视觉语言导航(4)——强化学习的三种方法 与 优化算法 2.43.4
之前已经讲过监督学习、无监督学习
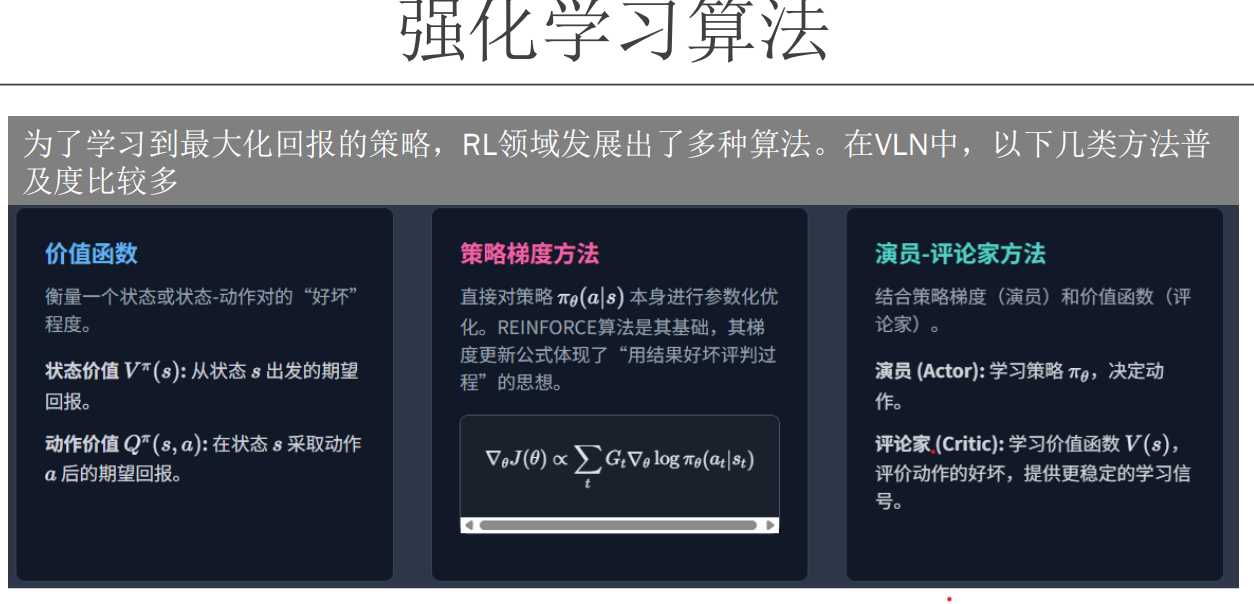
监督学习的目标是找到函数拟合数据,无监督学习的目标是学习数据的规律和结构(聚类),强化学习则是最大化奖励。
本质上,监督学习和无监督学习都是在静态的环境下学习的,也就是输出不会对环境(数据)造成影响,而强化学习则是在动态环境中通过与环境交互获得最大化奖励,也就是说,强化学习的输出会影响环境,影响下一次决策,这就是它与前两者不同之处。
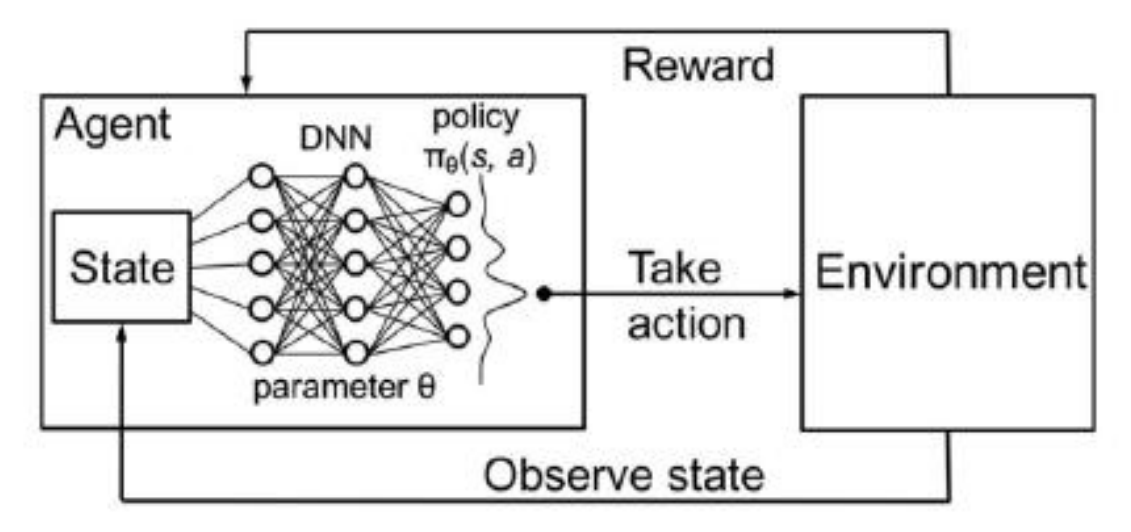
强化学习的基本框架包括智能体(agent)、环境(environment)、状态(state)、动作(action)和奖励(reward)。
在强化学习中,数据通常表示为状态-动作对(state-action pairs),即在某个状态下采取某个动作。我们的目标是在多个时间步上最大化累积奖励(cumulative rewards)。
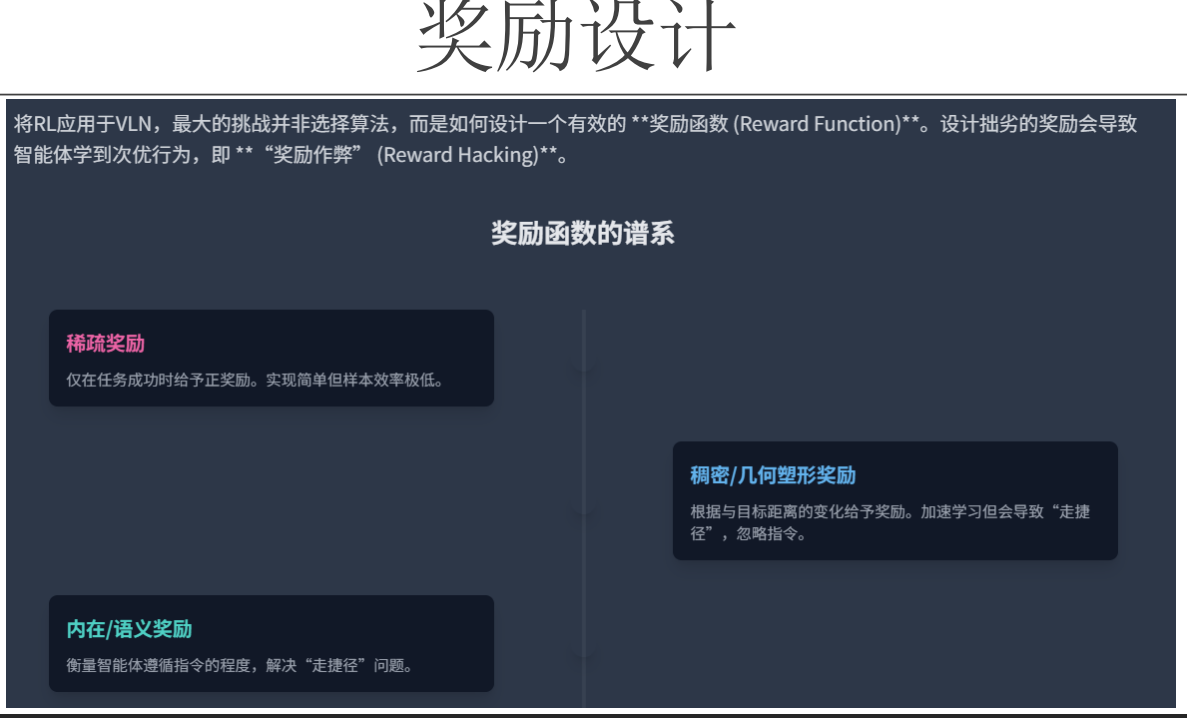
奖励函数的设计



策略网络
智能体需要通过与环境的交互来学习最优的行为策略。而策略网络正是实现这一目标的关键组件之一。它是一种神经网络模型,用于根据当前的状态输出一个动作的概率分布,从而指导智能体采取相应的行动。
输入层接收环境的状态信息,经过隐藏层的计算和变换后,最终在输出层生成各个可能动作的概率值。
尽管策略网络主要用于强化学习,但它在训练过程中也借鉴了监督学习的思想。具体来说,在策略网络的训练过程中,我们同样需要通过前向传播和反向传播来更新网络的参数。
在前向传播阶段,策略网络根据当前的状态计算出各个动作的概率值;
而在反向传播阶段,我们则需要根据智能体的实际表现(即获得的奖励)来调整网络的参数,以优化其决策能力。

没有标志答案的情况下如何计算误差?
这个 0 -1.0 是怎么来的?
- 智能体从两个动作中采样了 动作1
- 执行后得到了奖励 R=−1.0(负奖励,表示这个动作不好)
- 我们希望 降低 未来选择这个动作的概率
- 所以我们要 减少 动作1的 log probability(对数概率)
- 因此,对 logp 的梯度是 -1.0(表示要往负方向调整)
- 而动作0没被选,所以它的 logp 不需要调整 → 梯度为 0
上面是单个动作,如果是动作链呢?
折扣因子(Discount Factor) 和 回报(Return)
🎮 场景:你玩《贪吃蛇》
你的目标是吃到苹果,活下来,越长越好。
假设你玩了一局,一共走了 5 步,最后得分 +10。
这 5 步是:
| 步数 | 动作 | 结果 |
|---|---|---|
| 1 | 向右 | 避开墙 |
| 2 | 向下 | 靠近苹果 |
| 3 | 向右 | 吃到苹果!🍎 |
| 4 | 向上 | 正常移动 |
| 5 | 向左 | 游戏结束,+10 分 |
现在问题来了:
❓ 这 +10 分,该怎么分给这 5 步?
- 第 3 步吃到苹果,功劳最大?
- 但第 1 步没撞墙,也很关键?
- 第 2 步靠近苹果,是“铺垫”?
这就用到了 折扣因子 γ(gamma)
💡 折扣因子 γ:越远的奖励,影响越小
我们设定一个 γ,比如 γ = 0.9,
我们从后往前算,给每一步一个“未来收益的估计值”,叫 回报(Return)
我们来算每一步的“回报”(Discounted Return)
假设每一步的即时奖励是:
- 吃到苹果:+1
- 其他:0
- 最后总分:+10(我们简化成每步的累计)
| 步数 | 即时奖励 rₜ | 折扣回报 Gₜ = rₜ₊₁ + γ·rₜ₊₂ + γ²·rₜ₊₃ + ... |
|---|---|---|
| 1 | 0 | 0 + 0.9×0 + 0.9²×1 + 0.9³×0 + 0.9⁴×0 = 0.81 |
| 2 | 0 | 0 + 0.9×1 + 0.9²×0 + 0.9³×0 = 0.9 |
| 3 | 1 | 1 + 0.9×0 + 0.9²×0 = 1.0 |
| 4 | 0 | 0 + 0.9×0 = 0 |
| 5 | 0 | 0(游戏结束) |
✅ 注意:我们是从后往前算的,每一步的 Gₜ 是它之后所有奖励的“打折总和”
我们用这个 Gₜ 当作“梯度信号”
| 步数 | 动作 | Gₜ(折扣回报) | 如何更新策略 |
|---|---|---|---|
| 1 | 向右 | 0.81 | 稍微鼓励:“你第一步走得好,保持” |
| 2 | 向下 | 0.9 | 更鼓励:“你靠近苹果,干得不错” |
| 3 | 向右 | 1.0 | 大力鼓励:“你吃到苹果了!多这么干!” |
| 4 | 向上 | 0 | 不鼓励也不惩罚 |
| 5 | 向左 | 0 | 不更新 |
👉 这就是 REINFORCE 算法 的完整逻辑:
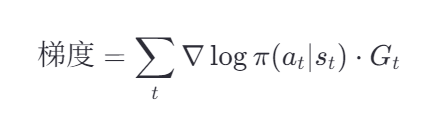
策略梯度(Policy Gradient)
梯度信号是:策略网络输出的 log概率 对网络参数 θ 的梯度,再乘以奖励 G_t
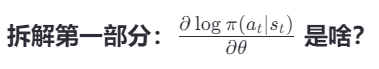
要使at这个动作概率增大,θ应该怎么调。
✅ 举个例子:
- 状态:你看到一个苹果
- 动作:向右移动
- 当前网络输出:向右的概率是 60%
- ∂logπ∂θ∂θ∂logπ 告诉你:
“如果你想让‘向右’的概率变大,就把权重 W2W2 增加一点点”

真正决定θ增加减少的
- Gt>0:好结果 → 应该鼓励这个动作
- Gt<0:坏结果 → 应该惩罚这个动作
它只关心结果,不关心“怎么调参数”。
✅ 比如:
- 你向右移动 → 吃到苹果 → Gt=+1.0 → 鼓励
- 你向右移动 → 撞墙 → Gt=−1.0 → 惩罚
综上,
- 导航系统:告诉你“往北是上坡”(增大θ可以增加at的概率)
- 目的地:你说“我要去南方”(计算得到这个动作的Gt是负的,想要更多奖励就要反着走)
- 结果:你选择“往南下坡”(减小θ)


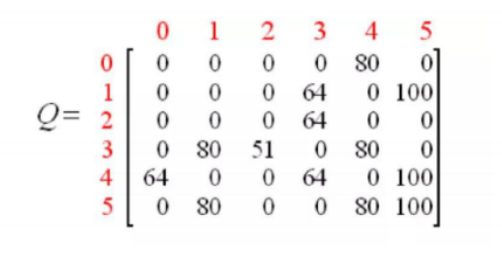
Q-LEARNING
Q-Learning是一种无模型的强化学习算法,它旨在学习一个策略,该策略告诉智能体在给定的状态下应该采取什么行动。Q-Learning的核心是学习一个动作价值函数 Q(s,a),它代表当处于状态 ss 时执行动作 aa 所能得到的长期回报的期望值。
这个算法不需要一个环境模型,并且可以处理随机性的问题。
举例:
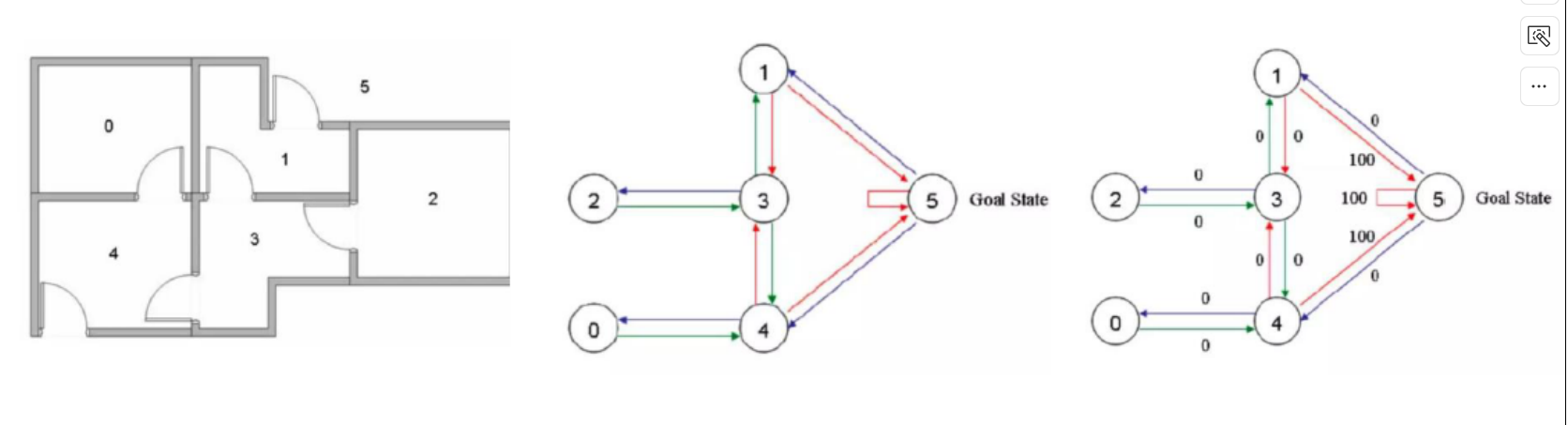
- 如果机器人能够离开房子,则视为成功;到达点5(房间外)的奖励设置为100,否则设置为0,不可达路径设为-1
- 状态:当前在哪个房间
- 动作:从哪个房间到哪个房间
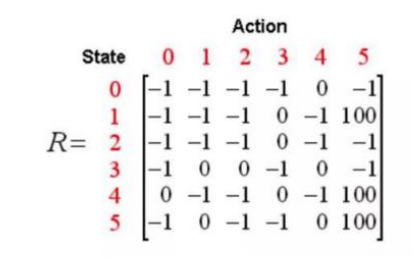
奖励矩阵(R矩阵)
在Q-Learning中,奖励矩阵(R矩阵)定义了智能体在特定状态下执行某个动作后立即获得的奖励。这个矩阵通常是根据问题的具体情况手工设计的。每个元素 R(s,a) 表示在状态 s 下执行动作 a 后得到的即时奖励。
根据规则可以得到:
如果机器人能够离开房子,则视为成功;到达点5(房间外)的奖励设置为100,否则设置为0,不可达路径设为-1
初始Q表的设置
Q表是一个二维数组,其中行表示不同的状态,列表示可采取的动作。Q表中的每一个元素 Q(s,a) 存储的是在状态 s 下采取动作 a 的预期累积奖励。在学习过程开始之前,我们通常将Q表初始化为0或较小的随机数,以避免任何预先存在的偏好影响学习过程。
State\Actions | Action 0 | Action 1 | Action 2 | Action 3
-----------------------------------------------------------
State 0 | 0 | 0 | 0 | 0
State 1 | 0 | 0 | 0 | 0
State 2 | 0 | 0 | 0 | 0
State 3 | 0 | 0 | 0 | 0
State 4 | 0 | 0 | 0 | 0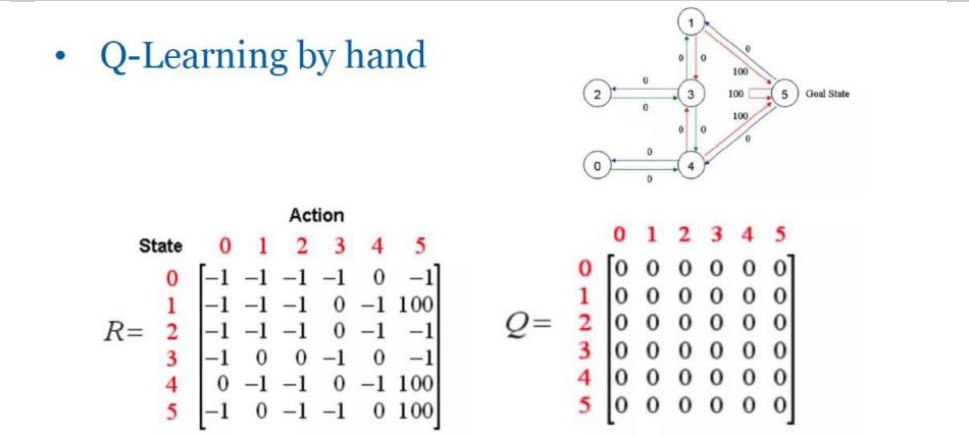
Q-Learning的核心更新公式
Q-Learning算法的核心在于Q值的更新公式(可能和书上不一样,别急):
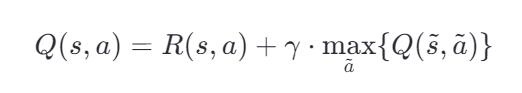
其中:

手动计算Q值更新的例子
假设我们处于状态2,采取了动作3(即从房间2移动到房间3),并且已知即时奖励矩阵 R 和当前的Q表如下所示:
即时奖励矩阵 R
| State | Action 0 | Action 1 | Action 2 | Action 3 | Action 4 | Action 5 |
|---|---|---|---|---|---|---|
| 0 | -1 | -1 | -1 | -1 | 0 | -1 |
| 1 | -1 | -1 | -1 | 0 | -1 | 100 |
| 2 | -1 | -1 | -1 | 0 | -1 | -1 |
| 3 | -1 | 0 | 0 | -1 | 0 | -1 |
| 4 | 0 | -1 | -1 | 0 | -1 | 100 |
| 5 | -1 | 0 | -1 | -1 | 0 | 100 |
当前Q表
| State | Action 0 | Action 1 | Action 2 | Action 3 | Action 4 | Action 5 |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 |
假设折扣因子 γ=0.8,我们现在要更新Q(2, 3)的值。
- 计算即时奖励:根据即时奖励矩阵 R,我们可以看到 R(2,3)=0。
- 找到下一个状态的最大Q值:采取动作3后,我们到达状态3。我们需要查看Q表中状态3的所有可能动作对应的Q值,并找出最大值。目前Q表中所有值都是0,所以 maxa~{Q(3,a~)}=0
- 应用Q值更新公式:
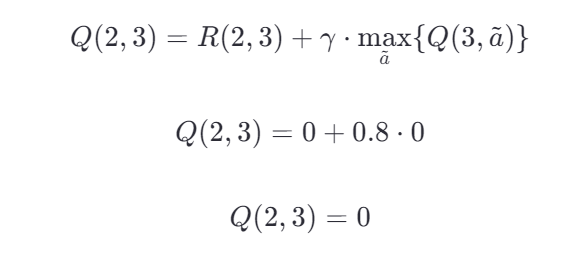
在这个例子中,由于我们刚开始训练,Q表中的值都为0,因此更新后的Q(2, 3)仍然是0。随着更多的训练迭代,Q表中的值会逐渐被更新,从而更好地反映每个状态-动作对的价值。
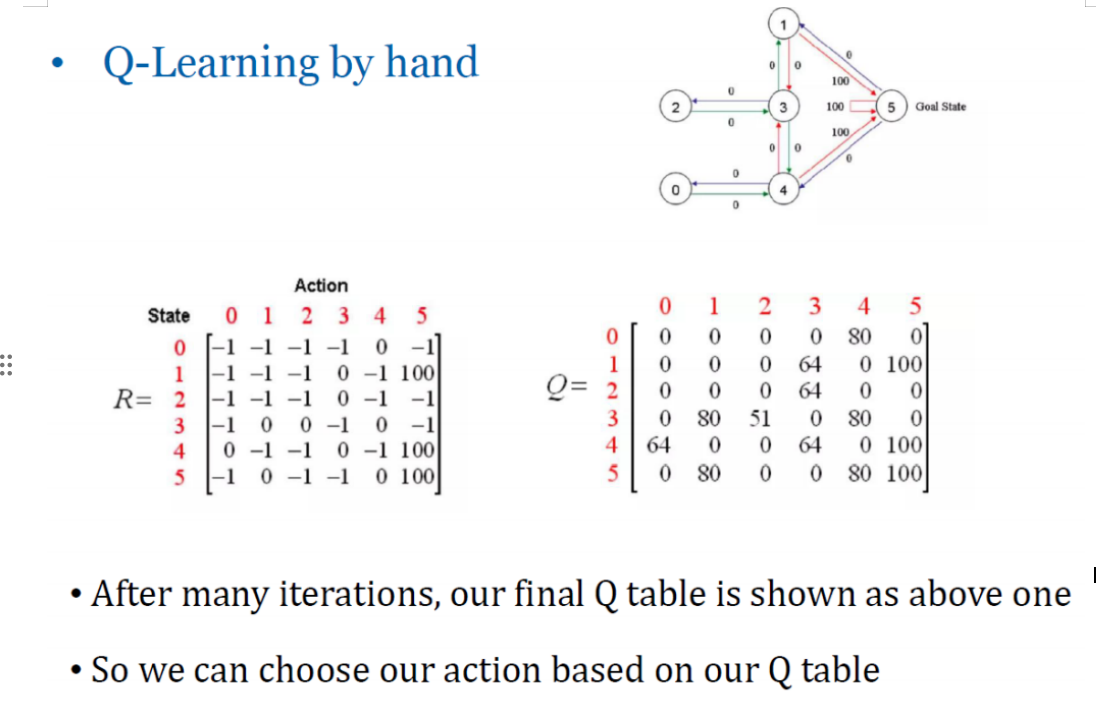
理论上,在经过足够多的训练和探索之后,Q表中的每一个位置(即每个状态-动作对)都会被更新到接近其最优值。之后无论机器人在哪都能查表决策。
接下来解决为什么这个更新公式和书上不一样的问题
贝尔曼方程——“一个动作的价值 = 即时奖励 + 未来最大价值的折扣版”
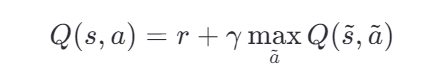 -----①
-----①
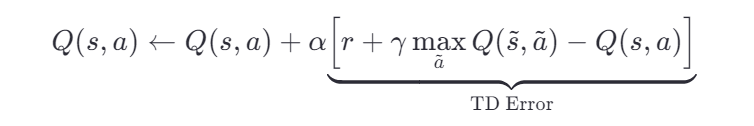 -----②
-----②
①式这是理想情况下的等式,就像“正确答案”。
但在实际训练中,我们的 Q 值是估计值,不准确。所以我们不能直接“等于”,而要慢慢靠近这个目标。
因此在实际计算的时候我们使用的是②式。

经过多次迭代后,Q值会逐步逼近真实的方程,也就是②式经过多轮迭代后会更新为①式。
我们举例:
场景设定:机器人找宝藏(实则和上面一样走出房间)
想象有一个机器人在一个小迷宫里,有 6 个房间(状态 0~5),目标是找到藏在房间 5 的宝藏。
- 房间之间有门可以走
- 走错会2887(小惩罚)
- 走对能靠近宝藏
- 到达房间 5 → 拿到宝藏(大奖励)
我们的任务:教机器人学会“从任意房间出发,怎么最快走到房间 5”
🧩 第一步:定义“奖励规则”——我们人为设定 R(s,a)R(s,a)
我们先设计一个即时奖励矩阵 R,告诉机器人:
| 动作结果 | 奖励 |
|---|---|
| 走向宝藏房间 | +100 |
| 走向死路/墙 | -1 |
| 正常移动 | 0 |
比如:
- 从房间 1 走到房间 5 → R(1,5)=100
- 从房间 0 走到房间 4 → R(0,4)=0
- 从房间 0 想走到房间 1(没门)→ R(0,1)=−1
✅ 这个 R 矩阵是我们人为设定的,完全准确。
📊 第二步:初始化 Q 表——“机器人一无所知”
我们创建一个 Q 表,记录机器人对每个“状态+动作”的价值估计。
初始时,它啥也不知道,所以 Q 表全是 0:
| State | a=0 | a=1 | a=2 | a=3 | a=4 | a=5 |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 |
✅ Q(s,a) 当前只是“猜测”,不是真实价值
🔁 第三步:机器人开始探索(试错)
机器人从某个房间出发(比如房间 2),开始乱走:
🎲 第一次尝试:2 → 3 → 1 → 5(成功!)
| 步骤 | 当前状态 s | 动作 a | 下一状态 s' | 即时奖励 r | Q 更新 |
|---|---|---|---|---|---|
| 1 | 2 | 3 | 3 | 0 | 更新 Q(2,3) |
| 2 | 3 | 1 | 1 | 0 | 更新 Q(3,1) |
| 3 | 1 | 5 | 5 | 100 | 更新 Q(1,5) |
🧮 第四步:用 Q-Learning 公式更新 Q 值
使用公式:
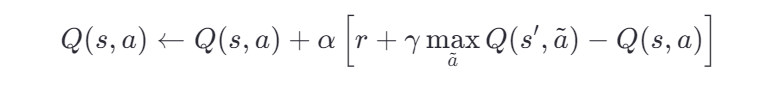
假设:
- 学习率 α=0.1
- 折扣因子 γ=0.9
我们从后往前更新(因为最后一步最确定):
🔺 更新第3步:Q(1,5)

达到5已经找到了宝藏,因此未来收益为0:
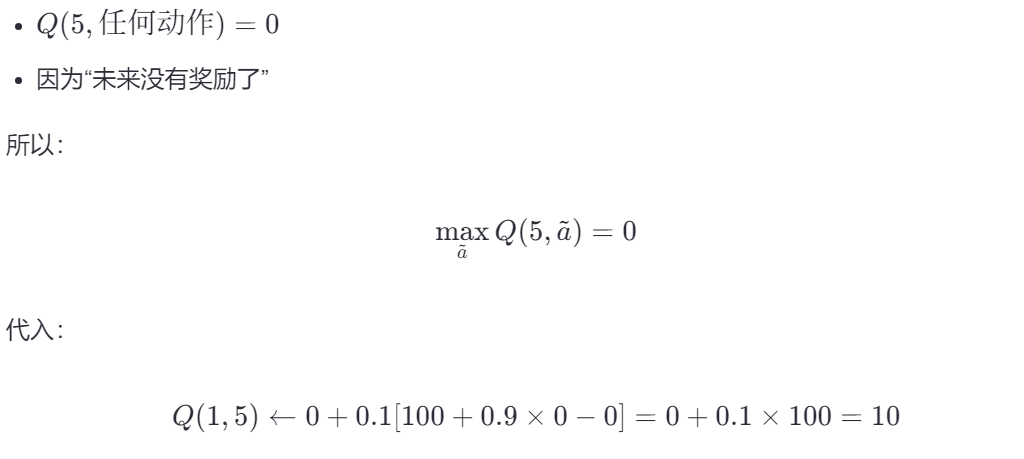
🔺 更新第2步:Q(3,1)

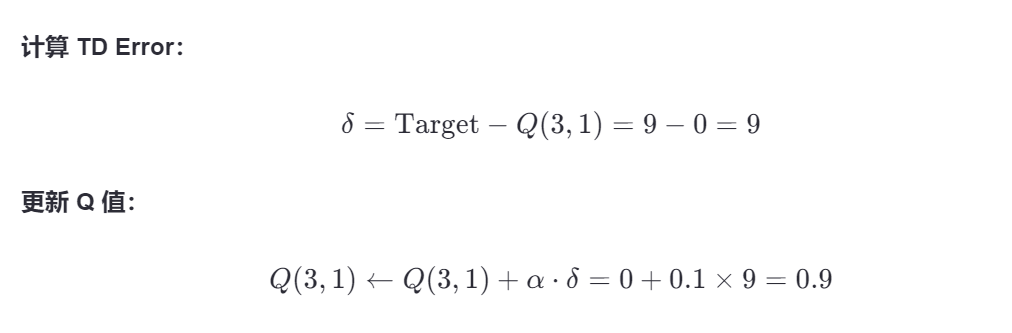
🔺 更新第1步:Q(2,3)

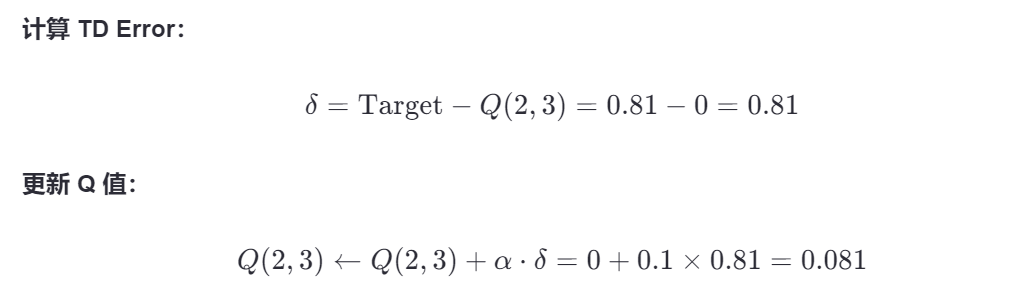
此时Q表这三个位置被更新:
| State | a=0 | a=1 | a=2 | a=3 | a=4 | a=5 |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 10 |
| 2 | 0 | 0 | 0 | 0.081 | 0 | 0 |
| 3 | 0 | 0.9 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 |
以上就是真实情况下的一次更新,第二次更新有两种选择:
机器人怎么决定下一步?——利用OR探索
| 策略 | 概率 | 行为 |
|---|---|---|
| 利用(Exploitation) | 1−ε | 查 Q 表,选当前 Q 值最大的动作 → 走“已知最优路径” |
| 探索(Exploration) | ε | 随机选一个动作 → 可能走新路、试错 |
其中 ε 是一个小数,比如 0.1 或 0.2。
决策过程:
- 随机生成一个数 p∈[0,1]
- 如果 p<0.2p<0.2 → 探索:随机选一个动作(比如 a=0,哪怕它Q值是0)
- 如果 p≥0.2p≥0.2 → 利用:查表,选 Q 值最大的动作(a=1 或 a=4)
利用是为了优化原先的路径,找找有没有更优的路径并更新原先路径的Q值。
ε 衰减——随着训练进行,策略会变化
通常我们会逐渐减小 ε:
| 训练阶段 | ε | 行为 |
|---|---|---|
| 早期 | 0.9 ~ 0.5 | 大部分时间乱走 → 快速探索环境 |
| 中期 | 0.3 ~ 0.1 | 偶尔探索, mostly 利用 → 精进策略 |
| 后期 | 0.05 ~ 0 | 几乎完全利用 → 稳定执行最优策略 |
这叫 ε 衰减(epsilon decay)
经过若干轮后,这张Q表就会更新得和答案一样了,同时②式也会和①式一样。
银浆-》锡焊浆
气流发声
有限元力学流体分析作为脚掌受力分析
如何学
第一遍流程+向量显示
第二遍向量+伪代码显示
Actor-Critic方法
AC都是网络,都需要训练。
AC 是“大脑的决策系统”,RCM 是“大脑的感知系统”。
在 VLN 等任务中,RCM 为 AC 提供“理解”,而 AC 基于这种理解做出“行动”。
它们不是替代关系,而是 “感知 → 决策” 的上下游协作关系。

增强交叉模态匹配 (RCM)
考虑内在和外在,目标+距离奖励+指令保真度

外在奖励——欧几里得距离
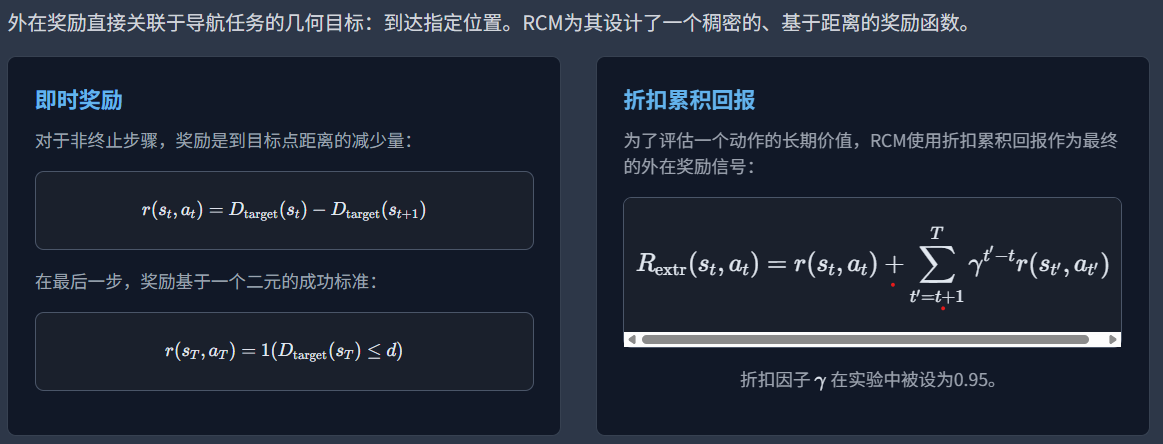

R外定义为当前操作的距离减少+往期的操作奖励衰减
内在奖励——用Speaker的输出匹配语义相似度

因此,内在奖励被定义为这个重构的成功概率。






训练流程是多阶段的:必须首先在专家数据上预训练评论家,然后才能用它来训练导航器 。
这不仅增加了工程上的复杂性和计算开销,更重要的是,导航器的最终性能上限被预训练评论家的质量所束缚。如果评论家本身对路径-指令的对齐判断能力不佳,它就会提供一个充满噪声甚至具有误导性的奖励信号,从而“毒化”导航器的学习过程。这种模块化的设计哲学虽然在当时很普遍,但它引入了潜在的性能瓶颈和显著的工程开销
双脑结构——AC方法和SF模型
混合模型


VLN-R1模型(分层型(HANNA))——扩大预测视野、减小积累误差
TDR时间衰减奖励函数
描述
智能体的行为序列在多大度上模仿了专家的行为序列。


VLN-R1流程——走向LLM-VLN(将图片文字化)
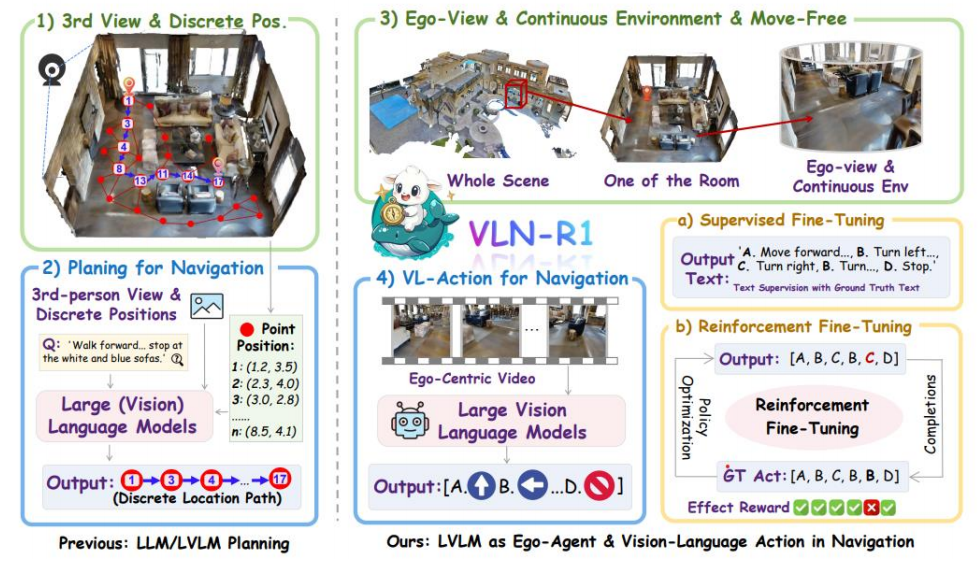
其中2)中的LVLM可以是CLIP(
视觉-语言翻译器
它能告诉你:
- 这张图“像”哪句话?
- 这句话“对应”哪类场景?
)
类比理解:LLM 是“盲人天才”,视觉编码器是“导盲犬”
- LLM:语言能力极强,但天生“看不见”
- 视觉编码器 + Projector:是它的“眼睛”和“翻译官”,把图像转成“语言描述”(token 序列)
- 最终输入:是“文字+图像描述”的混合文本,LLM 就能“看图说话”了
整个流程如何运行?(带张量示例)
我们用一个具体例子 + 张量表示来说明:
🎯 任务:
“Walk forward and stop at the white and blue sofas.”
🧭 第一层:高层规划(离散路径生成)
# 第三人称视角提取的可达点(n x 2)
waypoints = tensor([[1.2, 3.5], # p1: entrance[2.3, 4.0], # p2: table[3.0, 2.8], # p3: white sofa[4.1, 3.2], # p4: bookshelf[8.5, 4.1] # p17: blue sofa
]) # shape: [5, 2]# LVLM 输入:指令 + 所有点
prompt = f"""
Given the instruction: "{Q}"
Which sequence of waypoints leads to the correct destination?
Options: p1, p2, p3, p4, ..., p17
Answer: [p1 -> p3 -> p17]
"""# 高层输出:离散路径(token IDs)
high_level_path = [1, 3, 17] # 模型输出的 token 序列🎮 第二层:低层执行(动作生成)
# 当前状态:自身视角图像 + 当前位置 + 当前目标点
ego_image = get_current_view() # shape: [3, 224, 224]
current_pos = tensor([2.3, 4.0]) # p2: 当前在 table 附近
target_pos = tensor([3.0, 2.8]) # p3: 要去 white sofa# LVLM 输入上下文:
prompt = f"""
You are at position {current_pos}.
Your next goal is to reach {target_pos}.
Instruction: "{Q}"
Current view: [image]
What should you do? Choose from:
A. Move forward
B. Turn left
C. Turn right
D. Stop
Answer: A
"""# 低层输出:动作 token
action_logits = model(prompt) # shape: [vocab_size]
action = sample(action_logits) # e.g., 'A' → Move forward组相对优化GRPO
类似AC模型,其中LVLM是actor,TDR是critic,但是DTR不训练,仅仅作为打分标准,指导LVLM的行动。


TDR的设计反映了在拥有强大基础模型时代,奖励设计理念的根本性转变。VLN-R1所使用的LVLM是一个在海量数据上预训练过的巨模型,它本身已经内化了丰富的世界知识和语言理解能力 。因此,RFT阶段的目标不再是从零开始向模型“注入”关于“椅子”是什么或如何“左转”的知识。TDR奖励函数本身并不评估任何深层的语义一致性,它只衡量一件事:智能体的行为序列在多大程度上模仿了专家的行为序列。因此,TDR并非一种知识注入机制,而是一种精细的“行为微调”(behavioral nudging)工具。它利用强化学习的框架,温和地引导LVLM强大的生成能力,使其输出的动作序列在VLN这个特定任务上更具鲁棒性和时序连贯性。这标志着一种范式转变:当基础模型足够强大时,奖励设计的重点可以从构建复杂的、赋予知识的信号,转向设计更简单的、对齐行为的信号。繁重的认知工作由预训练完成,而强化学习则专注于“最后一公里”的专业化微调。(本节的主题“从认知走向决策”)
优化算法
优化算法《人工智能导论》课程已经讲过了,草草过一遍。
1. 优化的定义
优化是指从一组可能的解决方案中找到最佳解的过程,通常是在给定一系列约束条件或目标的情况下进行。在数学上,这通常表现为寻找一个函数的最大值或最小值。
2. 目标函数(Objective Function)
- 评估解的质量:目标函数用于衡量一个解的好坏。
- 机器学习中的应用:在机器学习中,我们通常需要优化一个目标函数来找到模型的最佳参数。这个目标函数通常是损失函数(Loss Function),它衡量了模型预测输出与实际输出之间的误差。
- 目标:通过调整模型参数来最小化损失函数。
3. 优化问题的分类
a. 确定性算法(Deterministic Algorithms)
这类算法在每次运行时都会产生相同的结果,它们依赖于精确的数学计算和规则。常见的确定性优化算法包括:
- 线性规划(Linear Programming):解决线性目标函数和线性约束条件下的优化问题。
- 二次规划(Quadratic Programming):解决包含二次项的目标函数和线性约束条件下的优化问题。
- 梯度下降(Gradient Descent):一种迭代算法,通过计算目标函数的梯度并沿着梯度的反方向更新参数来最小化目标函数。
b. 随机算法(Stochastic Algorithms)
这类算法在每次运行时可能会产生不同的结果,它们引入了随机性以探索解空间的不同部分。常见的随机优化算法包括:
- 进化算法(Evolutionary Algorithms):模拟自然选择和遗传机制,通过变异、交叉和选择等操作来搜索最优解。
- 模拟退火(Simulated Annealing):模拟金属退火过程,允许算法在一定概率下接受较差的解,从而避免陷入局部最优。
- 粒子群优化(Particle Swarm Optimization, PSO):模拟鸟群觅食行为,通过群体智能来搜索最优解。
搜索算法
优化算法也在《人工智能导论》课程已经讲过了,草草过一遍。
1. 定义
搜索是指探索可能解空间的过程,以找到满足一组约束条件或目标的最优解。在不同的领域中,搜索问题可以表现为多种形式:
- 路径寻找(Pathfinding):在地图或基于网格的环境中找到从一个位置到另一个位置的最短路径。
- 游戏AI(Game AI):在棋盘游戏、谜题或策略游戏中探索可能的游戏状态或移动。
- 决策树中的搜索(Search in Decision Trees):遍历决策树以在不确定环境中做出最优决策。
2. 常用搜索技术
a. 深度优先搜索(Depth-First Search, DFS)
- 原理:尽可能深地沿着每个分支进行搜索,直到达到叶节点或遇到死胡同,然后回溯。
- 特点:使用较少的内存,但可能会陷入无限循环(如果图中有环)。
- 应用场景:适用于需要完整遍历所有可能路径的情况,如迷宫求解。
b. 广度优先搜索(Breadth-First Search, BFS)
- 原理:逐层扩展节点,先访问离起始节点最近的所有节点,再访问稍远的节点。
- 特点:保证找到最短路径(对于无权图),但需要较多内存。
- 应用场景:适用于寻找最短路径的问题,如社交网络中的“六度分离”问题。
c. A搜索算法(A Search Algorithm)
- 原理:结合了最佳优先搜索和Dijkstra算法的思想,通过启发式函数估计从当前节点到目标节点的成本。
- 特点:在有启发式信息的情况下,能够高效地找到最优路径。
- 应用场景:广泛应用于路径规划、游戏AI等领域。
d. 遗传算法(Genetic Algorithms)
- 原理:模拟自然选择和遗传机制,通过变异、交叉和选择等操作来搜索最优解。
- 特点:适用于大规模、复杂且难以用传统方法解决的问题。
- 应用场景:优化设计、机器学习参数调优等。
文本生成中的采样方法
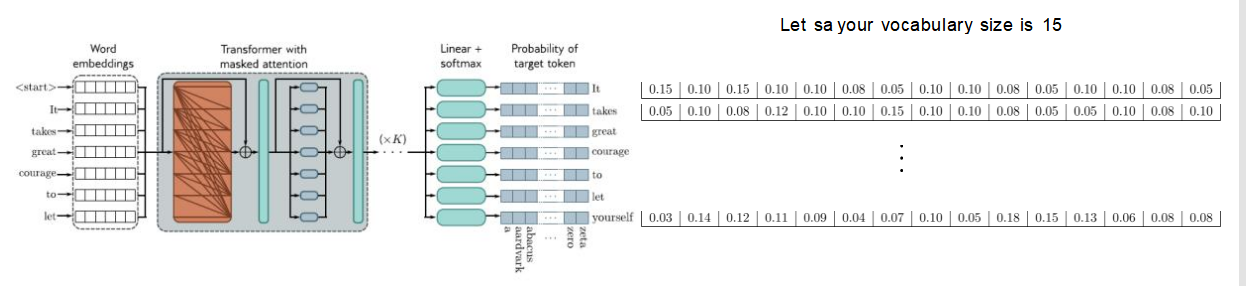
1. 背景
在文本生成任务中,模型通常会输出一个词的概率分布,表示下一个词的可能性。如何从这个概率分布中选择一个词作为输出,就是采样方法的核心问题。
2. 示例分析
假设词汇表大小为15,模型输出的概率分布如下:
| Word | Probability |
|---|---|
| It | 0.15 |
| takes | 0.10 |
| great | 0.12 |
| courage | 0.10 |
| to | 0.08 |
| let | 0.05 |
| yourself | 0.03 |
| ... | ... |
3. 常见采样方法
a. 贪婪采样(Greedy Sampling)
- 原理:每次选择概率最高的词作为输出。
- 特点:简单直接,但可能导致生成的文本缺乏多样性。
- 示例:每次都选"It"(概率最高)。
b. 随机采样(Random Sampling)
- 原理:根据概率分布随机选择一个词作为输出。
- 特点:增加了文本的多样性,但可能会生成低概率的不合理词。
- 示例:按照上述概率分布随机选择一个词。
c. Top-K 采样
- 原理:只考虑概率最高的K个词,从中随机选择一个词作为输出。
- 特点:平衡了多样性和合理性,避免了低概率词的影响。
- 示例:只考虑"It", "takes", "great"(假设K=3),从中随机选择一个词。
d. 温度采样(Temperature Sampling)
- 原理:通过调整概率分布的“温度”参数,控制采样的多样性。
- 特点:温度越高,概率分布越平滑,采样越随机;温度越低,概率分布越尖锐,采样越偏向高概率词。
- 公式:
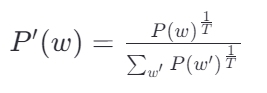
- 示例:当温度T=1时,概率分布不变;当T>1时,概率分布变平滑;当T<1时,概率分布变尖锐。
d. 束搜索
束搜索是一种用于序列生成任务的搜索算法,它在每个生成步骤中保留最有可能的k个序列,并通过考虑每个序列的k个最有可能的下一个词来扩展这些序列。
2. 工作流程
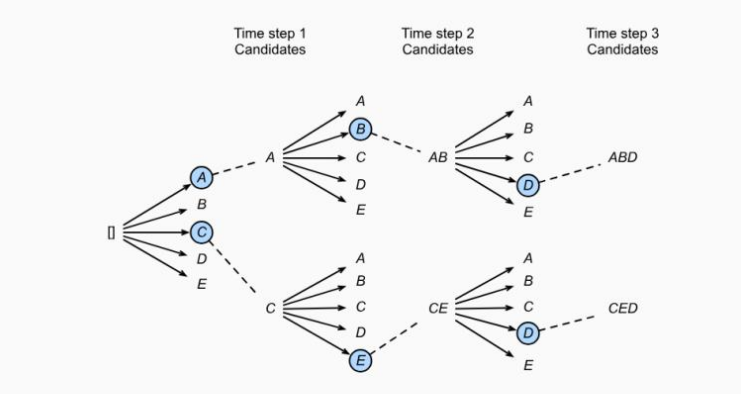
a. 初始化
- 在时间步0,只有一个空序列作为候选序列。
b. 扩展候选序列
- 在每个时间步t,对于当前的每个候选序列,根据模型预测的概率分布,选择k个最有可能的下一个词。
- 将每个候选序列与这k个词组合,形成新的候选序列。
c. 选择最佳序列
- 从所有新生成的候选序列中,选择概率最高的k个序列作为下一时间步的候选序列。
- 这些序列将被用于下一步的扩展。
d. 终止条件
- 当达到最大序列长度或所有候选序列都结束时,选择最终概率最高的序列作为输出。
优化中的挑战
1. 局部最小值(Local Minima)
a. 定义与影响
- 定义:在优化过程中,目标函数可能存在多个局部最小值点,这些点的函数值小于其邻域内的所有点,但不一定是最小。
- 影响:对于深度学习模型,目标函数通常非常复杂,包含大量的局部最小值。优化算法可能会陷入这些局部最小值,导致无法找到全局最优解。
b. 应对策略
- 引入噪声:通过在梯度下降过程中引入一定程度的噪声(如使用小批量随机梯度下降,mini-batch SGD),可以使参数跳出局部最小值,继续向全局最优解靠近。
- 动量方法:利用动量项加速收敛过程,帮助算法更快地越过局部最小值区域。
2. 鞍点(Saddle Points)
a. 定义与特点
- 定义:在某些点上,梯度为零,但这些点既不是局部最小值也不是局部最大值。在高维空间中,鞍点比局部最小值更常见。
- 特点:在鞍点处,函数值在某些方向上是增加的,在另一些方向上是减少的。
b. 应对策略
- 自适应学习率:使用自适应学习率的方法(如Adam、RMSprop等),可以自动调整每个参数的学习率,帮助算法更快地越过鞍点。
- 二阶优化方法:利用二阶导数信息(Hessian矩阵),可以更准确地判断当前点的性质,避免在鞍点处停滞不前。
3. 梯度消失(Vanishing Gradients)
a. 定义与原因
- 定义:在训练深度神经网络时,梯度在反向传播过程中逐渐减小,导致优化过程停滞不前,难以更新深层参数。
- 原因:激活函数的选择、权重初始化不当等因素都可能导致梯度消失问题。
b. 应对策略
- 选择合适的激活函数:使用ReLU及其变种(如Leaky ReLU、PReLU等)作为激活函数,可以有效缓解梯度消失问题。
- 权重初始化:采用合理的权重初始化方法(如Xavier初始化、He初始化等),可以使初始梯度保持在合理范围内。
- 残差连接(Residual Connections):在深层网络中引入残差连接,可以绕过某些层直接传递梯度,帮助优化过程顺利进行。
解决方法
凸性(凸函数/碗函数)的利用
想象一下你有一个碗和一个球。如果你把球放在碗里,无论你怎么放,球总是会滚到碗的最低点。这个最低点就是全局唯一的“最优点”,因为没有其他更低的地方可以去。这就像是一个凸函数的样子——它只有一个最低点,任何地方开始下滑,最终都会到达同一个最低点。
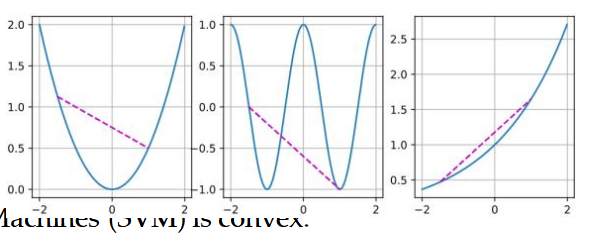
- 凸性意味着一个问题或者函数有一个单一的、最好的解决方案,即全局最小值。
- 避免陷入局部最优:在非凸问题中,优化算法可能会被困在一个局部最优解中,而不是全局最优解。而在凸问题中,这种情况不会发生,因为只有一个全局最优解。
- 简化求解过程:对于凸问题,我们有更多的理论工具和算法保证能够有效地找到最优解,使得求解过程更加直接和可靠。
动态学习率
衰减

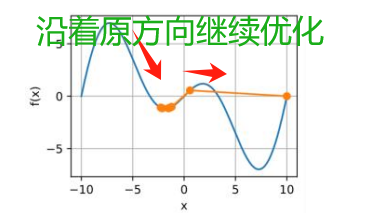
动量法(惯性使得优化仍沿着原先导数的方向前进一段距离)


自适应梯度下降(人工智能导论也讲了)


根均方传播(RMSprop)


Adadelta


Adam优化器


