推荐系统学习笔记(六)自监督学习
目录
为什么要做自监督学习❓
复习一下
自监督学习
目标
特征变换
1.random mask
2.dropout
3.互补特征 complementary
4. mask一组关联特征
如何用变换后的特征训练模型✍️
自监督学习用在双塔模型上会提高业务指标⬆️
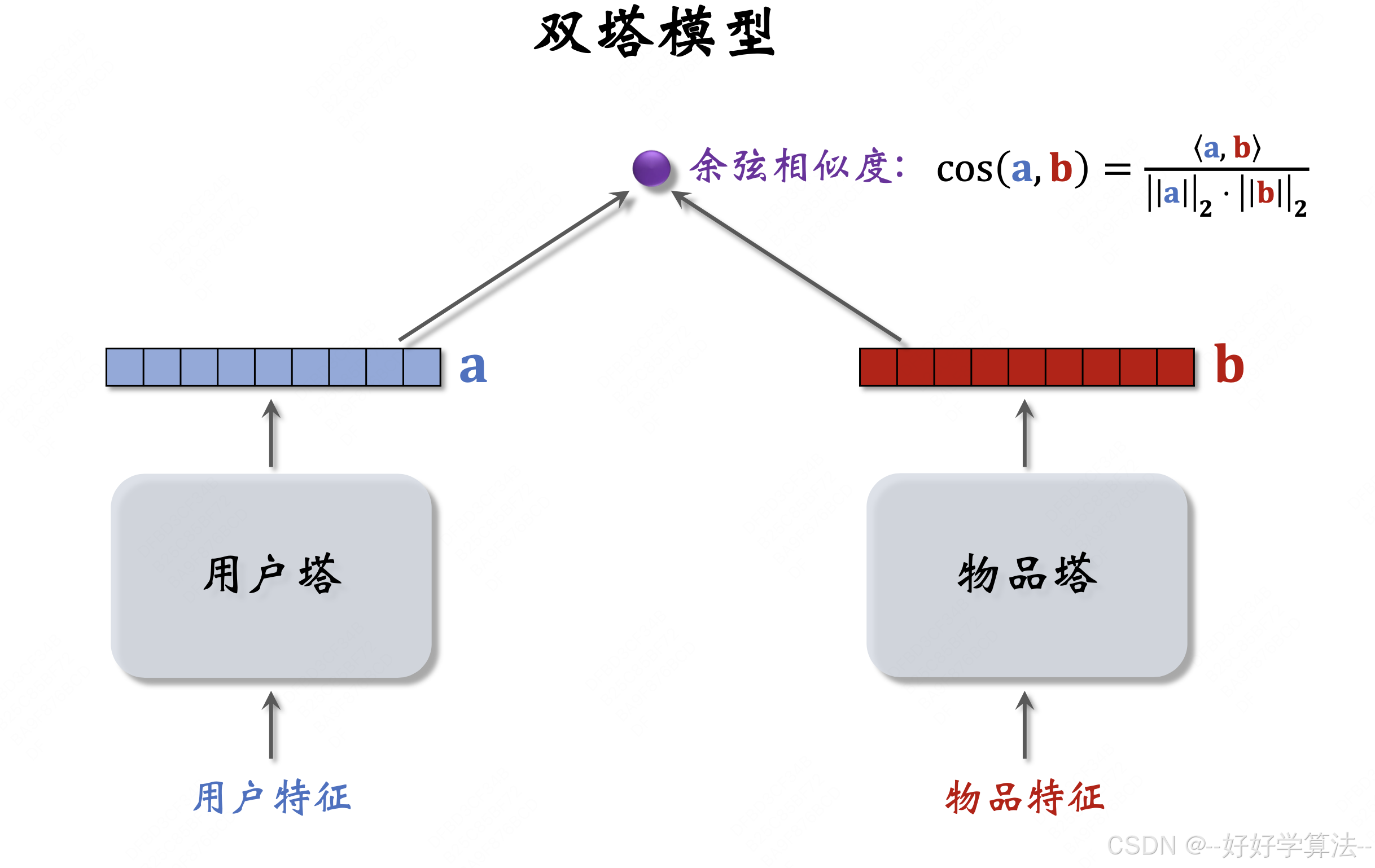
自监督学习的目的:把物品塔训练的更好
为什么要做自监督学习❓
1. 推荐系统头部效应严重:少部分物品占据大部分的点击
2. 高点击物品表征学的好,长尾物品表征学的不好
自监督学习,做data augmentation,更好地学习长尾物品表征
复习一下
batch内负样本,采用listwise训练,损失函数为:
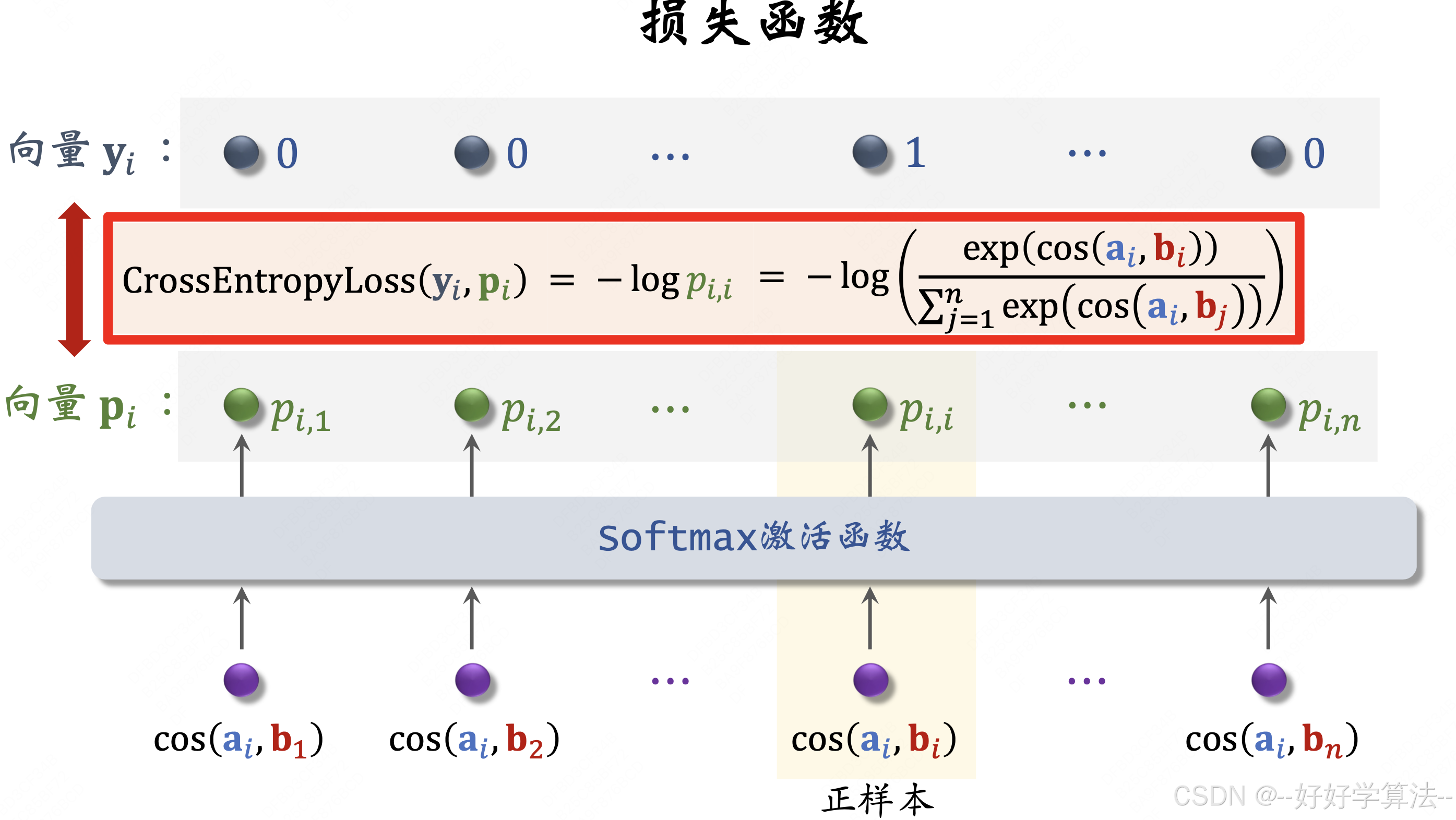
💡用batch内负样本需要纠偏:
做训练时把cos(ai,bj) 替换成 cos(ai,bj) - logpi,热门物品不至于被过分打压。
线上召回还采用cos(ai,bj)。
自监督学习
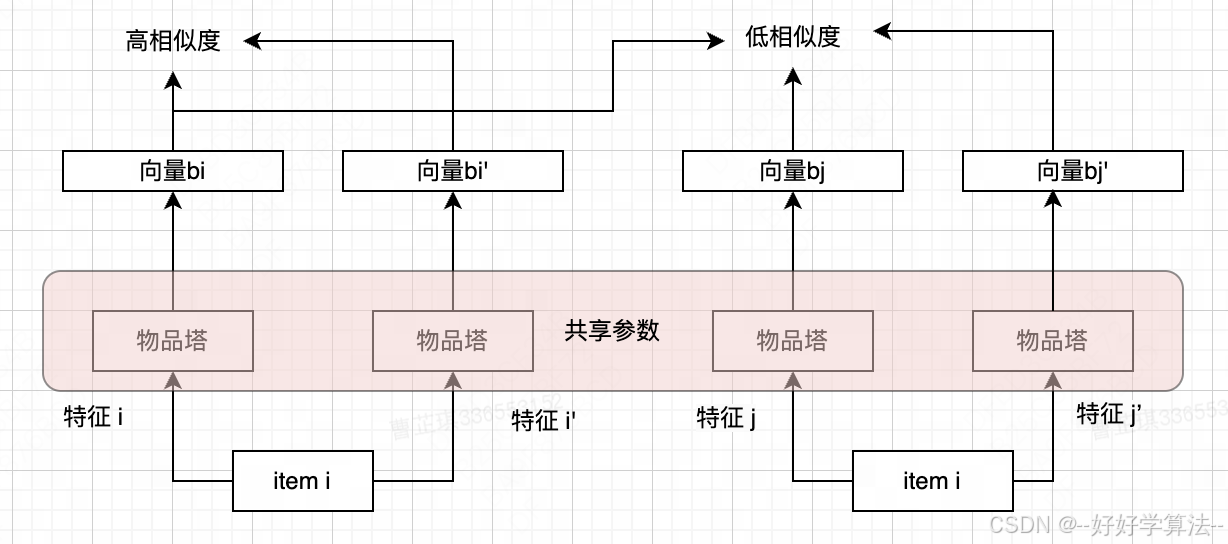
目标
- 物品i的两个向量表征bi和bi'有较高相似度 ➡️ cos(bi,bi')尽量大
- 不同物品i和j的向量表征bi和bj、bj'有较低相似度 ➡️ cos(bi,bj)和 cos(bi,bj') 尽量小
特征变换
1.random mask
随机选择一些离线特征(比如类目), 把它们“遮住”
例如:
item的类目特征 u = {数码,摄影},如果不mask就是对'数码"和"摄影"做embedding
mask后 u' = {default} (默认的缺失值),mask后对default做embedding
2.dropout
仅对多值离散特征生效(一个物品可以有多个类目,所以类目是一个多值离散特征)
dropout:随机丢弃特征中50%的值
例如:
item的类目特征 u = {数码,摄影},dropout之后 u' = {数码}
区别:mask是整个u的特征全部丢掉,dropout是u保留一半
3.互补特征 complementary
例如:
假设物品一共4种特征:ID、类目、关键词、城市
随机分两组:{ID,关键词}、{类目,城市}
{ID,关键词} ➡️ {ID,default,关键词,default} 向量bi
{类目,城市} ➡️ {default,类目,default,城市} 向量bj
训练时鼓励cos(bi,bj)尽量大
4. mask一组关联特征
较复杂。特征之间有较多关联,遮住一个并不会损失太多信息。模型可以从其他强关联的特征中学习到mask掉的特征。
例如:
受众性别 u ={男性,女性,中性},类目 v={美妆,数码,摄影,科技,……}
u=女性 和 v=美妆 同时出现的概率 p(u,v) 较大
u=男性 和 v=美妆 同时出现的概率 p(u,v) 较小
离线计算特征两两之间的关联,互信息衡量:
关联越强,p(u,v) 越大,MI 越大
操作流程:
- k个特征,离线计算两两之间的MI,得到k*k的矩阵
- 随机选一个特征作为种子,找到种子最相关的 k/2 种特征
- mask掉种子及其相关的 k/2 种特征,保留其余的 k/2 种特征
好处:实验效果好
坏处:复杂,实现难度大,且不容易维护,新加一个特征就得重算一遍MI
如何用变换后的特征训练模型✍️
- 从全体物品中均匀抽样,得到m个物品(与双塔区别:双塔根据点击行为抽,热门抽中概率大)
- 做两类特征变换,输出两组向量:(b1,b2,……,bm)和 (b1‘,b2’,……,bm‘)
- 第i个物品的损失函数为:
- 做梯度下降,减小损失: