数字ic后端设计从入门到精通13(含fusion compiler, tcl教学)全定制版图设计
基本CMOS工艺流程
1)整个CMOS工艺从一个P型衬底开始,它的表面是一层轻掺杂的P型外延层
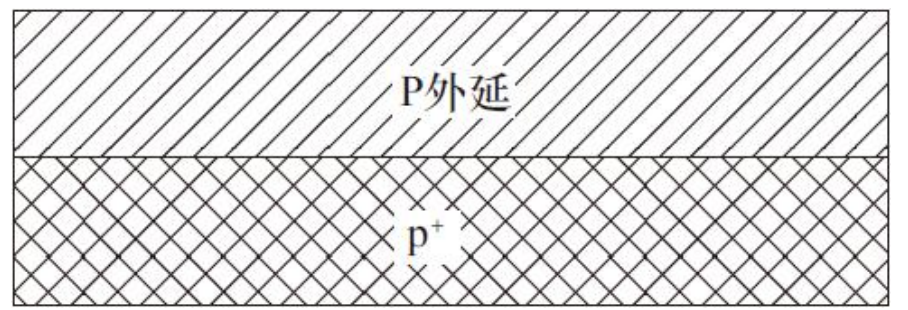
2)之后淀积一层很薄的二氧化硅(SiO2),以后它将成为晶体管的栅氧层,然后再淀积上一层较厚的氮化硅牺牲层,淀积栅氧和氮化硅牺牲层(作为缓冲层)
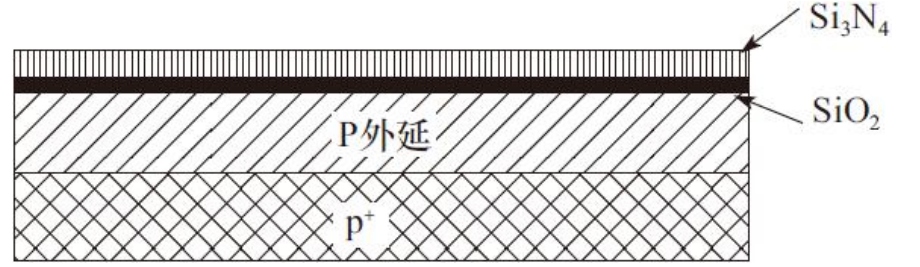
3)接着利用有源区掩膜的互补区域进行等离子刻蚀,以形成隔离器件的沟槽
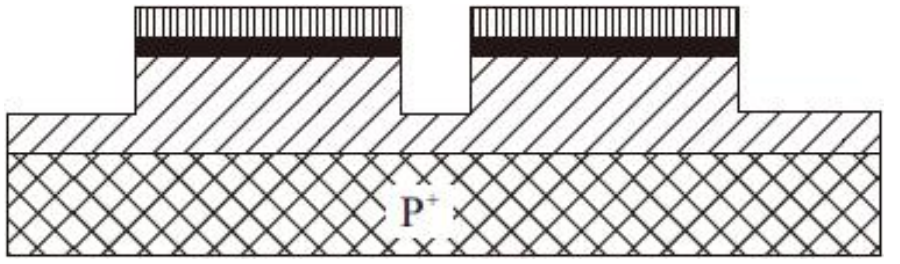
4)在完成沟道阻挡注入后,沟槽内填满二氧化硅,接着进行一系列的抛光工序来平整表面(包括与有源区图形相反区域的氧化物以及化学机械抛光)。这时,氮化硅牺牲层就被移去了
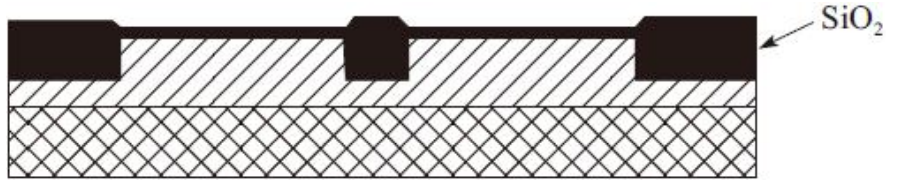
5)用N阱掩膜只曝光N阱区域(圆片的其余部分被一层厚缓冲材料所覆盖),之后进行注入-退火工序调整阱的掺杂。接着是第二次注入步骤以调整PMOS管的阈值电压。这次注入只对栅氧层下面的区域的掺杂产生影响
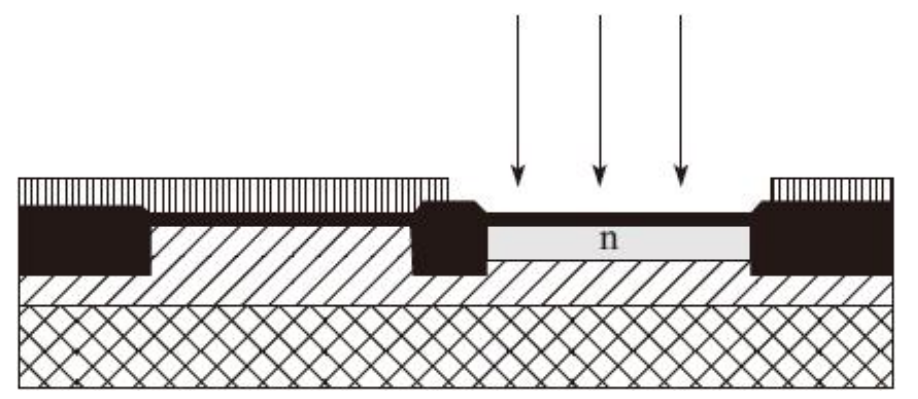
6)采用类似的操作(用其他掺杂剂)来形成P阱并调整NMOS管的阈值
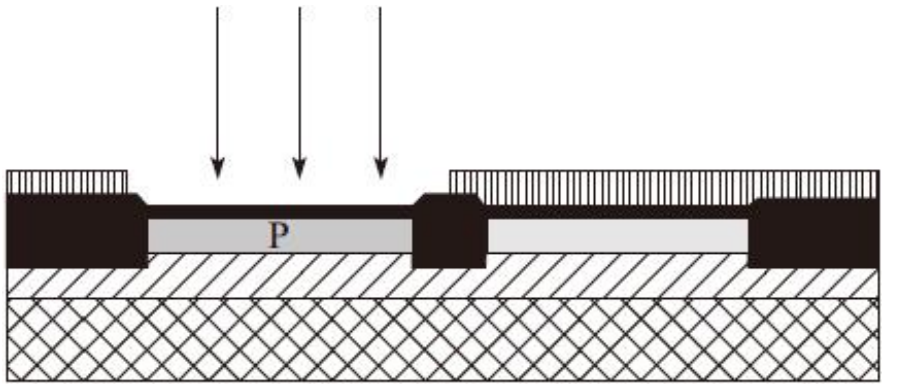
7)借助多晶硅掩膜的帮助将多晶硅薄层进行化学淀积并形成图形。多晶硅用于晶体管的栅电极和互连材料
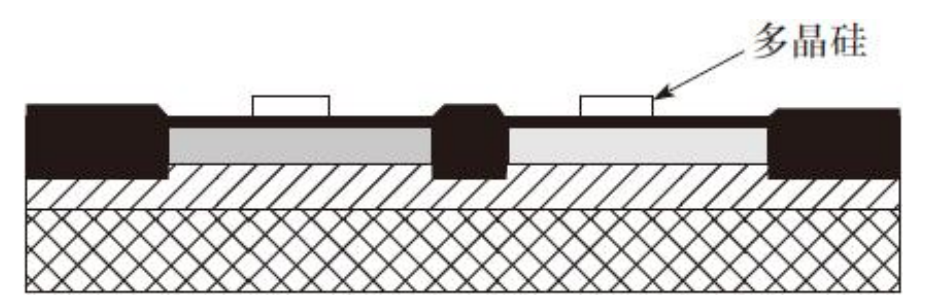
8)依次用离子注入分别注入PMOS和NMOS晶体管的源区和漏区(P+和N+),对源漏区进行掺杂
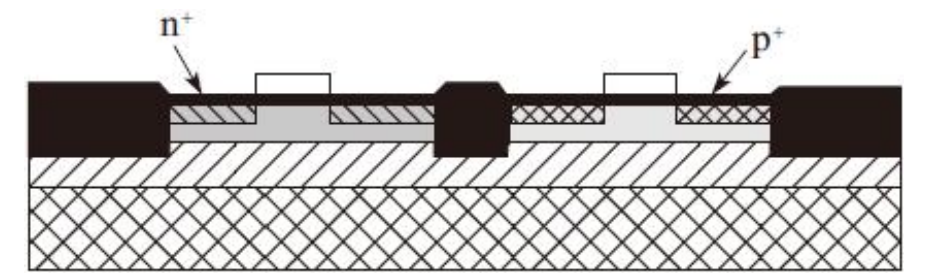
在此之后,刻蚀掉未被多晶硅覆盖的栅氧薄层。同样,注入用来对多晶硅表面进行掺杂以减小它的电阻率,因为未掺杂多晶硅的栅氧薄层具有非常高的电阻率。接下来的工艺步骤是淀积多层金属互连层,包括下列重复进行的步骤(9~11)。
9)淀积绝缘材料(多为二氧化硅)刻蚀接触孔和通孔
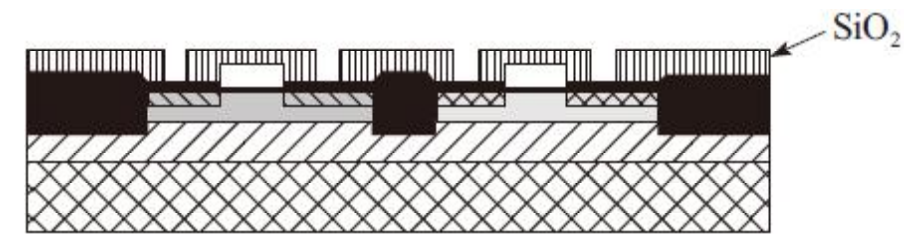
10)淀积金属(多为铝Al和铜Cu,但是在较低的互连层中也常使用钨W)以及形成的金属层图形。这中间的平面化步骤采用化学机械抛光以保证即便存在多个互连层时,表面仍保持适度的平整
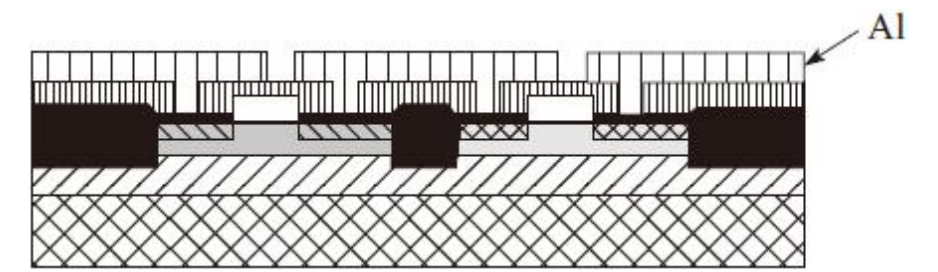
11)在最后一层金属淀积后,最终要淀积一层钝化层即覆盖玻璃加以保护。该层一般是二氧化硅,但常常还要再淀积一层氮化物,因为氮化物的防潮性能更好
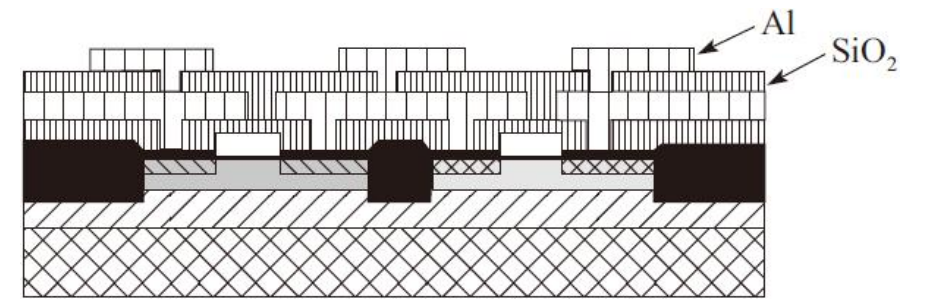
基本版图层
版图设计中的层是指将当前在CMOS中使用的一组难以理解的掩膜转化成一组简单的、概念化的版图层,它们对版图设计者来说更为直观。
所有的MOS管设计都包括下列的基本版图层。
1)衬底(P substrate)和阱,它们有P型(P WELL)和N型的(N WELL)。
2)扩散区(Nimp和Pimp),它们定义了可以形成晶体管的区域,这些区域通常称为有源区。
3)多晶硅层(Polysilion),用来形成晶体管的栅电极。
4)多个金属互连层(metal)。
5)接触孔(butting contact)和通孔(via),提供层与层之间的连接。
一个版图是多个多边形图形的组合,每个多边形可以属于不同的工艺层。电路的功能取决于所选择的工艺层以及不同工艺层上图形之间的相互作用。例如,一个MOS管是由扩散层和多晶硅层的重叠部分构成;两个金属层之间的互连是由两个金属层和一个接触孔层或者通孔层的重叠部分构成的。
NMOS/PMOS晶体管的版图实现
NMOS/PMOS晶体管是版图设计中最基础的元件,用NMOS/PMOS晶体管可以组成各种规模和功能不同的复杂器件。形成一个基本MOS晶体管所需要的基本工艺层叠加后得到的版图
漏区与源区的距离L称为沟道长度,漏区与源区的宽度W称为沟道宽度。它们的宽长比(W/L)是集成电路版图设计者考虑的最重要参数。
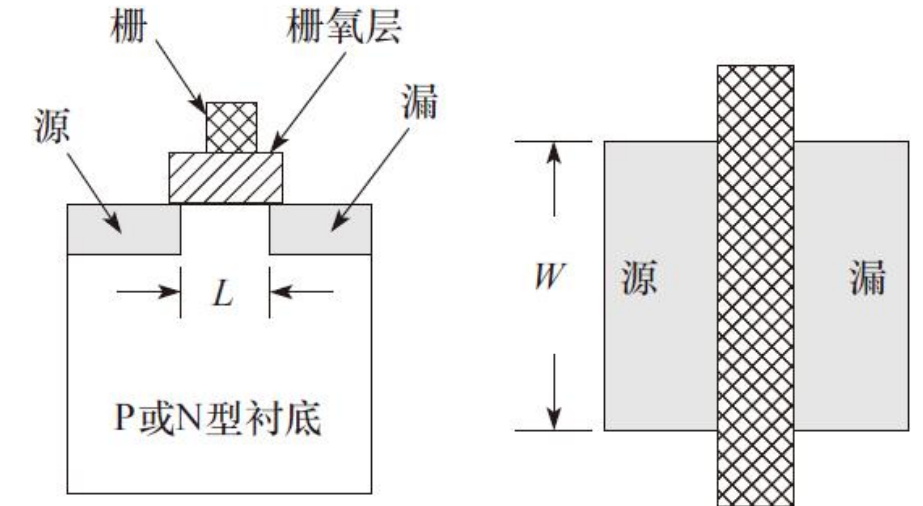
对NMOS晶体管和PMOS晶体管来说,两者的区别在于源区和漏区极性不一样
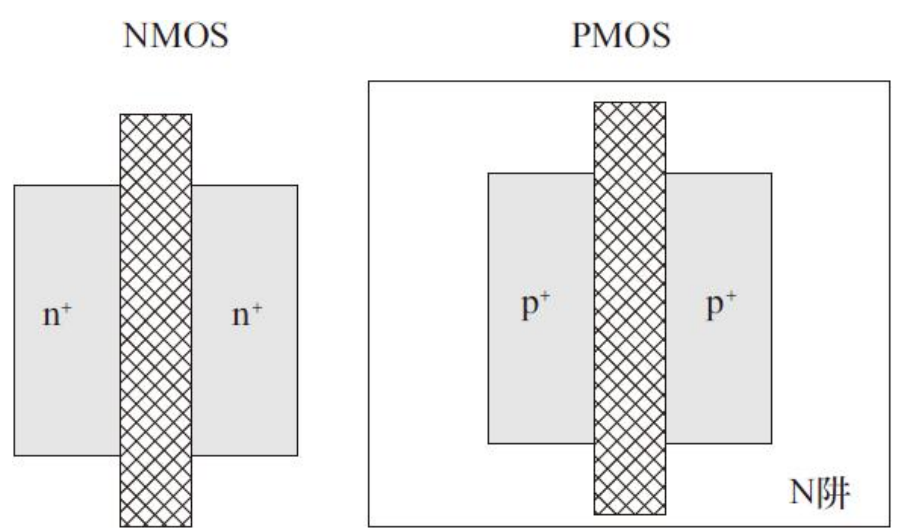
NMOS采用N型的漏区和源区,PMOS则具有P型的漏区和源区。NMOS可以直接在P型衬底形成,PMOS则需要增加N阱层,使其与P型衬底分隔开。
串联晶体管的版图实现
多个控制逻辑需要同时使能才能控制输出结果的电路结构,比如与逻辑AND,这样的电路结构需要在版图设计中实现晶体管串联,MOS晶体管串联组合如图
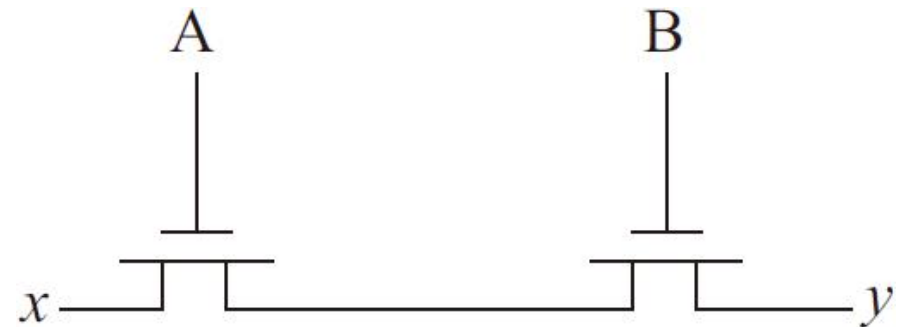
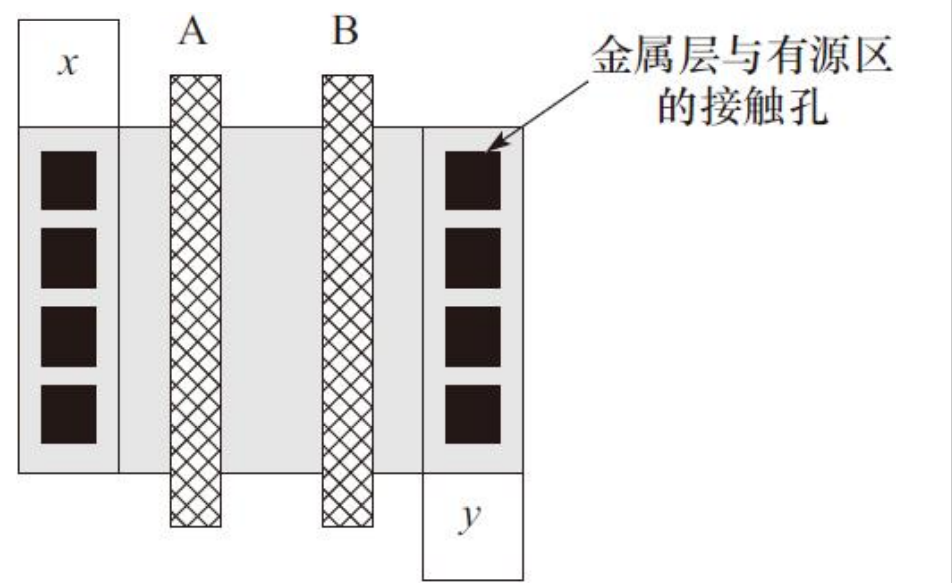
信号A和B分别加在两个MOS管的栅极上,并且只有两个信号同时有效时,MOS管才导通这样才能改变输出结果。在版图实现时,MOS器件可以共用图形区域,即两栅极间的有源区(N+和P+),这样可以节省版图面积和降低寄生电容。与门版图实现如图所示。
串联的总电阻是各个MOS管的电阻之和,所以串联的MOS管通常都是通过把宽度(W值)做得比单个MOS管更大来降低总电阻并提高驱动强度。
并联晶体管的版图实现
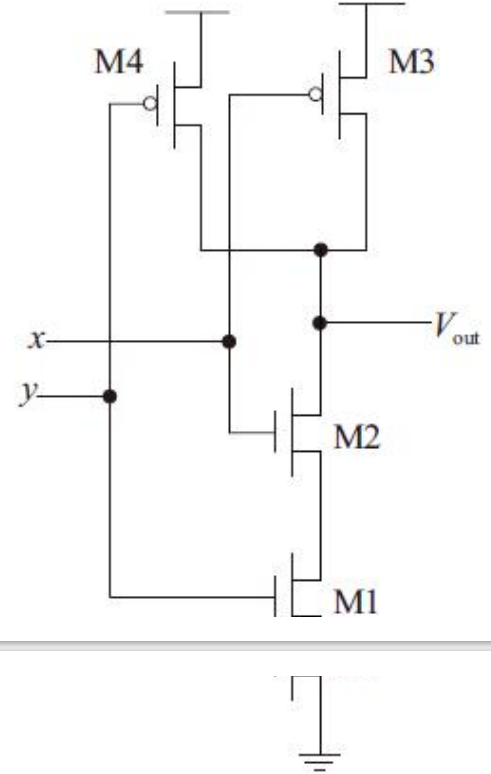
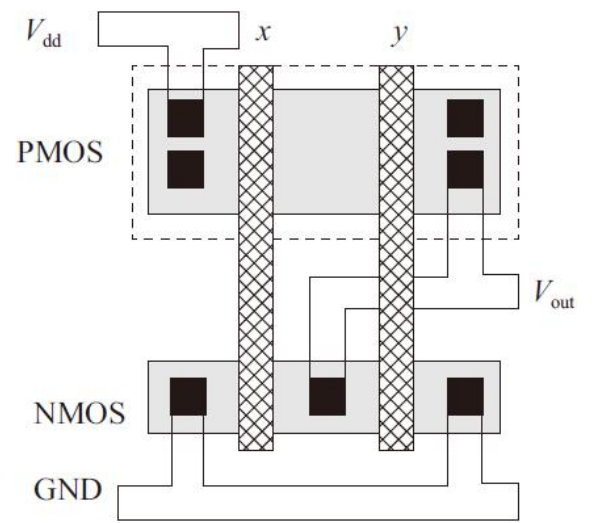
多个控制逻辑信号只需其中一个控制逻辑信号有效使能就可以控制输出结果的电路结构,比如或逻辑OR,这样的电路结构需要在版图设计中实现晶体管并联
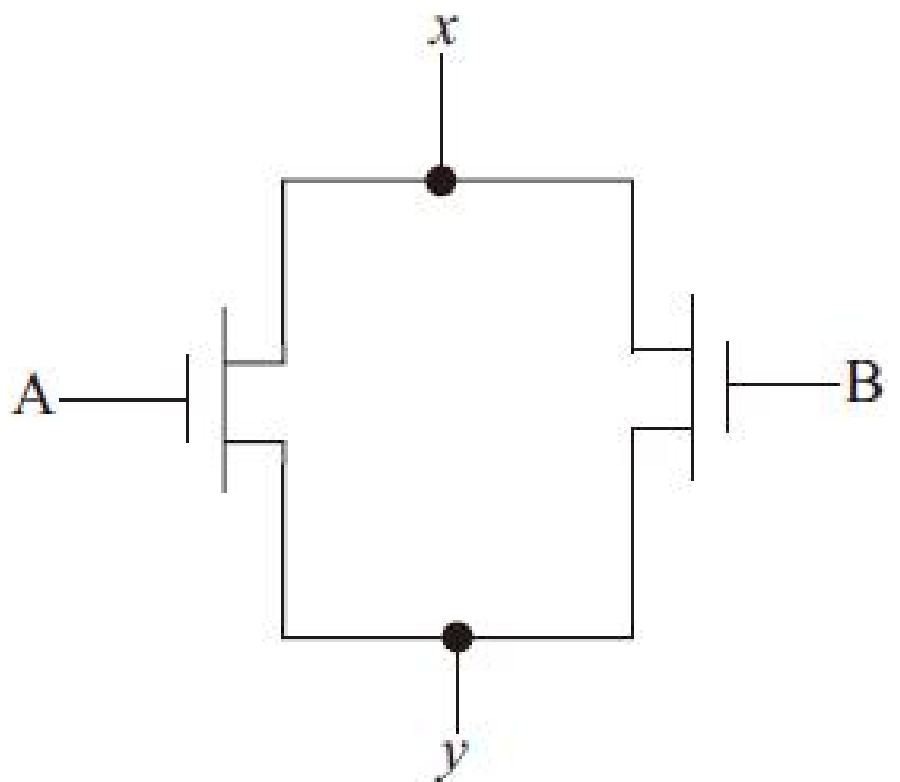
信号A和B分别加在两个MOS管的栅极上,但是只需要两个信号中任何一个信号有效就能改变输出结果。并联的MOS晶体管可以分别进行版图设计,再通过金属层将两个MOS管的漏/源区都连接到电路图所对应的节点x和y之间
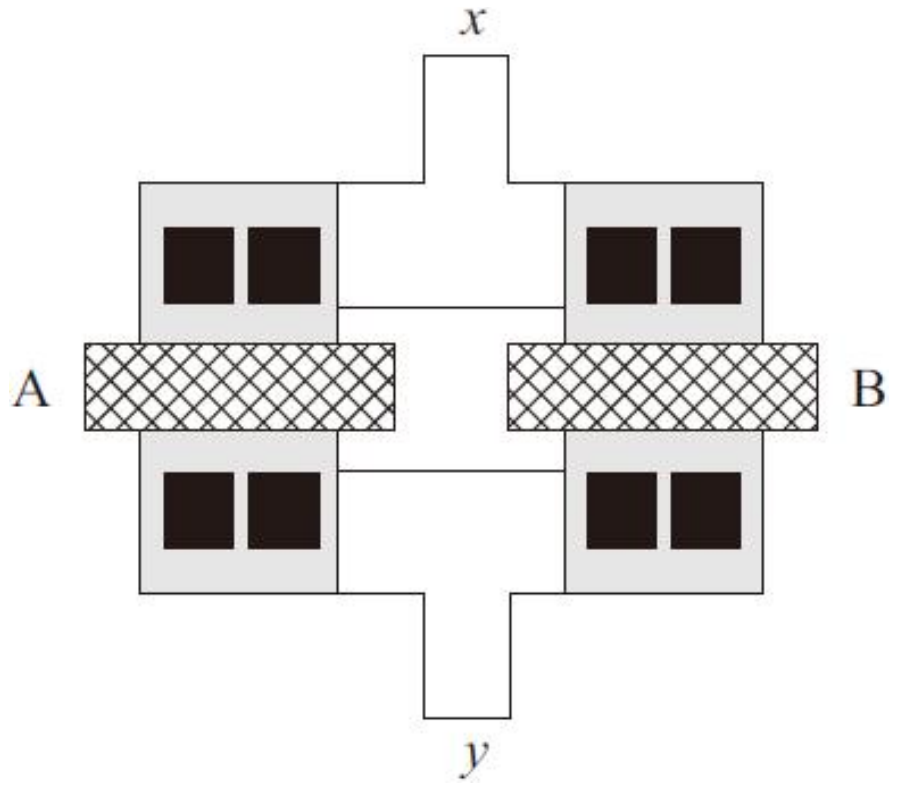
互相分开的晶体管通常比共享漏/源区的晶体管占用更多的面积和增加更多的寄生电容,所以可以通过共享漏/源区的版图实现并联晶体管结构
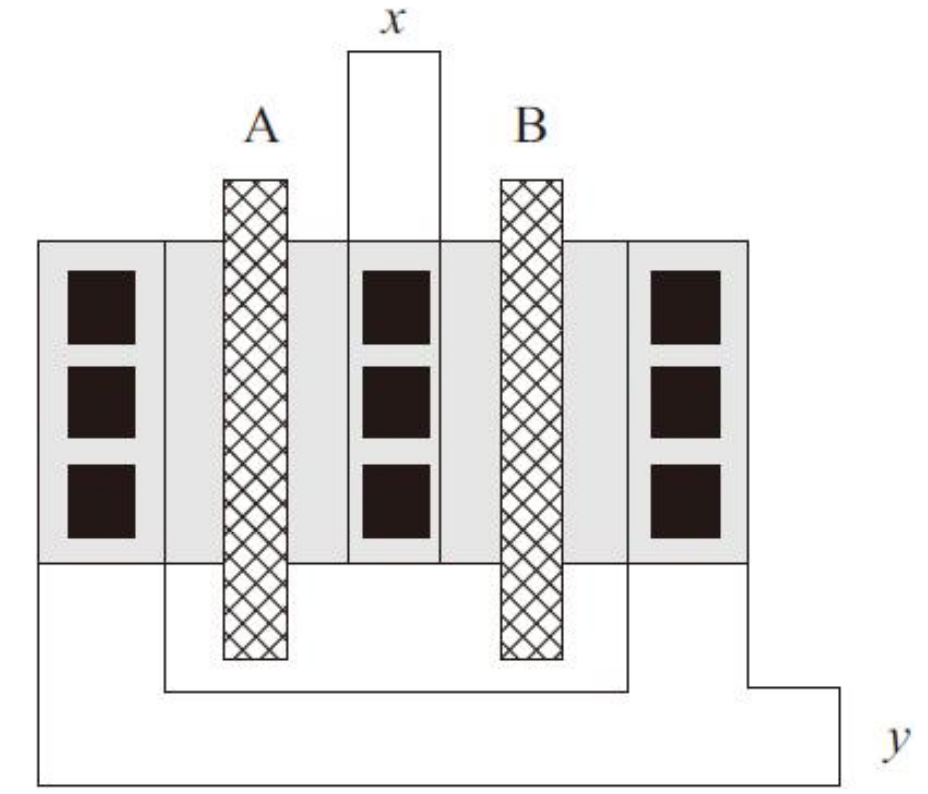
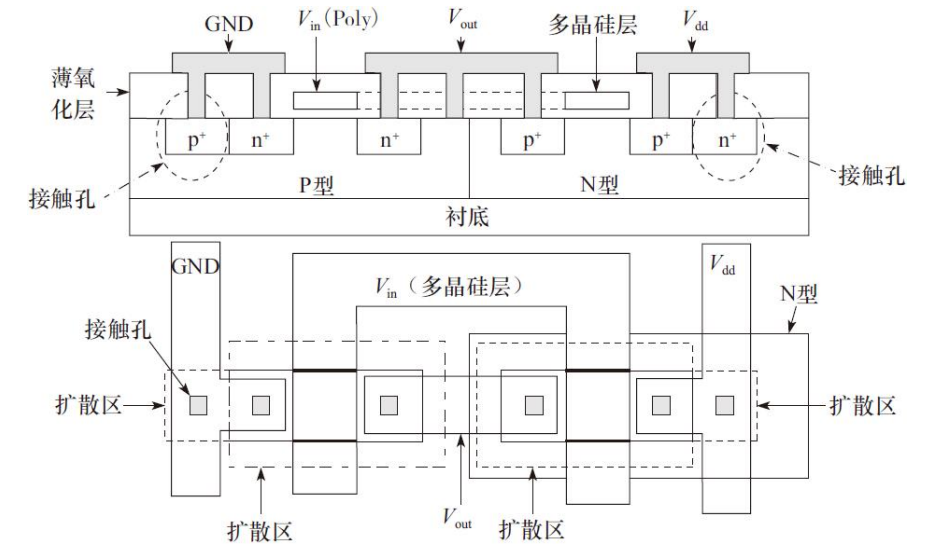
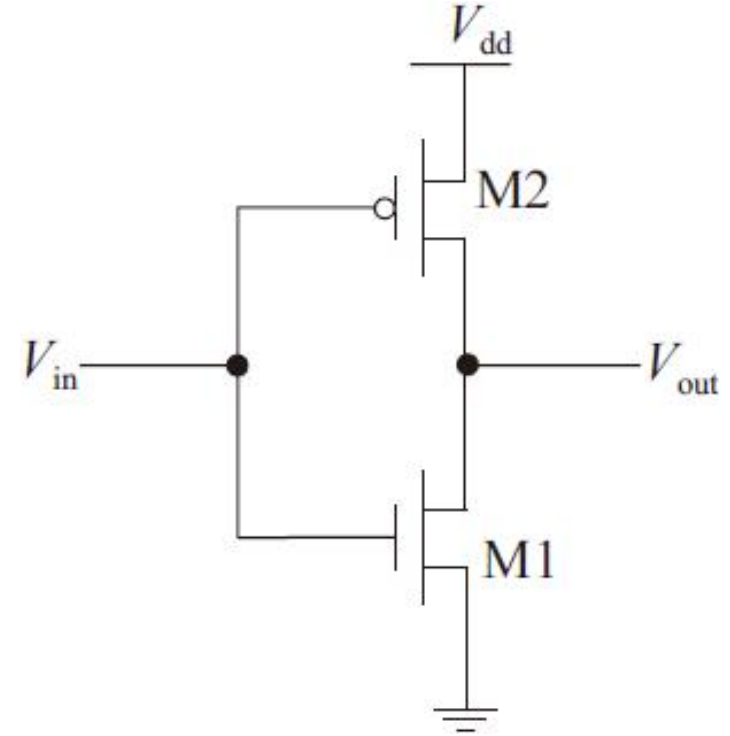
CMOS反相器的版图实现
信号Vin同时加在两个晶体管子的栅极上,在两种输出逻辑状态中,两个晶体管中总有一个是截止的。PMOS/NMOS晶体管可以分别进行版图设计,然后通过在金属层上形成互连线将它们连接在一起
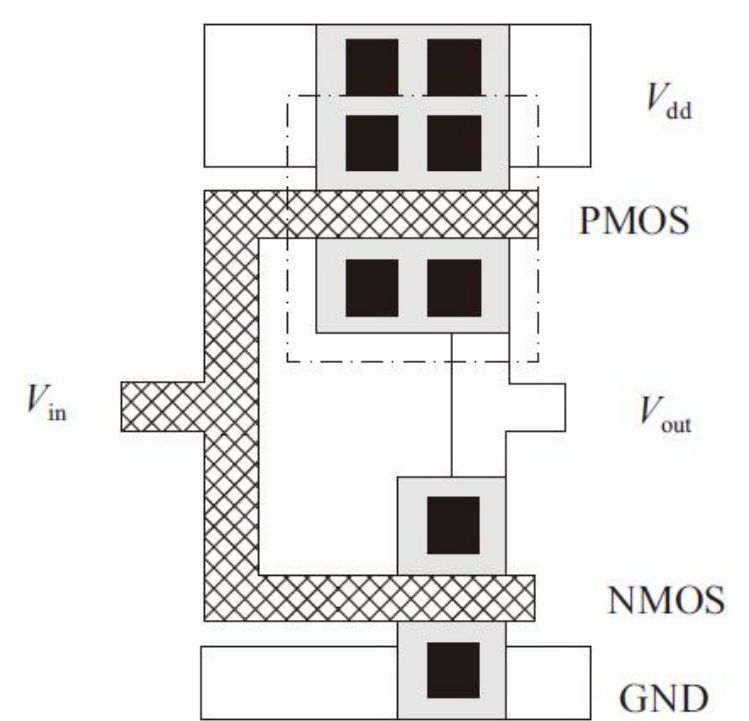
电源(Vdd)和地(GND)用金属线层实现,N+和P+区用同样的有源区层来表示,不同的是PMOS嵌入在N阱的区域内,由于金属层和N+或P+区处于不同的层,所以从金属层到N+或P+区需有接触孔来进行连接。
CMOS反相器特点有下面几点:
1)静态功耗低。稳定时,CMOS反相器总有一个MOS管处于截止状态,流过的电流为极小的漏电流。
2)抗干扰能力较强。由于其阈值电平近似为0.5Vdd,当输入信号变化时,输出信号过渡变化快速。同时低电平噪声容限和高电平噪声容限近似相等,并且随电源电压地升高,抗干扰能力增强。
3)电源利用率高。输出电压Vout=Vdd,所以允许输出信号电压有较宽的变化范围。
4)输入阻抗高,带负载能力强。
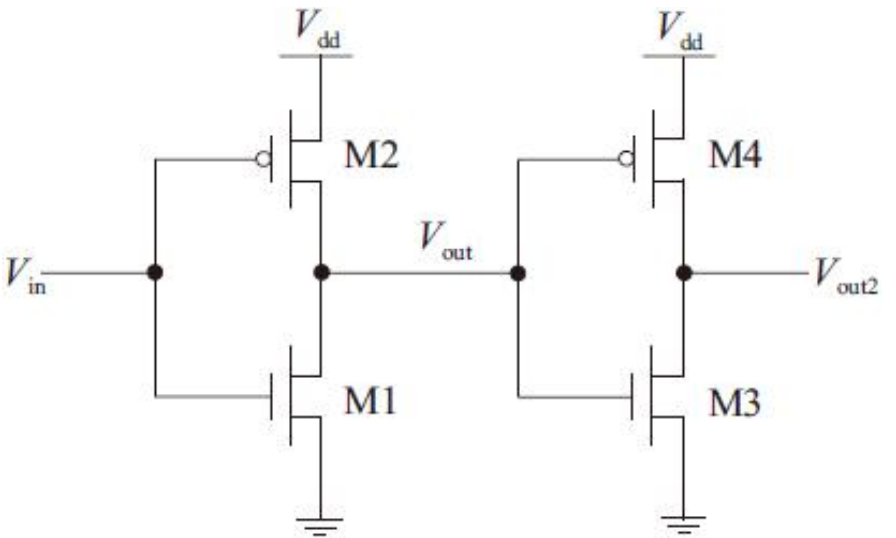
缓冲器的版图实现
缓冲器是由两个串联的反相器实现的,该单元主要用来增强信号的驱动强度,提高抗干扰能力。缓冲器电路如图6-22所示。
缓冲器版图的实现可以先将每个反相器单独实现,然后再通过金属层进行连接。
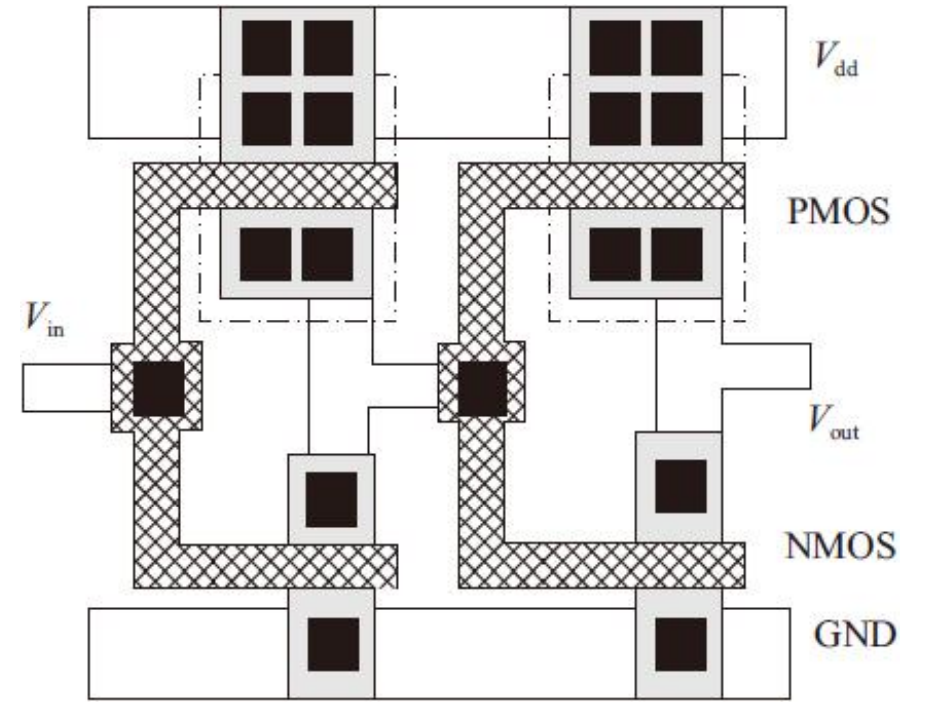
CMOS二输入与非门和或非版图实现
通过前面版图知识地介绍,建立了简单版图的基础后,就可以实现更复杂逻辑电路的版图。CMOS逻辑门电路功耗极低、输出电压范围宽、抗干扰能力强、输入阻抗高、驱动能力强。一个CMOS二输入与非门(NAND2)电路图如图所示。
与非门版图的实现可以通过共享源/漏区和电源地的方法提高版图质量。CMOS二输入与非门(NAND2)版图如图
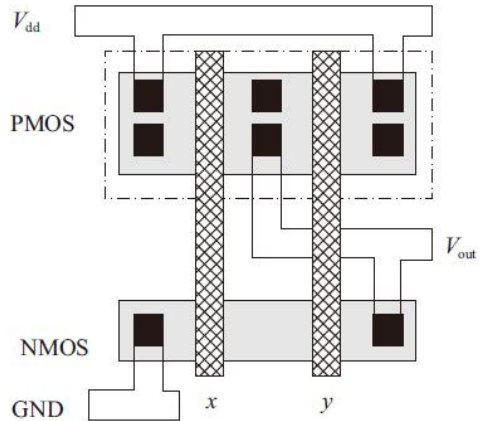
两个NMOS管通过共享源漏区串联在一起,同时两个PMOS也通过共享漏区实现并联,一个CMOS二输入或非门电路图如下
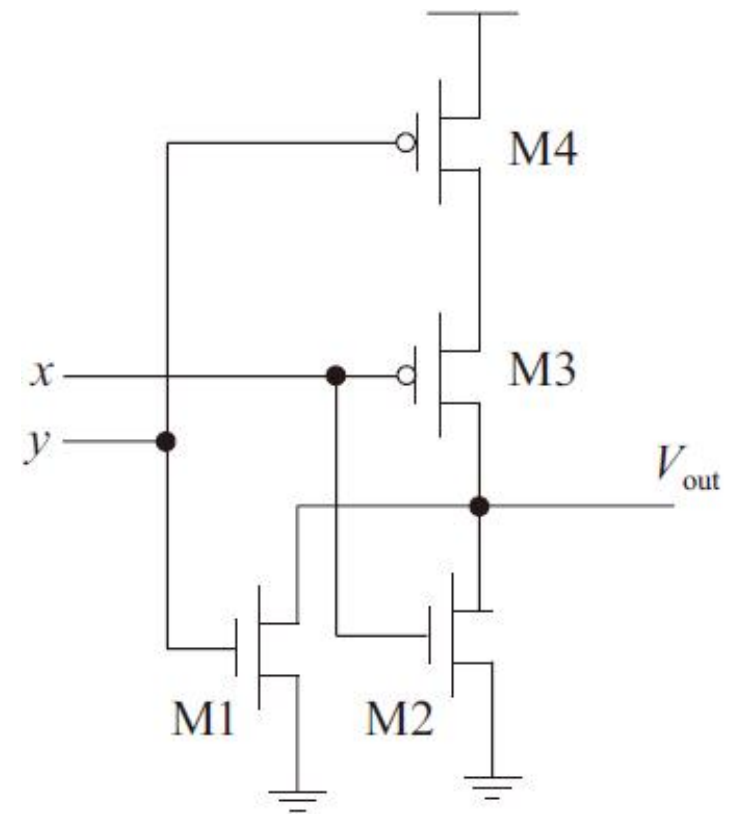
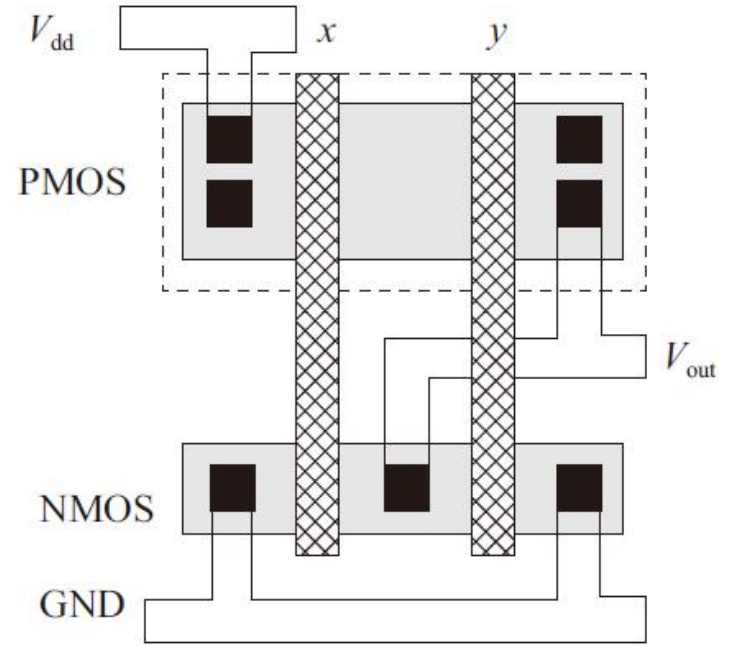
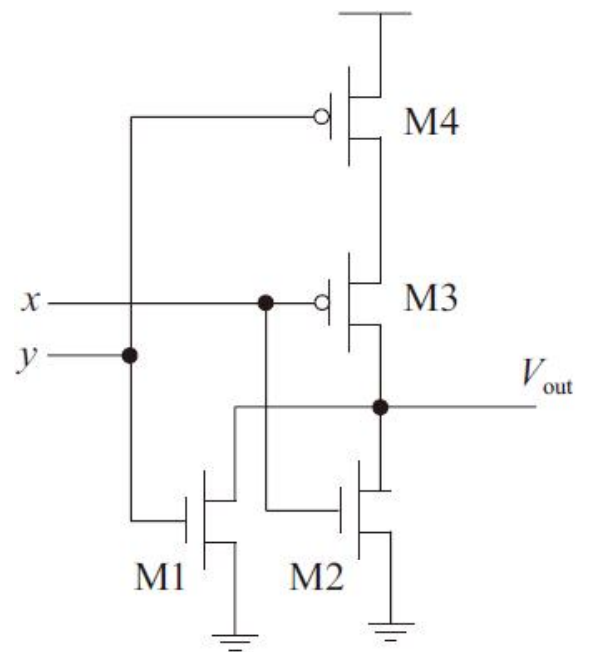
二输入或非门如下
二输入或非门电路
二输入或非门版图
版图设计规则
版图设计规则是用于指导版图设计的一组几何尺寸设计的规定,它规定掩膜版图各层几何图形的宽度、间距、重叠和层与层之间的距离等最小容许值,在保证集成电路在制造过程中工艺能够实现同时保证芯片不出问题的前提下,所提出的对版图设计的各种约束条件。
例如,连线过细会引起断路;金属信号线间距过小容易发生短路;层与层之间交叠的要求往往受光刻对准偏差、侧向腐蚀、横向扩散等因素的影响。
因此,必须在设计规则中对这些影响生产的各种因素加以考虑和规定。
一般而言,版图设计规则是芯片电路性能与成品率之间的折中。规则越保守,芯片电路可靠工作的可能性就越大;相反,规则越灵活,电路性能改进的机会就越大,但电路可靠性降低。
以某N阱硅栅工艺为基础简单介绍其中最基本层的版图设计规则。
1)N阱(NW)设计规则,如图
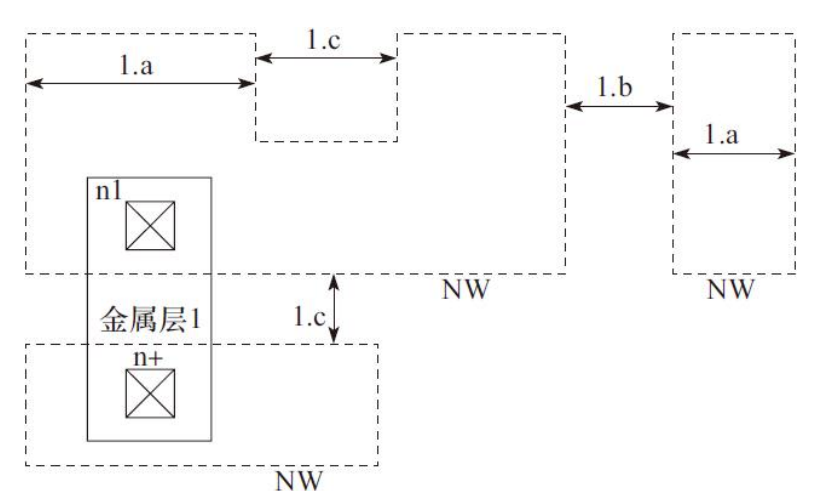
N阱(NW)设计规则详细说明

2)有源区OD设计规则,如图
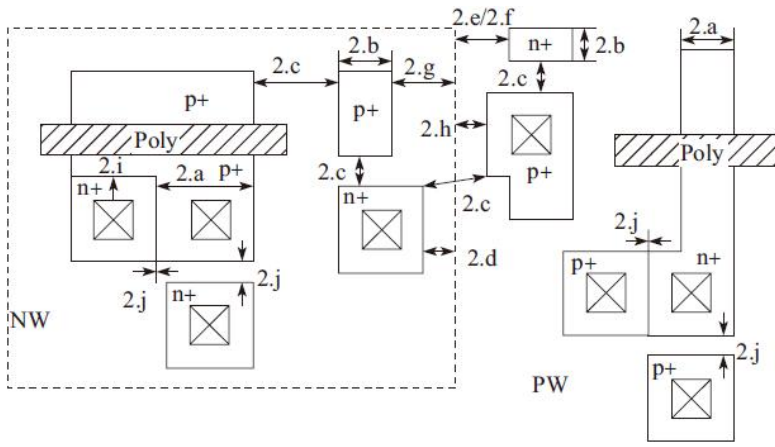
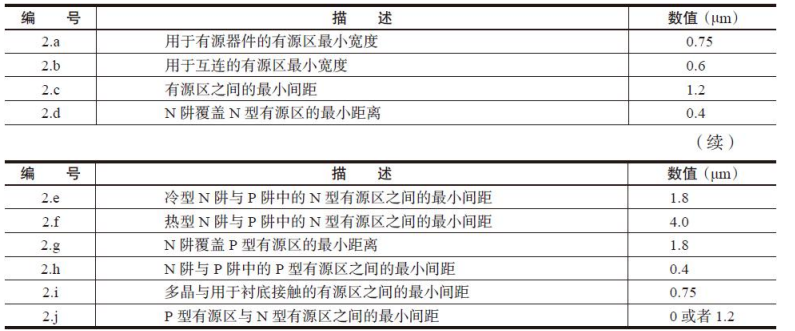
有源区OD设计规则详细说明,如表
3)多晶POLY设计规则,如图
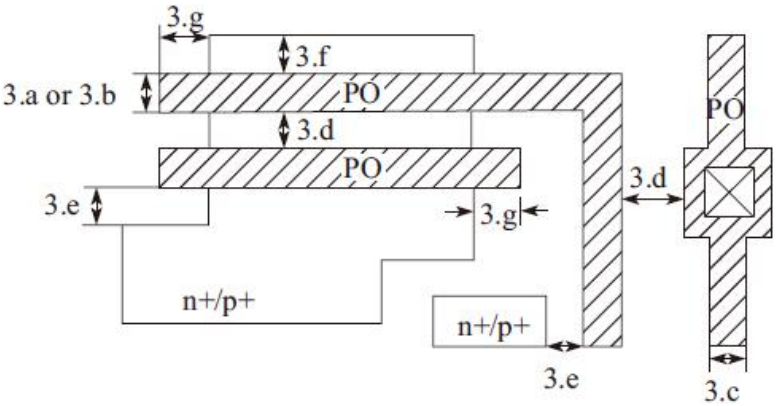
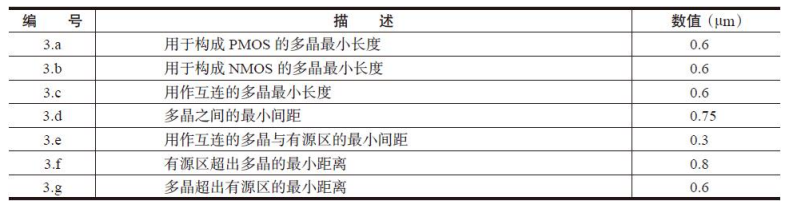
多晶POLY设计规则详细说明,如表
4)P掺杂(PP)与N掺杂(NP)设计规则,如图
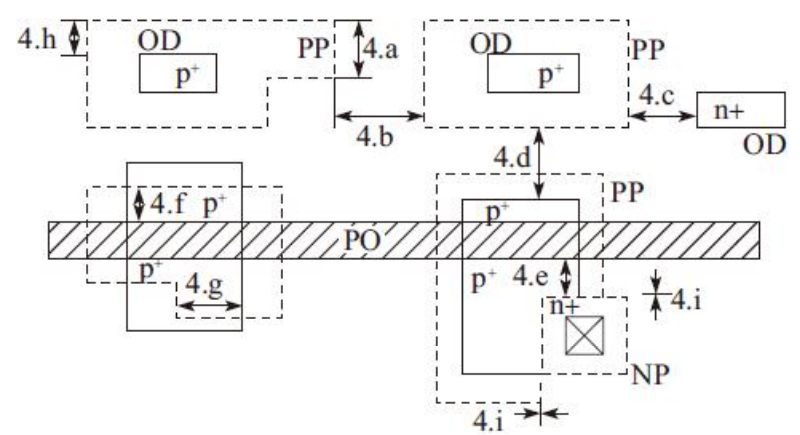
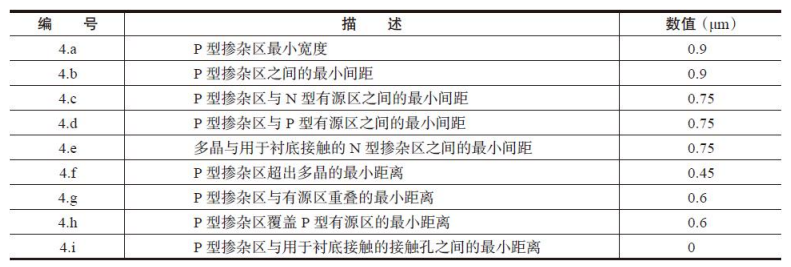
P掺杂(PP)与N掺杂(NP)设计规则详细说明,如表
5)接触孔CO设计规则,如图
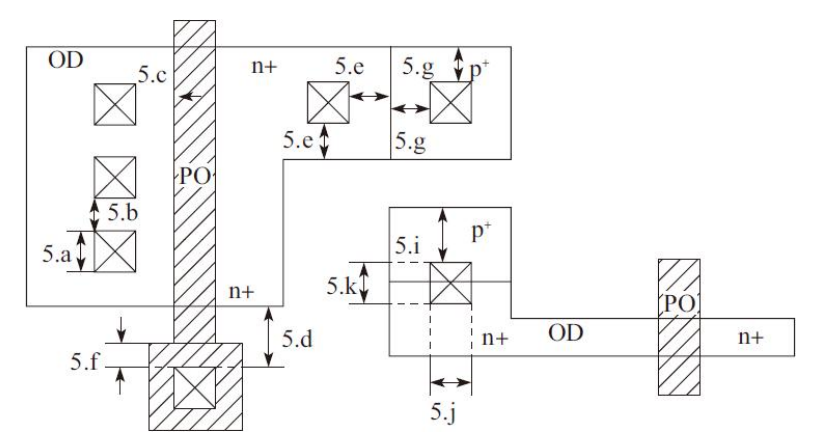
6)金属层1(M1)设计规则,如图
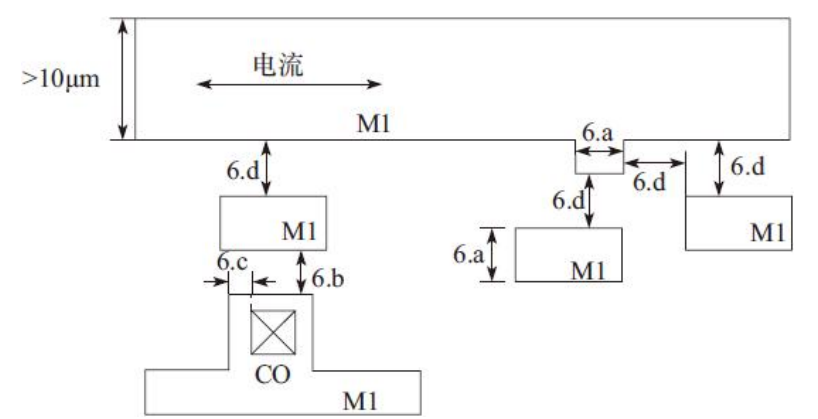
7)通孔1(VIA1)设计规则,如图
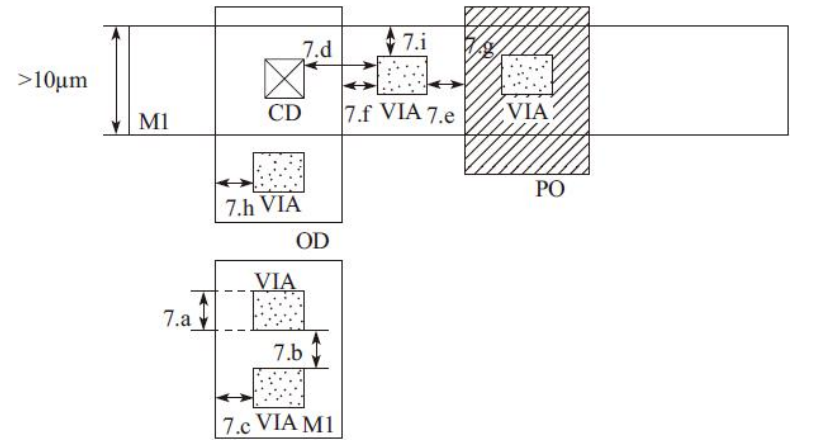
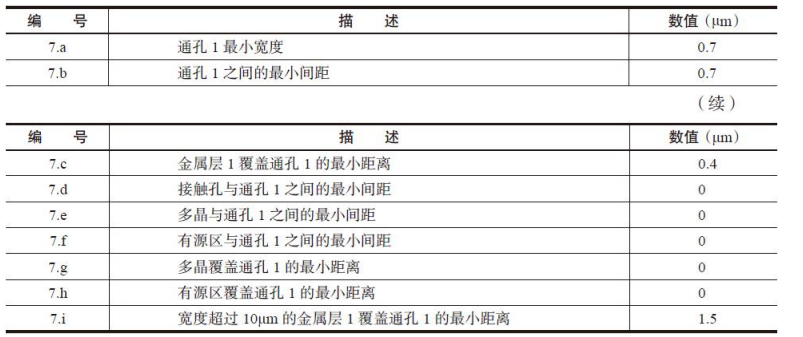
通孔1(VIA1)设计规则详细说明,如表
8)金属层2(M2)设计规则,如图
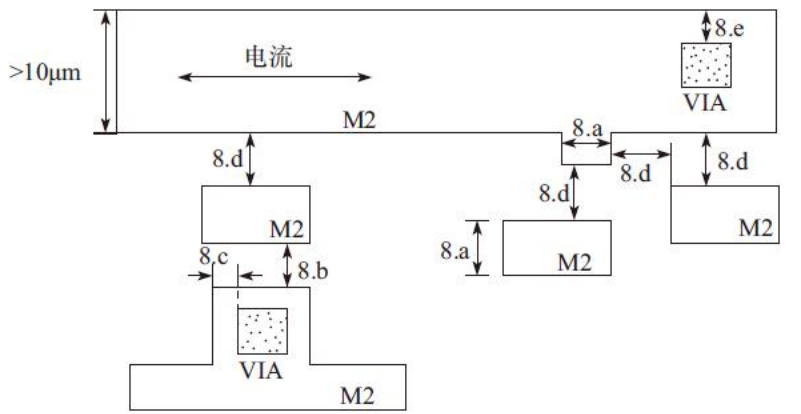
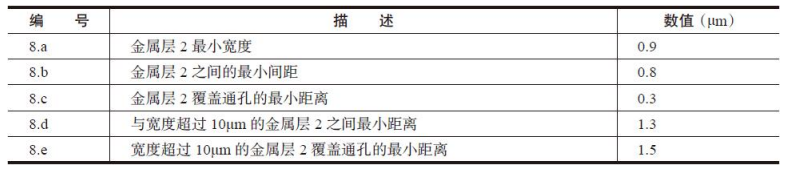
金属层2(M2)设计规则详细说明,如表
9)通孔2(VIA2)设计规则,如图
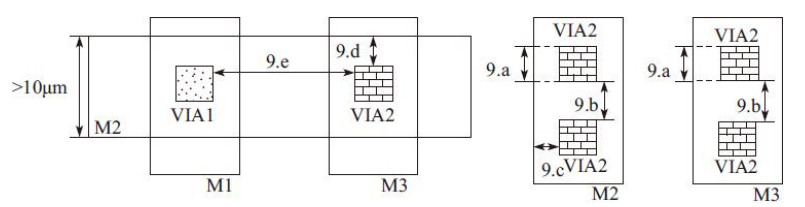
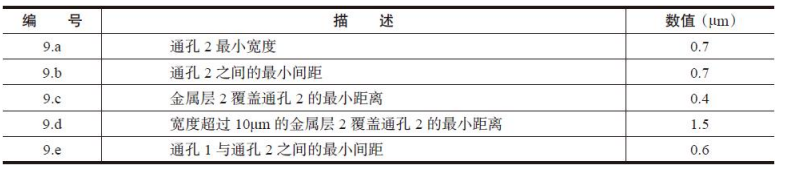
通孔2(VIA2)设计规则详细说明,如表
10)金属层3(M3)设计规则,如图
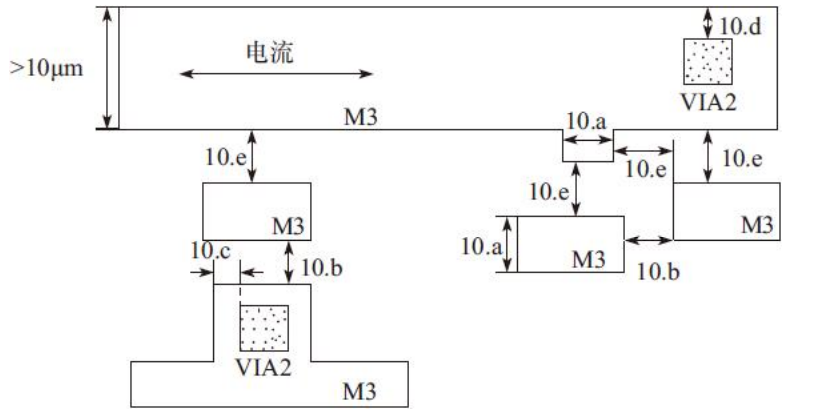
金属层3(M3)设计规则详细说明,如表
版图设计中晶体管布局方法
在版图设计中,如果可以使形成PMOS管和NMOS管的有源区得到有效地共用而使不隔断的次数降到最少,简单地说就是尽量让所有的N型晶体管均使用同一块有源区,让所有的P管也使用同一块有源区来达到充分利用有源区的目的,这使得多晶硅栅极的间隔可以变小,器件整体尺寸可以减少,由此减少电路版图面积。通过改变多晶竖列的排序就可以使有源区的中断次数最少,版图面积的减少带来连线长度的减少,从而减少连线电阻,进而提高电路性能,降低功耗。
基本欧拉路径法
为了达到在版图设计中充分利用有源区的目的,就需要应用如何确定栅管排序才能使所有的同一类型晶体管使用同一块有源区的有效方法。
确定最佳栅管排序的一种简单方法是基本欧拉路径法,其基本原理是:首先在上拉线图和下拉线图中找一条具有相同输入标号顺序的欧拉路径,即在两个线图中找一个共同的欧拉路径。欧拉路径又称欧拉通路,是指穿越线图中每条边一次且仅一次的连续路径。
上拉图是PMOS上拉网络的一种表示方法,其中节点表示PMOS上拉网络原理图中的互连线,连线表示PMOS晶体管。
下拉图是NMOS下拉网络的一种表示方法,其中节点表示NMOS下拉网络中的互连线,线表示NMOS晶体管。
一个复杂门电路原理图及其上拉线图和下拉线图。
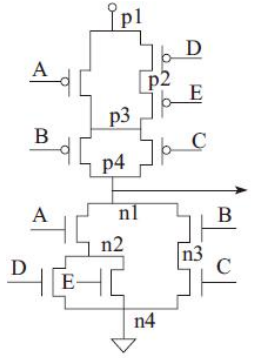
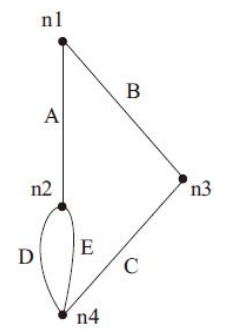
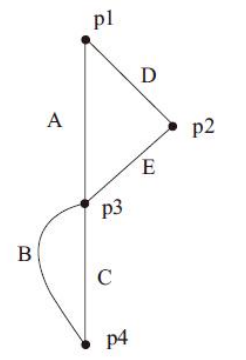
其表达式为:out=A(D+E)+BC。图中的节点n1、n2、n3和n4表示图中相应的互连线;下拉图中的A、B、C、D和E分别表示以A、B、C、D和E作为输入的NMOS晶体管;上拉图中的A、B、C、D和E分别表示以A、B、C、D和E作为输入的PMOS晶体管。
未经规划栅极排序的版图示意图
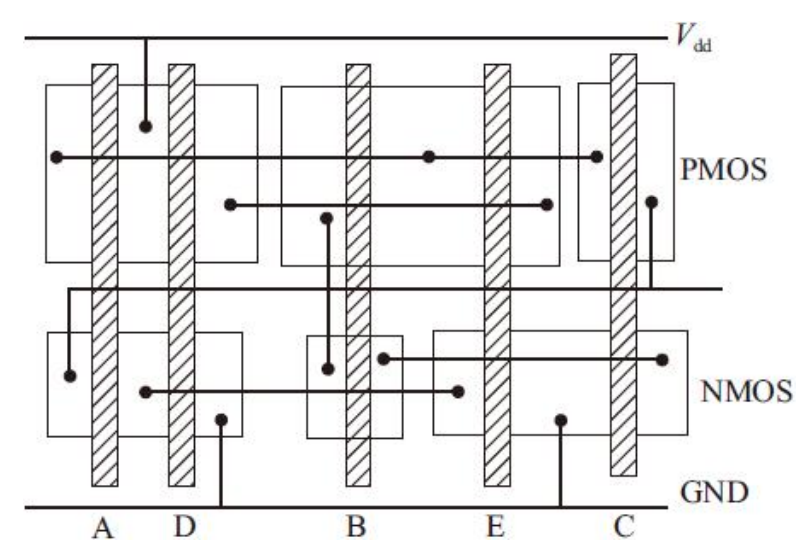
基本欧拉路径法优化版图布局的过程
1.分析电路图中的节点,是否存在奇度节点。
奇度节点是指与奇数个边相连的节点。下拉图中的n2和n4就是奇度节点,上拉图中没有奇度节点。如果存在两个奇度节点,任意选择一个奇度节点作为起点;如果图中存在两个以上的奇度节点,那么该图不存在欧拉路径,不存在欧拉路径的线图我们将在6.5节介绍;如果图中不存在奇度节点,那么可以任意选择一个节点。
对于下拉图,不妨选择n2作为起点。下面列出了以n2为起点的所有欧拉路径:①A-B-C-D-E;②A-B-C-E-D;③E-D-A-B-C;④E-C-B-A-D;⑤D-E-A-B-C;⑥D-C-B-A-E。
2.找到相同的欧拉路径,上拉图的起始边和下拉图的起始边必须相同。
上述欧拉路径的起始边共有三条:A、D和E。下面分别以A作为起始边,在上拉图中寻找欧拉路径:①A-B-C-E-D;②A-C-B-E-D;③A-D-E-B-C;④A-D-E-C-B
D,E也是同理
3.A-B-C-E-D和E-D-A-B-C是两图共同的欧拉路径
4.找出相同的欧拉路径后,多晶栅极竖列可以根据这个序列进行实现,这样可以构成p管和n管源区的次数最少。
确定栅极排序后,下一步需要把晶体管用金属线互连。具体做法是:首先把多晶栅极序列中的节点补充完全。这里我们使用的共同的欧拉路径为:E-D-A-B-C,下面将它的节点补齐。
NMOS:n2-E-n4-D-n2-A-n1-B-n3-C-n4;
PMOS:p3-E-p2-D-p1-A-p3-B-p4-C-p3。
然后把上述序列,按照从左到右的顺序分别标到NMOS管和PMOS管上,并且把相同标号的节点(这里代表晶体管的源区或漏区)用金属线连接。
注意:上拉线图中的节点p4和下拉线图中的节点n1都连接到输出,因此需要把这两个节点用金属线连接到一起,作为输出;节点n4和节点p1分别代表地线和电源线。
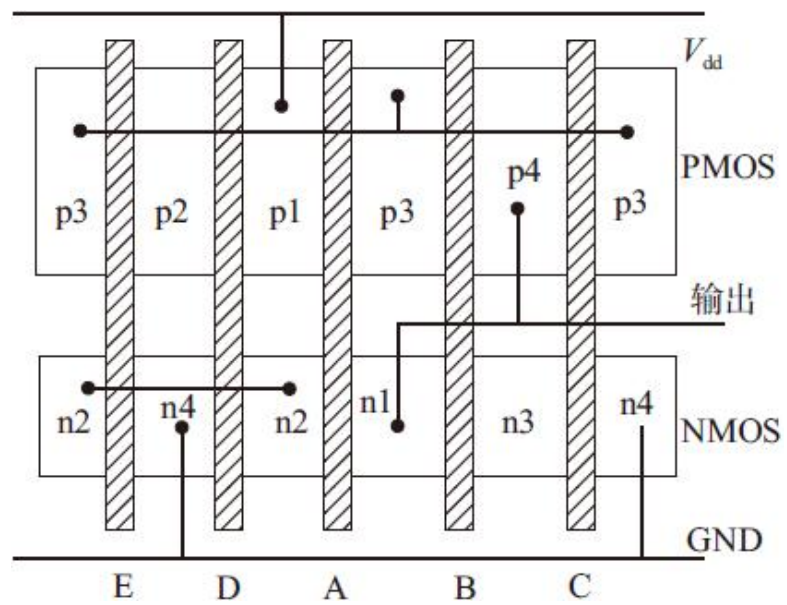
所有的P管共用一个有源区,所有的N管共用另一个有源区。其中,多晶阵列的最小间隔只要可以放下一个金属到有源区的接触孔即可。
欧拉路径法在动态电路中的应用
动态电路与互补COMS逻辑门的最大差别是:动态电路中N管数目远远大于P管数目(P型动态电路的情况相反)。针对这种N管和P管数目的不平衡性,可以采取一种策略:首先使用欧拉路径法先考虑多数同类型MOS管(一般是N管)的实现,暂时屏蔽掉少数同类型MOS管的影响。根据多数管布局后,再增加被忽略的晶体管。这种欧拉路径法,称为多管欧拉路径法。
一种动态译码器结构的动态电路如图
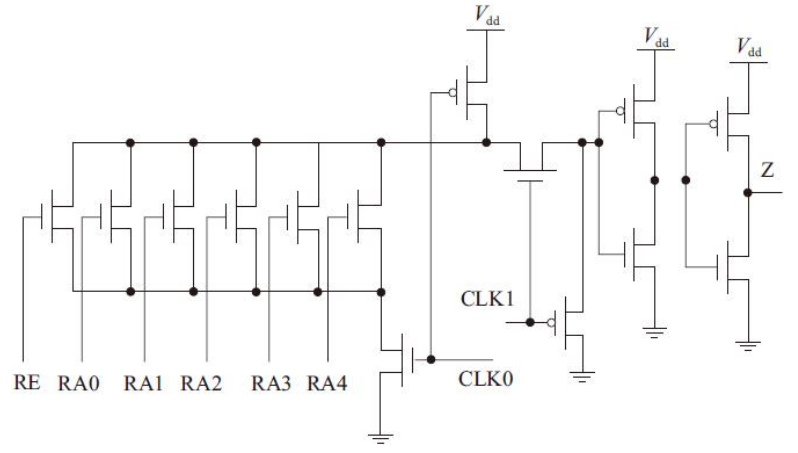
它有8个输入:两个脉冲输入、1个使能信号和5位的地址信号。该电路可以分成三部分:动态译码、译码输出和信号加强。信号加强电路由逐级加大尺寸的两级反相器组成。这里首先只考虑动态译码电路,它共有8个晶体管,其中只有1个P管,其下拉线图如图
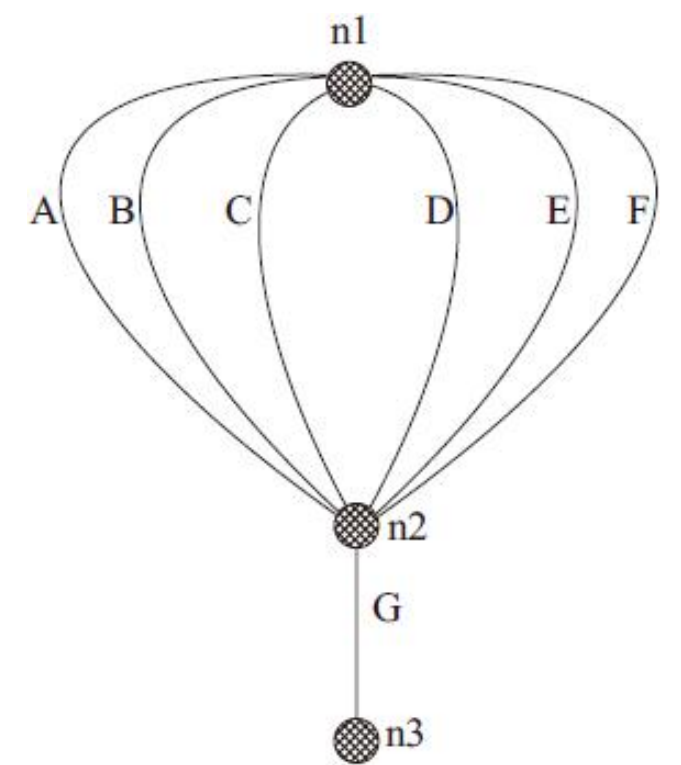
的欧拉路径为:G-A-B-C-D-E-F和A-B-C-D-E-F-G,其他路径与这两种路径同构。以欧拉路径A-B-C-D-E-F-G作为顺序的版图,如图
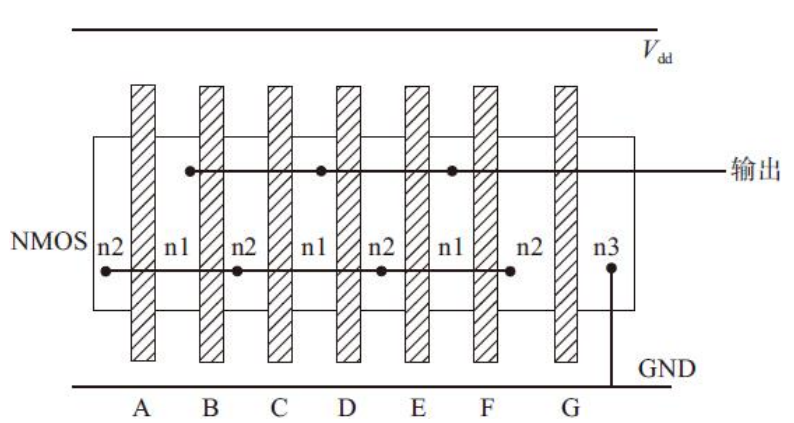
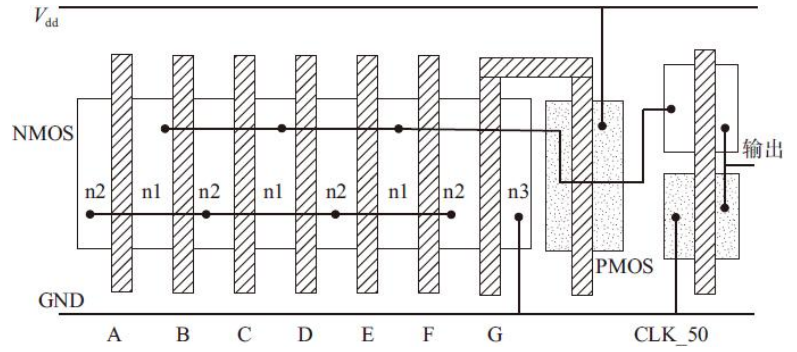
动态译码器结构的动态电路的最终版图,版图中未画出两级反相器
晶体管尺寸对版图的影响
前面介绍的欧拉方法是在假设晶体管尺寸基本相同的前提下提出的。事实上,很多逻辑门中的晶体管尺寸相差甚远。在这种情况下,晶体管的尺寸对电路布局有很大影响,因此不得不把晶体管的尺寸考虑进来。
大尺寸晶体管的版图在实现中往往折叠成多个并联晶体管。假设图6-38b中的n管A的宽度为2X,其余N管的宽度为X,假设所有P管的宽度基本相同,设为Y。那么可以把A管看作两个并联的晶体管,其宽度均为X。
这种情况下,首先考虑以A作为起始边,寻找上拉线图和下拉线图的相同欧拉路径。根据欧拉路径法分析,存在以A作为起始边的相同欧拉路径:A-B-C-E-D。考虑晶体管尺寸的最终版图,如图
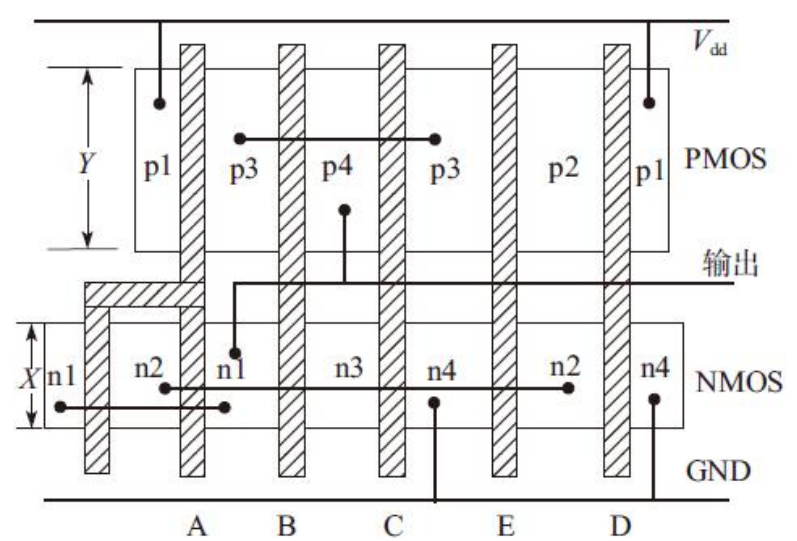
如果不存在以A作为起始边的相同欧拉路径,那么只好先把A当做宽度X的晶体管处理,然后,再增加一个与A并连的N管。
标准单元版图设计的基本指导
在详细设计单元库之前,设计者应该要清楚得明白:单元本身面积设计得最小可能并不会使最终的芯片面积最小。相反,这里的设计建议可能对于单元本身面积结果是增加的,但是最终芯片面积由于提高了布线资源反而变小了。
优化设计标准单元
1)标准单元中每一个逻辑PIN脚在物理版图上至少有一个对应的金属端口。
2)所有单元的版图都必须在单元边界之内。
3)在一些工艺中,电源和地的PIN脚在单元版图的边界上或者超出边界之外。
4)PIN脚的边界与版图必须至少离单元边界至少半个格点间距以避免潜在的DRC违反。
5)把单元缩小到最小,芯片面积并不一定最小。适当的增加单元的大小比没有考虑布线资源的缩小单元面积的做法对布线效率更有好处。
优化单元宽度
优化单宽度应注意以下两点:
1)避免设计的同一类型的标准单元的宽度差别太大。宽度差别太大会导致单元行长度不一。
一般地,大驱动标准单元的宽度应该不超过同类型最小单元宽度的5~6倍。如果需要设计比较复杂的标准单元,最好在高度上设计为两倍或者3倍以保证合理的单元宽度。布局布线工具通过混合单高度与多高度单元的无缝拼接来实现最终芯片面积的最优。
2)所有单元的宽度应该是布线格点间距的整数倍。
如果单元宽度不是布线格点间距的整数倍,即使单元的PIN脚处在单元内部的布线格点上,单元本身可能也会引起相邻单元在拼接后PIN脚没有处在布线格点上。所以如果出现这种情况,就会占用更多的垂直和水平的布线资源。即使单元宽度设计为布线格点间距的整数倍可能会增加单元本身的尺寸,但是最终芯片的面积将会减少。通过设置单元的宽优化单元高度取决于芯片设计中所使用的标准单元的布局策略。
优化单元高度
四种策略:其中第2种策略是不高效的。布局布线中一般选择其他3种策略中的一种来实现芯片版图。最后2种策略能够实现最小芯片的面积。
第1种:统一行高度单元排列的布局策略
一般这种布局策略的实现需要两层以上的布线资源,同时单元高度是受限制的。如果使用这样的排列策略可以把电源和地共享起来。电源和地共享可以减少布线通道,同时减少芯片的最终面积。

第2种:不规则可变高度单元排列的布局策略
这种实现策略主要用于只有两层布线资源的设计。由于没有更多布线层支持高效地布线,这种策略允许单元高度存在30%的随机浮动,但是无法做到电源和地的拼接共享。
第3种:单双倍高度单元排列的布局策略
这种设计需要两层以上的布线层资源。单高度和双倍高度单元混合排列在单高度的单元行里。这种排布策略也可以做到电源和地共享。
第4种:多种多倍高度单元排列的布局策略
这种排布策略的实现需要3层以上的布线资源。由于两层资源不够,同时单元之间没有专门的布线通道,所以不能使用基于额外布线通道的布局策略。但是这种布局策略可以同时使用单倍、双倍、3倍高度的单元,因此这种实现策略能实现高效的电源和地共享。
优化单元布线的连通性
普通标准单元都只使用金属层1完成内部逻辑的连接和构成输入输出PIN脚,由于中等驱动力和大驱动力标准单元比小驱动力标准单元要包含较多的MOS器件。
在不增加过多版图面积的情况下,中等驱动和大驱动标准单元都需要实现较高的连通性,这样大驱动力单元的版图可以使用金属层2。这种单元版图实现策略意味着中等驱动和大驱动单元通过使用金属层2提高了可连通的概率,这样可以达到与小驱动单元的可连通性保持相同。
如果单元之间的连通性差距太大,当连通性不好的单元都放置在一起后,布局布线工具可能导致布线绕通的难度加大。
虽然对于小单元(1~2个布线通道宽度),布局布线工具可以调整它们的位置距离来实现好的布通性,然而好的标准单元设计能大大改进布通率。
对于普通的标准单元,可以提高单元金属层1 PIN脚的面积,通过提高金属层1的空闲布线资源提高PIN脚的多孔连接性,如图
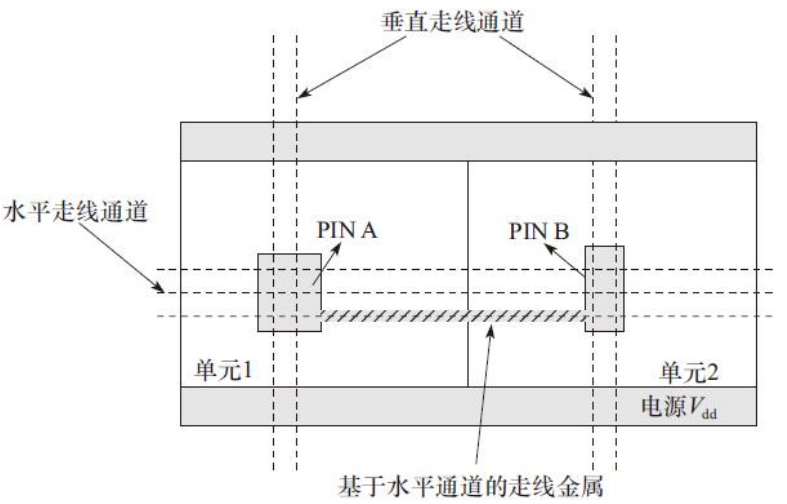
也可以通过为单元设计多个可以连接的PIN脚或者可以通过金属层2的Z形布线策略来充分地利用空闲格点空间的方法来提高连通率
标准单元PIN脚的设计
在标准单元设计中,如何设计合理的单元PIN脚至关重要,单元PIN脚设计越合理,那么可用于布局布线中单元之间可连接的通道就越多,布线工具越能高效地进行连接,这样可以最大化布线资源,同时减少布局布线软件的运行时间和内存使用率。
1.把单元的输入输出PIN脚放置在布线格点上。
尽可能地把PIN脚放置在布线格点上,但对于偏离格点的PIN脚要保证能满足生成的辅助格点的间距规则。放置一些特殊的辅助PIN脚来避免阻塞邻近的布线通道,这些特殊的PIN脚可以不处在格点上。
主流布局布线工具可以做无布线格点概念下的布局布线,但是工具对有布线格点概念的PIN脚的连接效率要比偏离格点的PIN脚连接要高得多。
如果PIN脚满足以下两条标准即可认为PIN脚位于格点上:
1)PIN脚的中心位于格点中心处。
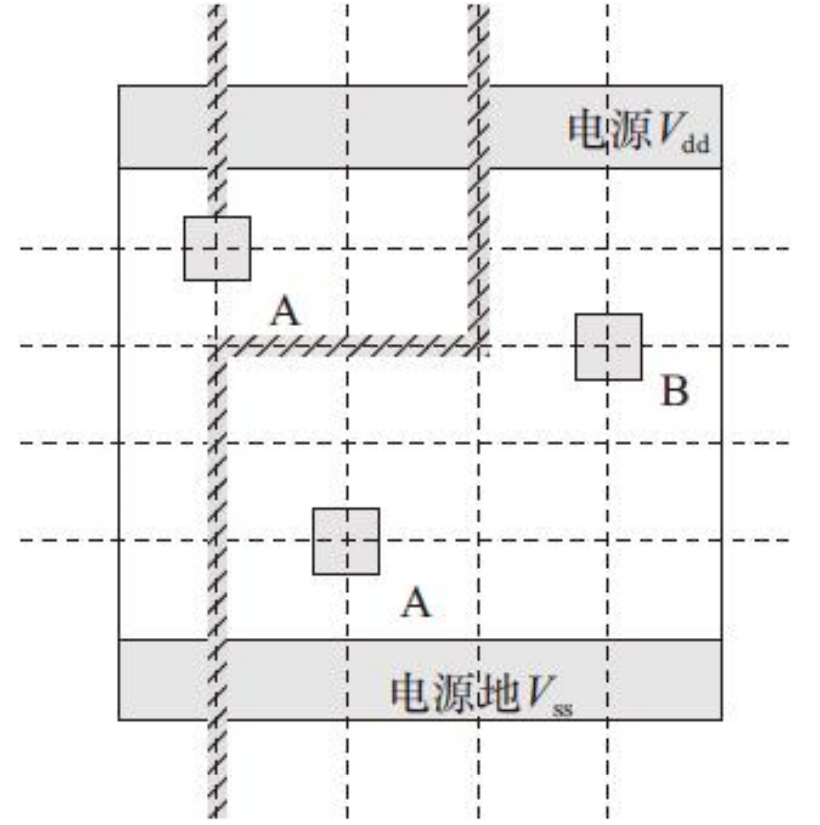
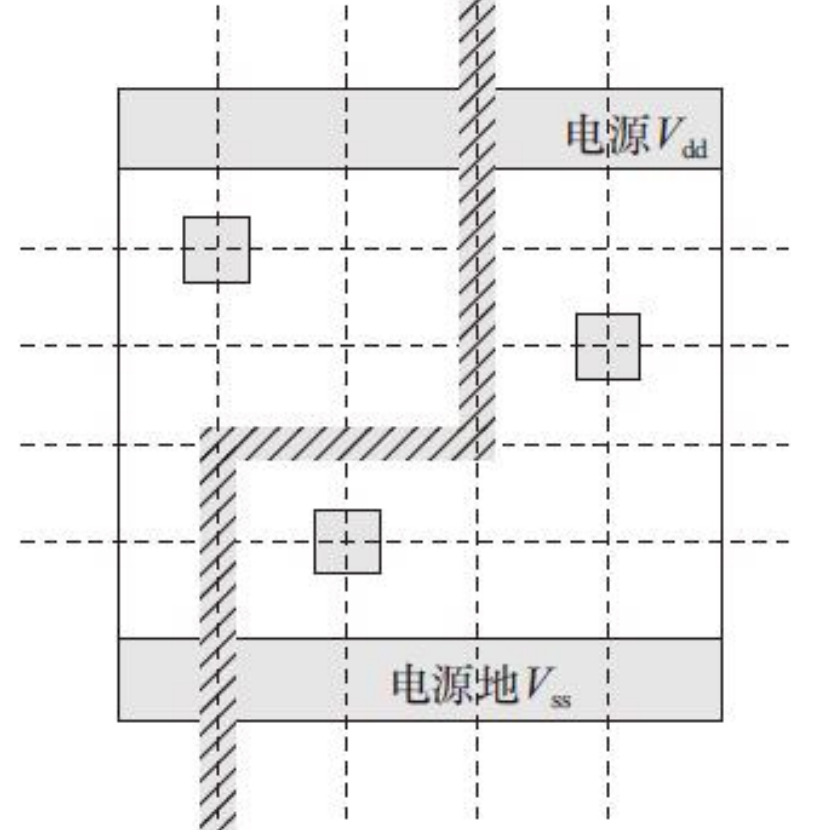
2)PIN脚的形状正好包裹格点中心,4条边多出最小金属宽度的一半。格点中心在该金属层在X轴Y轴布线格点单位宽度的交界处,这样布线工具恰好能连接到PIN脚中心。处在布线格点与不处在布线格点的单元PIN脚对比图,如图
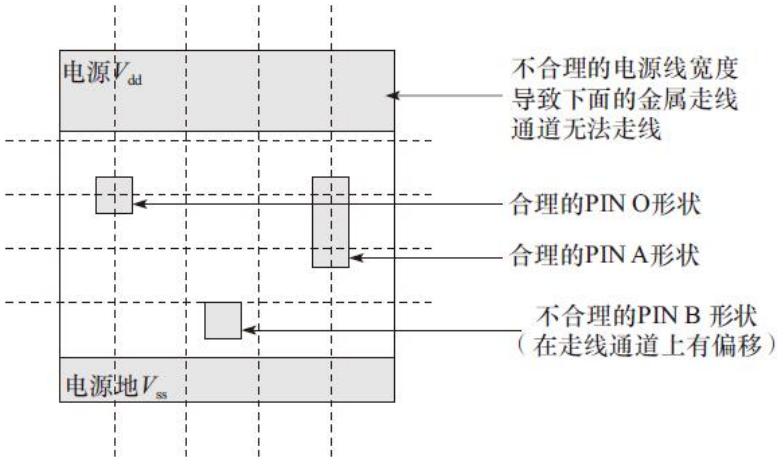
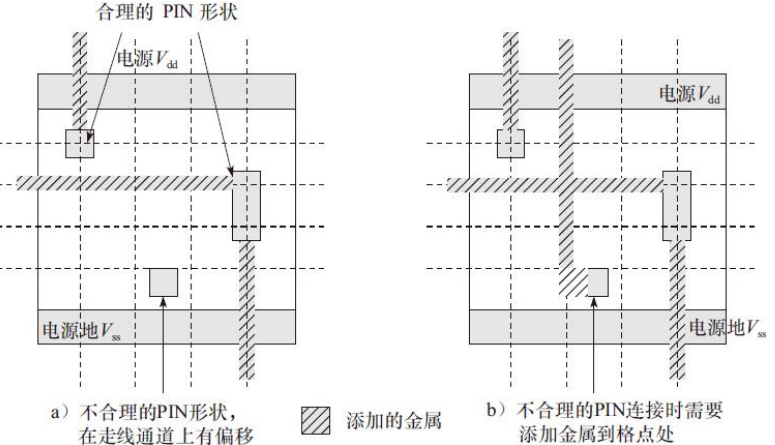
PIN脚A的金属层有偏移格点与处在格点的图形。PIN脚B的金属层偏移导致浪费了2个格点位置。PIN脚O的金属层处在格点上。偏移格点的PIN脚会减慢布局布线工具的计算时间,同时降低布线效率。如果PIN脚B由于设计规则的问题不能在该格点位置用通孔连接,那么布局布线工具就不能进行高效的连接,导致布线效率降低。
偏移布线格点的单元PIN脚对布线结果的影响
1)增大了芯片面积。偏移格点后,布局布线软件需要使用更多的走线资源进行连接,对于走线资源比较紧张的设计,只有增加芯片面积才能提供更多的走线资源,如图6-53所示。
2)增加了布线的难度和限制。越多的布线连接限制将导致布局布线软件效率越低。图6-54说明了单元PIN脚偏移布线格点导致了更多的布线连接限制。
PIN脚偏移格点后,布局布线软件需要在垂直方向上通过拐弯来连接没有在布线格点上的PIN脚,这样会占用更多的垂直通道同时增加布线难度。
3)导致工具运行时间增加。单元PIN脚偏离布线格点由于间接增加了临近的布线通道阻塞率,这样会大大增加软件的运行时间。
4)导致布局布线工具做虚拟全局布线的评估过于乐观而不准确。布局布线工具在进行虚拟全局布线评估时会忽略偏移格点而导致的阻塞,从而得出过于乐观的预估结果。
2.最大化使用布线资源
单元内部可利用的布线资源越多可以使布线工具实现布通结果的概率越高。因此可以通过对单元内部金属层进行相应的设计约束来最大化地利用布线资源。比如在3层工艺设计下,定义金属层2位垂直走线,金属层1和层3为水平走线,但是金属层2为典型的受限制层,那么在单元版图实现上尽量使PIN脚连接少占用金属层2的资源。
建议:
1)最大化PIN脚的可连通性。
在物理信息抽象化过程中把整个单元PIN脚的所有面积都定义为可连接的PIN脚区域,可以增加PIN脚的连通性。可以让布线工具找到最合适的格点位置而不是强制拐弯连接。
同时要避免同一金属层不要堵塞PIN脚的布线通道,如果那样就会导致布线工具无法连接或者需要换层连接,这样会降低布通效率。更不能让其他连线把PIN脚用于连接的通孔层也阻塞。
比如,避免金属层2的金属连线区域太接近金属层1的PIN脚区域,因为这样可能会导致当需要通孔连接PIN脚时,却由于金属层2设计规则违反(DRC)不能在该位置通过通孔来连接PIN脚。
2)PIN脚在X和Y轴方向上彼此错开。
错开PIN脚能提供更多的垂直布线资源,如图
如果两个或者更多的PIN脚垂直对齐,那么垂直方向上的布线通道会阻塞,导致需要使用水平通道来拐弯连接PIN脚。通过在垂直方向上错开PIN脚排列,特别是在垂直布线通道上PIN脚的间距正好为格点间距的整数倍,能为布线工具提供多方位选择,增加连接PIN脚的灵活性。
3)在受限制金属层上使PIN脚的数量最少化。
单元中受限制层的图形都会成为布线阻碍。比如对于金属层3设计,垂直走线的金属层2为受限层,可以通过增加PIN脚在金属层1的面积而保留金属层2和3走线资源,最大化地利用布线资源。
4)在受限制层中增加额外的布线资源。
假如设计金属层3,垂直走线的金属层2为受限层,基于阵列的端口可能在金属层2引起阻塞,那么应该扩大端口的图形面积来增加金属层2的布线资源。
比如,二输入的与非门中可能PIN脚有3个布线通道宽度的阻塞,就必须把该PIN脚的面积设计到至少4个布线通道宽来提供额外的布线资源。
5)在布线资源充足的情况下,不要增加额外的金属层来作为连接点。
一些单元库,通过在金属层2提供同一PIN脚连接点来提供更多的可连接性以解决金属层1的阻塞问题。
但是在金属层1布线资源比较充足的情况下,尤其在金属层2为受限层时,这样会因为金属层2而减少布线资源,从而降低布线工具的灵活性。因此在布线资源充足的情况下,不需要额外增加PIN脚的金属层,布线工具会通过通孔自动连接。
版图设计流程
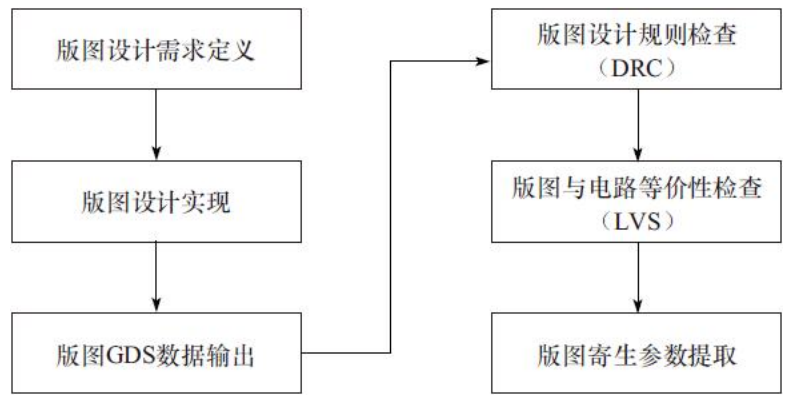
1)版图设计需求定义。版图设计之前需要对面积、模块划分和设计周期等需求因素进行评估和定义,为后续版图设计提供参考依据。
2)版图设计实现。基于电路图和版图设计需求定义,通过合理的版图规划实现版图设计。
3)版图GDS数据输出。在版图设计完成后,需要生成该版图的设计数据,供后期版图物理验证等过程调用。
4)版图设计规则检查(DRC)。版图设计完成后,需要通过版图设计规则检查来验证版图是否符合流片厂流片的要求。
5)版图与电路等价性检查(LVS)。版图设计完成后需要通过版图与电路进行等价性检查,验证版图是否与电路图设计保持一致。
6)版图寄生参数提取。在通过版图物理验证后,需要提取版图中的寄生参数信息。基于带寄生参数信息的网表,通过电路仿真验证版图功能的正确性和是否满足性能要求。
全定制版图设计(Full-custom Layout Design)和半定制后端设计(Semi-custom Backend Design
虽然都遵循类似的物理设计流程,但在设计目标、方法、自动化程度、精度要求和应用场景上存在本质区别。下面从六个步骤出发,系统性地对比两者的差异:
1. 版图设计需求定义
| 维度 | 全定制设计 | 半定制设计 |
|---|---|---|
| 面积目标 | 追求极致紧凑,常以“最小面积”或“高密度”为目标,尤其适用于模拟、射频、高压等模块。 | 面积由综合与布局布线(P&R)工具优化,目标是满足时序和拥塞约束下的合理面积。 |
| 模块划分 | 按功能单元精细划分(如运放、带隙、LDO),需考虑匹配、对称、共质心、梯度等模拟设计规则。 | 按逻辑功能模块划分(如CPU核、DMA、FIFO),由综合工具生成网表后自动划分。 |
| 设计周期 | 周期长,依赖工程师经验,迭代频繁,通常为数周至数月。 | 周期较短,高度自动化,主要依赖EDA工具流程,通常为数天至数周。 |
2. 版图设计实现
| 维度 | 全定制设计 | 半定制设计 |
|---|---|---|
| 设计方式 | 手动绘制晶体管级版图,精确控制器件形状、尺寸、位置、方向和互连。 | 使用标准单元库(Standard Cell Library)进行自动布局布线(Place & Route)。 |
| 工具 | Cadence Virtuoso、Synopsys Custom Compiler、Mentor Pyxis 等交互式版图编辑器。 | Synopsys ICC/ICC2、Cadence Innovus、Mentor Olympus-SoC 等自动化P&R工具。 |
| 灵活性 | 极高,可自由设计L型、U型、多指(multi-finger)晶体管,实现共质心、共边等匹配结构。 | 有限,只能使用预定义的标准单元,无法修改内部结构(如晶体管W/L)。 |
3. 版图GDS数据输出
| 维度 | 全定制设计 | 半定制设计 |
|---|---|---|
| 数据生成 | 通过版图工具直接导出GDSII或OASIS格式,包含所有手动绘制的几何图形。 | 由P&R工具生成GDSII,包含标准单元实例、自动布线金属层、填充(fill)等。 |
| 内容 | 包括晶体管、电阻、电容、电感、互连、匹配结构、保护环等。 | 主要是标准单元、电源环/条、自动布线网络、冗余填充(dummy fill)。 |
4. 版图设计规则检查(DRC)
| 维度 | 全定制设计 | 半定制设计 |
|---|---|---|
| 检查重点 | 更关注模拟规则:匹配间距、密度规则、天线规则、金属不对称、多晶对齐等。 | 主要检查数字规则:最小线宽/间距、通孔规则、电源环宽度、拥塞等。 |
| 工具 | Calibre、PVS、Assura 等,常需自定义DRC规则脚本。 | 同样使用Calibre等工具,但规则脚本通常由PDK提供,针对数字流程优化。 |
| 迭代次数 | 多,因手动设计易违反规则,需反复调整。 | 较少,工具具备自动修复(DRC fixing)能力。 |
5. 版图与电路等价性检查(LVS)
| 维度 | 全定制设计 | 半定制设计 |
|---|---|---|
| 复杂性 | 高,需处理非标准器件(如MOS电容、多晶电阻)、子电路匹配、端口映射、参数提取(W/L)。 | 相对简单,标准单元有预定义的LVS规则,工具自动匹配。 |
| 挑战 | 需手动定义器件属性、连接关系,易因命名或连接错误导致LVS失败。 | 主要依赖网表一致性,工具自动化程度高,LVS通过率高。 |
6. 版图寄生参数提取(PEX / RC Extraction)
| 维度 | 全定制设计 | 半定制设计 |
|---|---|---|
| 提取精度要求 | 极高,需提取电阻(R)、电容(C)、电感(L),支持全3D场求解器(如StarRC、Quantus)。 | 通常提取耦合电容(crosstalk)、net resistance、clock skew,用于静态时序分析(STA)。 |
| 用途 | 生成带寄生参数的SPICE网表,用于高精度仿真(AC、Transient、Monte Carlo等)。 | 生成SPEF(Standard Parasitic Exchange Format)文件,用于时序分析(PrimeTime)。 |
| 仿真验证 | 需进行电路仿真(如Spectre、HSPICE)验证功能、增益、带宽、噪声、PSRR等性能指标。 | 主要进行静态时序分析(STA) 和 功耗分析,功能正确性由前端验证保证。 |
总结对比表
| 项目 | 全定制版图设计 | 半定制后端设计 |
|---|---|---|
| 设计对象 | 模拟、混合信号、射频、存储器单元、定制数字模块 | 数字逻辑电路(CPU、GPU、SoC等) |
| 设计方式 | 手动布局布线 | 自动布局布线(APR) |
| 自动化程度 | 低,依赖工程师经验 | 高,依赖EDA工具 |
| 灵活性 | 极高,可自由设计器件 | 低,受限于标准单元库 |
| 精度要求 | 高,需考虑匹配、寄生、噪声 | 中等,关注时序、功耗、面积(PPA) |
| 主要工具 | Virtuoso, Custom Compiler, Calibre | Innovus, ICC, Genus, PrimeTime |
| 典型应用 | ADC/DAC、LDO、PLL、Bandgap、SRAM bitcell | 数字ASIC、SoC、FPGA后端 |
✅ 结论
- 全定制设计:适用于对性能、功耗、面积、匹配、噪声敏感的模块,追求极致优化,但设计周期长、成本高、依赖专家经验。
- 半定制设计:适用于大规模数字电路,强调设计效率、可重用性和自动化,适合快速迭代和量产。
在现代SoC设计中,通常是混合流程:
- 模拟/混合信号模块采用全定制设计,
- 数字逻辑部分采用半定制后端流程,
- 最终通过顶层集成完成整个芯片的物理实现。