token不对应任何实际语义,但其向量在预训练过程中专门学习“序列级语义”——通过与其他所有Token的注意力交互,捕捉整个序列