DataOceanAI Dolphin(ffmpeg音频转化教程) 多语言(中国方言)语音识别系统部署与应用指南

一、技术背景与系统架构
1.1 Dolphin 系统概述
官方地址:DataoceanAI-Dolphin
DataOceanAI Dolphin 是由清华大学与DataOceanAI联合开发的多语言自动语音识别(ASR, Automatic Speech Recognition)系统。该系统专门针对东方语言设计,支持40种亚洲语言和22种中文方言,基于超过21万小时的训练数据构建。系统采用Transformer架构,提供了从140M到1.67B参数规模的多个模型版本。
Dolphin的核心优势在于其对中文方言的精准识别能力。传统的语音识别系统如OpenAI Whisper在处理中文方言时准确率较低,而Dolphin通过引入地区特定标记(region-specific tokens)和大规模方言数据训练,显著提升了方言识别效果。系统不仅支持语音转文字,还集成了语音活动检测(VAD, Voice Activity Detection)、语言识别和音频分段功能。
1.2 技术架构分析
Dolphin采用端到端(end-to-end)的深度学习架构,核心组件包括音频编码器、注意力机制模块和文本解码器。音频信号首先通过梅尔频谱(Mel-spectrogram)转换为频域特征,然后输入到Transformer编码器中。系统使用CTC(Connectionist Temporal Classification)和Attention机制的混合解码策略,提高了长音频的识别准确率。
模型训练采用了多任务学习(multi-task learning)策略,同时优化语音识别、语言识别和方言识别三个任务。这种设计使得模型能够自动识别输入音频的语言类型和方言变体,无需用户手动指定。
二、环境准备与依赖管理
2.1 系统要求检查
在部署Dolphin之前,需要确保系统满足以下基本要求。Windows系统需要Windows 10版本1903或更高版本,内存至少8GB(推荐16GB),存储空间需要预留至少10GB用于模型文件和缓存。如果计划使用GPU加速,需要NVIDIA显卡并安装CUDA 11.8或更高版本。
2.2 包管理器安装
也可以安装choco,以下是教程(为了安装FFmpeg):Windows安装 choco包管理工具
Winget 安装与配置
Winget是Windows官方的包管理器,从Windows 10版本1809开始内置。首先验证Winget是否已安装:
winget --version
如果系统未安装Winget,可以通过Microsoft Store安装"应用安装程序",或从GitHub下载安装包。Winget的主要优势在于其与Windows系统的深度集成,能够自动处理依赖关系和环境变量配置。
2.3 FFmpeg 音频处理工具配置(不安装会报错)
FFmpeg 功能介绍
FFmpeg是一个开源的多媒体处理框架,在Dolphin系统中用于音频格式转换和预处理。Dolphin要求输入音频为WAV格式,采样率16kHz,单声道。FFmpeg能够将各种音频格式(MP3、M4A、FLAC等)转换为符合要求的格式。
安装方法对比
| 安装方式 | 优势 | 劣势 | 推荐场景 |
|---|---|---|---|
| Winget | 自动配置环境变量,一键安装 | 需要Winget支持 | 日常使用 |
| Scoop | 轻量级,易于管理 | 需要额外安装Scoop | 开发环境 |
| 手动安装 | 完全控制,版本灵活 | 需要手动配置PATH | 特定版本需求 |
使用Winget安装FFmpeg:
winget install Gyan.FFmpeg
验证安装:
ffmpeg -version
三、Conda 环境配置与Python依赖
3.1 Conda 环境管理策略
Conda是Python科学计算领域的标准环境管理工具。它通过创建独立的虚拟环境来隔离不同项目的依赖,避免版本冲突。Dolphin项目建议使用Python 3.8或3.9版本,以确保与PyTorch等深度学习框架的兼容性。
创建专用环境:
# 创建名为dolphin-env的新环境,指定Python版本
conda create -n dolphin-env python=3.9 -y# 激活环境
conda activate dolphin-env# 验证Python版本
python --version
3.2 依赖包安装与版本管理
Dolphin系统依赖多个Python包,包括深度学习框架PyTorch、音频处理库librosa、模型管理工具ModelScope等。安装过程中可能遇到的主要问题是包版本冲突和编译依赖缺失。
基础依赖安装:
# 安装PyTorch(CPU版本)
pip install torch torchvision torchaudio# 如需GPU支持,安装CUDA版本
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118# 安装Dolphin包(可以直接这一步)
pip install -U dataoceanai-dolphin
四、常见安装问题诊断与解决
4.1 依赖冲突解决策略
问题现象分析
安装过程中最常见的错误是ctc-segmentation编译失败和NLTK数据下载失败。ctc-segmentation是用于音频分段的关键组件,需要C++编译器支持。NLTK(Natural Language Toolkit)提供文本处理功能,但其数据下载经常因网络问题失败。
解决方案实施
对于Windows系统的编译错误,需要安装Microsoft C++ Build Tools:
# 下载Visual Studio Installer
winget install Microsoft.VisualStudio.2022.BuildTools# 在安装器中选择"使用C++的桌面开发"工作负载
处理NLTK数据下载问题:
import nltk
import ssl# 绕过SSL验证(仅在受信任网络环境中使用)
try:_create_unverified_https_context = ssl._create_unverified_context
except AttributeError:pass
else:ssl._create_default_https_context = _create_unverified_https_context# 下载必要的NLTK数据
nltk.download('averaged_perceptron_tagger')
nltk.download('cmudict')
4.2 环境变量与路径配置
循环导入问题
一个容易被忽视的问题是Python脚本命名冲突。如果将测试脚本命名为dolphin.py,会与Dolphin包产生循环导入错误。这是因为Python优先从当前目录导入模块。
缓存目录管理
Dolphin和ModelScope使用特定的缓存目录存储模型文件:
import os# Windows系统的默认缓存路径
cache_paths = {'dolphin': r'C:\Users\{username}\.cache\dolphin','modelscope': r'C:\Users\{username}\.cache\modelscope\hub'
}# 创建必要的目录结构
for path in cache_paths.values():os.makedirs(path, exist_ok=True)
五、模型下载与管理
5.1 模型版本选择
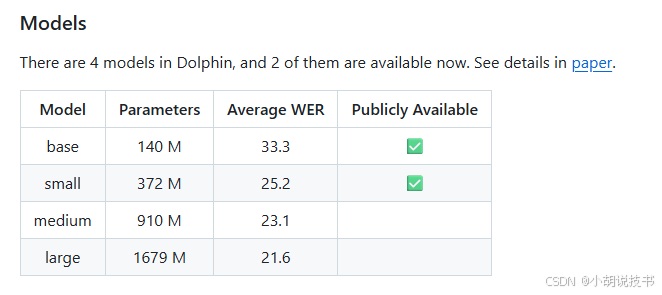
Dolphin提供两个公开模型版本,选择时需要权衡准确率和性能:
| 模型 | 参数量 | 文件大小 | WER | RTF (CPU) | 适用场景 |
|---|---|---|---|---|---|
| Base | 140M | 约600MB | 33.3% | 0.15 | 实时应用,资源受限 |
| Small | 372M | 约1.5GB | 25.2% | 0.11 | 高准确率需求 |
WER(Word Error Rate)表示词错误率,数值越低准确率越高。RTF(Real Time Factor)表示处理时间与音频时长的比值,小于1表示快于实时。
后续可以等官方在更新:
5.2 下载策略优化
自动下载机制
首次使用时,Dolphin会自动从ModelScope下载模型:
import dolphin# 自动下载到默认缓存目录
model = dolphin.load_model("small", device="cpu")
手动下载管理
对于网络受限环境,建议手动下载模型文件(国内快):
from modelscope import snapshot_download# 下载到指定目录
model_dir = snapshot_download('DataoceanAI/dolphin-small',cache_dir='./models'
)# 使用本地模型
model = dolphin.load_model("small", model_dir=model_dir, device="cpu")
六、音频预处理技术
6.1 格式转换与参数优化
Dolphin对输入音频有严格要求,不符合规范的音频会导致识别率下降。FFmpeg提供了完整的音频处理能力:
# 基础转换:任意格式转WAV
ffmpeg -i input.mp3 -ar 16000 -ac 1 output.wav# 参数说明:
# -i: 输入文件
# -ar 16000: 重采样到16kHz(语音识别标准采样率)
# -ac 1: 转换为单声道
# -sample_fmt s16: 16位采样深度(可选)
音频分段处理
长音频需要分段处理以提高识别准确率和处理效率:
# 提取前30秒
ffmpeg -i input.wav -t 30 output_30s.wav# 提取特定时间段(1分钟到1分30秒)
ffmpeg -i input.wav -ss 00:01:00 -to 00:01:30 output_segment.wav# 批量分割长音频(每30秒一段)
ffmpeg -i input.wav -f segment -segment_time 30 -c copy output_%03d.wav
七、语音识别实践应用
7.1 命令行使用方法
基础识别命令
Dolphin提供了功能完整的命令行接口:
# 最简单的使用方式
dolphin audio.wav# 指定模型和语言
dolphin audio.wav --model small --lang_sym "zh" --region_sym "CN"# 完整参数示例
dolphin audio.wav \--model small \--model_dir "./models/dolphin-small" \--lang_sym "zh" \--region_sym "CN" \--device "cpu" \--verbose
方言识别配置
Dolphin支持22种中文方言,通过region_sym参数指定:
# 温州话
dolphin audio.wav --model small --lang_sym "zh" --region_sym "WENZHOU"# 粤语(两种方式)
dolphin audio.wav --model small --lang_sym "ct" # 使用粤语语言代码
dolphin audio.wav --model small --lang_sym "zh" --region_sym "GUANGDONG"# 四川话
dolphin audio.wav --model small --lang_sym "zh" --region_sym "SICHUAN"
以下是从官方复制过来的对照表(官方对照表地址)
Language Code
| Language Code | English Name | Chinese Name |
|---|---|---|
| zh | Mandarin Chinese | 中文 |
| ja | Japanese | 日语 |
| th | Thai | 泰语 |
| ru | Russian | 俄语 |
| ko | Korean | 韩语 |
| id | Indonesian | 印度尼西亚语 |
| vi | Vietnamese | 越南语 |
| ct | Yue Chinese | 粤语 |
| hi | Hindi | 印地语 |
| ur | Urdu | 乌尔都语 |
| ms | Malay | 马来语 |
| uz | Uzbek | 乌兹别克语 |
| ar | Arabic | 阿拉伯语 |
| fa | Persian | 波斯语 |
| bn | Bengali | 孟加拉语 |
| ta | Tamil | 泰米尔语 |
| te | Telugu | 泰卢固语 |
| ug | Uighur | 维吾尔语 |
| gu | Gujarati | 古吉拉特语 |
| my | Burmese | 缅甸语 |
| tl | Tagalog | 塔加洛语 |
| kk | Kazakh | 哈萨克语 |
| or | Oriya / Odia | 奥里亚语 |
| ne | Nepali | 尼泊尔语 |
| mn | Mongolian | 蒙古语 |
| km | Khmer | 高棉语 |
| jv | Javanese | 爪哇语 |
| lo | Lao | 老挝语 |
| si | Sinhala | 僧伽罗语 |
| fil | Filipino | 菲律宾语 |
| ps | Pushto | 普什图语 |
| pa | Panjabi | 旁遮普语 |
| kab | Kabyle | 卡拜尔语 |
| ba | Bashkir | 巴什基尔语 |
| ks | Kashmiri | 克什米尔语 |
| tg | Tajik | 塔吉克语 |
| su | Sundanese | 巽他语 |
| mr | Marathi | 马拉地语 |
| ky | Kirghiz | 吉尔吉斯语 |
| az | Azerbaijani | 阿塞拜疆语 |
Language Region Code
| Language Region Code | English Name | Chinese Name |
|---|---|---|
| zh-CN | Chinese (Mandarin) | 中文(普通话) |
| zh-TW | Chinese (Taiwan) | 中文(台湾) |
| zh-WU | Chinese (Wuyu) | 中文(吴语) |
| zh-SICHUAN | Chinese (Sichuan) | 中文(四川话) |
| zh-SHANXI | Chinese (Shanxi) | 中文(山西话) |
| zh-ANHUI | Chinese (Anhui) | 中文(安徽话) |
| zh-TIANJIN | Chinese (Tianjin) | 中文(天津话) |
| zh-NINGXIA | Chinese (Ningxia) | 中文(宁夏话) |
| zh-SHAANXI | Chinese (Shaanxi) | 中文(陕西话) |
| zh-HEBEI | Chinese (Hebei) | 中文(河北话) |
| zh-SHANDONG | Chinese (Shandong) | 中文(山东话) |
| zh-GUANGDONG | Chinese (Guangdong) | 中文(广东话) |
| zh-SHANGHAI | Chinese (Shanghai) | 中文(上海话) |
| zh-HUBEI | Chinese (Hubei) | 中文(湖北话) |
| zh-LIAONING | Chinese (Liaoning) | 中文(辽宁话) |
| zh-GANSU | Chinese (Gansu) | 中文(甘肃话) |
| zh-FUJIAN | Chinese (Fujian) | 中文(福建话) |
| zh-HUNAN | Chinese (Hunan) | 中文(湖南话) |
| zh-HENAN | Chinese (Henan) | 中文(河南话) |
| zh-YUNNAN | Chinese (Yunnan) | 中文(云南话) |
| zh-MINNAN | Chinese (Minnan) | 中文(闽南语) |
| zh-WENZHOU | Chinese (Wenzhou) | 中文(温州话) |
| ja-JP | Japanese | 日语 |
| th-TH | Thai | 泰语 |
| ru-RU | Russian | 俄语 |
| ko-KR | Korean | 韩语 |
| id-ID | Indonesian | 印度尼西亚语 |
| vi-VN | Vietnamese | 越南语 |
| ct-NULL | Yue (Unknown) | 粤语(未知) |
| ct-HK | Yue (Hongkong) | 粤语(香港) |
| ct-GZ | Yue (Guangdong) | 粤语(广东) |
| hi-IN | Hindi | 印地语 |
| ur-IN | Urdu | 乌尔都语(印度) |
| ur-PK | Urdu (Islamic Republic of Pakistan) | 乌尔都语 |
| ms-MY | Malay | 马来语 |
| uz-UZ | Uzbek | 乌兹别克语 |
| ar-MA | Arabic (Morocco) | 阿拉伯语(摩洛哥) |
| ar-GLA | Arabic | 阿拉伯语 |
| ar-SA | Arabic (Saudi Arabia) | 阿拉伯语(沙特) |
| ar-EG | Arabic (Egypt) | 阿拉伯语(埃及) |
| ar-KW | Arabic (Kuwait) | 阿拉伯语(科威特) |
| ar-LY | Arabic (Libya) | 阿拉伯语(利比亚) |
| ar-JO | Arabic (Jordan) | 阿拉伯语(约旦) |
| ar-AE | Arabic (U.A.E.) | 阿拉伯语(阿联酋) |
| ar-LVT | Arabic (Levant) | 阿拉伯语(黎凡特) |
| fa-IR | Persian | 波斯语 |
| bn-BD | Bengali | 孟加拉语 |
| ta-SG | Tamil (Singaporean) | 泰米尔语(新加坡) |
| ta-LK | Tamil (Sri Lankan) | 泰米尔语(斯里兰卡) |
| ta-IN | Tamil (India) | 泰米尔语(印度) |
| ta-MY | Tamil (Malaysia) | 泰米尔语(马来西亚) |
| te-IN | Telugu | 泰卢固语 |
| ug-NULL | Uighur | 维吾尔语 |
| ug-CN | Uighur | 维吾尔语 |
| gu-IN | Gujarati | 古吉拉特语 |
| my-MM | Burmese | 缅甸语 |
| tl-PH | Tagalog | 塔加洛语 |
| kk-KZ | Kazakh | 哈萨克语 |
| or-IN | Oriya / Odia | 奥里亚语 |
| ne-NP | Nepali | 尼泊尔语 |
| mn-MN | Mongolian | 蒙古语 |
| km-KH | Khmer | 高棉语 |
| jv-ID | Javanese | 爪哇语 |
| lo-LA | Lao | 老挝语 |
| si-LK | Sinhala | 僧伽罗语 |
| fil-PH | Filipino | 菲律宾语 |
| ps-AF | Pushto | 普什图语 |
| pa-IN | Panjabi | 旁遮普语 |
| kab-NULL | Kabyle | 卡拜尔语 |
| ba-NULL | Bashkir | 巴什基尔语 |
| ks-IN | Kashmiri | 克什米尔语 |
| tg-TJ | Tajik | 塔吉克语 |
| su-ID | Sundanese | 巽他语 |
| mr-IN | Marathi | 马拉地语 |
| ky-KG | Kirghiz | 吉尔吉斯语 |
| az-AZ | Azerbaijani | 阿塞拜疆语 |
问题诊断清单
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 模型加载卡住 | 网络下载慢,内存不足 | 手动下载模型,增加虚拟内存 |
| 识别率低 | 音频质量差,方言设置错误 | 预处理音频,正确设置region_sym |
| 程序崩溃 | 依赖版本冲突 | 重建conda环境,固定包版本 |
| GPU不可用 | CUDA版本不匹配 | 重装对应版本PyTorch |
调试工具集
def debug_dolphin_setup():"""全面的环境诊断工具"""import sysimport importlib.utilprint("=== 系统信息 ===")print(f"Python版本: {sys.version}")print(f"平台: {sys.platform}")print("\n=== 依赖检查 ===")packages = ['torch', 'dolphin', 'modelscope', 'librosa', 'ffmpeg']for package in packages:spec = importlib.util.find_spec(package)if spec:print(f"✓ {package} 已安装")else:print(f"✗ {package} 未安装")print("\n=== PyTorch配置 ===")try:import torchprint(f"PyTorch版本: {torch.__version__}")print(f"CUDA可用: {torch.cuda.is_available()}")if torch.cuda.is_available():print(f"CUDA版本: {torch.version.cuda}")except Exception as e:print(f"PyTorch错误: {e}")print("\n=== 模型缓存 ===")cache_dir = os.path.expanduser("~/.cache/modelscope/hub")if os.path.exists(cache_dir):models = os.listdir(cache_dir)print(f"已缓存模型: {models}")else:print("无缓存模型")