【js】让项目支持倾听和朗读AI技术
前言
随着AI技术的迅猛发展,语音识别已经逐渐走入我们的日常生活。从语音助手到语音输入法,语音转文字,及文字直接转语音朗读技术为用户提供了更加便捷的交互方式。
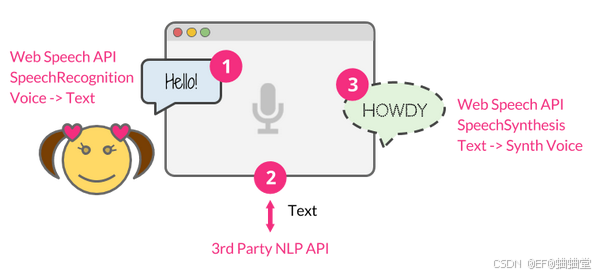
什么是 Web Speech API
Web Speech API 是一组浏览器 API,允许开发者在 Web 应用程序中集成语音识别和语音合成功能。这些 API 的引入标志着浏览器开始支持本地端的语音交互能力,不仅改善了用户体验,还为开发者提供了更多创新的可能性。

Web Speech API 由两部分组成:
SpeechRecognition(异步语音识别 ) :
该接口能够从音频输入中识别语音上下文并做出适当的响应。通常,开发者需要使用该接口的构造函数创建一个新的 SpeechRecognition 对象,该对象包含多个事件处理程序,用于检测何时通过设备麦克风输入语音。SpeechGrammar 接口表示应用应该识别的一组特定语法的容器,使用 JSpeech 语法格式 (JSGF) 定义。
- 允许用户通过麦克风输入语音,然后将其转换为文本。
- 可以检测语音的开始和结束,以便进行适当的处理和响应。
- 提供了各种配置选项,如语言识别设置、连续识别等,以满足不同应用场景的需求。
SpeechSynthesis(语音合成):
文本转语音组件,允许程序读出文本内容。不同的语音类型由 SpeechSynthesisVoice 对象表示,而如果想要朗读文本的不同部分则由 SpeechSynthesisUtterance 对象表示。开发者可以通过将其传递给 SpeechSynthesis.speak() 方法来朗读部分内容。
- 允许开发者将文本转换为语音输出。
- 支持多种语音合成引擎和语音效果,可以根据需求选择合适的语音风格和语言。
- 提供了控制音调、语速等参数的接口,以实现个性化的语音输出效果。
优势:
- 多语言支持: Web Speech API 支持多种语言,可0以通过设置
recognition.lang或utterance.lang来切换不同的语言环境。例如,识别法语、西班牙语等。 - 语音指令的识别: 不仅仅是简单的文本转换,可以实现对特定命令或短语的识别,如控制网页的导航、播放媒体等。这需要在识别的事件处理程序中进行语音指令的解析和响应。
- 连续语音识别: 设置
recognition.continuous = true,使得语音识别能够持续监听用户的语音输入,而不是单次识别。 - 实时反馈和动态调整: 根据识别的实时结果,可以实现实时反馈或动态调整应用程序的行为。例如,在用户说话时动态更新界面或提供即时建议。
实现语音识别
const recognition = new webkitSpeechRecognition(); // 创建语音识别对象
recognition.lang = 'en-US'; // 设置识别语言为英语
recognition.onresult = function(event) {const transcript = event.results[0][0].transcript; // 获取识别结果文本console.log('识别结果:', transcript);
};
recognition.start(); // 开始识别属性
- recognition.grammars 用于存储一组语法规则,可以通过
addFromString方法添加语法规则。 - recognition.lang 设置或获取语音识别的语言
- recognition.interimResults 如果设置为
true,则在识别过程中会提供临时结果。如果为false,则只提供最终结果 - recognition.maxAlternatives 设置语音识别返回的替代结果的最大数量。默认值为 1,表示只返回最可能的结果
- recognition.continuous 如果设置为
true,则识别会持续运行直到显式停止。如果为false,识别会在单次语音输入后自动停止 - recognition.onresult 当识别结果可用时触发的事件处理程序。事件对象的
results属性包含识别结果 - recognition.onaudiostart 当开始录制音频时触发的事件处理程序
- recognition.onsoundstart 当检测到声音时触发的事件处理程序
- recognition.onspeechstart 当检测到用户开始说话时触发的事件处理程序
- recognition.onspeechend 当用户停止说话时触发的事件处理程序
- recognition.onaudioend 当音频录制停止时触发的事件处理程序
- recognition.onend 当语音识别结束时触发的事件处理程序
- recognition.onerror 当语音识别发生错误时触发的事件处理程序。事件对象的
error属性包含错误信息 - recognition.onnomatch 当语音识别没有匹配到任何结果时触发的事件处理程序
- recognition.onsoundend 当检测到的声音停止时触发的事件处理程序
实现语音合成
const utterance = new SpeechSynthesisUtterance('Hello, welcome to our website.');
utterance.lang = 'en-US'; // 设置语音合成的语言
window.speechSynthesis.speak(utterance); // 开始语音合成属性
- SpeechSynthesisUtterance.lang 获取并设置说话的语言
- SpeechSynthesisUtterance.pitch 获取并设置说话的音调(值越大越尖锐,越小越低沉)
- SpeechSynthesisUtterance.rate 获取并设置说话的速度(值越大越快)
- SpeechSynthesisUtterance.text 获取并设置说话的文本
- SpeechSynthesisUtterance.voice 获取并设置说话时的声音
- SpeechSynthesisUtterance.volume 获取并设置说话的音量
通过语音控制网站背景颜色
当用户点击屏幕并说出一个 HTML 颜色关键字,应用的背景颜色就会变为该颜色。
const SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
// 语音识别
const SpeechGrammarList = SpeechGrammarList || window.webkitSpeechGrammarList;
// 希望识别的单词模式或者单词
const SpeechRecognitionEvent = SpeechRecognitionEvent || webkitSpeechRecognitionEvent;
const colors = ['aqua' , 'azure' , 'beige', 'bisque', 'black', 'blue', 'brown', 'chocolate', 'coral', 'crimson', 'cyan', 'fuchsia', 'ghostwhite', 'gold', 'goldenrod', 'gray', 'green', 'indigo', 'ivory', 'khaki', 'lavender', 'lime', 'linen', 'magenta', 'maroon', 'moccasin', 'navy', 'olive', 'orange', 'orchid', 'peru', 'pink', 'plum', 'purple', 'red', 'salmon', 'sienna', 'silver', 'snow', 'tan', 'teal', 'thistle', 'tomato', 'turquoise', 'violet', 'white', 'yellow'];
const recognition = new SpeechRecognition();
if (SpeechGrammarList) { // SpeechGrammarList目前在 Safari 不可用,Chrome>=33/Edge>=79才可用 const speechRecognitionList = new SpeechGrammarList(); const grammar = '#JSGF V1.0; grammar colors; public <color> =' + colors.join('|') + ';' ;speechRecognitionList.addFromString(grammar, 1); recognition.grammars = speechRecognitionList;
}recognition.continuous = false;
// 控制每次识别是否返回连续结果,还是仅返回单个结果recognition.lang = 'en-US';recognition.interimResults = false;// 是否返回中期结果(true)或不返回(false),而中期结果是指尚未最终确定的结果recognition.maxAlternatives = 1;// 设置每个结果提供的 SpeechRecognitionAlternatives 的最大数量const diagnostic = document.querySelector('.output');const bg = document.querySelector('html');const hints = document.querySelector('.hints');const colorHTML= '';colors.forEach(function(v, i, a){ colorHTML += '<span style="background-color:'+ v +';">' + v + '</span>';});hints.innerHTML = 'Tap/click then say a color to change the background color of the app. Try' + colorHTML + '.';// 启动识别document.body.onclick = function() { recognition.start(); console.log('Ready to receive a color command.');}recognition.onresult = function(event) { // 返回的是 SpeechRecognitionResultList 对象,其提供getter方法并支持通过数组方法 // [0]返回最后一个 SpeechRecognitionResult 结果,继续访问[0]返回第一个可选项 const color = event.results[0][0].transcript; // 根据结果修改页面 diagnostic.textContent = 'Result received:' + color + '.'; bg.style.backgroundColor = color; console.log('Confidence:' + event.results[0][0].confidence);}// 停止语音输入recognition.onspeechend = function() { recognition.stop();}// 没有匹配的结果recognition.onnomatch = function(event) { diagnostic.textContent = "I didn't recognise that color.";}
// 语音出错
recognition.onerror = function(event) { diagnostic.textContent = 'Error occurred in recognition:' + event.error;}//html<!DOCTYPE html>
<html lang="en">
<head>
<meta name="viewport" content="width=device-width" />
<title>Speech color changer</title> <link rel="stylesheet" href="style.css" /> </head> <body> <h1>Speech color changer</h1> <p class="hints"></p> <div> <p class="output"><em>...diagnostic messages</em></p> </div> <script src="script.js"></script>
</body>
</html>
SpeechGrammarList:包含开发者希望识别服务识别的单词或单词模式的 SpeechGrammar 对象列表,其目前默认使用 JSpeech 语法格式 (JSGF) 定义,将来也可能支持其他格式。
SpeechRecognitionEvent: 表示 result 和 nomatch 事件的事件对象,包含与中间或最终语音识别结果相关的所有数据。
语音合成:网站朗读功能
function setupSpeechButton(contentSelector, buttonSelector) {const button = document.getElementById(buttonSelector);const content = document.getElementById(contentSelector);// 如果设备不支持Web Speech API直接跳过 if (!window.speechSynthesis || !button || !content) return;// 从HTML文档获取当前语言的语音 function getPreferredVoice() {const htmlLang = document.documentElement.lang || 'en';const voices = window.speechSynthesis.getVoices();return voices.find((v) => v.lang.startsWith(htmlLang)) || voices[0];} // 真正开始语音朗读功能 function speakContent() {window.speechSynthesis.cancel();// 设置读取的内容 const utterance = new SpeechSynthesisUtterance(content.innerText);// 基于语言获取语音 const voice = getPreferredVoice();if (voice) utterance.voice = voice;// 切换按钮 utterance.onstart = () => {button.disabled = true;button.textContent = 'Stop';};utterance.onend = () => {button.disabled = false;button.textContent = 'Listen';};utterance.onend = () => (button.disabled = false);// 读取内容 window.speechSynthesis.speak(utterance);}// 兼容有些浏览器加载语音是异步的流程 if (window.speechSynthesis.getVoices().length === 0) {window.speechSynthesis.onvoiceschanged = () => {button.addEventListener('click', speakContent);};} else {button.addEventListener('click', speakContent);}}setupSpeechButton('blog-content', 'listen-btn');
SpeechSynthesisUtterance:表示一个语音请求,包含语音服务需要读取的内容以及如何读取的信息,例如:语言、音调和音量等
window.speechSynthesis:调用该方法,并传入 SpeechSynthesisUtterance 对象即可读取内容
总结
Web Speech API 为网页开发者提供了强大的语音交互能力,但需要注意不同浏览器对其支持程度可能有所差异,在实际应用中可能需要进行兼容性处理。