私有化部署本地大模型+function Calling+本地数据库
目录
什么是function Calling?
为什么有function calling?
实现过程
项目背景
运行本地模型
代码
执行结果
思考
什么是function Calling?
Function Calling 是大型语言模型(LLM)连接外部工具和系统的核心技术,通过结构化参数生成实现模型与真实世界交互的能力。
为什么有function calling?
弥补大模型时效性与实时性不足:大模型训练数据存在时间滞后性(如训练时间是2023年,但是2023年后的数据没有),通过Function Calling可动态调用外部API(如天气、股价接口)获取最新信息
实现过程
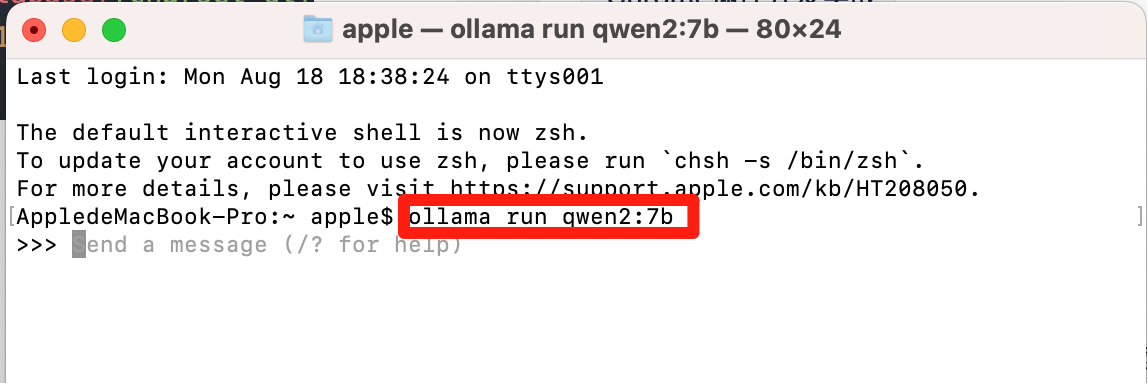
1、使用ollama运行qwen2:7b,启动本地大模型。
2、使用qwen_agent执行function Calling
from qwen_agent.tools.base import BaseTool, register_tool
@register_tool('exc_sql') # <-- 使用 register_tool 装饰器
3、连接本地数据库
database = args.get('database', 'bjgk')# 创建数据库连接engine = create_engine(f'mysql+pymysql://root:xxxxxx@localhost:3306/{database}?charset=utf8mb4',connect_args={'connect_timeout': 10}, pool_size=10, max_overflow=20)项目背景
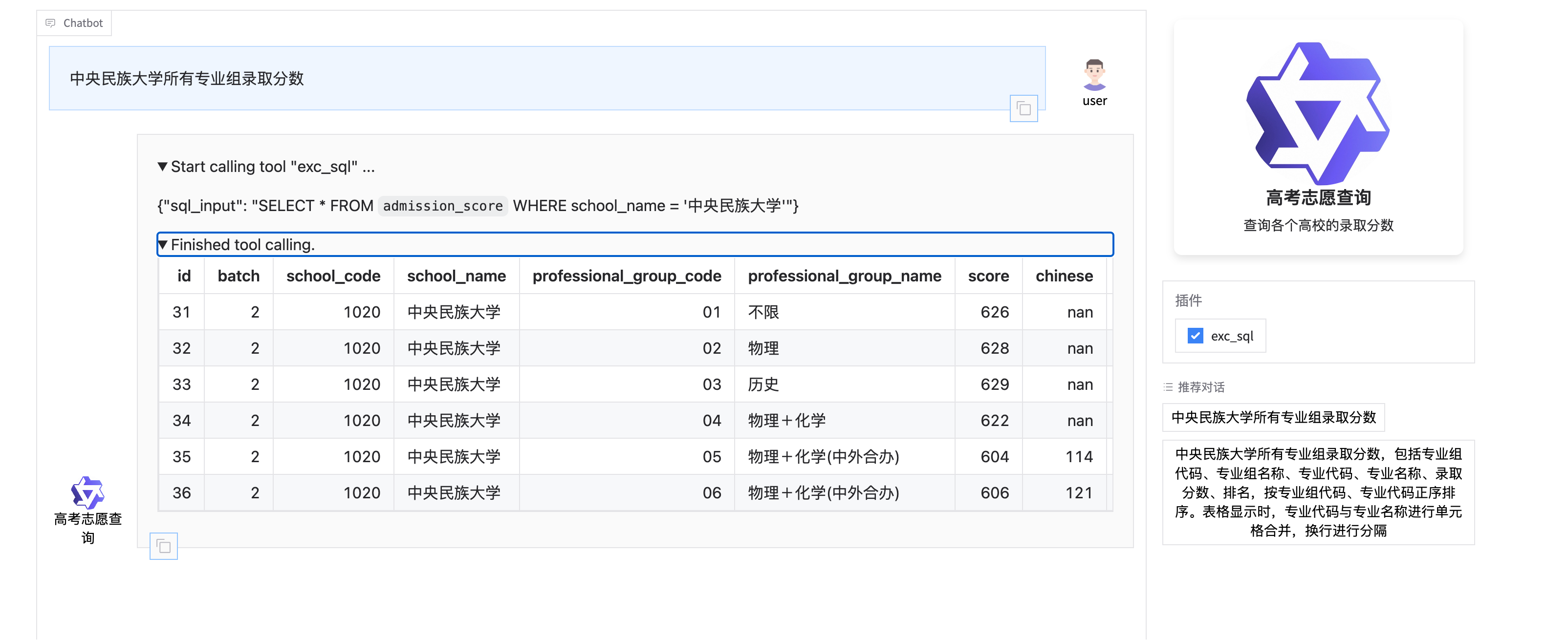
搭建高校录取分数查询助手,在前端UI上面输入问题,例:中央民族大学2025年北京录取分数,发送给大模型进行查询,然后返回前端数据,前端以表格的形式显示查询的结果。
运行本地模型
本次选择的模型为Qwen2:7B,其优势为以下:
- 更好的中文理解能力
- 更成熟的Function Calling支持
- 对结构化数据查询任务处理更好
- 更容易理解复杂的SQL生成需求
运行qwen2:7b:使用 ollama 拉取ollama pull qwen2:7b(大小4.4G),然后执行命令运行 ollama run qwen2:7b
代码
import os
import asyncio
from typing import Optional
import dashscope
from qwen_agent.agents import Assistant
from qwen_agent.gui import WebUI
import pandas as pd
from sqlalchemy import create_engine
from qwen_agent.tools.base import BaseTool, register_tool# 定义资源文件根目录
ROOT_RESOURCE = os.path.join(os.path.dirname(__file__), 'resource')# ====== 助手 system prompt 和函数描述 ======
system_prompt = """我是高校录取分数查询助手,以下是关于录取分数相关的字段,我可能会编写对应的SQL,对数据进行查询,每次查询显示所有,不要只显示10条
重要规则:
1. 当用户询问与高校录取分数相关的问题时,必须使用 exc_sql 工具执行SQL查询
2. 必须根据用户的具体需求编写准确的SQL语句
3. 查询结果必须包含用户要求的所有字段和排序规则-- 录取分数表,包括提前批、普通批、专科
CREATE TABLE `admission_score` (`id` int NOT NULL AUTO_INCREMENT COMMENT '录取分数表,包括提前批、普通批、专科',`batch` int DEFAULT NULL COMMENT '1-提前批A\\n2-提前批B\\n3-普通批',`school_code` varchar(45) DEFAULT NULL COMMENT '院校代码',`school_name` varchar(200) DEFAULT NULL COMMENT '学校名称',`professional_group_code` varchar(10) DEFAULT NULL COMMENT '专业组代码',`professional_group_name` varchar(45) DEFAULT NULL COMMENT '专业组名称',`score` int DEFAULT NULL,`chinese` int DEFAULT NULL COMMENT '语文',`math` int DEFAULT NULL COMMENT '数学',`english` int DEFAULT NULL COMMENT '英语',`other` int DEFAULT NULL COMMENT '选考科目',`notes` varchar(2000) DEFAULT NULL COMMENT '备注',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=37 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- 一分一段表
CREATE TABLE `score_distribution` (`id` int NOT NULL AUTO_INCREMENT COMMENT '一分一段表',`score` varchar(200) DEFAULT NULL COMMENT '分数',`score_number` int DEFAULT NULL COMMENT '本段人数',`amount_number` int DEFAULT NULL COMMENT '排名',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=348 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `professional_and_people_number` (`id` int NOT NULL AUTO_INCREMENT COMMENT '高校招生计划',`school_code` varchar(45) DEFAULT NULL COMMENT '学校代码',`school_name` varchar(200) DEFAULT NULL COMMENT '学校名称',`professional_group_code` varchar(45) DEFAULT NULL COMMENT '专业组代码',`professional_group_name` varchar(45) DEFAULT NULL COMMENT '专业组名称',`professional_code` varchar(45) DEFAULT NULL COMMENT '专业代码',`professional_name` varchar(2000) DEFAULT NULL COMMENT '专业名称',`pepole_number` int DEFAULT NULL COMMENT '人数',`notes` varchar(200) DEFAULT NULL COMMENT '备注',`adress` varchar(45) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;我将回答用户关于录取分数相关的问题
"""# ====== exc_sql 工具类实现 ======
@register_tool('exc_sql')
class ExcSQLTool(BaseTool):"""SQL查询工具,执行传入的SQL语句并返回结果。"""description = '对于生成的SQL,进行SQL查询'parameters = [{'name': 'sql_input','type': 'string','description': '生成的SQL语句','required': True}]def call(self, params: str, **kwargs) -> str:import jsonargs = json.loads(params)sql_input = args['sql_input']database = args.get('database', 'bjgk')# 创建数据库连接engine = create_engine(f'mysql+pymysql://root:xxxxxx@localhost:3306/{database}?charset=utf8mb4',connect_args={'connect_timeout': 10}, pool_size=10, max_overflow=20)try:df = pd.read_sql(sql_input, engine)return df.head(200).to_markdown(index=False)except Exception as e:return f"SQL执行出错: {str(e)}"# ====== 初始化助手服务 ======
def init_agent_service():"""初始化助手服务"""print("系统提示内容:")print(system_prompt[:200] + "..." if len(system_prompt) > 200 else system_prompt)llm_cfg = {'model': 'qwen2:7b','model_server': 'http://localhost:11434/v1','api_key': 'EMPTY','timeout': 30,'retry_count': 3,}try:bot = Assistant(llm=llm_cfg,name='高考志愿查询',description='查询各个高校的录取分数',system_message=system_prompt,function_list=['exc_sql'], # 只传工具名字符串)print("助手初始化成功!")return botexcept Exception as e:print(f"助手初始化失败: {str(e)}")raisedef app_tui():"""终端交互模式提供命令行交互界面,支持:- 连续对话- 文件输入- 实时响应"""try:# 初始化助手bot = init_agent_service()# 对话历史messages = []while True:try:# 获取用户输入query = input('user question: ')# 获取可选的文件输入file = input('file url (press enter if no file): ').strip()# 输入验证if not query:print('user question cannot be empty!')continue# 构建消息if not file:messages.append({'role': 'user', 'content': query})else:messages.append({'role': 'user', 'content': [{'text': query}, {'file': file}]})print("正在处理您的请求...")# 运行助手并处理响应response = []for response in bot.run(messages):print('bot response:', response)messages.extend(response)except Exception as e:print(f"处理请求时出错: {str(e)}")print("请重试或输入新的问题")except Exception as e:print(f"启动终端模式失败: {str(e)}")def app_gui():"""图形界面模式,提供 Web 图形界面"""try:print("正在启动 Web 界面...")# 初始化助手bot = init_agent_service()# 配置聊天界面,列举3个典型门票查询问题chatbot_config = {'prompt.suggestions': ['中央民族大学所有专业组录取分数','中央民族大学所有专业组录取分数,包括专业组代码、专业组名称、专业代码、专业名称、录取分数、排名,按专业组代码、专业代码正序排序。表格显示时,专业代码与专业名称进行单元格合并,换行进行分隔',]}print("Web 界面准备就绪,正在启动服务...")# 启动 Web 界面WebUI(bot,chatbot_config=chatbot_config).run()except Exception as e:print(f"启动 Web 界面失败: {str(e)}")print("请检查网络连接和 API Key 配置")if __name__ == '__main__':# 运行模式选择app_gui() # 图形界面模式(默认)
执行结果
思考
如果建表语句有更新,如何让大模型进行查询呢?