使用HtmlAgilityPack+PuppeteerSharp+iText7抓取Selenium帮助文档
Selenium官网帮助文档的导航菜单为三层结构,如下图左侧所示,查看网页源码,其中导航菜单位于类名为ul-1的列表元素中,其内的每个li元素代表第一层级的菜单,其中类名中包含without-child的li元素为末级节点菜单,类名中包含with-child的li元素标识该菜单还有下级菜单。

基于上述导航菜单结构,编写了内容分析程序,分析每一层级的菜单名称及链接,主要代码如下所示:
// 获取导航菜单一级节点
HtmlNode node = docu.DocumentNode.SelectSingleNode(@"//ul[@class='ul-1']");HtmlNodeCollection tmpNode;
string curClass = string.Empty;
DataGridViewRow dgvr = null;
string level1Name=string.Empty, level2Name=string.Empty, level3Name = string.Empty;
string className = string.Empty;// 遍历第一层级菜单
foreach (HtmlNode subNode in node.ChildNodes)
{if ((subNode.Name != "li")){continue;}className = subNode.GetAttributeValue<string>("class", string.Empty);//如果没有下级节点,则记录一级菜单名称及链接if (className.Contains("without-child")){dgvr = new DataGridViewRow();dgvr.CreateCells(dataGridView1);dgvr.Cells[0].Value = dataGridView1.Rows.Count + 1;dgvr.Cells[1].Value = subNode.SelectSingleNode(".//span").InnerText; dgvr.Cells[4].Value = @"https://www.selenium.dev" + subNode.SelectSingleNode(".//a").Attributes["href"].Value;dataGridView1.Rows.Add(dgvr);}else{// 获取当前菜单的下级html结构foreach (HtmlNode childSubNode in subNode.ChildNodes){className = childSubNode.GetAttributeValue<string>("class", string.Empty);// 获取第二层级菜单名称及链接if ((childSubNode.Name == "a")){level1Name = childSubNode.InnerText;dgvr = new DataGridViewRow();dgvr.CreateCells(dataGridView1);dgvr.Cells[0].Value = dataGridView1.Rows.Count + 1;dgvr.Cells[1].Value = level1Name; dgvr.Cells[4].Value = @"https://www.selenium.dev" + childSubNode.Attributes["href"].Value;dataGridView1.Rows.Add(dgvr);}// 获取第二层级菜单列表if ((childSubNode.Name == "ul") && (className.Contains("ul-2"))){foreach (HtmlNode subChildSubNode in childSubNode.ChildNodes){if ((subNode.Name != "li")){continue;}className = subChildSubNode.GetAttributeValue<string>("class", string.Empty);// 如果第二层级菜单没有下级节点,则获取第二层级子菜单名称及链接if (className.Contains("without-child")){dgvr = new DataGridViewRow();dgvr.CreateCells(dataGridView1);dgvr.Cells[0].Value = dataGridView1.Rows.Count + 1;dgvr.Cells[1].Value = level1Name;dgvr.Cells[2].Value = subChildSubNode.SelectSingleNode(".//span").InnerText;dgvr.Cells[4].Value = @"https://www.selenium.dev" + subChildSubNode.SelectSingleNode(".//a").Attributes["href"].Value;dataGridView1.Rows.Add(dgvr);}else{// 获取第二层级菜单的下级html结构foreach (HtmlNode subChildSubNode2st in subChildSubNode.ChildNodes){className = subChildSubNode2st.GetAttributeValue<string>("class", string.Empty);// 获取第三层级菜单名称及链接if ((subChildSubNode2st.Name == "a")){level2Name = subChildSubNode2st.InnerText;dgvr = new DataGridViewRow();dgvr.CreateCells(dataGridView1);dgvr.Cells[0].Value = dataGridView1.Rows.Count + 1;dgvr.Cells[1].Value = level1Name;dgvr.Cells[2].Value = level2Name;dgvr.Cells[4].Value = @"https://www.selenium.dev" + subChildSubNode2st.Attributes["href"].Value;dataGridView1.Rows.Add(dgvr);}// 获取第三层级子菜单名称及链接if ((subChildSubNode2st.Name == "ul")){foreach (HtmlNode subChildSubNode3st in subChildSubNode2st.ChildNodes){dgvr = new DataGridViewRow();dgvr.CreateCells(dataGridView1);dgvr.Cells[0].Value = dataGridView1.Rows.Count + 1;dgvr.Cells[1].Value = level1Name;dgvr.Cells[2].Value = level2Name;dgvr.Cells[3].Value = subChildSubNode3st.SelectSingleNode(".//span").InnerText;dgvr.Cells[4].Value = @"https://www.selenium.dev" + subChildSubNode3st.SelectSingleNode(".//a").Attributes["href"].Value;dataGridView1.Rows.Add(dgvr);} }}}}}}}
}
内容分析程序的运行效果如下图所示,获取三个层级的菜单名称及链接地址后,即可调用PuppeteerSharp生成每个菜单页面的pdf文件,为便于后续生成pdf标签,将层级名称拼接在一起作为pdf文件名称。
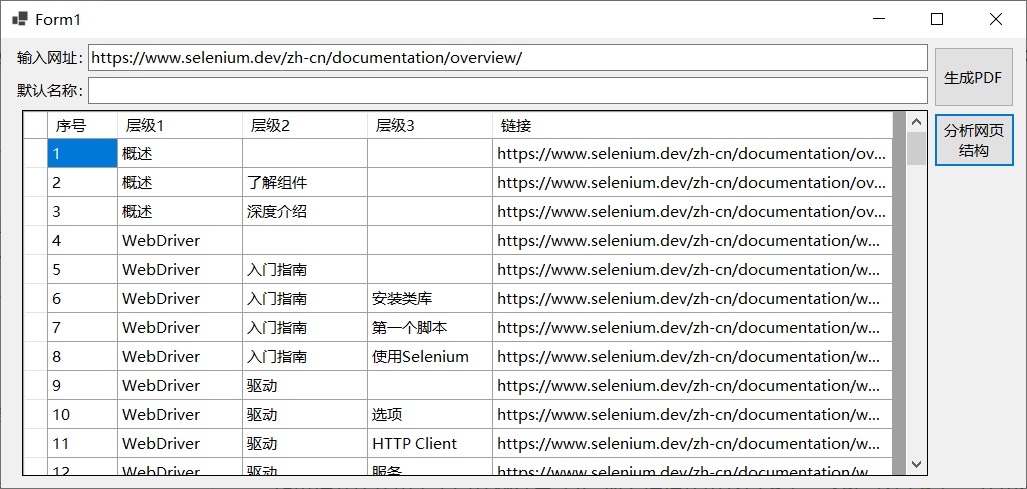
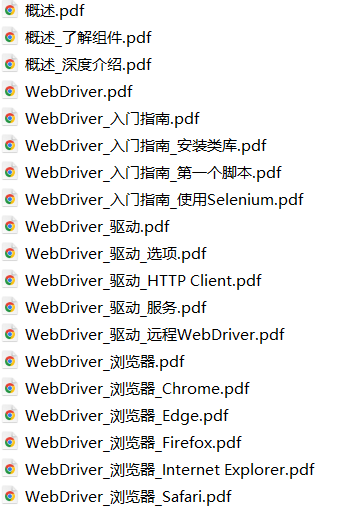
接着调用iText7合并所有pdf文件并生成三级标签,主要代码及程序运行效果如下所示:
PdfDocument pdfDoc = new PdfDocument(new PdfWriter(txtFileName.Text));
PdfMerger merger = new PdfMerger(pdfDoc);
merger.SetCloseSourceDocuments(false);List<PdfFileInfo> pdfFiles = GetSourceDocuments();// 合并所有pdf文档
foreach (PdfFileInfo doc in pdfFiles)
{merger.Merge(doc.docu, 1, doc.docu.GetNumberOfPages());
}PdfOutline rootOutline = pdfDoc.GetOutlines(false);
PdfOutline tmpOutline = null;
PdfOutline tmpSubOutlineLevel1 = null;
PdfOutline tmpSubOutlineLevel2 = null;
int curPageIndex = 1;
int underlineIndex = -1;
string tmpModule = "XXXXXX";
string tmpSubModule = "YYYYYY";foreach (PdfFileInfo doc in pdfFiles)
{string fileName = doc.FileName;string[] tmpParts = fileName.Split('_');// 生成第一层级标签if (tmpParts[0]!=tmpModule){tmpModule=tmpParts[0];tmpOutline = rootOutline.AddOutline(tmpModule);tmpOutline.AddDestination(PdfExplicitDestination.CreateFit(pdfDoc.GetPage(curPageIndex)));curPageIndex += doc.docu.GetNumberOfPages();}// 如果文件名称中包含第二层级菜单名称,则生成第二层级标签if(tmpParts.Length>1 && tmpParts[1]!=tmpSubModule){tmpSubModule=tmpParts[1];tmpSubOutlineLevel1 = tmpOutline.AddOutline(tmpSubModule);tmpSubOutlineLevel1.AddDestination(PdfExplicitDestination.CreateFit(pdfDoc.GetPage(curPageIndex)));curPageIndex += doc.docu.GetNumberOfPages();}// 如果文件名称中包含第三层级菜单名称,则生成第三层级标签if (tmpParts.Length > 2){tmpSubOutlineLevel2 = tmpSubOutlineLevel1.AddOutline(tmpParts[2]);tmpSubOutlineLevel2.AddDestination(PdfExplicitDestination.CreateFit(pdfDoc.GetPage(curPageIndex)));curPageIndex += doc.docu.GetNumberOfPages();}
}pdfDoc.Close();foreach (PdfFileInfo doc in pdfFiles)
{doc.docu.Close();
}
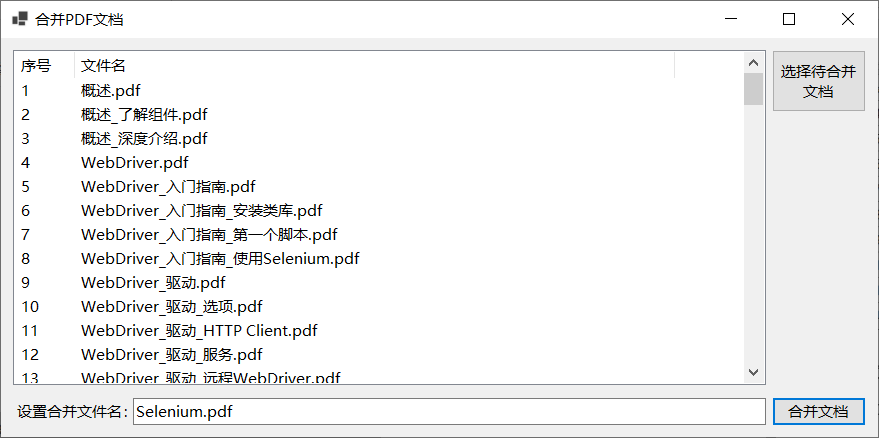
最终生成的pdf文档如下所示,已将文档上传到资源中,有需要的可以下载:
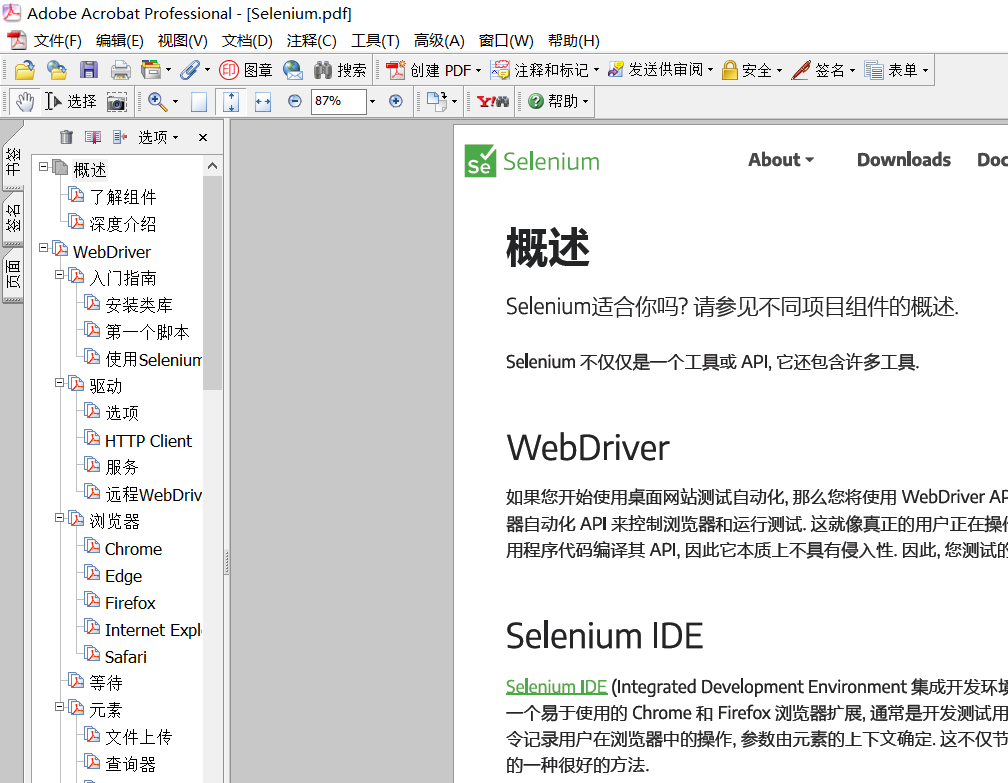
生成的pdf文档还存在以下2个问题:
1)Selenium支持多种语言,因此部分页面中存在多语言的标签页,方便查看对应语言的Selenium使用方式,使用HtmlAgilityPack+PuppeteerSharp获取网页生成pdf时,默认显示的是网页中第一个标签页的内容,暂时不知道如何切换到其它标签页再生成pdf;
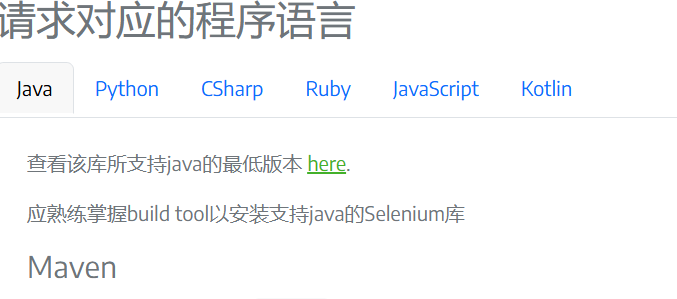
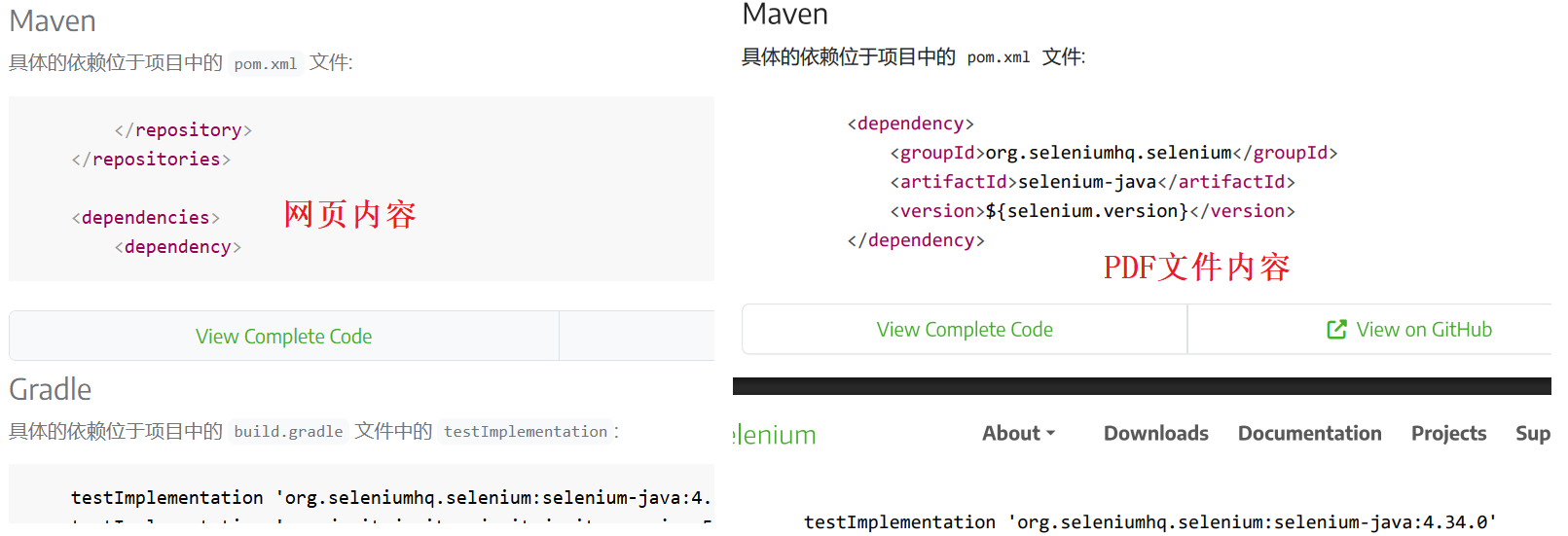
2)生成PDF文件按A4纸生成,原本在网页中连续的内容,生成pdf文件时位于两页内容夹着的部分会被遮挡或隐藏,暂时不知道该如何处理(使用浏览器的打印功能生成的pdf文件也有类似的情况)。
参考文献
[1]https://www.selenium.dev/zh-cn/documentation/overview/