h5bench(4)
图15总结了结果。对于一维写入场景,当内存布局是交错的(即,表示一个结构体数组,其中每个数组元素都是一个C结构体)且文件布局是连续的时,与同步调用相比,使用VOL-AsYNC,我们观察到分别使用1024、2048和4096个rank时,速度分别提高了2.93倍、1.38倍和2.20倍。
将同步执行与Log VOL连接器进行比较,对于这种I/O模式,我们观察到分别使用1024、2048和4096个rank时,速度分别提高了9.58倍、7.39倍和11.47倍。我们还观察到,在使用1024个rank连续读取内存和文件时,速度提高了1.55倍。
在内存中交错且在文件中连续写入的2D场景也受益于VOL-ASYNC连接器。我们观察到使用1024、2048和4096个等级时,速度分别提高了2.75倍、2.27倍和2.56倍。我们还观察到使用Log VOL时,与不使用任何连接器相比,使用1024、2048和4096个等级时,速度分别提高了8.21倍、8.64倍和12.36倍,也观察到类似的行为。
我们还观察到在使用1024个等级在内存和文件中连续读取时,速度提高了1.47倍。对于3D场景,我们仅在使用1024和2048个进程读取内存和文件中连续的模式时,观察到显著的速度提升,分别为1.23倍和1.18倍。
需要注意的是,观测到的速率也依赖于传输的数据量和并行文件系统的条带化配置。确定每种模式的最佳设置和配置,或展示每种VOL发挥优势的所有场景,均不在本文的讨论范围之内。
我们提供了一个基准测试套件,旨在帮助系统管理员和最终用户评估预期的I/O性能ASYNC:.LOGSYNC
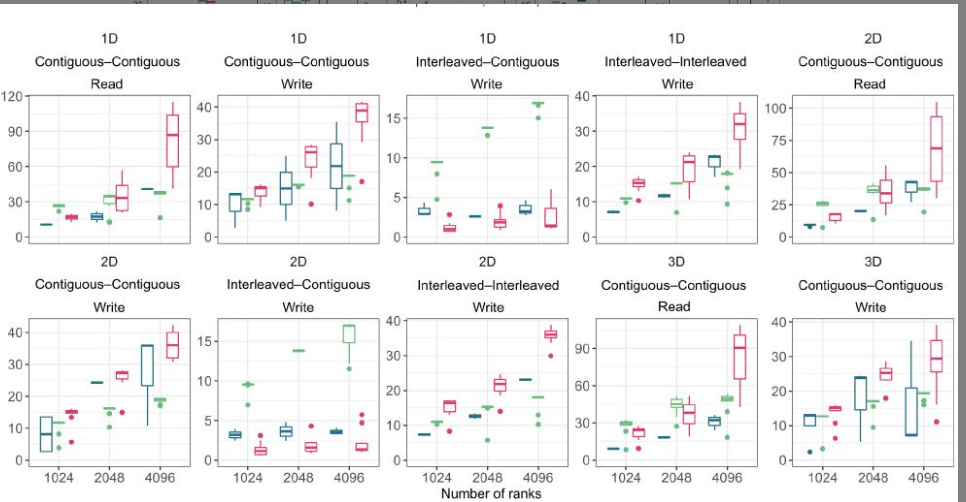
这个部分不看了,把之前的结论在大的超算重新验证了一下,说明真的很好用就可以。
5 I 结论
在本文中,我们介绍了 h5bench,这是一个统一的基准测试套件,用于使用 HDF5 APl 按照各种 I/O 模式执行数据写入和读取。该套件包括代表 I/O 操作的基线模式,考虑了内存中的数据结构和文件布局、多维数组(1D、2D 和 3D)以及来自多个科学领域的科学 I/O 内核。
此外,h5bench 可以评估新的 HDF5 功能,例如 VOL 连接器(例如,Async、Cache、Log)。例如,Async VOL 通过将 I/O 阶段与计算阶段重叠来隐藏大部分 I/O 延迟。Cache VOL 允许在节点本地存储上缓存或暂存数据,然后在节点本地存储和并行文件系统之间异步移动数据。log VOL 将写入请求存储在日志布局中的连续文件空间中,从而避免了如果数据以规范顺序存储时可能需要的昂贵的进程间通信。
总而言之,本文的重点是展示 h5bench 可以执行不同的访问模式,而不是比较不同 VOL 连接器的性能。用户可以通过设置各种配置参数来使用 hsbench 套件,这些参数基于他们想要执行的模式、HDF5 功能和大规模系统。
我们对h5bench的性能评估涵盖了在Cori和Summit上读写内核的不同维度。我们还通过在三个新的预百亿亿次级平台上(Perlmutter、Theta和Polaris)执行不同的访问模式和HDF5特性,研究了hsbench的性能。h5bench的测量结果可用于识别性能瓶颈及其根本原因,并评估I/O优化。
随着这些预生产系统的可用性提高,可以应用进一步的优化。由于h5bench的I/O模式是多样化的,并且捕捉了来自各个科学领域的HPC应用程序的I/O行为,因此这些特性将有助于更广泛的超级计算和I/O社区。
h5bench 套件可于 https:/github.com/hpc-io/h5bench 获取,采用类 BSD 许可,允许外部贡献以及公开使用代码。它也可以通过 Spack 轻松安装 (spack install h5bench),并且作为部署在多个超级计算设施(例如,NERSC、JLSE、OLCF)的 Extreme-scale Scientific Software Stack (E4S)21 的一部分提供。
未来,我们计划支持其他功能(例如,压缩、统一的性能报告、数据与元数据的细分),并提供统一的报告 API 和评分,以跟踪结果并跟踪百亿亿次级系统性能的变化。
压缩好像已经支持了