攻防世界-Mobile-easyjni
源码分析
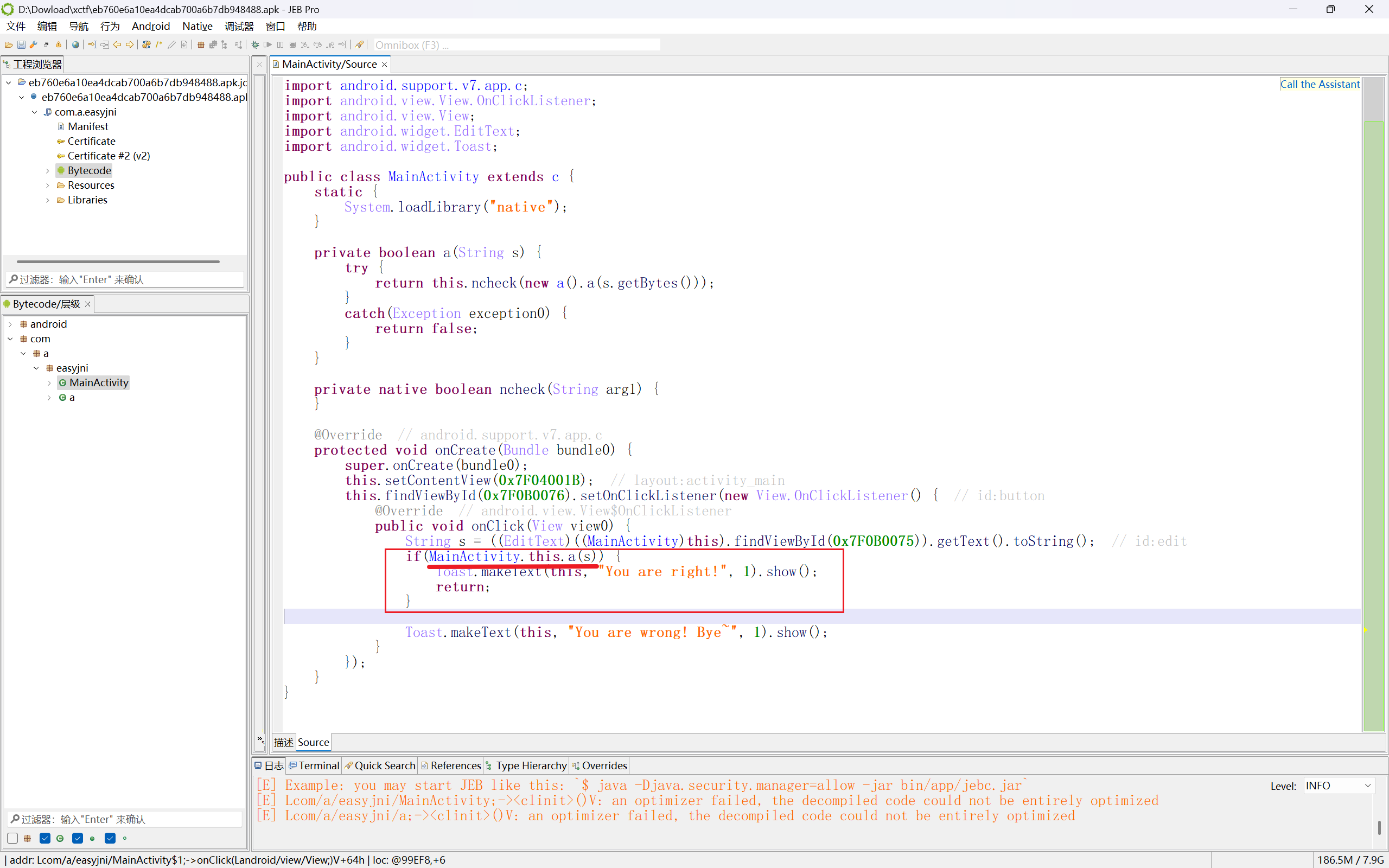
调用了方法a
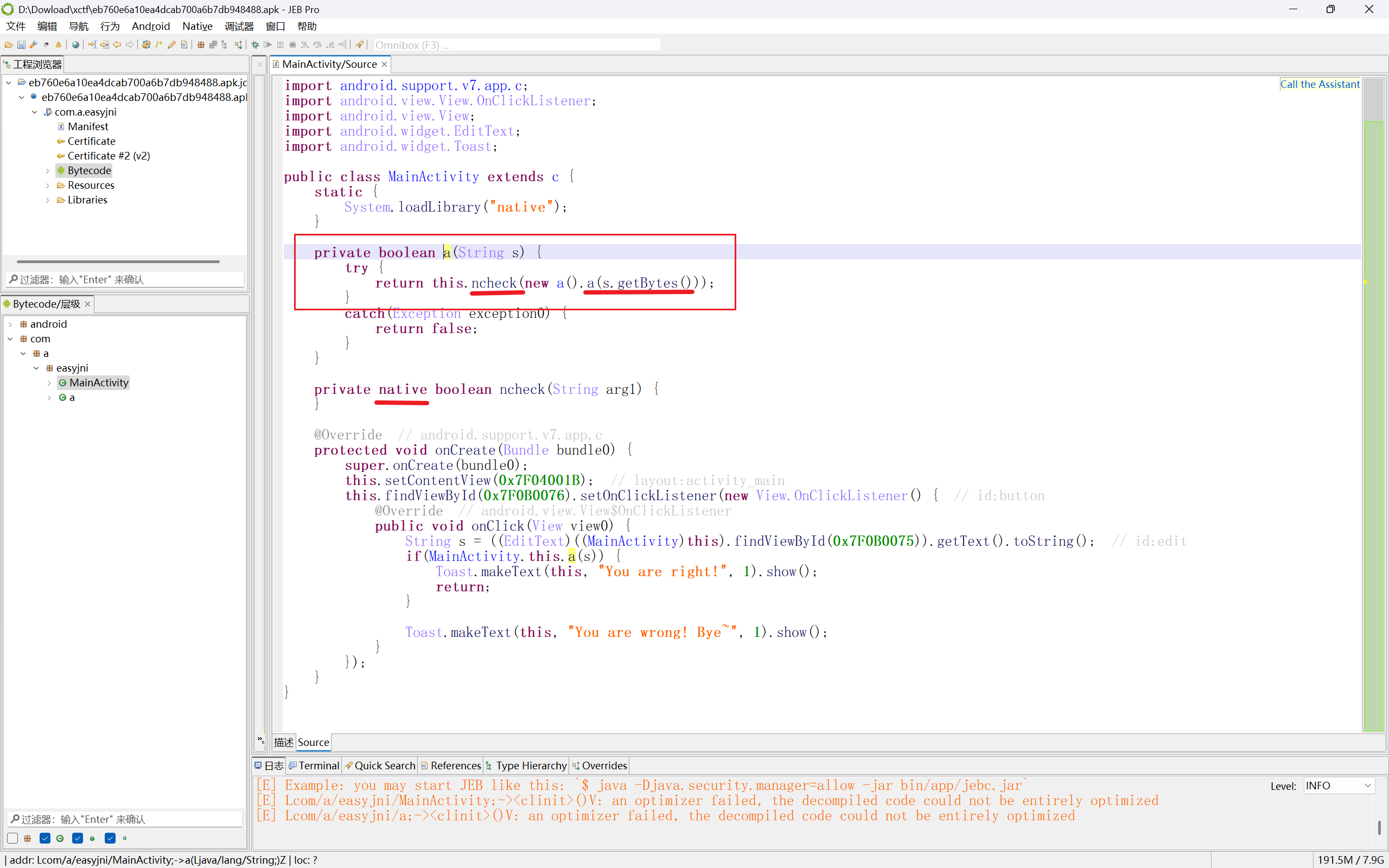
跟进发现,调用完方法a还调用了check方法,native关键字说明是so文件
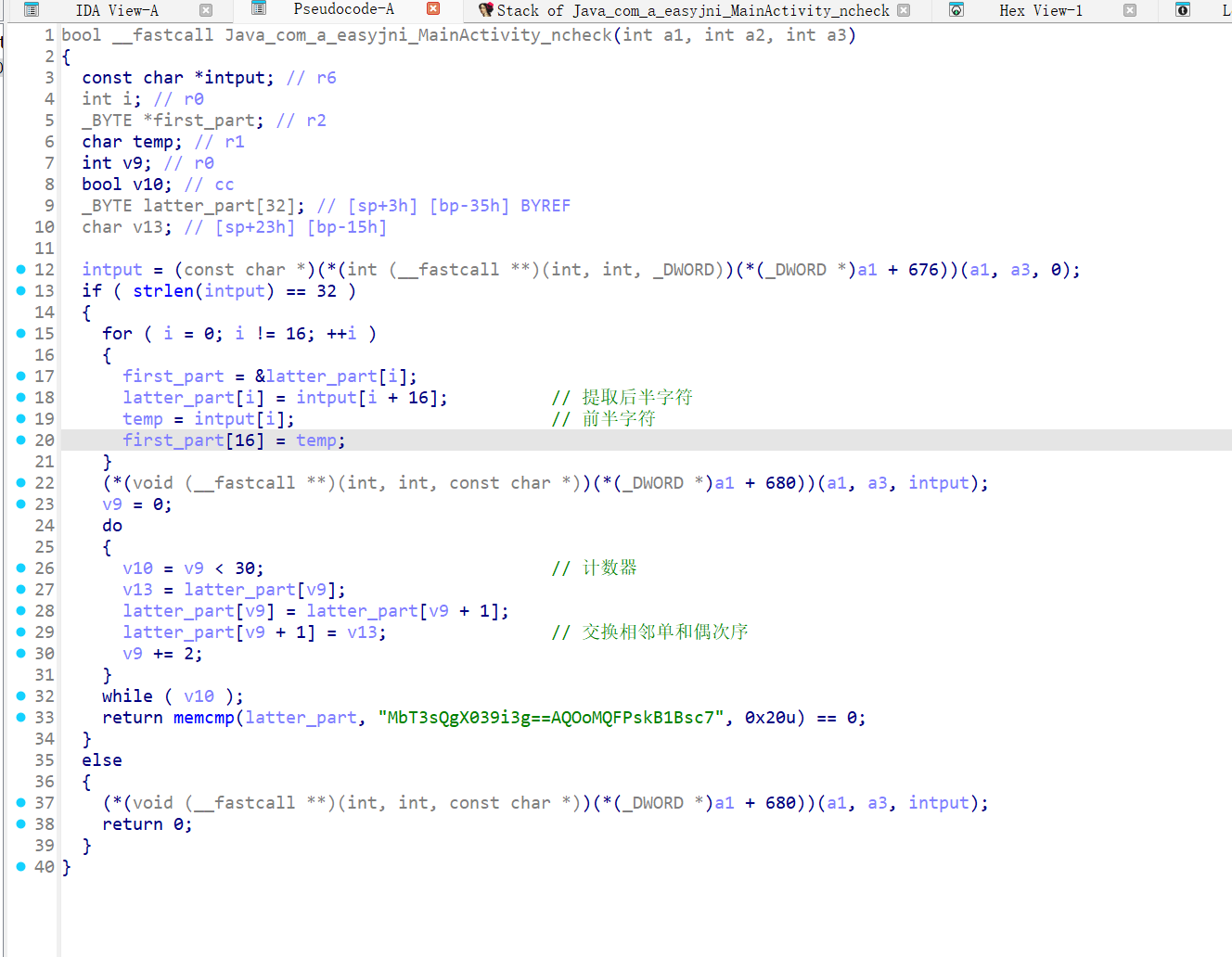
方法check的逆向
str1="MbT3sQgX039i3g==AQOoMQFPskB1Bsc7"
str2="00000000000000000000000000000000"
s2_list=list(str2)
for i in range(0,len(str1),2):s2_list[i] = str1[i+1]s2_list[i+1] = str1[i]
print("".join(s2_list))
for i in range(0,int(len(str1)/2),1):s3_list[i+16] =s2_list[i]s3_list[i] =s2_list[i+16]
print("".join(s3_list))
那么继续看a方法
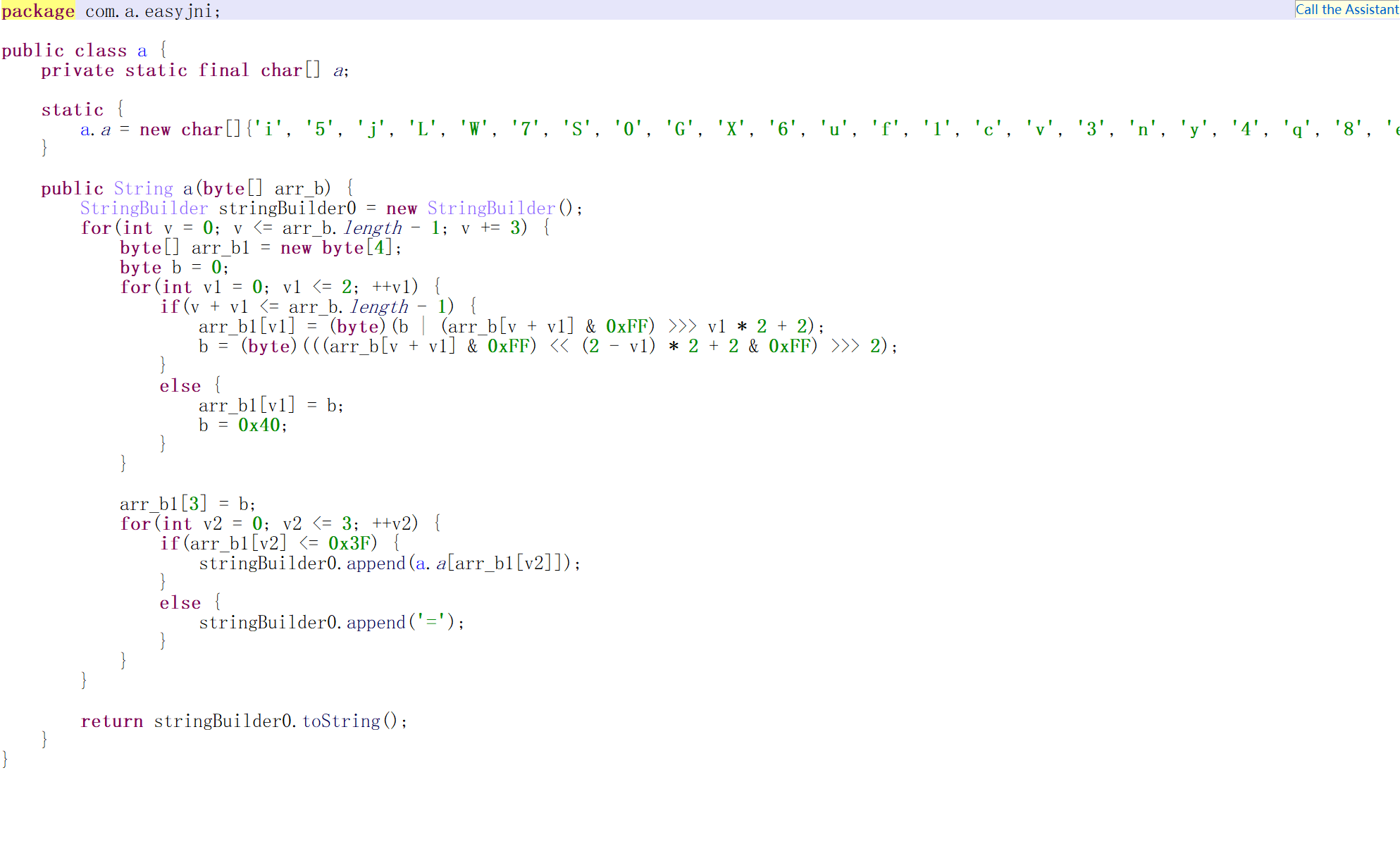
显然是base变种
import base64
str1="MbT3sQgX039i3g==AQOoMQFPskB1Bsc7"
str2="00000000000000000000000000000000"
s2_list=list(str2)
s3_list=["0"]*len(str1)
key_list=['i', '5', 'j', 'L', 'W', '7', 'S', '0', 'G', 'X', '6', 'u', 'f', '1', 'c', 'v', '3', 'n', 'y', '4', 'q', '8', 'e', 's', '2', 'Q', '+', 'b', 'd', 'k', 'Y', 'g', 'K', 'O', 'I', 'T', '/', 't', 'A', 'x', 'U', 'r', 'F', 'l', 'V', 'P', 'z', 'h', 'm', 'o', 'w', '9', 'B', 'H', 'C', 'M', 'D', 'p', 'E', 'a', 'J', 'R', 'Z', 'N']
for i in range(0,len(str1),2):s2_list[i] = str1[i+1]s2_list[i+1] = str1[i]
print("".join(s2_list))for i in range(0,int(len(str1)/2),1):s3_list[i+16] =s2_list[i]s3_list[i] =s2_list[i+16]
print("".join(s3_list))
encoded="".join(s3_list)
old = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
new = "".join(key_list)
mapper = str.maketrans(new,old)
tmp=encoded.translate(mapper)
flag=base64.b64decode(tmp)
print(flag)
base64实现分析
Base64
简介
Base64是一种二进制到文本的编码方式,而且编码出的字符串只包含ASCII基础字符。
其设计目的是为了解决各系统以及传输协议中二进制不兼容的问题而导致信息丢失的问题。
Base64使用到的64个字符: A-Z 26个,a-z 26个,0-9 10个,+ 1个,/ 1个。
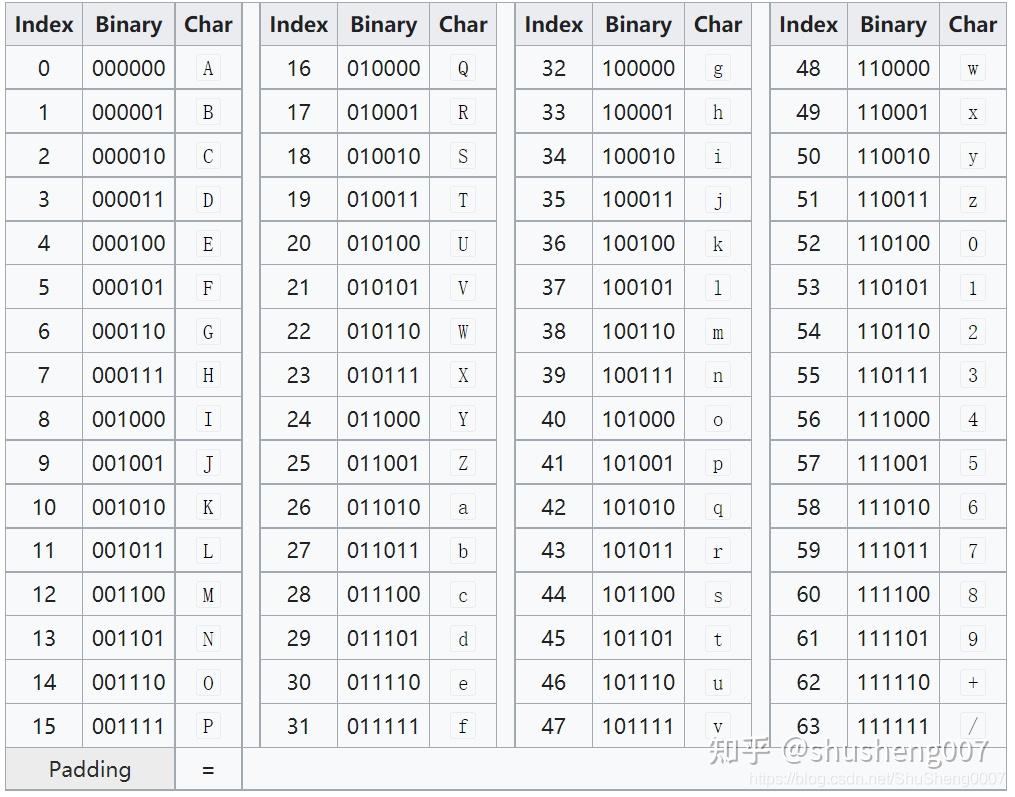
算法解析
流程原理
-
将原始数据每三个字节作为一组,每个字节是8个bit,所以一共是 24 个 bit
-
将 24 个 bit 分为四组,每组 6 个 bit
-
在每组前面加补 00,将其补全成四组8个bit
-
到此步,原生数据的3个字节已经变成4个字节了,增大了将近30%
-
根据Base64码表得到扩展后每个字节的对应符号(见上图)
代码实现
当进行编码的数据长度是3的倍数时,len=strlen(str_in)/3*4;
当进行编码的数据长度不是3的倍数时,len=(strlen(str_in)/3+1)*4;

(如上图),上面的索引是一个数组的索引,BASE64编码就是索引对应的表单。
static const char base64_alphabet[] = {//索引19就是T'A', 'B', 'C', 'D', 'E', 'F', 'G','H', 'I', 'J', 'K', 'L', 'M', 'N','O', 'P', 'Q', 'R', 'S', 'T','U', 'V', 'W', 'X', 'Y', 'Z','a', 'b', 'c', 'd', 'e', 'f', 'g','h', 'i', 'j', 'k', 'l', 'm', 'n','o', 'p', 'q', 'r', 's', 't','u', 'v', 'w', 'x', 'y', 'z','0', '1', '2', '3', '4', '5', '6', '7', '8', '9','+', '/'};for(i=0,j=0;i<len-2;j+=3,i+=4)//文本转索引 { res[i]=base64_table[str[j]>>2]; //取出第一个字符的前6位并找出对应的结果字符 res[i+1]=base64_table[(str[j]&0x3)<<4 | (str[j+1]>>4)]; //将第一个字符的后位与第二个字符的前4位进行组合并找到对应的结果字符 res[i+2]=base64_table[(str[j+1]&0xf)<<2 | (str[j+2]>>6)]; //将第二个字符的后4位与第三个字符的前2位组合并找出对应的结果字符 res[i+3]=base64_table[str[j+2]&0x3f]; //取出第三个字符的后6位并找出结果字符 }
解码时,就是把BASE64编码转换为索引再还原(如T对应ASCII是x,则把数组x的值设置为19)。
static const unsigned char base64_suffix_map[256] = {255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 253, 255,255, 253, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 253, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 62, 255, 255, 255, 63,52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 255, 255,255, 254, 255, 255, 255, 0, 1, 2, 3, 4, 5, 6,7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,19, 20, 21, 22, 23, 24, 25, 255, 255, 255, 255, 255,255, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36,37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,49, 50, 51, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255 };for(i=0,j=0;i < len-2;j+=3,i+=4) //解码{ res[j]=((unsigned char)table[code[i]])<<2 | (((unsigned char)table[code[i+1]])>>4); //取出第一个字符对应base64表的十进制数的前6位与第二个字符对应base64表的十进制数的后2位进行组合 res[j+1]=(((unsigned char)table[code[i+1]])<<4) | (((unsigned char)table[code[i+2]])>>2); //取出第二个字符对应base64表的十进制数的后4位与第三个字符对应bas464表的十进制数的后4位进行组合 res[j+2]=(((unsigned char)table[code[i+2]])<<6) | ((unsigned char)table[code[i+3]]); //取出第三个字符对应base64表的十进制数的后2位与第4个字符进行组合 }
完整代码
#include <stdio.h>
#include <stdlib.h>// base64 转换表, 共64个
static const char base64_alphabet[] = {'A', 'B', 'C', 'D', 'E', 'F', 'G','H', 'I', 'J', 'K', 'L', 'M', 'N','O', 'P', 'Q', 'R', 'S', 'T','U', 'V', 'W', 'X', 'Y', 'Z','a', 'b', 'c', 'd', 'e', 'f', 'g','h', 'i', 'j', 'k', 'l', 'm', 'n','o', 'p', 'q', 'r', 's', 't','u', 'v', 'w', 'x', 'y', 'z','0', '1', '2', '3', '4', '5', '6', '7', '8', '9','+', '/'};// 解码时使用 base64DecodeChars
static const unsigned char base64_suffix_map[256] = {255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 253, 255,255, 253, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 253, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 62, 255, 255, 255, 63,52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 255, 255,255, 254, 255, 255, 255, 0, 1, 2, 3, 4, 5, 6,7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,19, 20, 21, 22, 23, 24, 25, 255, 255, 255, 255, 255,255, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36,37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,49, 50, 51, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,255, 255, 255, 255 };static char cmove_bits(unsigned char src, unsigned lnum, unsigned rnum) {src <<= lnum; src >>= rnum;return src;
}int base64_encode( char *indata, int inlen, char *outdata, int *outlen) {int ret = 0; // return valueif (indata == NULL || inlen == 0) {return ret = -1;}int in_len = 0; // 源字符串长度, 如果in_len不是3的倍数, 那么需要补成3的倍数int pad_num = 0; // 需要补齐的字符个数, 这样只有2, 1, 0(0的话不需要拼接, )if (inlen % 3 != 0) {pad_num = 3 - inlen % 3;}in_len = inlen + pad_num; // 拼接后的长度, 实际编码需要的长度(3的倍数)int out_len = in_len * 8 / 6; // 编码后的长度char *p = outdata; // 定义指针指向传出data的首地址//编码, 长度为调整后的长度, 3字节一组for (int i = 0; i < in_len; i+=3) {int value = *indata >> 2; // 将indata第一个字符向右移动2bit(丢弃2bit)char c = base64_alphabet[value]; // 对应base64转换表的字符*p = c; // 将对应字符(编码后字符)赋值给outdata第一字节//处理最后一组(最后3字节)的数据if (i == inlen + pad_num - 3 && pad_num != 0) {if(pad_num == 1) {*(p + 1) = base64_alphabet[(int)(cmove_bits(*indata, 6, 2) + cmove_bits(*(indata + 1), 0, 4))];*(p + 2) = base64_alphabet[(int)cmove_bits(*(indata + 1), 4, 2)];*(p + 3) = '=';} else if (pad_num == 2) { // 编码后的数据要补两个 '='*(p + 1) = base64_alphabet[(int)cmove_bits(*indata, 6, 2)];*(p + 2) = '=';*(p + 3) = '=';}} else { // 处理正常的3字节的数据*(p + 1) = base64_alphabet[cmove_bits(*indata, 6, 2) + cmove_bits(*(indata + 1), 0, 4)];*(p + 2) = base64_alphabet[cmove_bits(*(indata + 1), 4, 2) + cmove_bits(*(indata + 2), 0, 6)];*(p + 3) = base64_alphabet[*(indata + 2) & 0x3f];}p += 4;indata += 3;}if(outlen != NULL) {*outlen = out_len;}return ret;
}int base64_decode(const char *indata, int inlen, char *outdata, int *outlen) {int ret = 0;if (indata == NULL || inlen <= 0 || outdata == NULL || outlen == NULL) {return ret = -1;}if (inlen % 4 != 0) { // 需要解码的数据不是4字节倍数return ret = -2;}int t = 0, x = 0, y = 0, i = 0;unsigned char c = 0;int g = 3;//while (indata[x] != 0) {while (x < inlen) {// 需要解码的数据对应的ASCII值对应base64_suffix_map的值c = base64_suffix_map[indata[x++]];if (c == 255) return -1;// 对应的值不在转码表中if (c == 253) continue;// 对应的值是换行或者回车if (c == 254) { c = 0; g--; }// 对应的值是'='t = (t<<6) | c; // 将其依次放入一个int型中占3字节if (++y == 4) {outdata[i++] = (unsigned char)((t>>16)&0xff);if (g > 1) outdata[i++] = (unsigned char)((t>>8)&0xff);if (g > 2) outdata[i++] = (unsigned char)(t&0xff);y = t = 0;}}if (outlen != NULL) {*outlen = i;}return ret;
}
python实现base64变种
import base64encoded = "zCN7zTJJP3hj71C3Bxsj72susnhQ="
old = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
new = "abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ+/"mapper = str.maketrans(new, old)
tmp = encoded.translate(mapper)
flag = base64.b64decode(tmp)print(flag.decode())