力扣top100(day02-03)--链表03
138. 随机链表的复制
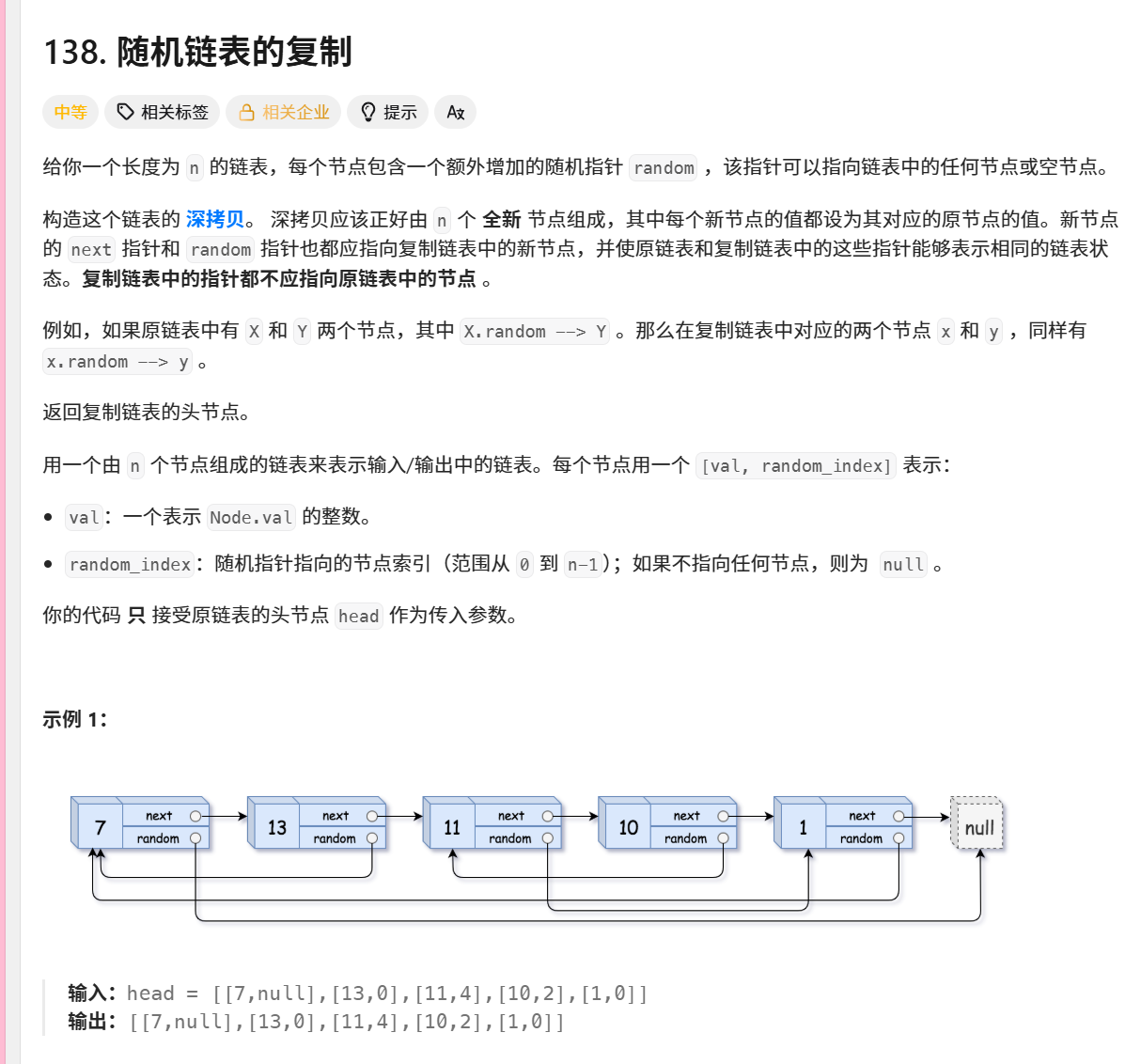
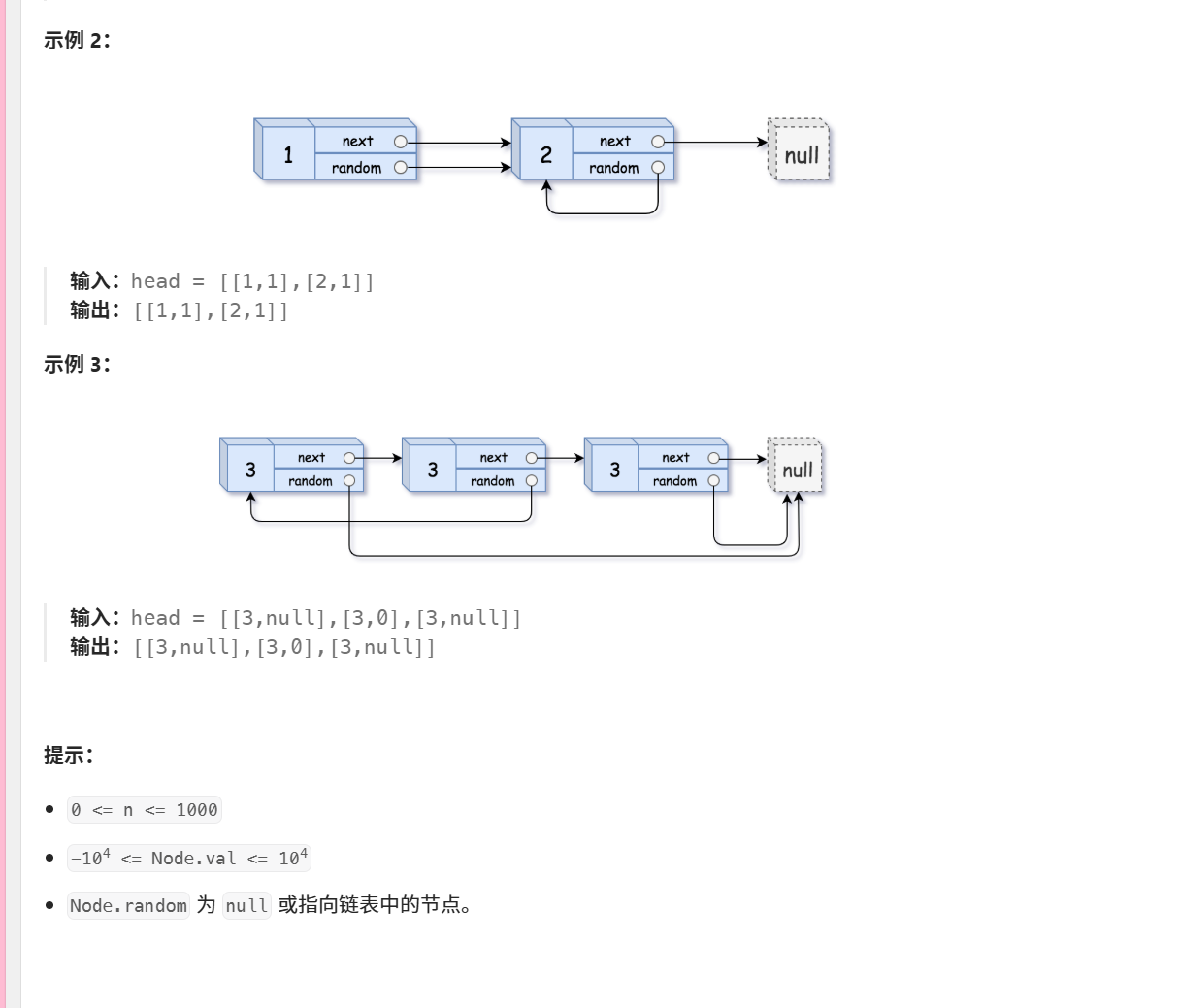
/*
// Definition for a Node.
class Node {int val;Node next;Node random;public Node(int val) {this.val = val;this.next = null;this.random = null;}
}
*/class Solution {public Node copyRandomList(Node head) {// 如果原链表为空,直接返回nullif (head == null) {return null;}// 第一步:创建新节点并插入原链表中// 在每个原节点后面插入一个它的复制节点for (Node node = head; node != null; node = node.next.next) {// 创建新节点,值与原节点相同Node nodeNew = new Node(node.val);// 新节点的next指向原节点的nextnodeNew.next = node.next;// 原节点的next指向新节点node.next = nodeNew;// 这样链表变为:原1 -> 新1 -> 原2 -> 新2 -> ...}// 第二步:设置新节点的random指针// 根据原节点的random指针设置新节点的random指针for (Node node = head; node != null; node = node.next.next) {// 获取当前原节点对应的新节点Node nodeNew = node.next;// 新节点的random指向原节点random指向节点的下一个节点(即对应的新节点)// 如果原节点的random为null,则新节点的random也为nullnodeNew.random = (node.random != null) ? node.random.next : null;}// 第三步:分离原链表和新链表// 保存新链表的头节点(原链表头节点的下一个节点)Node headNew = head.next;for (Node node = head; node != null; node = node.next) {// 获取当前原节点对应的新节点Node nodeNew = node.next;// 恢复原节点的next指针(跳过新节点,指向下一个原节点)node.next = node.next.next;// 设置新节点的next指针(指向下一个新节点)// 如果下一个新节点存在,则指向它;否则为nullnodeNew.next = (nodeNew.next != null) ? nodeNew.next.next : null;}// 返回新链表的头节点return headNew;}
}关键点解释:
插入新节点:
在原节点后立即插入它的复制节点,形成交替结构
这样可以通过原节点快速找到对应的新节点(原节点.next)
设置random指针:
新节点的random = 原节点.random.next
因为原节点的random指向的节点后面就是它的复制节点
链表分离:
需要同时维护原链表和新链表的next指针
原节点的next跳过新节点,指向下一个原节点
新节点的next指向下一个新节点
这种方法避免了使用额外的哈希表来存储新旧节点的映射关系,空间复杂度为O(1),是一种非常巧妙的解决方案。
148. 排序链表
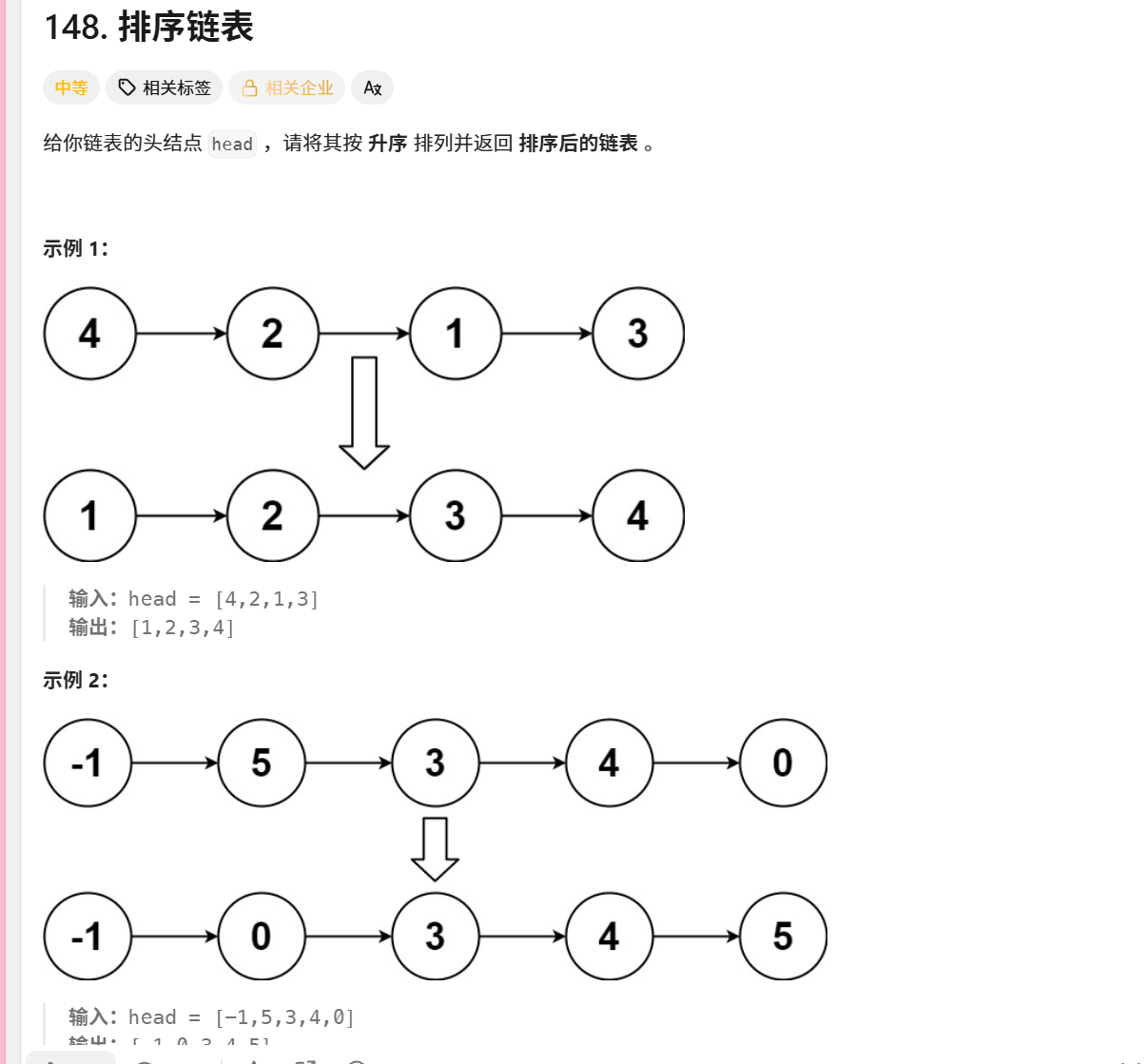
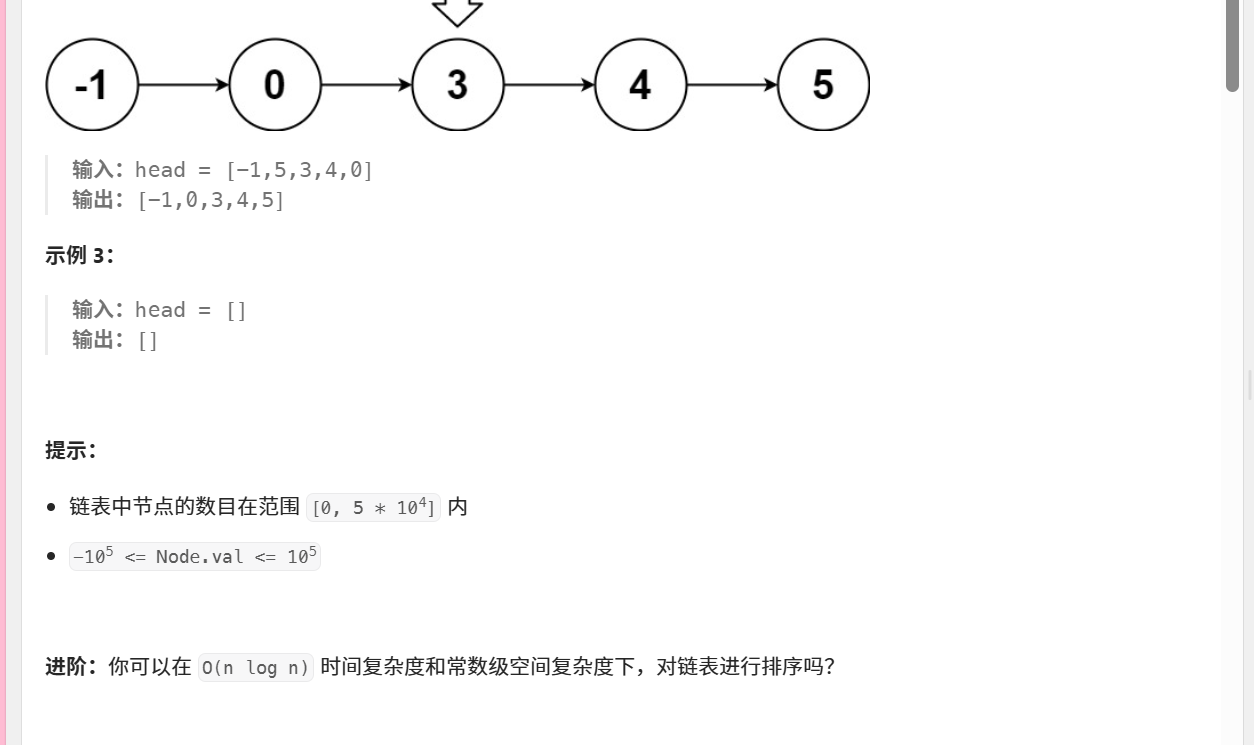
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {// 主排序方法入口public ListNode sortList(ListNode head) {// 调用辅助排序方法,初始tail为null表示整个链表return sortList(head, null);}// 辅助排序方法(递归实现)// head: 当前链表头节点// tail: 当前链表尾节点的下一个节点(类似区间[head, tail))public ListNode sortList(ListNode head, ListNode tail) {// 处理空链表情况if (head == null) {return head;}// 递归终止条件:当前链表只有一个节点// head.next == tail 表示只有一个节点if (head.next == tail) {head.next = null; // 断开链表,确保独立性return head; // 返回单个节点}// 使用快慢指针找到链表中点ListNode slow = head, fast = head;// 快指针每次走两步,慢指针每次走一步while (fast != tail) {slow = slow.next;fast = fast.next;// 防止fast一次移动两步时越界if (fast != tail) {fast = fast.next;}}ListNode mid = slow; // slow即为中点// 递归排序前半部分链表 [head, mid)ListNode list1 = sortList(head, mid);// 递归排序后半部分链表 [mid, tail)ListNode list2 = sortList(mid, tail);// 合并两个已排序的子链表ListNode sorted = merge(list1, list2);return sorted;}// 合并两个有序链表的方法public ListNode merge(ListNode head1, ListNode head2) {// 创建哑节点(dummy head)简化操作ListNode dummyHead = new ListNode(0);// temp: 指向结果链表的当前末尾节点// temp1和temp2分别遍历两个链表ListNode temp = dummyHead, temp1 = head1, temp2 = head2;// 当两个链表都还有节点时while (temp1 != null && temp2 != null) {// 比较节点值,选择较小的加入结果链表if (temp1.val <= temp2.val) {temp.next = temp1;temp1 = temp1.next;} else {temp.next = temp2;temp2 = temp2.next;}temp = temp.next; // 移动结果链表的指针}// 处理剩余节点if (temp1 != null) {temp.next = temp1; // 链表1还有剩余节点} else if (temp2 != null) {temp.next = temp2; // 链表2还有剩余节点}// 返回合并后的链表头节点(跳过哑节点)return dummyHead.next;}
}关键点详细解释:
递归分割链表:
使用快慢指针技巧找到链表中点(
slow)将链表从中点分为两部分,分别递归排序
递归终止条件是链表只有一个节点
合并两个有序链表:
创建哑节点简化链表头部的处理
使用双指针同时遍历两个链表
比较节点值,选择较小的加入结果链表
当一个链表遍历完后,直接将另一个链表的剩余部分接上
边界条件处理:
空链表直接返回
单节点链表直接返回(断开与原链表的连接)
快指针移动时检查是否越界(
fast != tail)时间复杂度分析:
分割过程:O(log n) 层递归
每层合并:O(n) 时间
总时间复杂度:O(n log n)
空间复杂度:
递归栈空间:O(log n)
合并操作使用常数空间
sortList(4→2→1→3)
├─ sortList(4→2) → returns 2→4
│ ├─ sortList(4) → returns 4
│ └─ sortList(2) → returns 2
│ └─ merge(4,2) → 2→4
└─ sortList(1→3) → returns 1→3
├─ sortList(1) → returns 1
└─ sortList(3) → returns 3
└─ merge(1,3) → 1→3
└─ merge(2→4, 1→3) → 1→2→3→4
146. LRU 缓存

class LRUCache extends LinkedHashMap<Integer, Integer>{private int capacity;public LRUCache(int capacity) {super(capacity, 0.75F, true);this.capacity = capacity;}public int get(int key) {return super.getOrDefault(key, -1);}public void put(int key, int value) {super.put(key, value);}@Overrideprotected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {return size() > capacity; }
}
import java.util.LinkedHashMap;
import java.util.Map;/**
* LRU (Least Recently Used) 缓存实现
* 继承LinkedHashMap,利用其有序特性实现LRU算法
*/
class LRUCache extends LinkedHashMap<Integer, Integer> {
// 缓存容量
private int capacity;
/**
* 构造函数
* @param capacity 缓存容量
*/
public LRUCache(int capacity) {
// 调用LinkedHashMap的构造函数
// 参数说明:
// capacity - 初始容量
// 0.75F - 负载因子
// true - 按访问顺序排序(为false时是按插入顺序排序)
super(capacity, 0.75F, true);
this.capacity = capacity;
}/**
* 获取缓存值
* @param key 键
* @return 值,如果不存在返回-1
*/
public int get(int key) {
// 使用父类的getOrDefault方法
// 如果key存在,会将该键值对移到链表尾部(因为设置了accessOrder=true)
return super.getOrDefault(key, -1);
}/**
* 添加缓存项
* @param key 键
* @param value 值
*/
public void put(int key, int value) {
// 调用父类的put方法
// 如果key已存在,会更新value并将该键值对移到链表尾部
// 如果key不存在,会添加新键值对到链表尾部
super.put(key, value);
}/**
* 重写该方法决定何时移除最老的条目
* @param eldest 最老的条目(最近最少使用的条目)
* @return 当缓存大小超过容量时返回true,触发移除操作
*/
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
// 当当前大小超过容量限制时,移除最久未使用的条目
return size() > capacity;
}
}