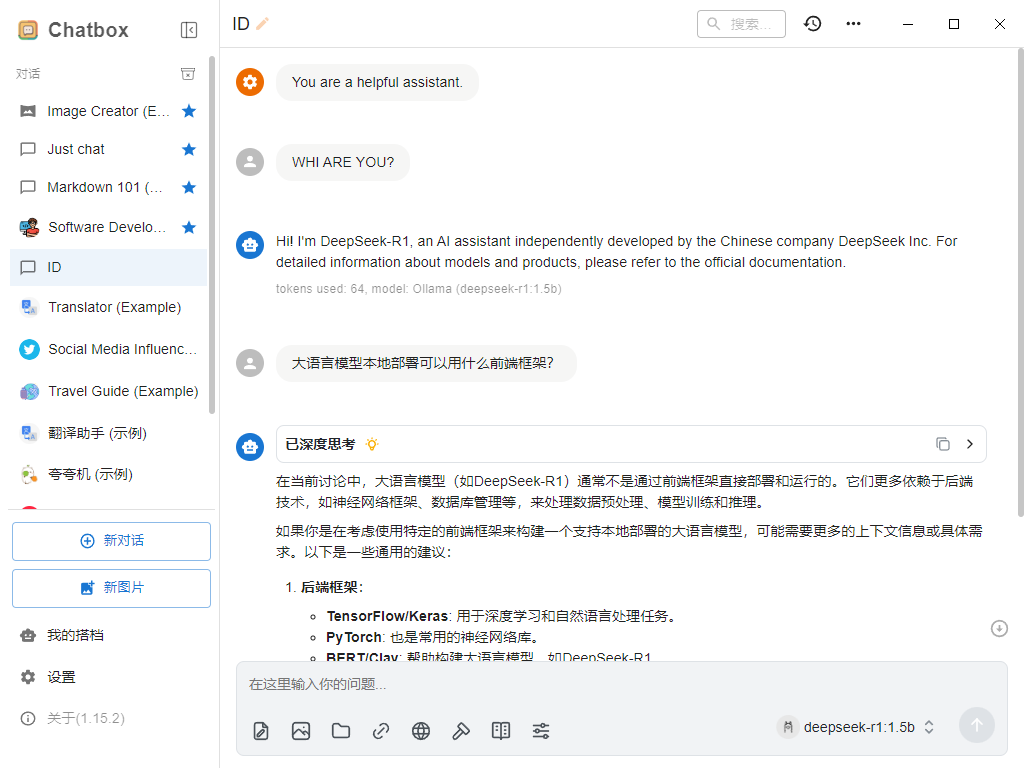
个人电脑部署私有化大语言模型LLM
个人电脑部署私有化大语言模型
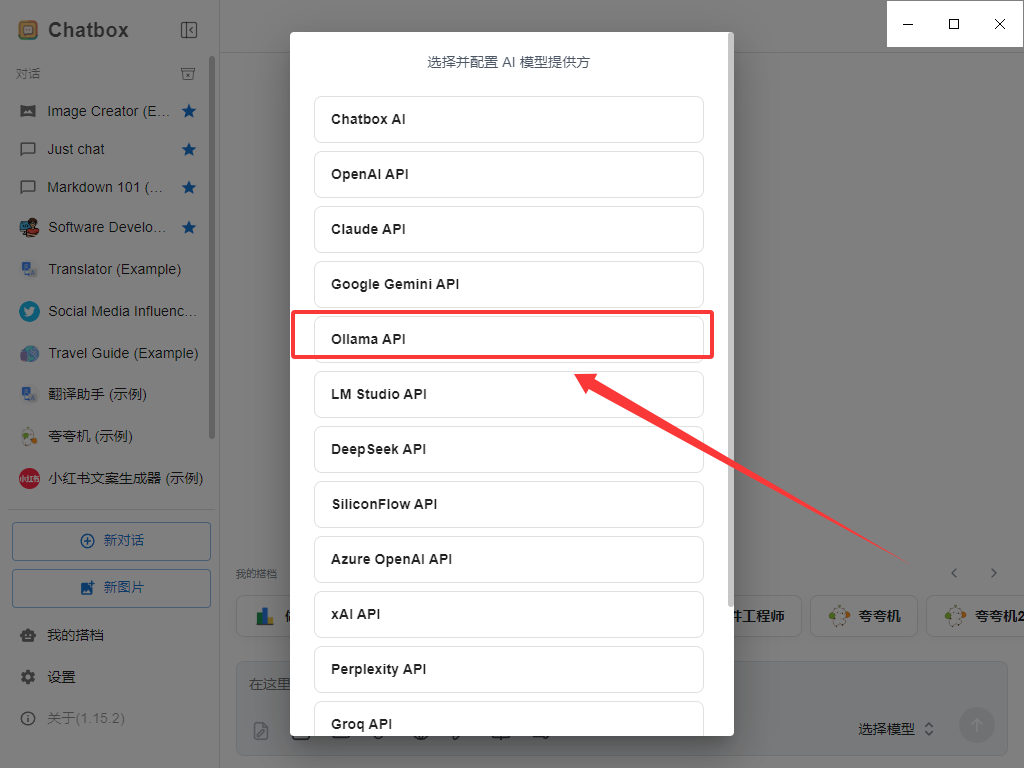
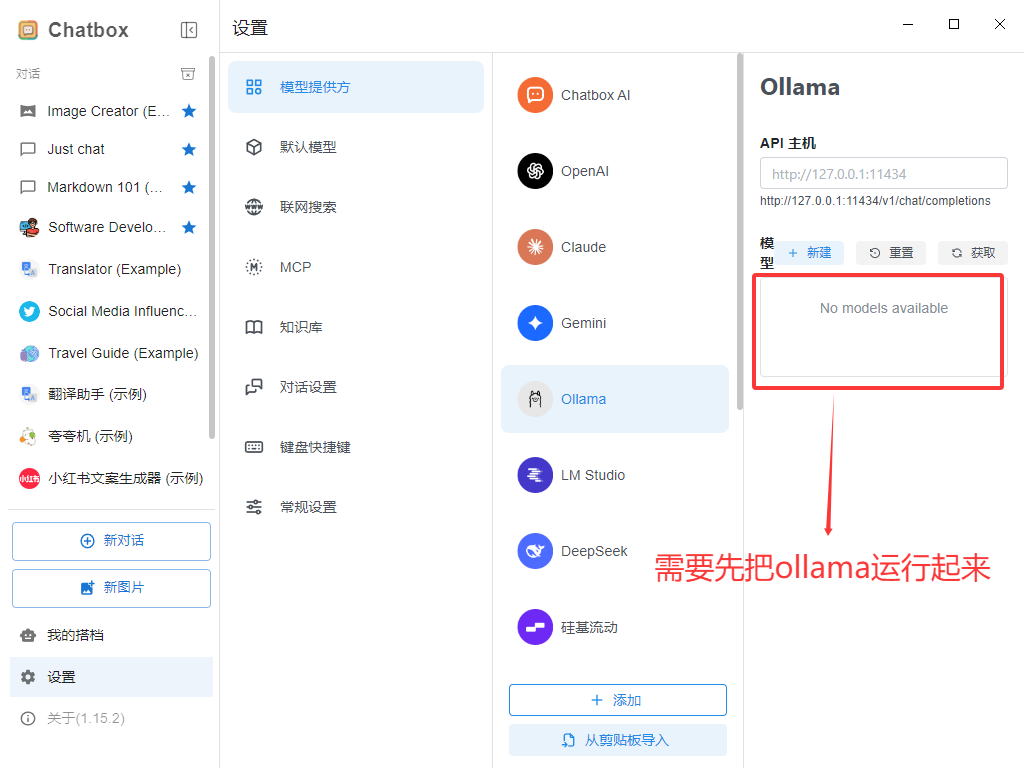
首先要知道的是我们需要后端和前端,这里我们使用后端ollama,但是由于部署完后端之后,需要用命令行操作,不方便,
所以我们需要部署前端框架(chatbox AI, Stremlit(需要编程实现))
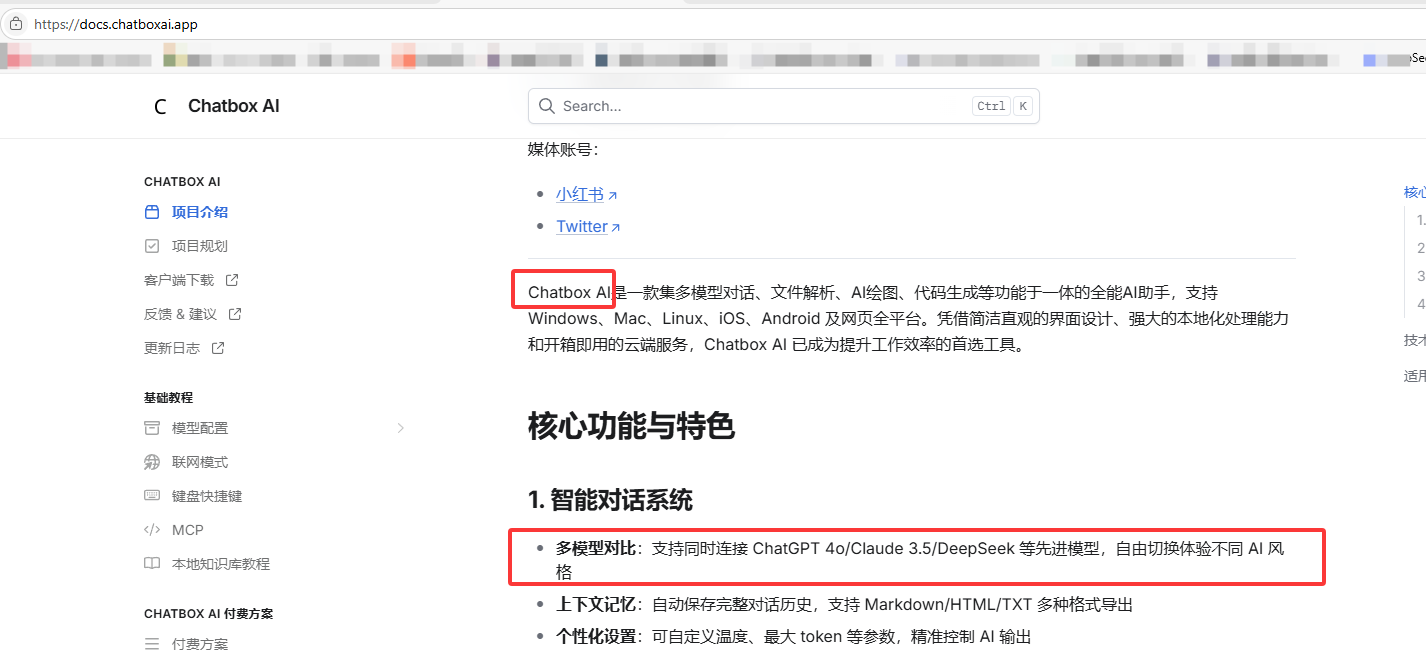
Chatbox AI
是一款集多模型对话、文件解析、AI绘图、代码生成等功能于一体的全能AI助手,支持Windows、Mac、Linux、iOS、Android 及网页全平台。凭借简洁直观的界面设计、强大的本地化处理能力和开箱即用的云端服务,Chatbox AI 已成为提升工作效率的首选工具。
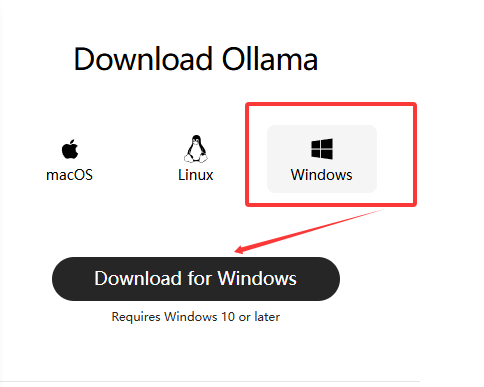
后端 :ollama下载
https://ollama.com/download
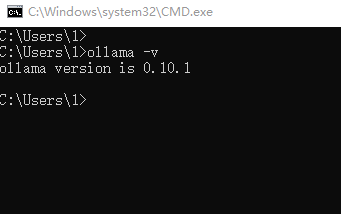
 、
、
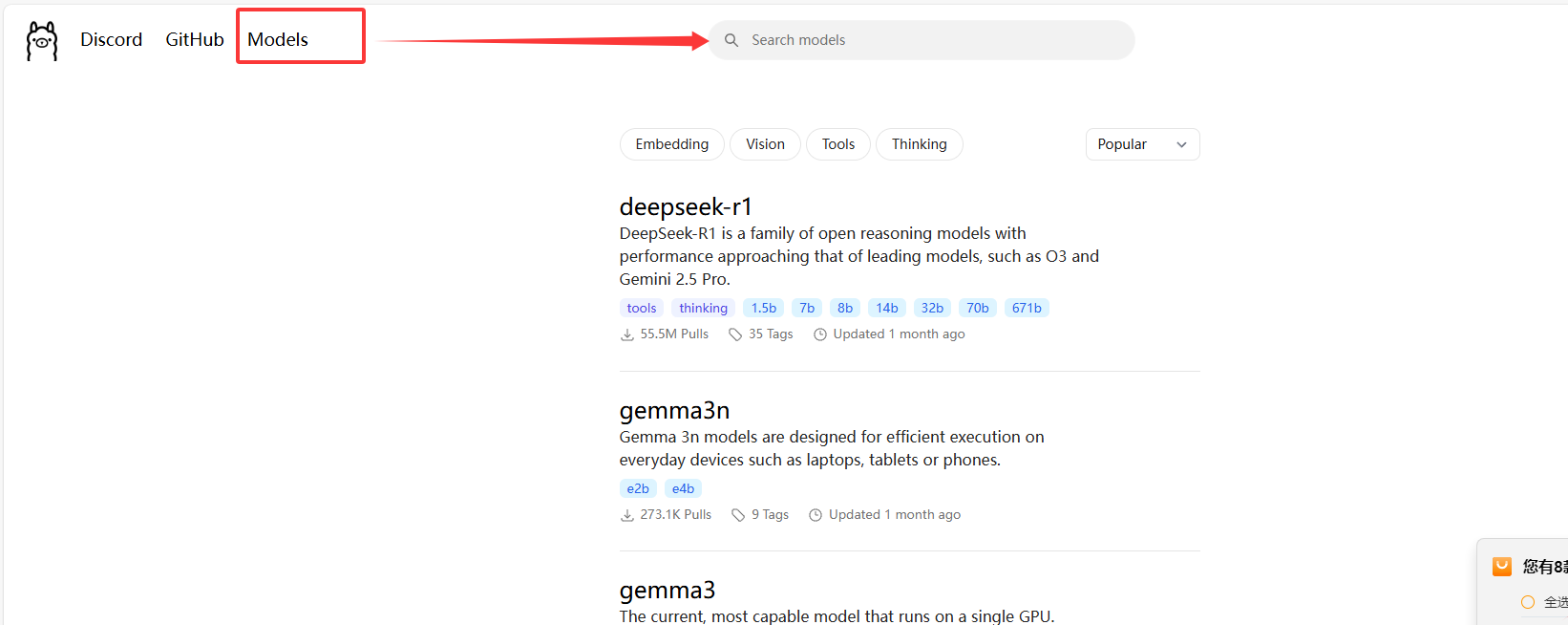
可以search models搜索你需要的模型,我将部署deepseek所以直接点击第一个
点击deep seek后选择你需要部署的模型,这里我将部署最小的模型,点击箭头所指
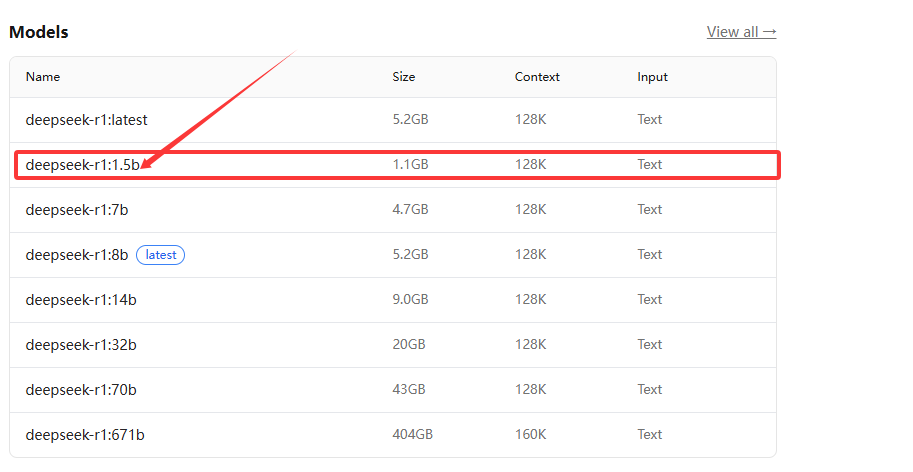
点击上述箭头之后,会出现下述的命令行
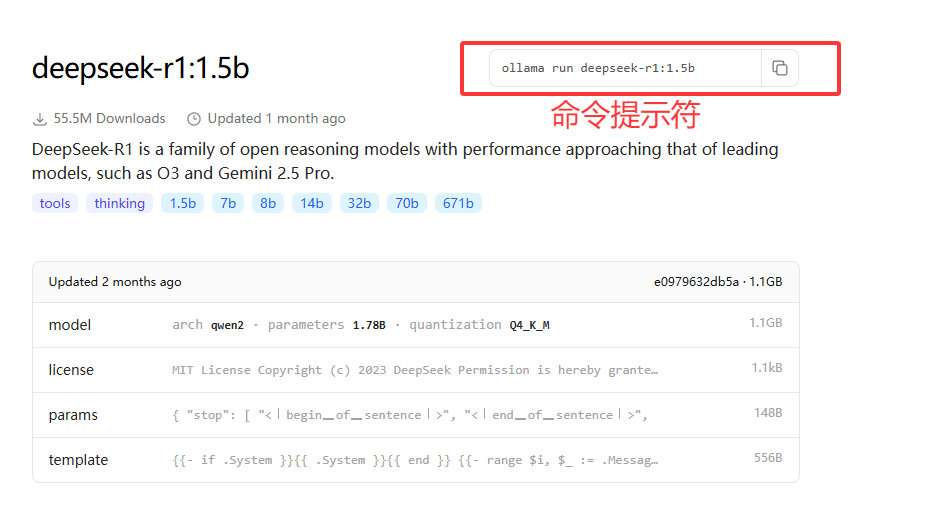
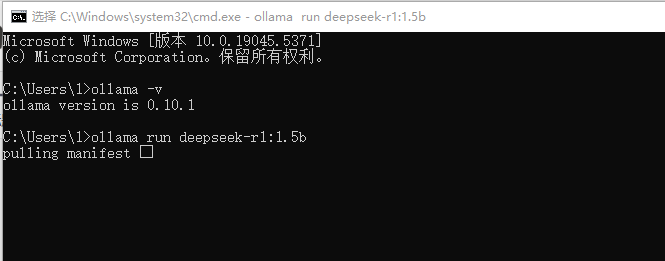
把命令行输入到命令行窗口
ollama run deepseek-r1:1.5b
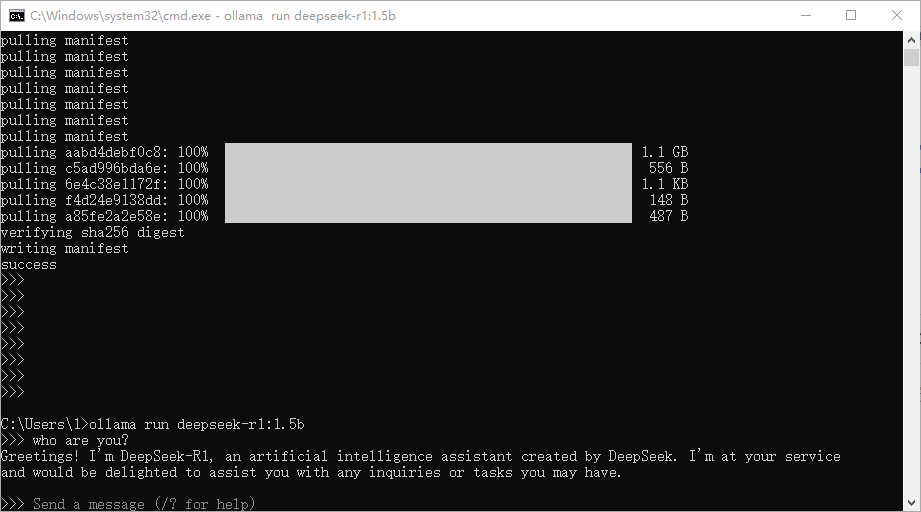
部署成功,可以使用命令行进行询问
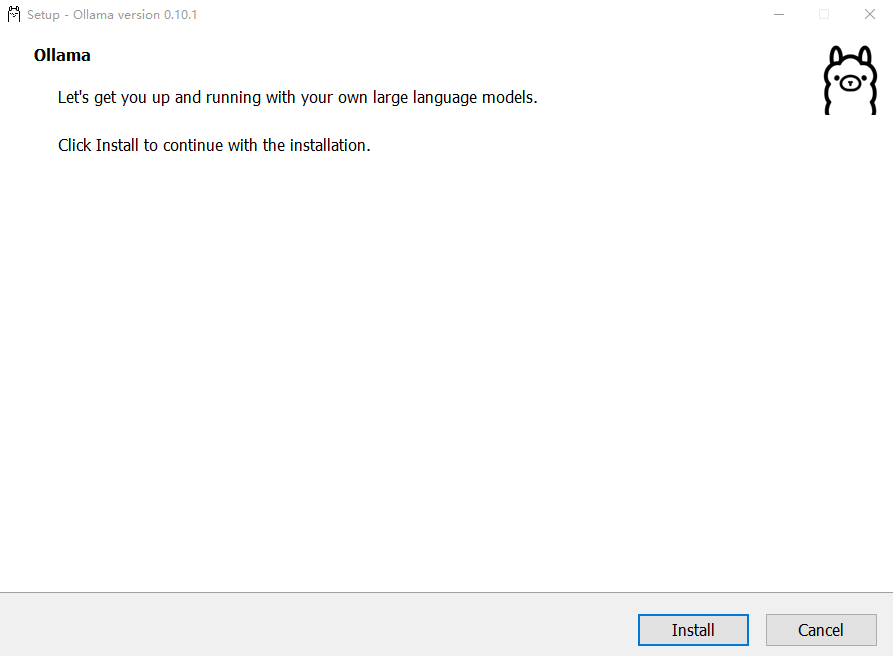
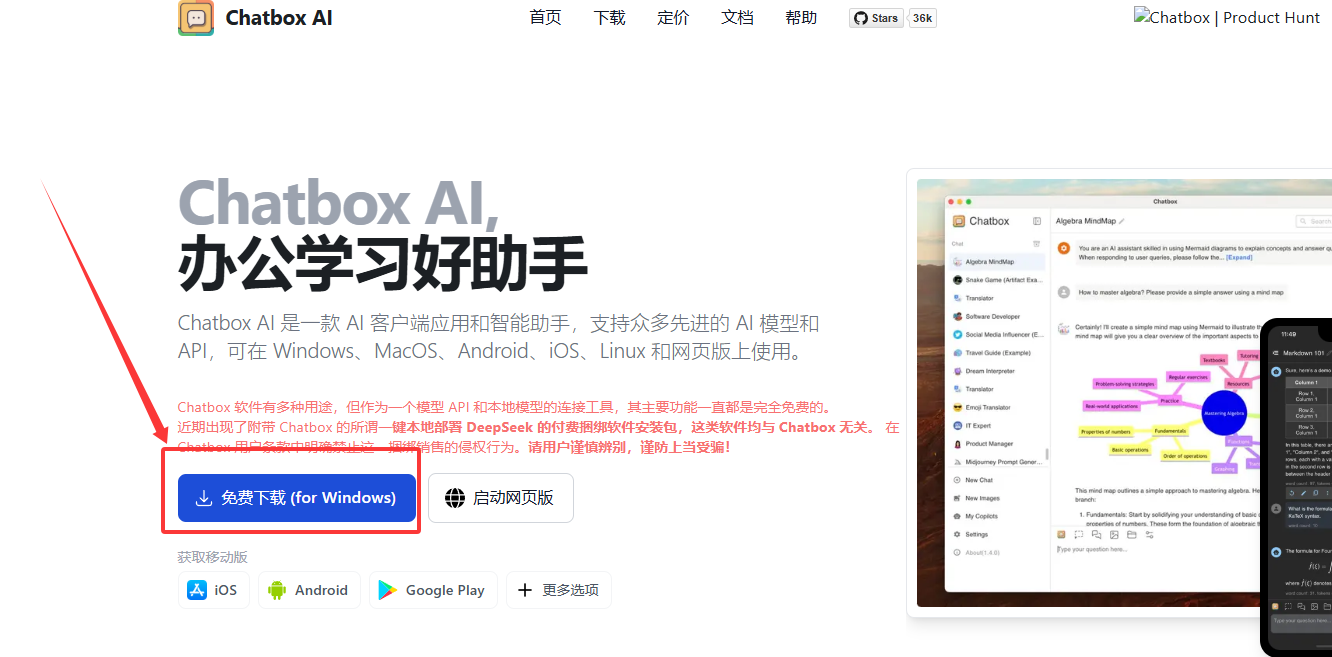
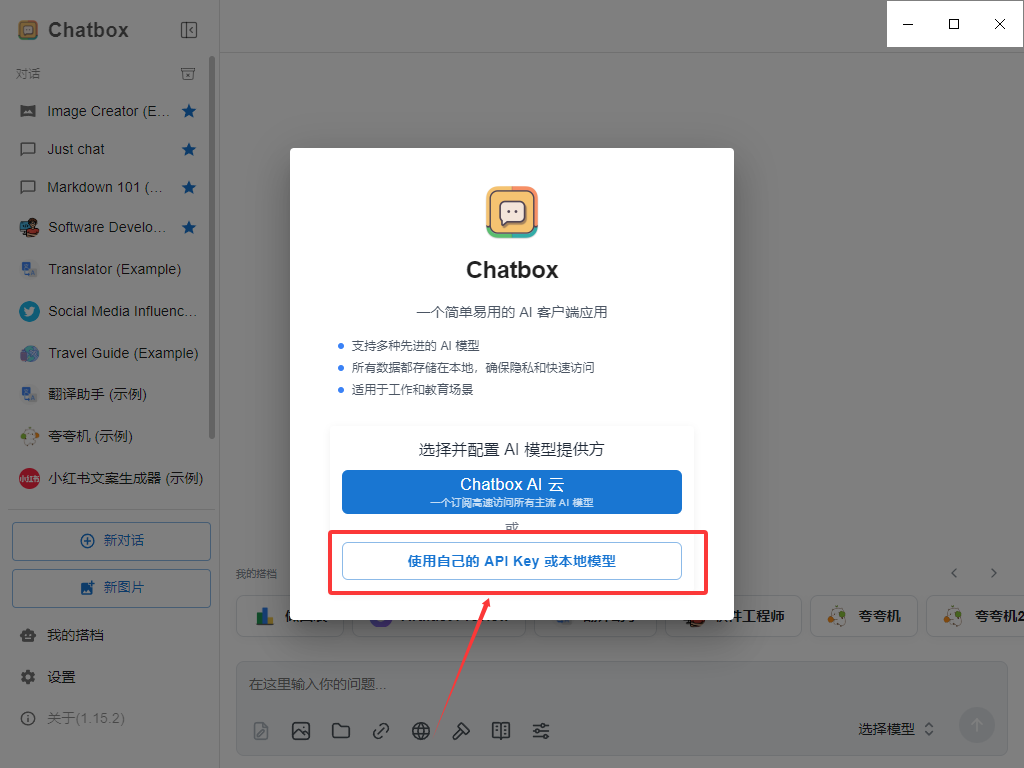
前端部署 :安装chatbox AI
在这里插入图片描述
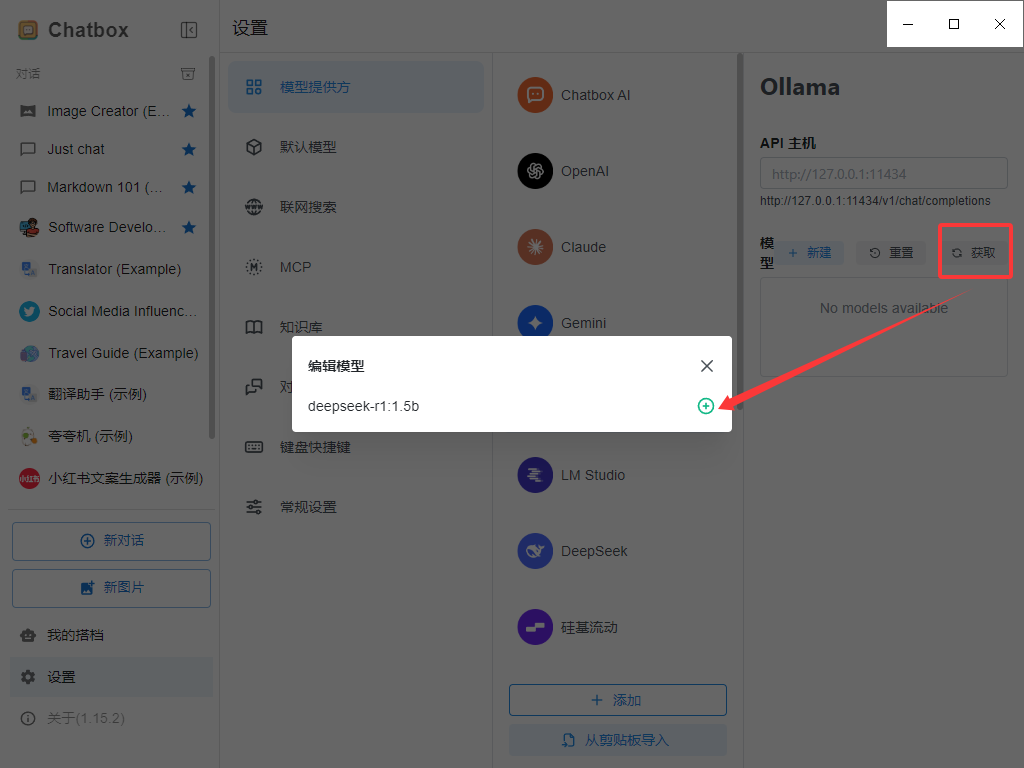
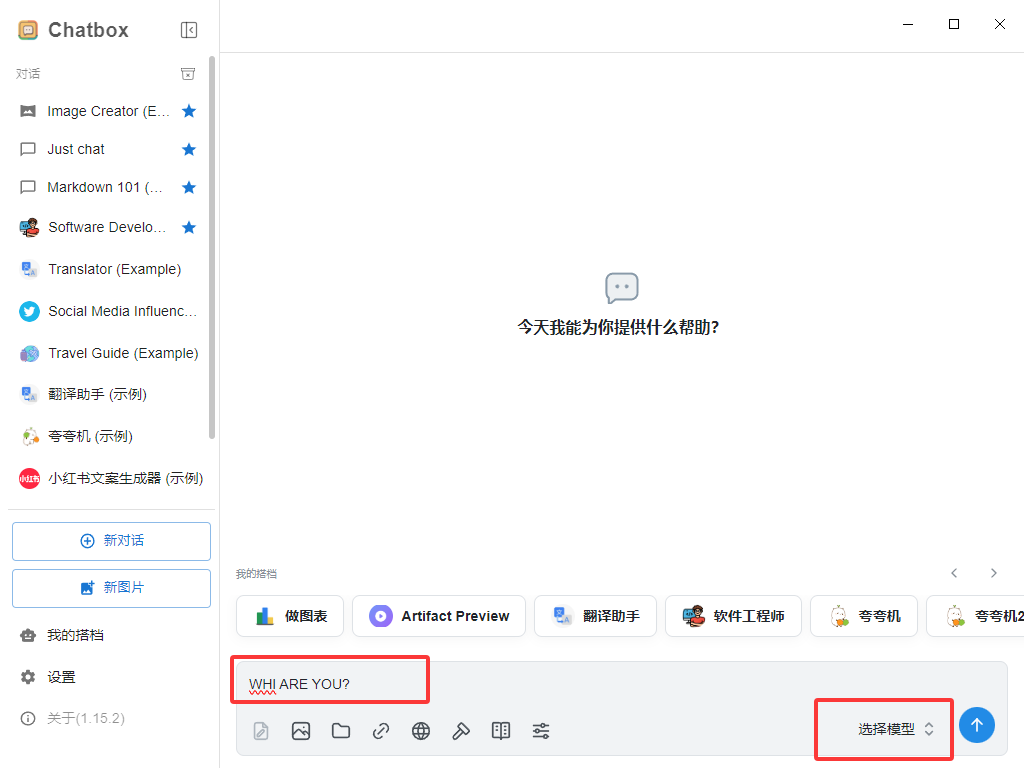
部署成功