TF-IDF实战——《红楼梦》文本分析
文章目录
- 前言
- 一、数据(红楼梦.txt)
- 二、项目目标
- 三、初版代码
- 四、优化后代码
- 五、优化点对比
前言
在进行《红楼梦》这类古典文本分析时,我们常常需要完成:文本清洗、分卷处理、分词、去停用词、关键词提取等任务。
本文将展示一个从“原始可运行代码”到“优化高效代码”的完整演进过程,帮助你理解如何写出更清晰、更健壮的 Python 代码。
一、数据(红楼梦.txt)
因数据太多,这里只展示部分数据。
[红楼梦 / 曹雪芹 著 ]手机电子书·大学生小说网Txt版阅读,阅读作品更多请访问:http://www.dxsxs.com,书籍介绍:中国古代四大名著之一------章节内容开始-------上卷 第一回 甄士隐梦幻识通灵 贾雨村风尘怀闺秀手机电子书·大学生小说网 更新时间:2006-7-26 11:43:00 本章字数:8717此开卷第一回也.作者自云:因曾历过一番梦幻之后,故将真事隐去,而借"通灵"之说,撰此《石头记》一书也.故曰"甄士隐"云云.但书中所记何事何人?自又云:“今风尘碌碌,一事无成,忽念及当日所有之女子,一一细考较去,觉其行止见识,皆出于我之上.何我堂堂须眉,诚不若彼裙钗哉?实愧则有余,悔又无益之大无可如何之日也!当此,则自欲将已往所赖天恩祖德,锦衣纨绔之时,饫甘餍肥之日,背父兄教育之恩,负师友规谈之德,以至今日一技无成,半生潦倒之罪,编述一集,以告天下人:我之罪固不免,然闺阁中本自历历有人,万不可因我之不肖,自护己短,一并使其泯灭也.虽今日之茅椽蓬牖,瓦灶绳床,其晨夕风露,阶柳庭花,亦未有妨我之襟怀笔墨者.虽我未学,下笔无文,又何妨用假语村言,敷演出一段故事来,亦可使闺阁昭传,复可悦世之目,破人愁闷,不亦宜乎?"故曰"贾雨村"云云. 此回中凡用“梦”用“幻”等字,是提醒阅者眼目,亦是此书立意本旨. 列位看官:你道此书从何而来?说起根由虽近荒唐,细按则深有趣味.待在下将此来历注明,方使阅者了然不惑.
这里宝钗又向湘云道:“诗题也不要过于新巧了.你看古人诗中那些刁钻古怪的题目和那极险的韵了, 若题过于新巧,韵过于险,再不得有好诗,终是小家气.诗固然怕说熟话,更不可过于求生,只要头一件立意清新,自然措词就不俗了.究竟这也算不得什么, 还是纺绩针黹是你我的本等.一时闲了,倒是于你我深有益的书看几章是正经. "湘云只答应着,因笑道:“我如今心里想着,昨日作了海棠诗,我如今要作个菊花诗如何?"宝钗道:“菊花倒也合景,只是前人太多了。”湘云道:“我也是如此想着,恐怕落套. "宝钗想了一想,说道:“有了,如今以菊花为宾,以人为主,竟拟出几个题目来,都是两个字: 一个虚字,一个实字,实字便用`菊'字,虚字就用通用门的.如此又是咏菊,又是赋事,前人也没作过,也不能落套.赋景咏物两关着,又新鲜,又大方。”湘云笑道:“这却很好.只是不知用何等虚字才好.你先想一个我听听。”宝钗想了一想,笑道:“ 《菊梦》就好。”湘云笑道:“果然好.我也有一个,《菊影》可使得?"宝钗道:“也罢了.只是也有人作过,若题目多,这个也夹的上.我又有了一个。”湘云道:“快说出来。”宝钗道:“《问菊》如何?"湘云拍案叫妙,因接说道:“我也有了,《访菊》如何?"宝钗也赞有趣, 因说道:“越性拟出十个来,写上再来。”说着,二人研墨蘸笔,湘云便写,宝钗便念,一时凑了十个.湘云看了一遍,又笑道:“十个还不成幅,越性凑成十二个便全了,也如人家的字画册页一样。”宝钗听说,又想了两个,一共凑成十二.又说道:“既这样,越性编出他个次序先后来。”湘云道:“如此更妙,竟弄成个菊谱了。”宝钗道:“起首是< <忆菊》,忆之不得,故访,第二是《访菊》,访之既得,便种,第三是《种菊》,种既盛开, 故相对而赏,第四是《对菊》,相对而兴有余,故折来供瓶为玩,第五是《供菊》,既供而不吟,亦觉菊无彩色,第六便是《咏菊》,既入词章,不可不供笔墨,第七便是《画菊》,既为菊如是碌碌,究竟不知菊有何妙处,不禁有所问,第八便是《问菊》,菊如解语,使人狂喜不禁,第九便是《簪菊》,如此人事虽尽,犹有菊之可咏者,《菊影》《菊梦》二首续在第十第十一,末卷便以《残菊》总收前题之盛.这便是三秋的妙景妙事都有了.湘云依说将题录出,又看了一回,又问诗,何苦为韵所缚.咱们别学那小家派,只出题不拘韵.原为大家偶得了好句取乐,并不为此而难人。”湘云道:“这话很是.这样大家的诗还进一层. 但只咱们五个人,这十二个题目,难道每人作十二首不成?"宝钗道:“那也太难人了.将这题目誊好,都要七言律,明日贴在墙上.他们看了,谁作那一个就作那一个.有力量者,十二首都作也可,不能的,一首不成也可.高才捷足者为尊.若十二首已全,便不许他后赶着又作,罚他就完了。”湘云道:“这倒也罢了。”二人商议妥贴,方才息灯安寝.要知端的,且听下回分解.上卷 第三十八回 林潇湘魁夺菊花诗 薛蘅芜讽和螃蟹咏手机电子书·大学生小说网 更新时间:2006-7-26 11:43:00 本章字数:8221首页 | 原创书库 | 现代 | 言情 | 武侠 | 科幻 | 侦探 | 港台 | 外国 | 军事 | 纪实 | 历史 | 名著 | 古典 | 儿童 | 排行 | 论坛
本站长期招收作品更新管理员,欢迎有时间及兴趣的书友报名加入,点此察看详情!
后一页
前一页
回目录
回首页第三十八回 林潇湘魁夺菊花诗 薛蘅芜讽和螃蟹咏
--------------------------------------------------------------------------------话说宝钗湘云二人计议已妥, 一宿无话.湘云次日便请贾母等赏桂花.贾母等都说道:“是他有兴头,须要扰他这雅兴。”至午,果然贾母带了王夫人凤姐兼请薛姨妈等进园来. 贾母因问那一处好?山坡下两棵桂花开的又好,河里的水又碧清,坐在河当中亭子上岂不敞亮, 看着水眼也清亮。”贾母听了,说:“这话很是。”说着,就引了众人往藕香榭来. 原来这藕香榭盖在池中,四面有窗,左右有曲廊可通,亦是跨水接岸,后面又有曲折竹桥暗接. 众人上了竹桥,凤姐忙上来搀着贾母,口里说:“老祖宗只管迈大步走,不相干的,这竹子桥规矩是咯吱咯喳的。” 一时进入榭中, 只见栏杆外另放着两张竹案,一个上面设着杯箸酒具,一个上头设着茶筅茶盂各色茶具.那边有两三个丫头煽风炉煮茶,这一边另外几个丫头也煽风炉烫酒呢. 贾母喜的忙问:“这茶想的到,且是地方,东西都干净。”湘云笑道:“这是宝姐姐帮着我预备的。”贾母道:“我说这个孩子细致,凡事想的妥当。”一面说,一面又看见柱上挂的黑漆嵌蚌的对子,命人念.湘云念道:
二、项目目标
- 按“回”分卷(如 01_第一回.txt)
- 去除垃圾信息(页眉、页脚、广告等)
- 使用 jieba 分词 + 自定义词典 + 停用词过滤
- 计算每回的 TF-IDF 值
- 输出每回 TF-IDF 排名前五的关键词
三、初版代码
import os
import pandas as pd
import jieba'''去除垃圾信息并分卷'''
file = open(r'红楼梦.txt', 'r', encoding='utf-8')
flag = 0
juan_file = open(r'红楼梦开头.txt', 'w', encoding='utf-8')
for line in file:if '卷 第' in line:juan_name = line.strip('\n') + '.txt'path = os.path.join(r'..\分卷', juan_name)print(path)if flag == 0:juan_file = open(path, 'w', encoding='utf-8')flag = 1else:juan_file.close()juan_file = open(path, 'w', encoding='utf-8')continueif '手机电子书·大学生小说网 更新时间' in line or line == '\n' \or '首页 | 原创' in line \or '本站长期招收' in line \or '后一页' in line \or '前一页' in line \or '回目录' in line \or '回首页' in line \or ' 第' in line \or ' 本书来自' in line \or '----------------' in line:continuejuan_file.write(line)
juan_file.close()
file.close()filePaths = []
fileContents = []
for root, dirs, files in os.walk(r'..\分卷'):for name in files:filePath = os.path.join(root, name)print(filePath)filePaths.append(filePath)f = open(filePath, 'r', encoding='utf-8')fileContent = f.read()f.close()fileContents.append(fileContent)corpus = pd.DataFrame({'filePath': filePaths,'fileContent': fileContents})
print(corpus)jieba.load_userdict(r'红楼梦词库.txt')
stopwords = pd.read_csv(r"StopwordsCN.txt", encoding='utf8', engine='python', index_col=False)file_to_jieba = open(r'分词后汇总.txt', 'w', encoding='utf-8')
for index, row in corpus.iterrows():juan_ci = ''fileContent = row['fileContent']segs = jieba.cut(fileContent)for seg in segs:if seg not in stopwords.stopword.values and len(seg.strip()) > 0:juan_ci += seg + ' 'file_to_jieba.write(juan_ci + '\n')
file_to_jieba.close()
运行结果:
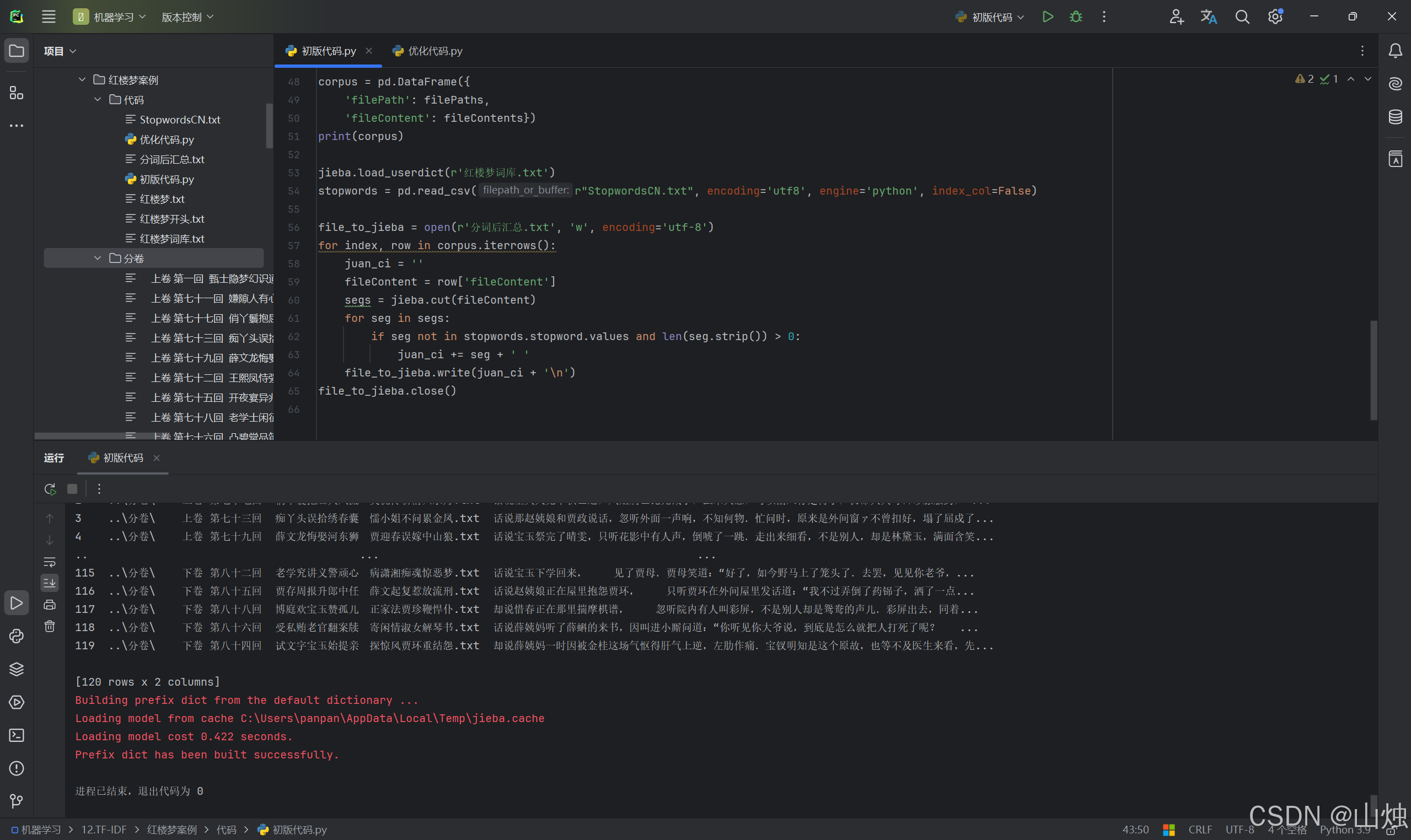
问题分析:
- flag 控制首次打开,不够优雅
- 文件未用 with 管理,可能泄漏
- 文件排序错误(字符串排序)
- 代码重复(多次 open/close)
- 变量命名不规范(juan_ci)
四、优化后代码
import os
import pandas as pd
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
import re# 创建分卷目录
output_dir = r'..\分卷'
os.makedirs(output_dir, exist_ok=True)# === 1. 分卷处理 ===
current_file = None
juan_count = 0with open(r'红楼梦.txt', 'r', encoding='utf-8') as f:for line in f:if '卷 第' in line:juan_name = line.strip().replace('卷 ', '').replace(' ', '_')juan_count += 1filename = f"{juan_count:02d}_{juan_name}.txt"path = os.path.join(output_dir, filename)print(path)if current_file:current_file.close()current_file = open(path, 'w', encoding='utf-8')continue# 垃圾信息过滤if any(keyword in line for keyword in ['手机电子书·大学生小说网 更新时间','首页 | 原创','本站长期招收','后一页', '前一页', '回目录', '回首页',' 第', ' 本书来自', '----------------']) or line == '\n':continueif current_file:current_file.write(line)if current_file:current_file.close()# === 2. 读取分卷文件(自然排序) ===
filePaths = []
fileContents = []def natural_sort_key(filename):return [int(c) if c.isdigit() else c for c in re.split(r'(\d+)', filename)]for root, dirs, files in os.walk(output_dir):for name in sorted(files, key=natural_sort_key):if name.endswith('.txt'):path = os.path.join(root, name)print(path)filePaths.append(path)with open(path, 'r', encoding='utf-8') as f:fileContents.append(f.read())corpus = pd.DataFrame({'filePath': filePaths, 'fileContent': fileContents})# === 3. 分词处理 ===
jieba.load_userdict(r'红楼梦词库.txt')
stopwords = pd.read_csv(r"StopwordsCN.txt", encoding='utf8', engine='python', index_col=False)with open(r'分词后汇总.txt', 'w', encoding='utf-8') as f_out:for content in corpus['fileContent']:words = [word for word in jieba.cut(content)if word.strip() and word not in stopwords.stopword.values]f_out.write(' '.join(words) + '\n')# === 4. TF-IDF 关键词提取 ===
with open(r'分词后汇总.txt', 'r', encoding='utf-8') as f:docs = [line.strip() for line in f]vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(docs)
words = vectorizer.get_feature_names_out()
scores = tfidf_matrix.toarray()for i, doc_scores in enumerate(scores):top5 = sorted(enumerate(doc_scores), key=lambda x: x[1], reverse=True)[:5]keywords = [(words[idx], round(score, 6)) for idx, score in top5]filename = os.path.basename(corpus.iloc[i]['filePath'])juan_num = filename.split('_')[0]print(f"第{juan_num}回的核心关键词是:{keywords}")
运行结果:
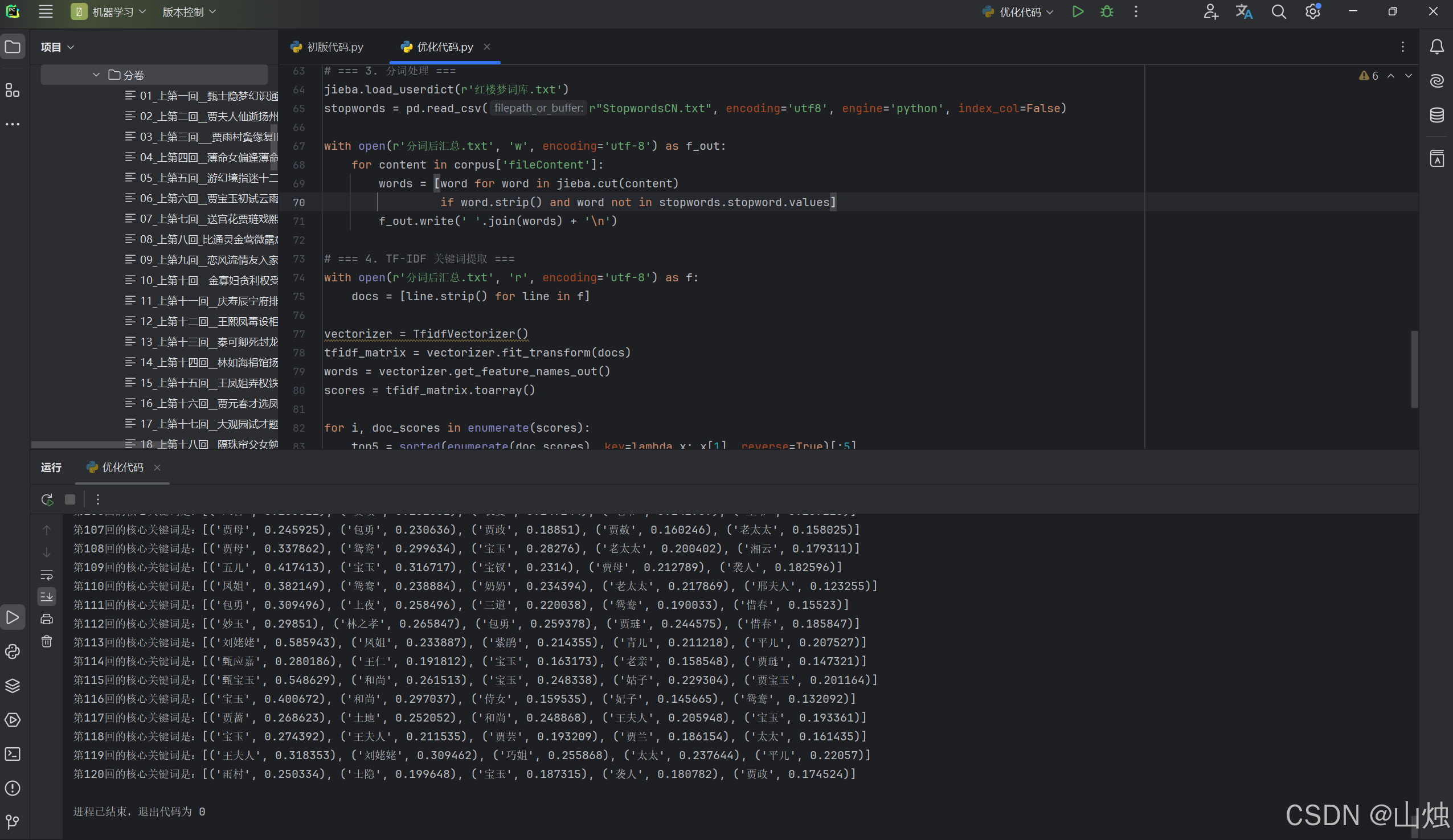
五、优化点对比
| 优化项 | 原始代码 | 优化后代码 |
|---|---|---|
| 文件操作 | 手动 open/close | 使用 with 自动管理 |
| 首次打开逻辑 | 使用 flag 标志位 | 直接判断 if current_file |
| 文件排序 | 字符串排序(错误) | 自然排序(正确) |
| 垃圾信息过滤 | 长 if 条件 | 使用 any() + 列表,可读性强 |
| 分词逻辑 | 字符串拼接 | 列表推导式 + ’ '.join() |
| TF-IDF 处理 | 多次遍历 | 向量化 + 紧凑逻辑 |
| 代码结构 | 混合在一起 | 模块化(分块注释) |
| 垃圾信息过滤 | 长 if 条件 | 使用 any() + 列表,可读性强 |
| 分词逻辑 | 字符串拼接 | 列表推导式 + ’ '.join() |
| TF-IDF 处理 | 多次遍历 | 向量化 + 紧凑逻辑 |
| 代码结构 | 混合在一起 | 模块化(分块注释) |
| 可维护性 | 低 | 高(变量命名清晰) |