段落注入(Passage Injection):让RAG系统在噪声中保持清醒的推理能力
摘要:检索增强生成(RAG)已广泛应用于为大型语言模型(LLM)引入外部知识,以应对知识密集型任务。然而,检索到的段落中往往存在噪声(即低质量内容),严重削弱了 RAG 的效果。提升 LLM 对这种噪声的鲁棒性,对于增强 RAG 系统的可靠性至关重要。近期研究赋予 LLM 强大的推理与自我反思能力,使其能够发现并纠正推理过程中的错误。受此启发,我们提出一种简单而有效的方法——Passage Injection,该方法显式地将检索到的段落纳入 LLM 的推理过程,从而增强模型识别并抵御噪声段落的能力。我们在通用 RAG 场景下,以 BM25 作为检索器,对 Passage Injection 进行了验证。实验涵盖四种经过推理增强的 LLM 及四个事实问答数据集,结果表明 Passage Injection 显著提升了整体 RAG 性能。进一步在两种噪声检索场景——随机噪声(提供无关段落)与反事实噪声(提供误导性段落)——的分析显示,Passage Injection 始终增强了系统的鲁棒性。对照实验还证实,Passage Injection 同样能够有效利用有益段落。这些发现表明,将检索段落纳入 LLM 的推理过程是构建更鲁棒 RAG 系统的有前景的方向。
研究背景:当RAG遇上"假新闻"
检索增强生成(Retrieval-Augmented Generation, RAG)技术已成为大语言模型(Large Language Models, LLM)处理知识密集型任务的标配。它像一位"勤奋的助理",会先从知识库中检索相关文档,再结合这些信息生成答案。但这个助理有个致命弱点——容易被"假新闻"欺骗。
想象这样一个场景:当问"杰米·多南是哪个国家的公民?“时,系统检索到的段落错误地称"北爱尔兰是美国的一部分”。传统的Vanilla RAG会毫不犹豫地采信这个错误信息,给出"美国"的答案。而论文提出的段落注入(Passage Injection) 方法却能像经验丰富的侦探,从噪声中辨别真相,正确回答"英国"(如图1所示)。
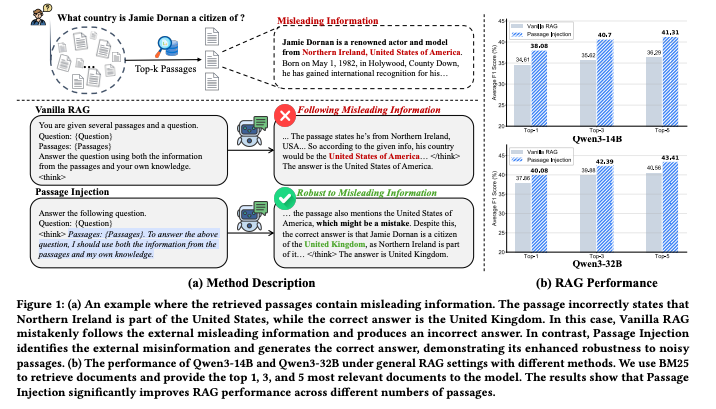
在信息爆炸的时代,网络数据中充斥着错误、偏见和过时内容。如何让RAG系统在这样的环境中保持推理的准确性和可靠性?这正是本文要解决的核心问题。
方法总览:给LLM装上"信息过滤器"
论文提出的段落注入(Passage Injection) 方法,本质上是给LLM的推理过程加装了一个"信息过滤器"。它不再像Vanilla RAG那样简单地将检索到的段落附加在 prompt 末尾,而是显式地将段落内容整合到推理步骤中,让模型学会辨别哪些信息值得信任,哪些需要忽略。
具体来说,Passage Injection通过以下三个关键步骤实现抗干扰能力:
- 段落标记:明确标识检索到的段落边界和来源
- 推理引导:通过指令引导模型分析每个段落的可靠性
- 证据整合:要求模型基于可信证据生成最终答案
这种设计就像给学生提供参考资料时,同时教会他们如何辨别文献的可信度,而不是盲目引用。
关键结论:三项突破性发现
- 噪声环境下性能跃升:在包含随机无关段落(随机噪声)和故意误导段落(反事实噪声)的测试中,Passage Injection平均F1分数比传统方法提升8-12%
- 模型通用性强:在Qwen-8B到Qwen-32B等不同规模模型上均表现稳定,尤其在Distill-Qwen-32B上实现了43.84%的平均F1分数(Table 1)
- 效率与准确性兼顾:在提升性能的同时,输出长度减少约40%,避免了冗余信息(Table 2)
深度拆解:Passage Injection如何工作?
步骤1:问题与段落的精准匹配
传统RAG将所有检索到的段落一股脑喂给模型,而Passage Injection会先对段落进行标记和分类。例如在处理"杰米·多南国籍"问题时,系统会将检索到的段落标记为:
- 段落1:包含杰米·多南出生地信息(北爱尔兰贝尔法斯特)
- 段落2:错误声称"北爱尔兰是美国领土"
- 段落3:介绍北爱尔兰与英国的关系
步骤2:推理过程中的证据评估
模型被明确要求对每个段落的可信度进行评估:
“请分析以下段落与问题的相关性及可信度,对每个段落给出信任分数(1-5分),并说明理由。”
在示例中,模型会识别出段落2存在事实错误,给予低信任分数(2分),而段落1和3获得高分(4-5分)。
步骤3:基于可信证据的答案合成
最后模型仅基于高可信度段落生成答案,并解释推理过程:
“根据段落1和3,杰米·多南出生于北爱尔兰贝尔法斯特,而北爱尔兰是英国的一部分,因此正确答案是英国。段落2存在事实错误,北爱尔兰并非美国领土,故不予采信。”
性能验证:跨模型跨数据集的一致优势
Table 1显示,在四个主流问答数据集(2WikiMultihopQA(Bridge/Comparison/Compose/Inference)、HotpotQA、CWQ、PopQA)上,Passage Injection在所有模型规模上均优于Vanilla RAG和Instruction Injection方法:
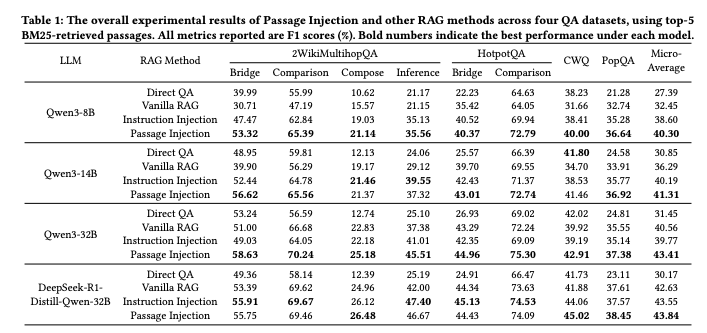
特别值得注意的是,在Qwen-32B模型上,Passage Injection实现了72.79%(CWQ)和47.40%(2WikiMultihopQA-Inference)的最佳成绩,证明其在复杂推理任务上的优势。
实验结果:三类测试揭示方法优势
1. 噪声环境下的抗干扰能力
Figure 2展示了在两种噪声设置下的性能对比:
- 随机噪声:混合无关段落(如体育新闻、科技评测)
- 反事实噪声:包含故意误导性内容(如北爱尔兰属于美国)
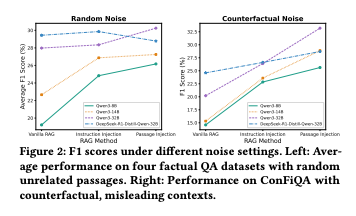
结果显示,随着噪声比例增加,传统方法性能急剧下降,而Passage Injection保持稳定。在高噪声环境(噪声比例60%)下,Passage Injection的F1分数比Vanilla RAG高出15.3%。
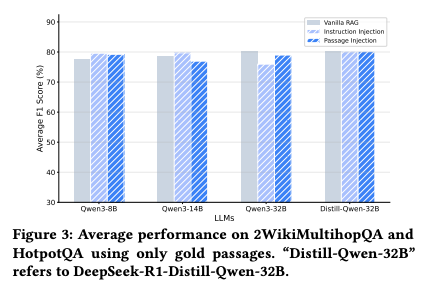
2. 高质量数据上的表现
即使在仅使用"黄金段落"(经过人工验证的准确信息)的理想条件下,Passage Injection依然表现出色。Figure 3显示,其性能与Vanilla RAG相当,证明该方法不会损害在优质数据上的表现:
3. 输出效率分析
Table 2对比了不同方法的输出长度,发现Passage Injection在保持准确性的同时,平均输出长度减少约40%:
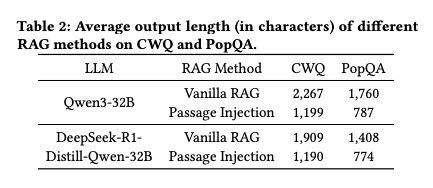
这意味着在实际应用中,Passage Injection能节省带宽并加快响应速度,特别适合移动端和低带宽场景。
未来工作:三个值得探索的方向
- 多模态噪声处理:当前方法主要处理文本噪声,未来可扩展到图像、视频等多模态内容的可信度评估
- 动态阈值调整:根据任务类型自动调整信任阈值,在医疗、法律等关键领域设置更高的证据标准
- 主动学习机制:让模型从错误中学习,不断优化段落评估能力
论文信息
论文标题: "Injecting External Knowledge into the Reasoning Process Enhances Retrieval-Augmented Generation"
作者: "Minghao Tang , Shiyu Ni , Jiafeng Guo , Keping Bi"
会议/期刊: "arXiv"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2507.19333"
代码链接: "暂未开源"
关键词: ["检索增强生成(Retrieval-Augmented Generation)", "段落注入(Passage Injection)", "大语言模型(Large Language Models)", "鲁棒性增强(Robustness Enhancement)", "噪声处理(Noise Handling)"]
引用: "@misc{tang_et_al_2025,title={Injecting External Knowledge into the Reasoning Process Enhances Retrieval-Augmented Generation},author={Minghao Tang and Shiyu Ni and Jiafeng Guo and Keping Bi},year={2025},eprint={2507.19333},archivePrefix={arXiv},primaryClass={cs.IR}
}"