Tableau筛选器所有值与总和的差异:同一度量,两重世界
目录
一、引言
二、示例数据与问题背景
三、Tableau 计算管线中的位置差异
四、案例复现:从数字看差异
五、汇总表格:差异一览
六、选型框架:如何为业务选择正确的方式
七、常见误区与调试技巧
八、结语
一、引言
当我第一次把“成交金额”拖到 Tableau 的筛选器对话框时,系统抛出的两个选项——“所有值”与“总和”——曾让我愣在原地。表面上,它们指向同一字段,实际上却分别代表了原始行级世界与聚合汇总世界的分水岭。本文以笔者在 2025 年 7 月处理的一份区域销售数据为例,结合三张截图所示的 12 省 120 606 433 元成交记录,系统梳理这两种筛选方式在计算次序、结果粒度、交互行为及业务语义上的差异,并给出可复用的选型框架。
二、示例数据与问题背景
截图中,数据已被整理为“区域—省份—成交金额”三级结构,共 12 487 行(文件 3 的计数)。每条记录对应一次成交,度量“成交金额”在行级保存单笔订单实收金额。业务方提出两个需求:
- A. 仅保留单笔订单大于 10 000 元的记录,重新计算各省的成交客户数;
- B. 仅展示“按省份汇总后成交金额超 1 000 万元”的省份,但保留这些省份的全部订单。
需求 A 与 B 恰好分别对应“所有值”与“总和”筛选,于是成为本文的天然案例。
三、Tableau 计算管线中的位置差异
Tableau 官方白皮书中,数据在视图渲染前依次经过“行级(Row-level)”“聚合(Aggregate)”“表计算(Table-calc)”三大阶段。
“所有值”筛选发生在第一阶段,它对数据源返回的每一行进行布尔判断,剔除不满足条件的行后再进入聚合阶段。因此,它直接减少行数,聚合函数所见即所得。
“总和”筛选则发生在第二阶段之后,它对已按视图维度聚合出的 SUM(成交金额) 进行二次过滤,原始行仍然完整存在于内存,仅是在渲染层被隐藏。理解这一点,就能解释为何同一张条形图在两种筛选下纵轴刻度与客户数标记会出现截然不同的变化。
四、案例复现:从数字看差异
笔者在 Tableau 中复现了上述需求。
步骤一:将“省份”置于行,“SUM(成交金额)”置于列,默认生成总和 120 606 433 元。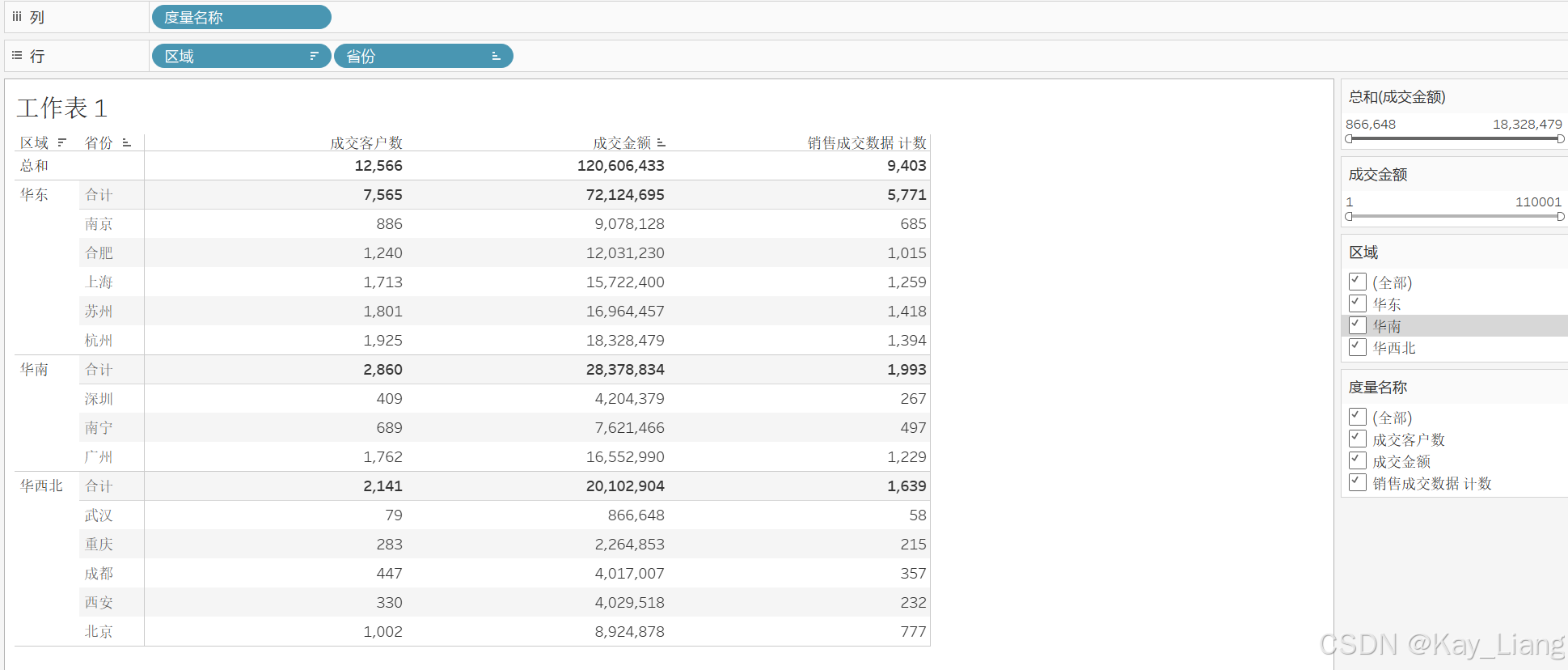
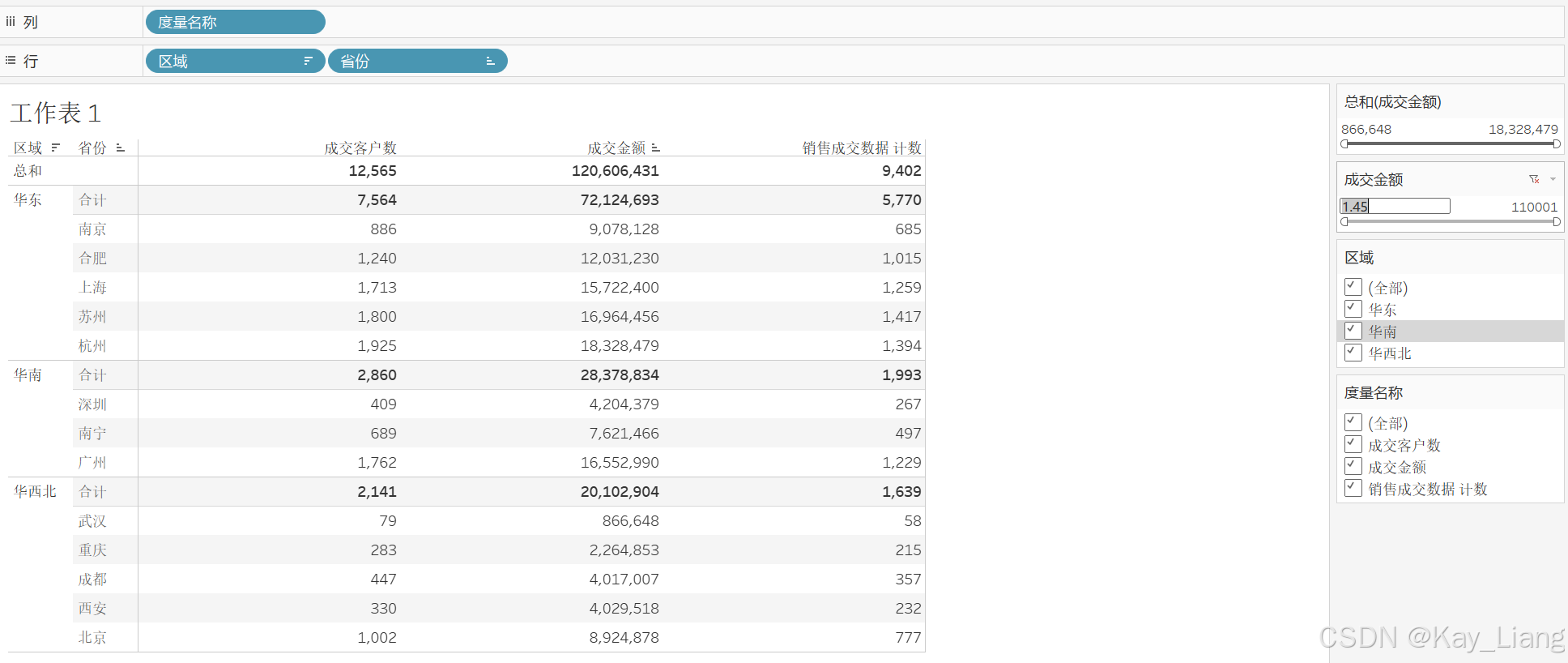
步骤二:在筛选器中选择“成交金额–所有值”,条件设为 >1.45 元。行级过滤后,仅 苏州的成交金额的原始数据因有单笔大于1.45 的记录而被整体剔除;成交客户数也从 1801 降至 1800。
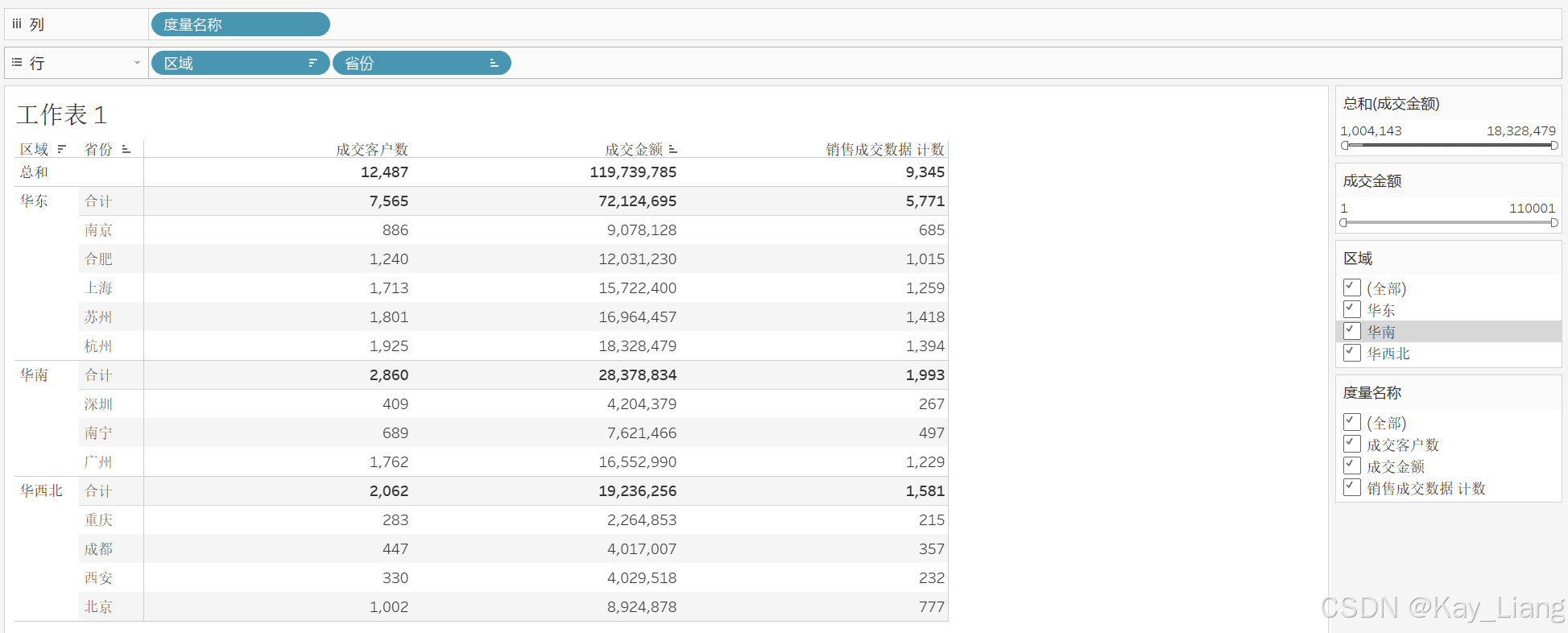
步骤三:撤销筛选,再次添加“成交金额–总和”,条件设为 SUM >10 04143元。此时武汉被隐藏,但武汉原始订单仍在数据集中,仅被视图排除。若将“客户数”改为 CNTD(CustomerID),可见湖北客户数仍为 58,证明行级数据未受损伤。
五、汇总表格:差异一览
为了让读者快速对照,笔者将核心差异整理为表 1。
| 维度 | 所有值 | 总和 |
|---|---|---|
| 计算阶段 | 行级过滤 | 聚合后过滤 |
| 数据粒度 | 单笔订单 | 聚合后的省份/区域 |
| 对行数影响 | 实际减少 | 不减少,仅隐藏 |
| 对聚合结果影响 | 重新计算 SUM、AVG、CNTD 等 | 保持原始聚合值,仅筛选展示 |
| 适用场景 | 关注单笔质量,如剔除异常大单 | 关注汇总结果,如 Top N 省份 |
| 交互行为 | 交叉表、散点图同步减少标记 | 地图、条形图可联动高亮,但明细表仍完整 |
六、选型框架:如何为业务选择正确的方式
1. 明确分析目标。若报表用于风控审核,需剔除单笔异常,则“所有值”不可或缺;若用于高层看板,仅需展示高贡献省份,则“总和”更简洁。
2. 评估性能。行级过滤在大数据引擎中可能触发全表扫描,而聚合后过滤仅作用于已缓存的聚合结果,计算成本更低。
3. 留意后续动作。若下游需要导出明细,选择“总和”可确保完整数据;若后续步骤需计算留存率,则“所有值”已改变分母,需提前确认口径。
七、常见误区与调试技巧
- 误区一:把“总和”当作“单笔金额大于 X 的汇总”。实际上,后者应使用行级 IF 计算字段,再求和。
- 误区二:混淆上下文筛选器与维度筛选器。上下文筛选器虽也提前执行,但仍属于行级过滤,可与“所有值”并用。
- 调试技巧:在“查看数据”窗口勾选“显示全部行”,即可直观判断当前筛选属于行级还是聚合级。
八、结语
“所有值”与“总和”如同显微镜与望远镜,前者聚焦微观订单,后者俯瞰宏观省份。只有理解它们在 Tableau 计算管线中的先后次序,才能在业务需求与性能之间做出恰到好处的权衡。希望本文的实例、表格与框架能帮助你在下一次遇到筛选器选项时,不再犹豫,精准落笔。