Kubernetes Service 全面详解:从概念到实践
前言
在 Kubernetes 中,Pod 是最小的部署单元,但 Pod 存在生命周期短、IP 动态变化等特点,直接通过 Pod IP 访问服务会面临诸多问题。Kubernetes Service 作为集群内部服务暴露和负载均衡的核心组件,解决了这些难题。本文将从概念原理、工作模式、实践操作到排错总结,全面讲解 Kubernetes Service,帮助读者深入理解并掌握其使用方法。
1.Service 概念原理
1.1 概述
Kubernetes Service 定义了一种抽象:一个 Pod 的逻辑分组,以及访问它们的策略(通常称为微服务)。这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector 进行关联。
简单来说,Service 就像一个 “中介”,它为一组具有相同标签的 Pod 提供一个稳定的访问入口,并实现负载均衡功能。无论后端 Pod 如何动态变化(创建、删除、IP 变更等),客户端只需通过 Service 提供的固定地址即可访问服务。
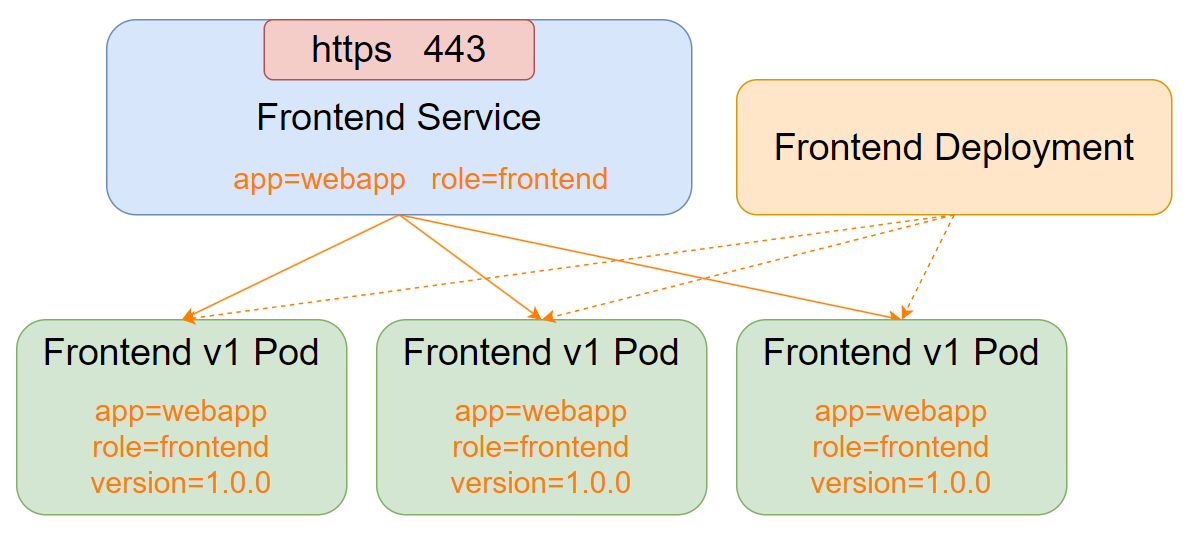
1.2为什么需要 Service
在 Kubernetes 集群中,我们可以通过 Deployment 等控制器创建多个副本的 Pod 来提供服务。例如,创建 100 个 myapp 的 Pod 给用户提供访问。但此时存在一个问题:如何为用户提供一个统一的接口并实现负载均衡?
如果不使用 Service,直接通过 Pod IP 配置负载均衡(如 Nginx 的 upstream)会存在以下问题:
- 当 Pod 发生故障重建时,其 IP 会发生变化,而 Nginx 配置中的 IP 不会自动更新,导致访问失败。
- 即使 Nginx 有存活探测功能,能剔除已死亡的 Pod,但无法自动添加新创建的 Pod。
- 需要编写额外的脚本从 apiserver 抓取 Pod 变化并更新配置,操作复杂。
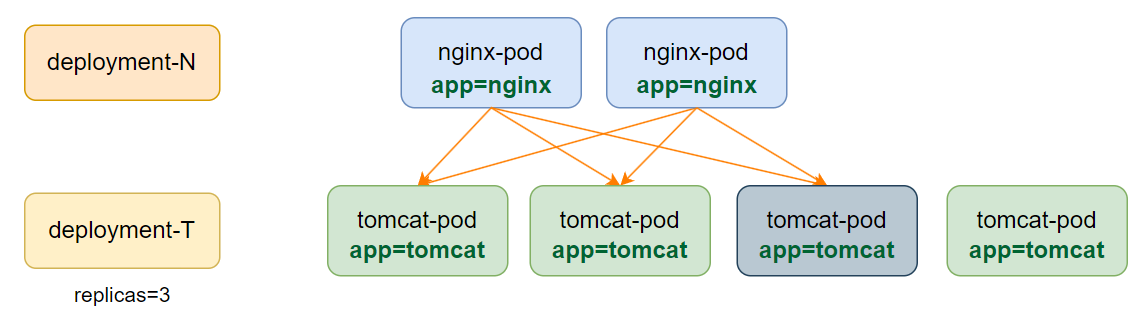
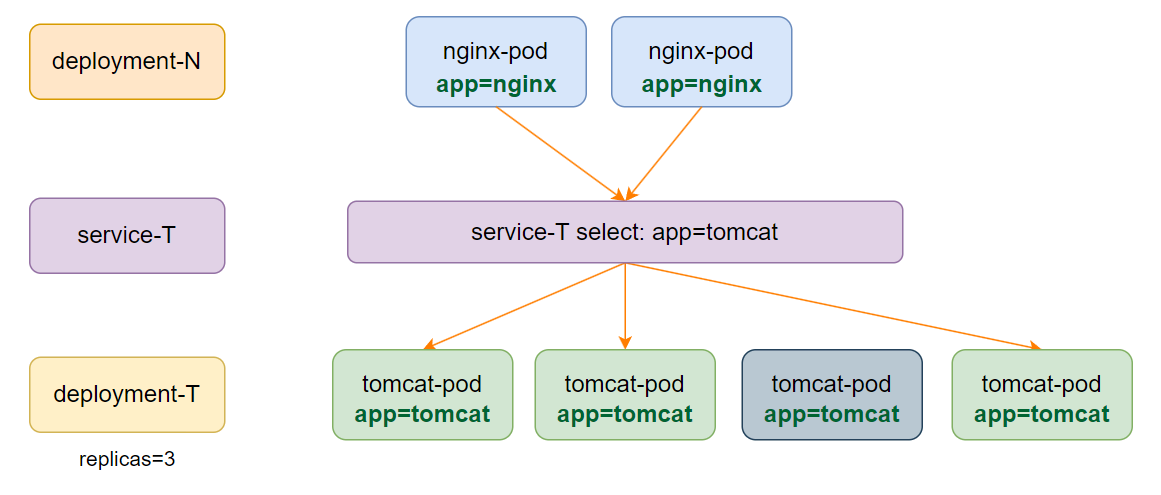
Service 恰好解决了这些问题:
- Service 会为一组 Pod 提供一个固定的虚拟 IP(VIP)。
- 通过 Label Selector 动态关联符合条件的 Pod,当 Pod 发生变化时,Service 会自动更新关联的 Pod 列表。
- 实现了前后端解耦,客户端只需访问 Service 的 VIP,无需关心后端 Pod 的具体信息。
1.3 核心迭代
Kubernetes Service 的实现依赖于每个 Node 上运行的 kube-proxy 进程,kube-proxy 负责为 Service 实现虚拟 IP(VIP)的形式。其迭代过程如下:
- Kubernetes v1.0 版本:代理完全在 userspace(用户空间)。
- Kubernetes v1.1 版本:新增了 iptables 代理,但不是默认模式。
- 从 Kubernetes v1.2 起:默认使用 iptables 代理。
- Kubernetes v1.8.0beta.0 中:添加了 ipvs 代理。
目前,最新的 Kubernetes 集群默认仍使用 iptables 方式实现负载均衡。
验证当前代理模式的小实验:
-
删除所有 cronjob(清理环境):
kubectl delete cronjob --all该命令用于删除集群中所有的 CronJob 资源,避免对后续实验产生干扰。
-
创建一个 deployment 控制器:
kubectl create deployment myapp --image=harbor.registry.com/library/myapp:1.0kubectl create deployment:创建 Deployment 资源。myapp:Deployment 的名称。--image=harbor.registry.com/library/myapp:1.0:指定创建 Pod 所使用的镜像。
-
查看创建的 Pod:
kubectl get pod输出类似:
NAME READY STATUS RESTARTS AGE myapp-5846867694-lhn5v 1/1 Running 0 14s该命令用于查看当前命名空间下的 Pod 状态,确认 Pod 已成功运行。
-
扩容 deployment:
kubectl scale deployment myapp --replicas=10kubectl scale deployment:用于扩容或缩容 Deployment 管理的 Pod 数量。myapp:要扩容的 Deployment 名称。--replicas=10:指定目标副本数为 10。
-
再次查看 Pod,确认已扩容到 10 个:
kubectl get pod -
创建 service:
kubectl create svc clusterip myapp --tcp=80:80kubectl create svc clusterip:创建 ClusterIP 类型的 Service。myapp:Service 的名称。--tcp=80:80:指定 TCP 端口映射,前面的 80 是 Service 暴露的端口,后面的 80 是 Pod 中容器的端口。
-
查看 ipvs 规则:
ipvsadm -Ln若没有对应的 ipvs 规则,则说明当前使用的是 iptables 代理模式。
1.3.1 userspace 模式
在 userspace 模式下,包含 kube-apiServer 和 kube-proxy 两个组件:
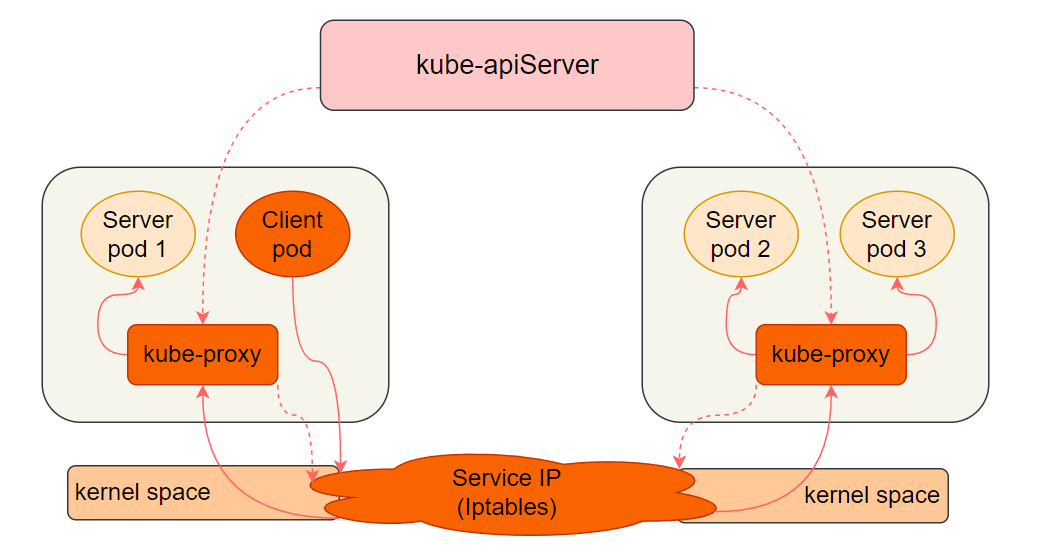
- 每台机器上的 kube-proxy 监听 kube-apiServer,获取 Service 对象的变化。
- 客户端 Pod 访问本地的防火墙规则,防火墙规则将流量转发至当前节点或其他节点的 kube-proxy。
- kube-proxy 再代理请求到后端的 Server Pod,并将结果返回给客户端 Pod,实现负载均衡。
这种模式下,kube-proxy 既负责修改防火墙规则,又负责代理请求,当请求量较大时,kube-proxy 可能成为性能瓶颈。
1.3.2 iptables 模式
iptables 模式同样包含 kube-apiServer 和 kube-proxy 组件:
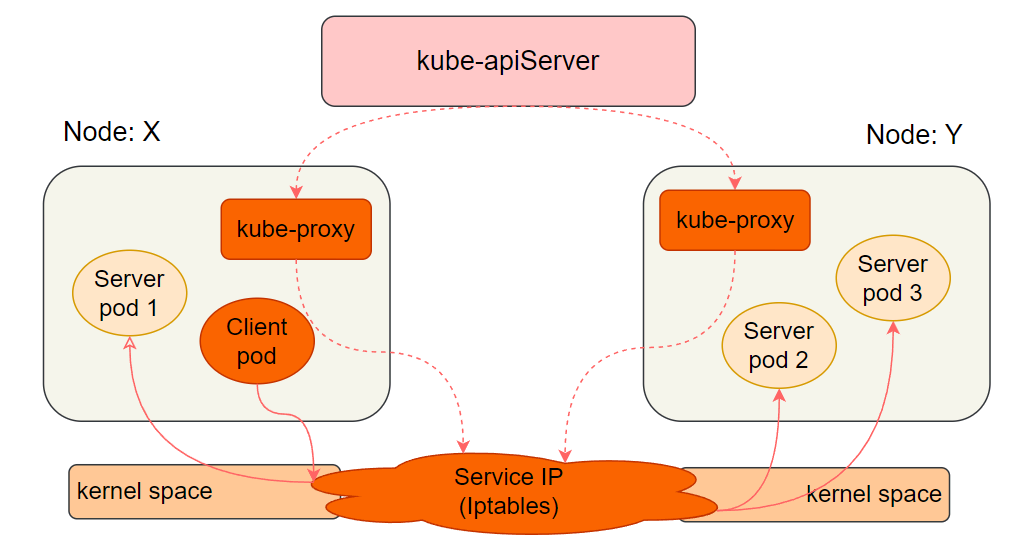
- kube-proxy 监听 kube-apiServer 后,仅将结果写入当前节点的 iptables 规则。
- 客户端的访问完全由 iptables 转发给本地或远程的 Server Pod,kube-proxy 不再参与代理功能。
这种模式实现了解耦,kube-proxy 仅负责更新规则,不参与请求转发,稳定性更高,不会因请求量增大而给 kube-proxy 带来压力。
1.3.3 ipvs 模式
ipvs 模式的工作方式与 iptables 类似,唯一的区别是将底层的 iptables 替换为四层负载均衡器 ipvs(也叫 LVS)。
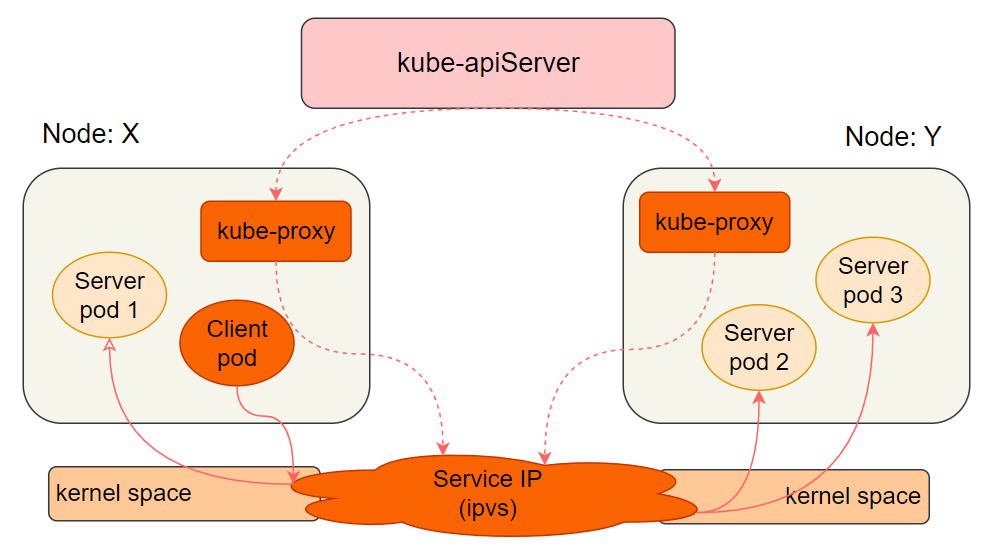
ipvs 在四层负载均衡领域更专业,性能优于 iptables。但默认情况下 Kubernetes 不使用 ipvs,因为需要内核开启 ipvs 模块,官方担心部分机器未启用该模块导致服务无法正常工作。
修改 Kubernetes 集群配置以支持 ipvs 工作方式:
-
编辑 kube-proxy 的 configmap:
kubectl edit configmap kube-proxy -n kube-systemkubectl edit configmap:编辑 ConfigMap 资源。kube-proxy:要编辑的 ConfigMap 名称。-n kube-system:指定命名空间为 kube-system,因为 kube-proxy 运行在该命名空间下。
-
在编辑页面中,找到
mode配置项,将其值改为ipvs:mode: "ipvs" -
保存退出后,删除 kube-proxy 的 Pod 使其重建,以应用新配置:
kubectl delete pod -n kube-system -l k8s-app=kube-proxykubectl delete pod:删除 Pod。-n kube-system:指定命名空间。-l k8s-app=kube-proxy:通过标签选择器删除所有 k8s-app=kube-proxy 的 Pod。
-
查看 kube-proxy 的 Pod 是否重建成功:
kubectl get pod -A -
再次查看 ipvs 规则,确认已生效:
ipvsadm -Ln此时可以看到与 Service 相关的 ipvs 规则。
2. Service 工作模式及使用
2.1 Service 类型
Kubernetes Service 主要有以下几种类型:
- ClusterIP:默认类型,自动分配一个仅集群内部可以访问的虚拟 IP。
- NodePort:在 ClusterIP 基础上,为 Service 在每台机器上绑定一个端口,可通过
<NodeIP>:NodePort访问服务。 - LoadBalancer:在 NodePort 的基础上,借助云服务提供商创建外部负载均衡器,将请求转发到
<NodeIP>:NodePort。 - ExternalName:将集群外部的服务引入到集群内部,通过域名别名实现,无需创建代理。仅 Kubernetes 1.7 或更高版本的 kube-dns 支持。
2.2 组件协同
当管理员通过 kubectl 命令创建 Service 时,流程如下:
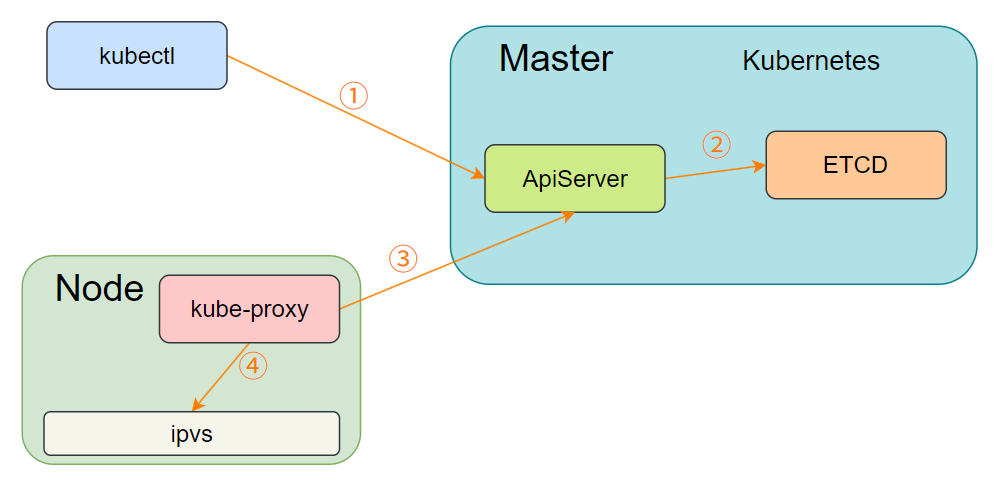
- 请求发送到 ApiServer,并将数据存储到 etcd 数据库中。
- kube-proxy 监听 ApiServer 中 Service 的变化。
- kube-proxy 将 Service 信息转换为对应节点的 IPVS 或 iptables 规则(取决于配置的代理模式)。
2.3 ClusterIP
2.3.1 模式结构
ClusterIP 是默认的 Service 类型,用于为集群内部的 Pod 提供访问服务的固定虚拟 IP。其结构如下:
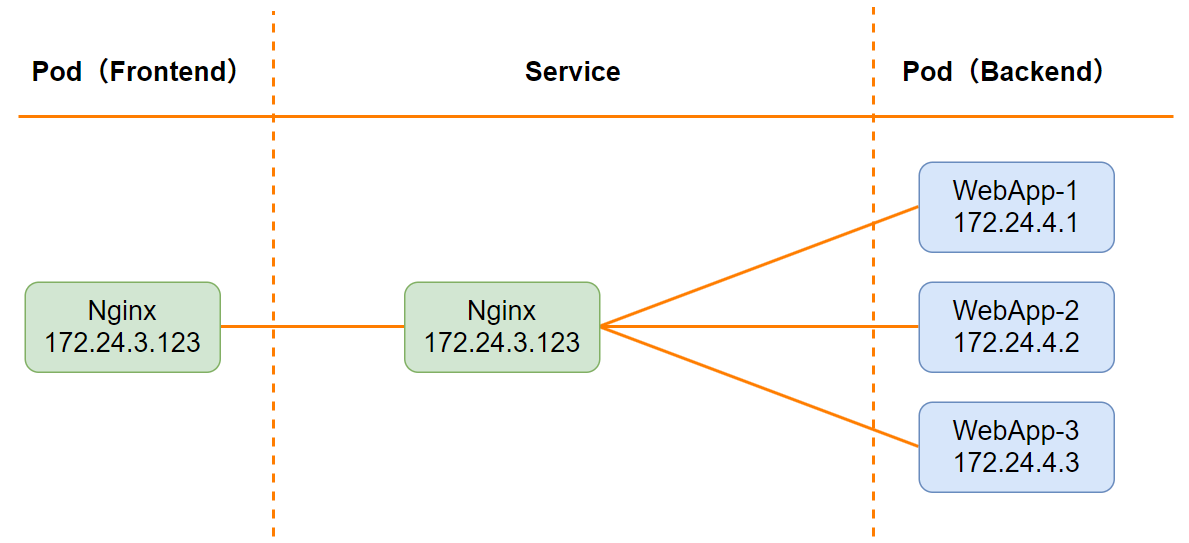
- 前端的 Pod(如 Nginx)通过 Service 访问后端的多个 Pod(如 WebApp)。
- 当后端 Pod 的 IP 发生变化时,Service 会自动发现并更新,对前端 Pod 透明。
ClusterIP 类型的 Service 资源清单示例:
apiVersion: v1 # 接口组版本为核心组 v1 版
kind: Service # 资源类型为 Service
metadata: # 定义元数据name: myapp-clusterip # 当前 service 的名字namespace: default # 放在 default 名字空间下
spec: # 定义期望状态type: ClusterIP # 工作模式为 ClusterIP,默认模式selector: # 标签选择器,需与 pod 的标签匹配app: myapprelease: stabelsvc: clusteripports: # 定义负载均衡集群的端口- name: http # 端口的名称port: 80 # 集群暴露的端口targetPort: 80 # 后端 Pod 中容器的端口
IPVS 支持三种工作模式,Kubernetes 中默认使用 NAT 模式:
- NAT 模式:地址转换模式,后端端口与集群端口可以不同;但入站和出站流量都必须经过 IPVS 调度器。
- DR 模式:直接路由模式,回程流量不经过 IPVS,压力更小;但后端端口和集群端口必须一致,且可能需要配置 ARP 响应。
- TUN 模式:隧道模式,可跨公网组建集群;但需要对数据报文二次封装,性能较低。
在 Kubernetes 中选择 NAT 模式,是因为每个节点的 ipvs 规则仅被当前节点的客户端使用,压力较小,且集群端口与后端端口可以不同,灵活性更高。
2.3.2 模式演示
实验目的:演示 ClusterIP 类型的 Service 如何关联 Pod 并实现负载均衡。
实验步骤:
-
清理环境,删除之前创建的 deployment 和 service:
kubectl delete deployment --all kubectl delete svc myappkubectl delete deployment --all:删除所有 Deployment。kubectl delete svc myapp:删除名为 myapp 的 Service。
-
创建一个目录用于存放资源清单文件,并进入该目录:
mkdir 6 cd 6 -
创建 Deployment 资源清单文件
1.deployment.yaml:apiVersion: apps/v1 kind: Deployment metadata:name: myapp-clusterip-deploynamespace: default spec:replicas: 3selector:matchLabels:app: myapprelease: stabelsvc: clusteriptemplate:metadata:labels: # 定义 pod 的标签app: myapprelease: stabelenv: testsvc: clusteripspec:containers:- name: myapp-containerimage: harbor.registry.com/library/myapp:1.0imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80readinessProbe: # 就绪探测httpGet:port: 80path: /index1.htmlinitialDelaySeconds: 1 # 延迟 1 秒开始探测periodSeconds: 3 # 每 3 秒探测一次该 Deployment 定义了 3 个副本的 Pod,每个 Pod 包含一个 myapp 容器,并配置了就绪探测,探测 80 端口的 index1.html 页面。
-
创建 Deployment 资源:
kubectl apply -f 1.deployment.yamlkubectl apply -f:根据资源清单文件创建资源。 -
查看 Pod 状态:
kubectl get pod此时 Pod 处于 Running 状态,但 READY 为 0/1,因为就绪探测失败(镜像中不存在 index1.html 文件)。
-
创建 Service 资源清单文件
2.svc.yaml:apiVersion: v1 kind: Service metadata:name: myapp-clusteripnamespace: default spec:type: ClusterIPselector:app: myapprelease: stabelsvc: clusteripports:- name: httpport: 80targetPort: 80该 Service 为 ClusterIP 类型,通过标签选择器关联具有
app: myapp、release: stabel、svc: clusterip标签的 Pod。 -
创建 Service 资源:
kubectl apply -f 2.svc.yaml -
查看 Service 信息:
kubectl get svc可以看到 myapp-clusterip 已创建,并分配了 ClusterIP。
-
尝试访问 Service 的 ClusterIP:
curl 10.3.124.142 # 替换为实际的 ClusterIP访问失败,因为 Pod 未通过就绪探测,Service 未关联任何 Pod。
-
进入其中一个 Pod,创建 index1.html 文件,使就绪探测通过:
kubectl exec -it myapp-clusterip-deploy-77c59649fb-6vzxx -- /bin/bashkubectl exec -it:交互式进入 Pod 中的容器。myapp-clusterip-deploy-77c59649fb-6vzxx:Pod 的名称。-- /bin/bash:在容器中执行 bash 命令。
在容器内部执行:
cd /usr/local/nginx/html/ date > index1.html exit -
再次查看 Pod 状态,确认该 Pod 已就绪(READY 为 1/1):
kubectl get pod -
再次访问 Service 的 ClusterIP:
curl 10.3.124.142 # 替换为实际的 ClusterIP此时可以访问成功,返回 nginx 页面内容。
-
查看访问的是哪个 Pod:
curl 10.3.124.142/hostname.html # 替换为实际的 ClusterIP返回 Pod 的名称。
-
按照步骤 10 的方法,使另外两个 Pod 也通过就绪探测。
-
多次访问 Service 的 ClusterIP,验证负载均衡:
curl 10.3.124.142/hostname.html curl 10.3.124.142/hostname.html curl 10.3.124.142/hostname.html可以看到请求被分发到不同的 Pod。
-
查看 ipvs 规则,确认已包含三个 Pod 的 IP:
ipvsadm -Ln
2.3.3 域名解析
Kubernetes 集群中的每个 Service 创建后,都会在 DNS 插件中注册一个域名,格式为:Service名称.所在名字空间.svc.cluster.local。集群内部的 Pod 可以通过该域名访问 Service。
实验目的:验证 Service 的域名解析功能。
实验步骤:
- 安装 bind-utils 工具包(包含 dig 等 DNS 工具):
dnf install bind-utils -y
-
该命令用于安装 DNS 解析工具,方便后续测试域名解析。
-
查看 Service 名称:
kubectl get svc确认 myapp-clusterip 服务的名称及所在命名空间(默认是 default)。
-
查看 DNS 插件的 IP:
kubectl get pod -n kube-system -o wide | grep dns输出结果中包含 coredns 插件的 Pod 及对应的 IP 地址(如 10.244.85.208、10.244.85.210),这些是集群内部的 DNS 服务器地址。
-
解析 Service 域名:
dig -t A myapp-clusterip.default.svc.cluster.local @10.0.0.10-t A:指定查询 A 记录(IP 地址)。myapp-clusterip.default.svc.cluster.local:Service 的完整域名,格式为 “Service 名称。命名空间.svc.cluster.local”。@10.0.0.10:指定 DNS 服务器地址(集群 DNS 服务的虚拟 IP)。
解析结果中,ANSWER 部分会显示该域名对应的 ClusterIP(如 10.3.124.142),说明域名解析成功。
-
在 Pod 内部验证域名访问:
创建一个用于测试的 Pod 资源清单3.dnstest.yaml:apiVersion: v1 kind: Pod metadata:name: pod-demonamespace: defaultlabels:app: myapp spec:containers:- name: busybox-1image: harbor.registry.com/library/busybox:1.0command: ["/bin/sh", "-c", "sleep 3600"]该 Pod 运行一个 busybox 容器,主要用于测试集群内部的网络访问。
创建 Pod:
kubectl create -f 3.dnstest.yaml进入 Pod 内部,通过域名访问 Service:
kubectl exec -it pod-demo -- /bin/sh / # wget http://myapp-clusterip.default.svc.cluster.local/hostname.html && cat hostname.html && rm -rf hostname.html输出结果会显示访问到的 Pod 名称,说明在 Pod 内部可通过域名访问 Service,且实现了负载均衡。
2.3.4 internalTrafficPolicy
internalTrafficPolicy 用于定义节点如何分发通过 ClusterIP 接收的服务流量,有以下两种取值:
- Cluster(默认):将流量路由到所有端点(跨节点的 Pod)。
- Local:仅将流量路由到与客户端 Pod 同一节点上的端点,若没有本地端点则丢弃流量。
实验目的:对比 Cluster 和 Local 模式的区别。
实验步骤:
-
查看当前 Service 的
internalTrafficPolicy配置:kubectl get svc myapp-clusterip -o yaml | grep internalTrafficPolicy默认值为
Cluster。 -
在 Cluster 模式下测试访问:
- 通过 ClusterIP 访问:
curl 10.3.124.142(成功)。 - 在 Pod 内部通过域名访问:
wget http://myapp-clusterip.default.svc.cluster.local(成功)。
- 通过 ClusterIP 访问:
-
修改为 Local 模式:
kubectl edit svc myapp-clusterip在编辑页面中将
internalTrafficPolicy: Cluster改为internalTrafficPolicy: Local,保存退出。 -
在 Local 模式下测试访问:
- 通过 ClusterIP 访问:
curl 10.3.124.142(失败,连接被拒绝)。 - 在 Pod 内部通过域名访问:
wget http://myapp-clusterip.default.svc.cluster.local(成功)。
结论:Local 模式仅允许集群内部的 Pod 通过域名访问,不允许通过 ClusterIP 直接访问,可减少跨节点流量,提高性能。
- 通过 ClusterIP 访问:
2.3.5 会话保持(IPVS 持久化连接)
通过配置 sessionAffinity 可实现会话保持,即同一客户端的请求在一段时间内定向到同一后端 Pod。sessionAffinity 有以下取值:
- None(默认):无会话保持,请求按负载均衡算法分发。
- ClientIP:基于客户端 IP 进行会话保持,默认超时时间为 3 小时(10800 秒)。
实验目的:验证 ClientIP 模式的会话保持功能。
实验步骤:
-
查看当前 Service 的
sessionAffinity配置:kubectl explain svc.spec.sessionAffinity默认值为
None。 -
在 None 模式下测试访问:
curl 10.3.124.142/hostname.html curl 10.3.124.142/hostname.html多次访问会负载到不同的 Pod。
-
修改为 ClientIP 模式:
kubectl edit svc myapp-clusterip在编辑页面中添加
sessionAffinity: ClientIP,保存退出。 -
查看持久化时间配置:
kubectl explain svc.spec.sessionAffinityConfig.clientIP默认超时时间为 10800 秒(3 小时),可通过
timeoutSeconds自定义(0 < 取值 ≤ 86400 秒)。 -
在 ClientIP 模式下测试访问:
curl 10.3.124.142/hostname.html curl 10.3.124.142/hostname.html多次访问会定向到同一 Pod,验证了会话保持功能。
-
查看 ipvs 规则:
ipvsadm -Ln规则中会显示
persistent 10800,表示开启了 3 小时的持久化连接。
2.4 NodePort
NodePort 类型在 ClusterIP 基础上,为 Service 在每个节点的物理网卡绑定一个端口(默认范围 30000-32767),可通过 <NodeIP>:NodePort 从集群外部访问服务。
2.4.1 模式结构
- 底层通过 Deployment 创建 Pod,关联一个 ClusterIP 类型的 Service。
- 再创建一个 NodePort 类型的 Service,匹配目标 Pod,并在每个节点绑定一个物理端口(如 30010)。
- 外部客户端通过任一节点的 IP 和 NodePort 访问服务,流量经节点的 IPVS 规则转发到后端 Pod。
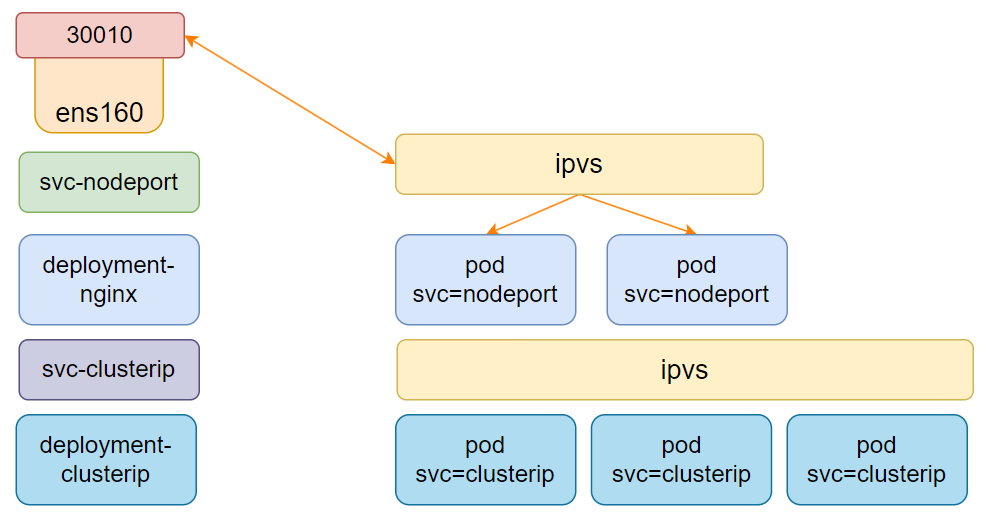
2.4.2 模式演示
实验目的:演示 NodePort 类型的 Service 如何暴露服务到集群外部。
实验步骤:
-
创建 Deployment 资源清单
5.deployment.yaml:apiVersion: apps/v1 kind: Deployment metadata:name: myapp-nodeport-deploynamespace: default spec:replicas: 3selector:matchLabels:app: myapprelease: stabelsvc: nodeporttemplate:metadata:labels:app: myapprelease: stabelenv: testsvc: nodeportspec:containers:- name: myapp-containerimage: harbor.registry.com/library/myapp:1.0imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80创建 3 个副本的 Pod,标签为
app: myapp、release: stabel、svc: nodeport。创建 Deployment:
kubectl apply -f 5.deployment.yaml -
创建 NodePort 类型的 Service 资源清单
6.nodeport.yaml:apiVersion: v1 kind: Service metadata:name: myapp-nodeportnamespace: default spec:type: NodePortselector:app: myapprelease: stabelsvc: nodeportports:- name: httpport: 80 # 集群内部访问端口targetPort: 80 # 后端 Pod 端口nodePort: 30010 # 集群外部访问端口(需在默认范围)创建 Service:
kubectl apply -f 6.nodeport.yaml -
查看 Service 信息:
kubectl get svc myapp-nodeport输出中
PORT(S)列显示80:30010/TCP,表示集群内部通过 80 端口访问,外部通过 30010 端口访问。 -
集群内部访问测试:
curl 10.1.69.228:80/hostname.html # 替换为实际的 ClusterIP成功访问并实现负载均衡。
-
集群外部访问测试:
在集群外部的机器上,通过节点 IP 和 NodePort 访问:curl 192.168.10.11:30010/hostname.html # 替换为实际的节点 IP curl 192.168.10.12:30010/hostname.html所有节点的 30010 端口均可访问,验证了 NodePort 暴露服务的功能。
2.4.3 externalTrafficPolicy
externalTrafficPolicy 用于定义节点如何分发通过 NodePort、ExternalIPs 或 LoadBalancer IP 接收的外部流量,取值如下:
- Cluster(默认):将流量路由到所有端点(跨节点的 Pod)。
- Local:仅将流量路由到接收流量的节点上的本地端点,保留客户端源 IP,若没有本地端点则丢弃流量。
实验目的:验证 Local 模式对外部访问的限制。
实验步骤:
-
修改 NodePort 服务的
externalTrafficPolicy为 Local:kubectl edit svc myapp-nodeport在编辑页面中添加
externalTrafficPolicy: Local,保存退出。 -
集群内部节点访问测试:
curl 192.168.10.11:30010 # 节点自身 IP 访问,成功 -
集群外部机器访问测试:
curl 192.168.10.11:30010 # 失败,无法访问结论:Local 模式仅允许集群节点通过物理 IP:NodePort 访问,外部机器无法访问,适用于需要限制外部访问来源的场景。
2.5 LoadBalancer
LoadBalancer 类型在 NodePort 基础上,借助云服务提供商(如阿里云、AWS)的负载均衡服务,自动创建外部负载均衡器,将流量转发到节点的 NodePort。该类型仅在云环境中可用,解决了 NodePort 模式下外部访问的高可用问题(避免单节点故障导致服务不可用)。
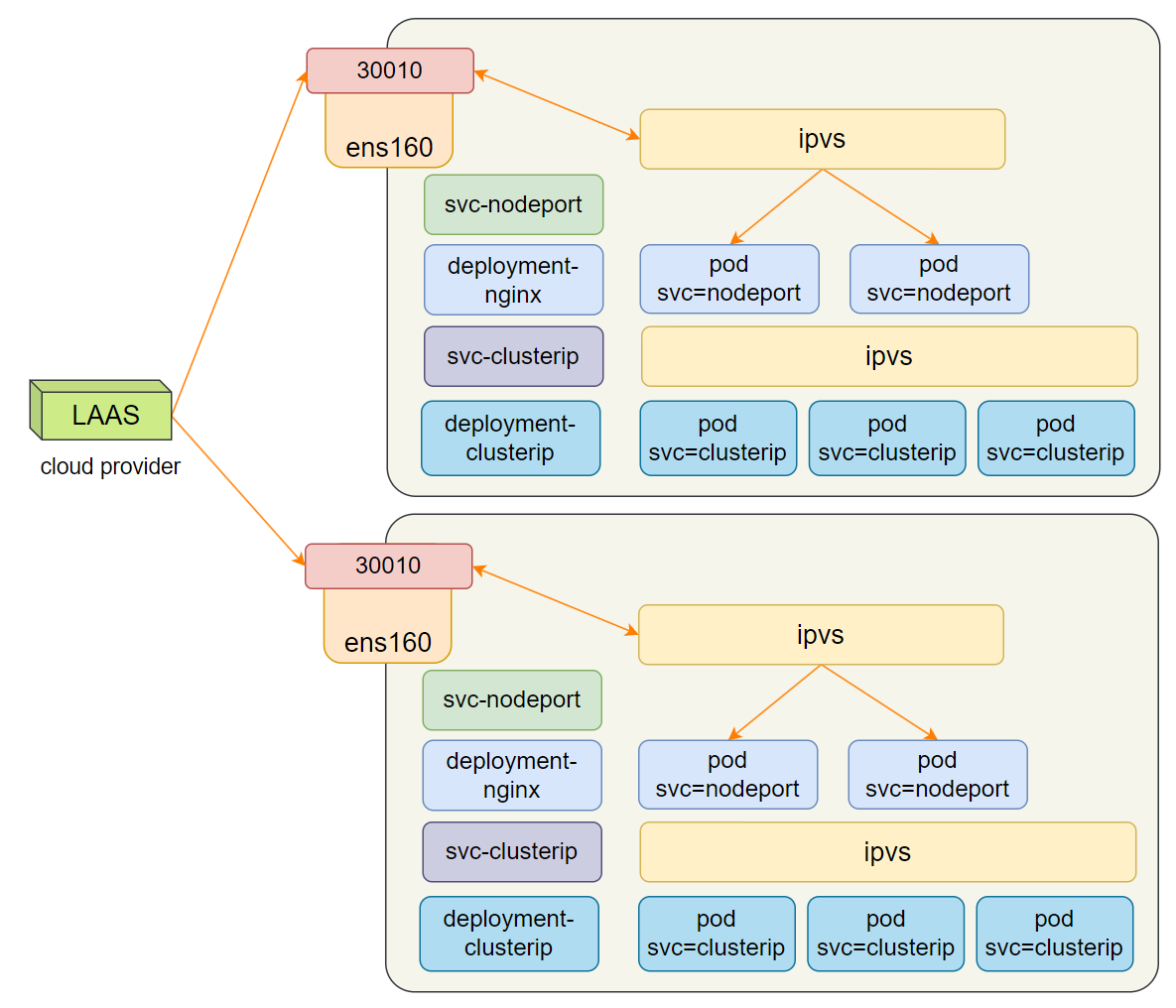
资源清单示例(阿里云):
apiVersion: v1
kind: Service
metadata:annotations:service.beta.kubernetes.io/alibaba-cloud-loadbalancer-id: ${YOUR_LB_ID}service.beta.kubernetes.io/alicloud-loadbalancer-force-override-listeners: 'true'labels:app: nginxname: my-nginx-svcnamespace: default
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: nginxtype: LoadBalancer
annotations:云厂商特定的负载均衡器配置(如负载均衡器 ID)。- 云厂商会自动将负载均衡器的流量转发到集群节点的 NodePort,实现外部访问的高可用。
2.6 ExternalName
ExternalName 类型用于将集群外部的服务引入集群内部,通过 DNS 别名实现,无需选择器或端口配置。适用于访问集群外部的固定服务(如外部数据库)。
2.6.1 模式结构
- 无底层 IPVS 参与,仅通过 CoreDNS 实现域名别名映射。
- 集群内部的 Pod 通过 Service 域名访问,CoreDNS 将其解析为外部服务的域名,再由客户端解析外部域名获取 IP。
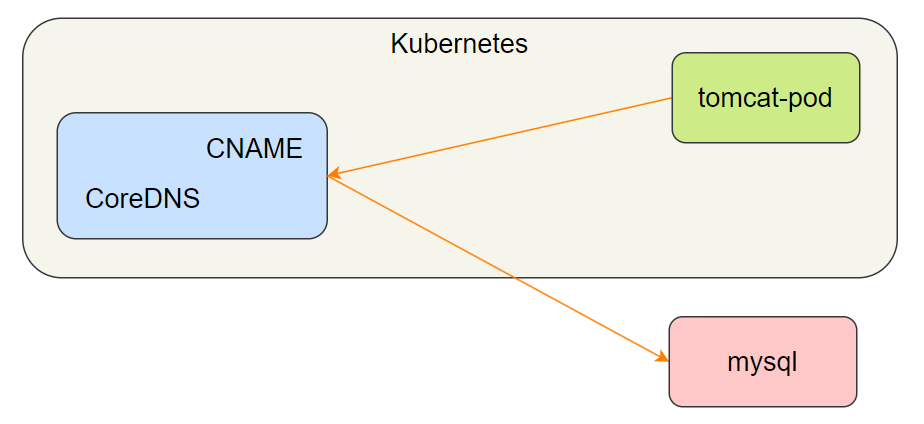
2.6.2 模式演示
实验目的:将外部服务(如 www.baidu.com)通过 ExternalName 引入集群内部。
实验步骤:
-
创建 ExternalName 类型的 Service 资源清单
7.ensvc.yaml:apiVersion: v1 kind: Service metadata:name: my-service-1namespace: default spec:type: ExternalNameexternalName: www.baidu.comexternalName: www.baidu.com:指定外部服务的域名。
创建 Service:
kubectl apply -f 7.ensvc.yaml -
查看 Service 信息:
kubectl get svc my-service-1输出中
EXTERNAL-IP列为www.baidu.com,无 ClusterIP。 -
在 Pod 内部验证访问:
kubectl exec -it pod-demo -- /bin/sh / # ping my-service-1.default.svc.cluster.local解析结果为百度的 IP(如 183.240.99.58),说明成功通过别名访问外部服务。
2.6.3 实用案例:访问外部 MySQL
创建一个关联外部 MySQL 的 ExternalName 服务:
-
资源清单
8.mysql-external-svc.yaml:apiVersion: v1 kind: Service metadata:name: mysql-servicenamespace: default spec:type: ExternalNameexternalName: mysql.prod.company.comports:- name: mysqlport: 3306targetPort: 3306- 关联外部 MySQL 服务
mysql.prod.company.com:3306。
- 关联外部 MySQL 服务
-
应用程序配置中通过 Service 域名访问:
spring.datasource.url=jdbc:mysql://mysql-service:3306/dbname当外部 MySQL 地址变更时,只需修改
externalName即可,无需修改所有应用配置。
3. Endpoints
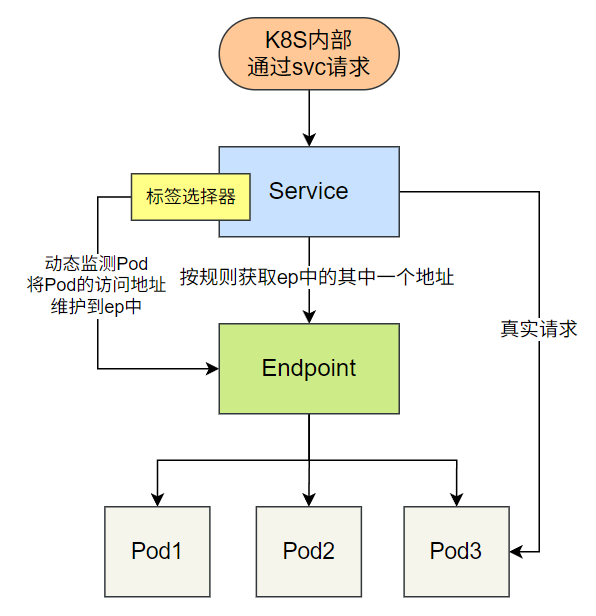
Endpoints 是 Service 的底层模型,记录了 Service 关联的后端端点(Pod IP 和端口)。Service 通过 Label Selector 自动关联 Pod 并生成同名 Endpoints,也可手动创建 Endpoints 关联外部服务。
3.1 关联关系
- Service:定义逻辑分组和访问策略,通过 Label Selector 匹配 Pod。
- Endpoints:存储实际的服务端点(IP:Port),与 Service 同名,由 Service 自动创建或手动定义。
- Pod:后端服务的实际运行单元,需满足标签匹配和就绪状态才会被加入 Endpoints。
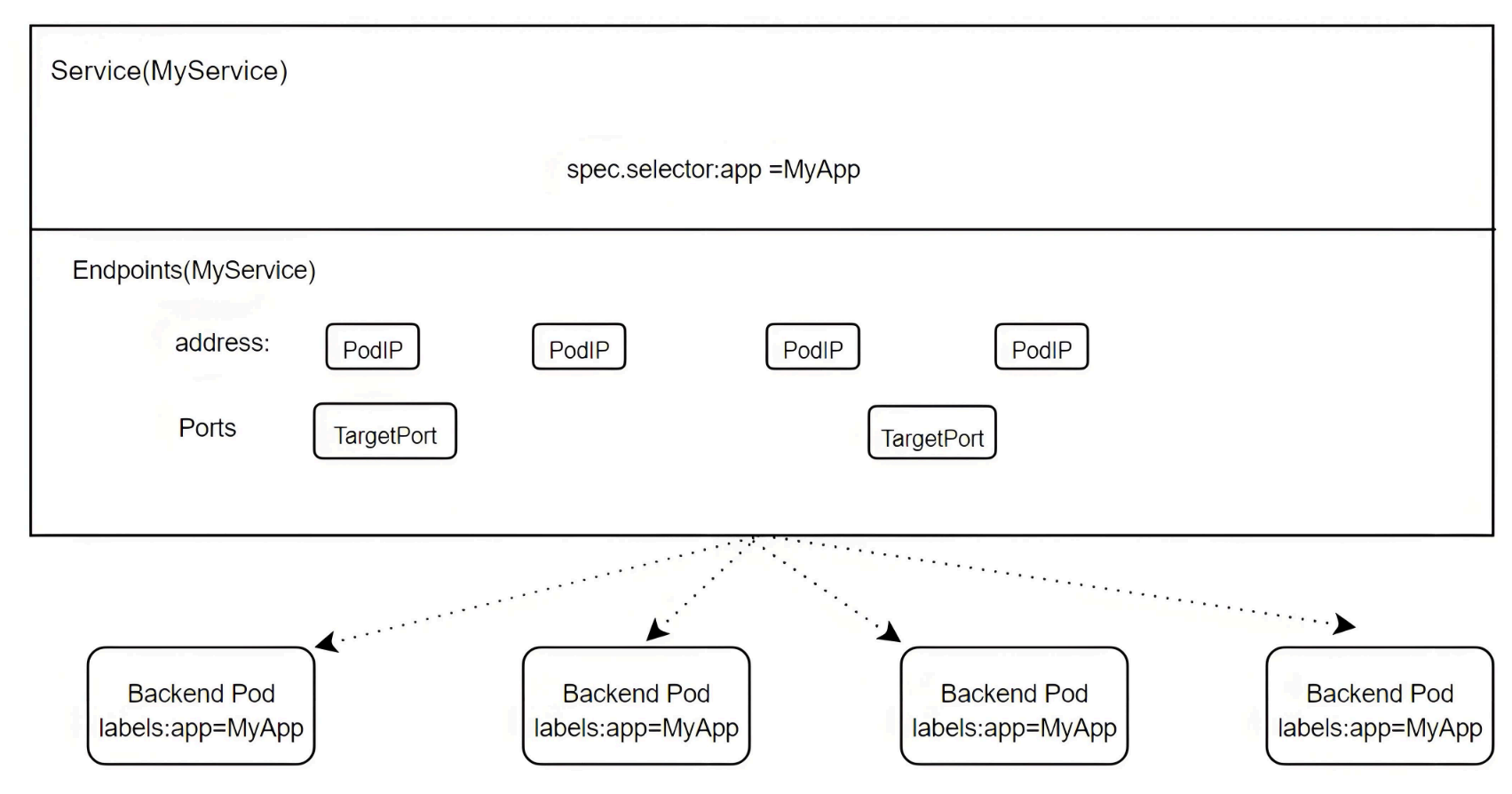
3.2 自动关联(配置 Selector)
当 Service 配置 Label Selector 时,会自动监测符合条件的 Pod,将其 IP 和端口添加到同名 Endpoints 中,kube-proxy 再将 Endpoints 同步到 IPVS 规则。
实验验证:
- 创建带就绪探测的 Deployment 和匹配的 Service(参考 6.2.3.2 步骤)。
- 查看 Endpoints:
bash
kubectl get endpoints myapp-clusterip
当 Pod 就绪后,Endpoints 会显示 Pod 的 IP:Port(如10.244.58.193:80)。
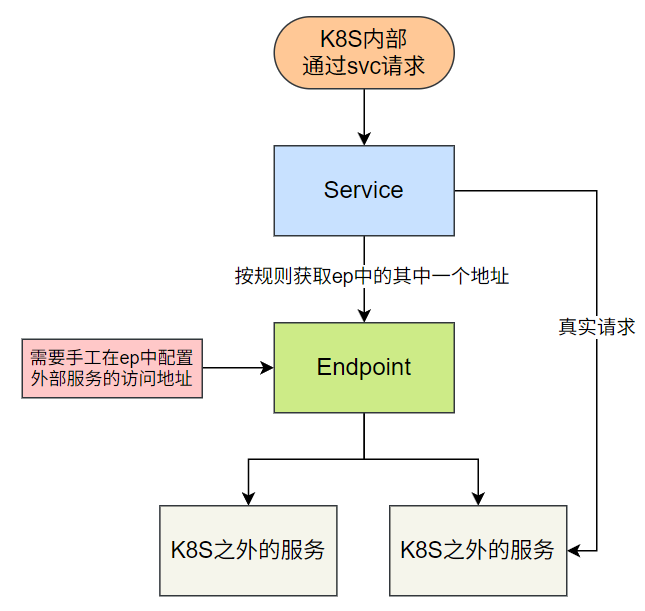
3.3 手动关联(无 Selector)
若 Service 未配置 Selector,需手动创建同名 Endpoints 定义后端端点(可关联集群外部服务)。
实验目的:手动关联外部 Nginx 服务。
实验步骤:
- 创建无 Selector 的 Service 资源清单
8.svc.yaml:
apiVersion: v1
kind: Service
metadata:name: nginx-noselects
spec:ports:- protocol: TCPport: 6666 # Service 暴露端口targetPort: 80 # 后端服务端口
创建 Service:
kubectl create -f 8.svc.yaml
- 该 Service 未配置
selector,因此不会自动生成 Endpoints。
-
查看 Service 和 Endpoints:
kubectl get svc nginx-noselects # 确认 Service 已创建 kubectl get endpoints nginx-noselects # 无结果,未自动生成 -
手动创建 Endpoints 资源清单
9.ep.yaml:apiVersion: v1 kind: Endpoints metadata:name: nginx-noselects # 必须与 Service 同名 subsets: - addresses:- ip: 192.168.10.12 # 外部服务 IP(如节点 node01 的 IP)ports:- port: 80 # 外部服务端口创建 Endpoints:
kubectl create -f 9.ep.yaml -
在节点
192.168.10.12上启动 Nginx 服务:docker run --name nginx -d -p 80:80 harbor.registry.com/library/myapp:1.0 -
访问 Service 验证:
curl 10.9.126.145:6666 # 替换为 Service 的 ClusterIP成功返回 Nginx 页面,说明手动关联的外部服务可通过 Service 访问。
4. publishNotReadyAddresses
默认情况下,Service 仅关联就绪状态且标签匹配的 Pod。若需将未就绪的 Pod 也纳入负载均衡(如特殊调试场景),可开启 publishNotReadyAddresses: true。
实验目的:验证未就绪 Pod 能否被 Service 关联。
实验步骤:
-
创建带就绪探测的 Pod 资源清单
10.pod.yaml:apiVersion: v1 kind: Pod metadata:name: readiness-httpget-podnamespace: defaultlabels:app: myappenv: test spec:containers:- name: readiness-httpget-containerimage: harbor.registry.com/library/myapp:1.0readinessProbe:httpGet:port: 80path: /index1.html # 镜像中无此文件,就绪探测失败initialDelaySeconds: 1periodSeconds: 3创建 Pod:
kubectl create -f 10.pod.yaml -
查看 Pod 状态:
kubectl get pod readiness-httpget-pod # 状态为 Running,但 READY 0/1 -
创建匹配的 Service:
kubectl create svc clusterip myapp --tcp=80:80 -
访问 Service(失败,因 Pod 未就绪):
curl 10.14.121.157 # 替换为 Service 的 ClusterIP,连接被拒绝 -
开启
publishNotReadyAddresses:kubectl patch service myapp -p '{"spec": {"publishNotReadyAddresses": true}}' -
再次访问 Service(成功,未就绪 Pod 被关联):
curl 10.14.121.157 # 返回 Nginx 页面
5. 排错指南
-
Service 无法访问后端 Pod
- 检查 Pod 标签是否与 Service 的
selector匹配:kubectl get pod --show-labels对比kubectl get svc <name> -o yaml | grep selector。 - 检查 Pod 是否就绪:
kubectl get pod确保 READY 1/1,就绪探测是否通过。 - 检查网络策略是否阻止流量:
kubectl get networkpolicy。
- 检查 Pod 标签是否与 Service 的
-
NodePort 外部无法访问
- 检查 NodePort 是否在默认范围(30000-32767):
kubectl get svc <name>。 - 检查节点防火墙是否开放 NodePort:
firewall-cmd --list-ports(如 30010/tcp)。 - 检查
externalTrafficPolicy是否为 Local 导致外部访问被拒:修改为 Cluster 重试。
- 检查 NodePort 是否在默认范围(30000-32767):
-
域名解析失败
- 检查 Service 域名格式是否正确:
Service名称.命名空间.svc.cluster.local。 - 检查 CoreDNS 插件是否正常运行:
kubectl get pod -n kube-system | grep coredns。 - 在 Pod 内部执行
nslookup <域名>排查 DNS 配置。
- 检查 Service 域名格式是否正确:
-
ipvs 规则未生成
- 检查 kube-proxy 模式是否为 ipvs:
kubectl get configmap kube-proxy -n kube-system -o yaml | grep mode。 - 重启 kube-proxy 使配置生效:
kubectl delete pod -n kube-system -l k8s-app=kube-proxy。
- 检查 kube-proxy 模式是否为 ipvs:
6. 总结
Kubernetes Service 是集群内部服务发现和负载均衡的核心组件,通过抽象 Pod 逻辑分组,提供稳定的访问入口。本文详细讲解了:
- 核心概念:Service 定义 Pod 逻辑分组及访问策略,解决 Pod IP 动态变化问题。
- 工作模式:
- ClusterIP:集群内部访问,提供虚拟 IP。
- NodePort:暴露服务到集群外部,绑定节点端口。
- LoadBalancer:云环境专用,结合外部负载均衡器。
- ExternalName:通过域名别名关联外部服务。
- 底层实现:kube-proxy 基于 userspace、iptables 或 ipvs 实现负载均衡,ipvs 性能更优。
- Endpoints:记录后端端点,支持自动或手动关联,是 Service 与 Pod 关联的桥梁。
- 高级配置:会话保持、流量策略、未就绪地址暴露等功能,满足复杂场景需求。
掌握 Service 的使用和原理,能有效提升 Kubernetes 集群中服务的可用性和可维护性。
7. 思考与答案
思考:在生产环境中,如何选择 Service 类型?
答案:
- 仅集群内部访问:优先选择 ClusterIP,性能最优且资源开销小。
- 需要外部访问且无云环境:使用 NodePort,配合外部负载均衡器(如 Nginx、F5)实现高可用。
- 云环境外部访问:使用 LoadBalancer,利用云厂商的负载均衡服务,简化高可用配置。
- 访问集群外部服务:使用 ExternalName,通过域名别名解耦,避免直接依赖外部 IP。
根据实际场景选择合适的类型,平衡可用性、性能和维护成本。