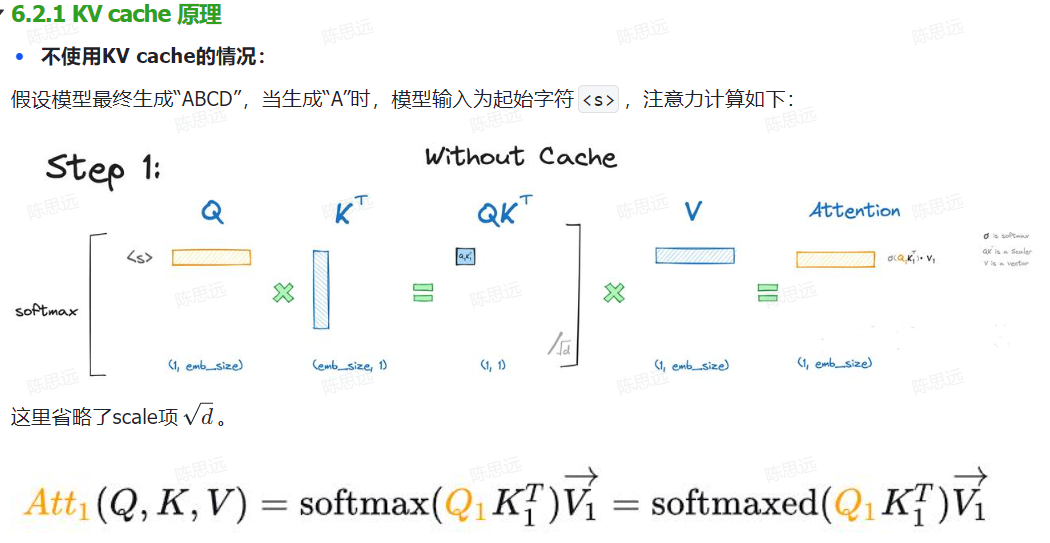
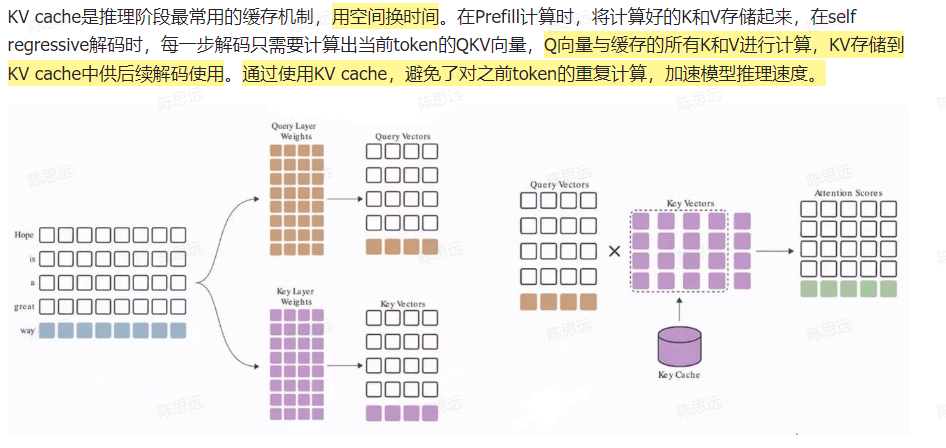
KV cache
键值缓存 (KV) 发生在多个 token 生成步骤中,并且仅发生在解码器中(例如,在 GPT 等仅解码器模型中,或在 T5 等编码器-解码器模型的解码器部分中)。BERT 等模型不是生成式的,因此没有键值缓存。
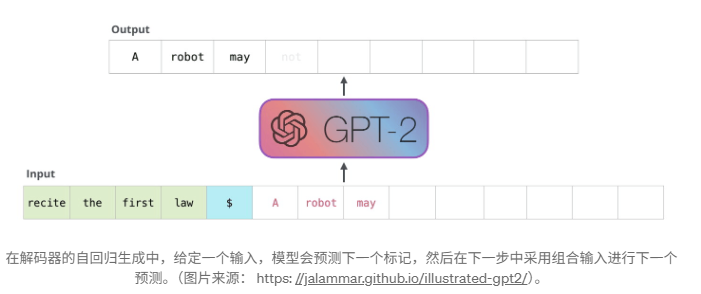
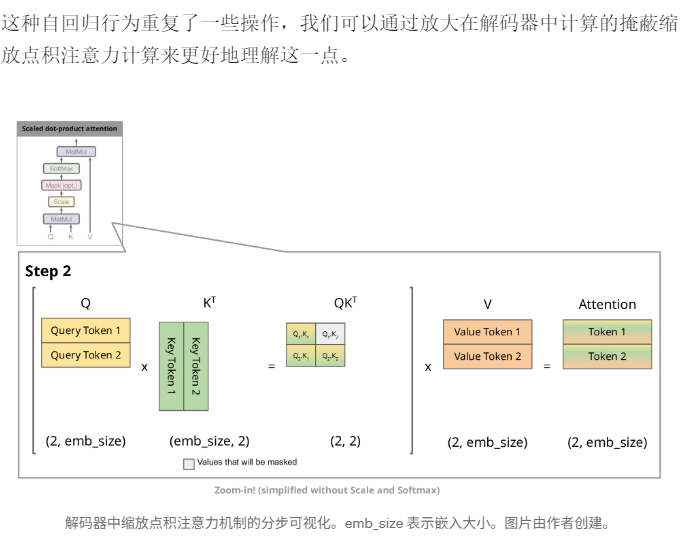
由于解码器是因果的(即,一个标记的注意力仅取决于其前面的标记),因此在每个生成步骤中,我们都在重新计算相同的先前标记的注意力,而实际上我们只是想计算新标记的注意力。
这就是键值对 (KV) 发挥作用的地方。通过缓存之前的键和值,我们可以专注于计算新 token 的注意力。
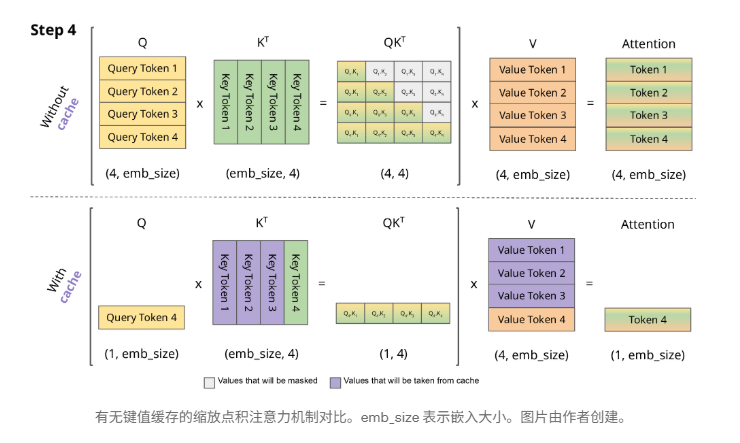
为什么这种优化重要吗?如上图所示,使用键值缓存获得的矩阵要小得多,从而可以加快矩阵乘法的速度。唯一的缺点是它需要更多的 GPU 显存(如果不使用 GPU,则需要更多的 CPU 显存)来缓存键和值的状态。