8.高斯混合模型
高斯混合模型,简称GMM,对数据可以进行聚类或拟合,多用于传统语音识别。他会将每个数据看做多个高斯分布混合生成的。
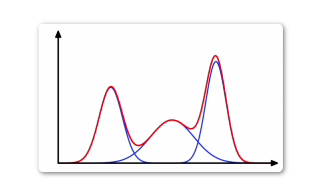
对于无标签的数据进行聚类,一般采用高斯混合模型处理。
算法过程
1.首先进行初始猜测,假设有n个簇,然后随机选择数据点,作为聚类中心点。
2.EM算法多次迭代,每次迭代更新中心点,并且还会计算每个数据点属于每个簇的概率。
3.迭代完成
高斯混合模型,简称GMM,对数据可以进行聚类或拟合,多用于传统语音识别。他会将每个数据看做多个高斯分布混合生成的。
对于无标签的数据进行聚类,一般采用高斯混合模型处理。
算法过程
1.首先进行初始猜测,假设有n个簇,然后随机选择数据点,作为聚类中心点。
2.EM算法多次迭代,每次迭代更新中心点,并且还会计算每个数据点属于每个簇的概率。
3.迭代完成