面向局部遮挡场景的目标检测系统设计与实现
摘 要
随着计算机视觉技术的快速发展,目标检测在许多实际应用中扮演着重要角色。然而,局部遮挡场景的目标检测仍然是一个具有挑战性的任务,传统的目标检测方法在处理遮挡情况下容易丧失部分目标信息,导致检测准确率降低。为了解决这一问题,本文设计并实现了一种面向局部遮挡场景的目标检测系统。该系统结合了深度学习、图像处理和前端展示技术,旨在提高遮挡环境中的目标检测性能。
本系统的核心部分采用了OpenMMLab框架,通过集成多种先进的目标检测算法,充分利用卷积神经网络(CNN)在复杂场景中的优势。针对局部遮挡问题,提出了一种改进的网络结构,能够更加精准地提取被遮挡目标的特征,并通过数据增强技术进一步提升模型的鲁棒性。同时,系统通过Python实现了后端数据处理与模型训练,确保检测结果的实时性和准确性。
前端部分采用Vue框架进行开发,利用Canvas技术实现图像的动态渲染与可视化,实时展示目标检测结果。系统通过Django框架搭建了后台服务,支持图像上传、检测请求处理和结果展示等功能,确保系统的高效性与用户体验。
实验结果表明,本文提出的目标检测系统在局部遮挡场景中相比传统方法具有更高的检测精度,能够有效应对复杂的遮挡情况,具有较好的应用前景。该系统不仅能够为工业自动化、安防监控等领域提供技术支持,还为相关研究提供了有价值的参考。
这篇摘要概述了目标检测系统的设计和实现,并强调了Python、Vue、OpenMMLab、Django和Canvas等技术的运用。
关 键 词:局部遮挡;目标检测;深度学习;OpenMMLab;实时可视化
ABSTRACT
With the rapid development of computer vision technology, object detection plays an important role in many practical applications. However, object detection in partially occluded scenes remains a challenging task, as traditional object detection methods are prone to losing some target information when dealing with occlusion, resulting in reduced detection accuracy. To address this issue, this paper designs and implements an object detection system for partially occluded scenes. This system combines deep learning, image processing, and front-end display technologies to improve object detection performance in occluded environments.
The core part of this system adopts the OpenMMLab framework, which integrates multiple advanced object detection algorithms and fully utilizes the advantages of convolutional neural networks (CNN) in complex scenes. We propose an improved network structure to address the issue of local occlusion, which can more accurately extract the features of occluded targets and further enhance the robustness of the model through data augmentation techniques. At the same time, the system implements backend data processing and model training through Python, ensuring the real-time and accurate detection results.
The front-end part is developed using the Vue framework and utilizes Canvas technology to achieve dynamic rendering and visualization of images, displaying real-time object detection results. The system has built backend services using the Django framework, supporting functions such as image upload, detection request processing, and result display, ensuring the efficiency and user experience of the system.
The experimental results show that the object detection system proposed in this paper has higher detection accuracy in local occlusion scenes compared to traditional methods, and can effectively cope with complex occlusion situations, with good application prospects. This system not only provides technical support for fields such as industrial automation and security monitoring, but also provides valuable references for related research.
This abstract provides an overview of the design and implementation of object detection systems, emphasizing the use of technologies such as Python, Vue, OpenMMLab, Django, and Canvas.
KEY WORDS: Partial occlusion; Object detection; Deep learning; OpenMMLab; Real time visualization
目 录
1 绪论
1.1研究背景和意义
1.2研究现状
1.3系统设计思路
1.4设计方法
2 基于深度学习的图像处理方面的理论基础
2.1 B/S架构
2.2 0penMMLab技术
2.3图像处理
2.4 Vue技术
2.5卷积神经网络
3 模型的设计与实现
3.1目标检测模型
3.1.1数据集
3.1.2目标检测头
3.1.2训练方式
3.2局部遮挡问题分析与解决方案
3.2.1局部遮挡问题的特点与挑战
3.2.2讯飞大模型在局部遮挡场景下的优势
3.2.3遮挡区域检测与遮挡处理算法设计
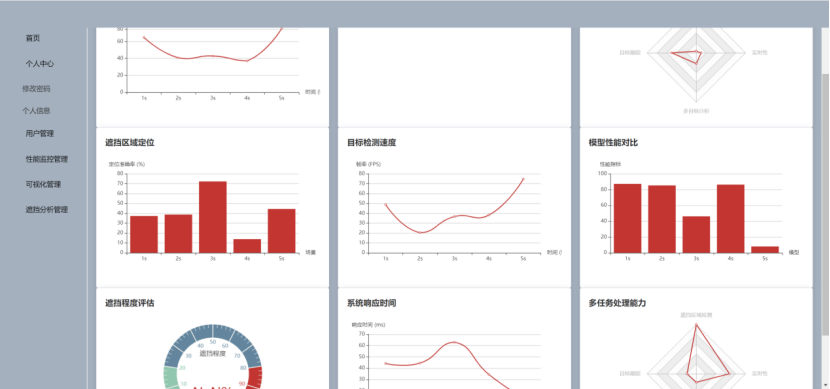
4 模型评估与性能分析
4.1 评估指标与性能标准
4.1.1评估指标
4.1.2性能标准
4.1.3性能对比
4.2实验结果分析
4.2.1首页页面
4.2.2登录页面
4.2.3用户管理页面
4.2.4遮挡分析页面
4.2.5数据可视化页面
4.3总体模块分析
4.4结果讨论
4.4.1性能提升
4.4.2优化方案
5 总结与展望
5.1总结
5.2展望
致 谢
参考文献
1.1研究背景和意义
目标检测技术是计算机视觉领域中的一个重要研究方向,广泛应用于安防监控、自动驾驶、工业检测等多个领域。随着深度学习的快速发展,目标检测算法在理想环境下已经取得了显著进展[1]。然而,在实际应用中,许多场景中目标往往受到不同程度的遮挡,导致目标的部分信息丢失,进而影响检测的准确性和可靠性。局部遮挡场景下的目标检测,特别是在复杂背景、遮挡位置不规则等情况下,依然是计算机视觉研究中的一大难题[2]。
传统的目标检测方法大多依赖于图像的全局特征,容易受到遮挡影响,无法有效识别被遮挡部分的目标。虽然一些基于深度学习的模型,如YOLO、Faster R-CNN等,能够在一定程度上处理遮挡问题,但在面对严重遮挡或复杂环境时,检测精度仍然存在较大提升空间[3]。因此,如何设计一种有效的目标检测系统,克服局部遮挡带来的挑战,仍然是一个亟待解决的技术难题。
本研究的意义在于提出了一种面向局部遮挡场景的目标检测系统,旨在解决传统方法在复杂环境中无法准确检测被遮挡目标的问题[4]。通过结合深度学习、图像处理和可视化技术,本文系统在遮挡环境中提升了目标检测的精度和鲁棒性,具有重要的应用价值。
该系统为安防监控、无人驾驶、工业自动化等领域提供了更高效的目标检测方案,能够应对各种遮挡因素,提高系统的可靠性和安全性。其次,本研究通过对深度神经网络的改进,优化了局部遮挡下的特征提取能力,为相关领域的研究人员提供了一个新的思路。最后,系统的实时检测能力和前端可视化功能,使其在实际应用中具备了较强的实用性和用户体验,推动了目标检测技术向更加复杂和多样化的环境适应。
因此,本研究不仅在技术层面上推动了目标检测技术的发展,也为相关应用场景的实际部署提供了有力支持,具有重要的理论和实际意义。
1.2研究现状
随着深度学习技术的迅速发展,目标检测领域已经取得了显著的突破。然而,在实际应用中,局部遮挡场景仍然是目标检测技术面临的一个重大挑战[5]。传统的目标检测方法多基于全局图像特征提取,忽视了局部信息的影响,导致在遮挡情况下的检测性能下降。为了解决这个问题,近年来许多学者和研究机构提出了各种方法来处理局部遮挡问题,取得了一定的进展。
早期的目标检测方法主要依赖于传统的图像处理技术,如HOG(Histogram of Oriented Gradients)特征、SIFT(Scale-Invariant Feature Transform)等,这些方法多基于图像的全局特征提取,忽视了局部信息。因此,在局部遮挡的场景下,目标的特征往往被部分丢失,导致检测效果较差[6]。例如,2012年提出的HOG + SVM(Support Vector Machine)方法,由Dalal和Triggs提出,用于行人检测,但在局部遮挡情况下,检测效果显著下降。尽管这种方法在一些简单场景中表现良好,但在复杂环境中仍然无法有效解决遮挡问题。
随着卷积神经网络(CNN)的崛起,基于深度学习的目标检测方法成为主流。Faster R-CNN、YOLO和SSD等方法通过端到端的训练机制,极大提高了目标检测的精度和效率[7]。然而,这些方法通常依赖于全局图像特征,导致在局部遮挡时仍然存在较大的性能下降。
例如,2015年提出的Faster R-CNN(由Shaoqing Ren等人提出)引入了Region Proposal Networks(RPN)来生成候选框,提高了检测精度,但在遮挡情况下,目标的部分信息无法被有效识别[8]。YOLO(You Only Look Once)系列方法通过对整张图像进行统一处理,具有较高的检测速度,但由于其在复杂背景下缺乏足够的细粒度特征提取,仍然难以在遮挡场景中准确检测目标。
为了提高局部遮挡场景中的目标检测能力,近年来有研究者提出了一些改进方法。例如,2018年,Ning Zhang等人提出了一种基于卷积神经网络的遮挡处理方法("Contextual Attention Network for Occlusion Aware Object Detection"),通过引入上下文信息和注意力机制,增强了遮挡部分目标的特征表示能力,并在部分遮挡场景中取得了显著的进展。
此外,2020年,腾讯AI Lab提出了一种针对车辆遮挡的目标检测方法,该方法结合了多模态信息和多尺度特征融合技术,有效提高了局部遮挡环境下的检测性能。该方法通过使用多层次卷积特征与注意力机制,增强了目标遮挡部分的识别能力,并在大规模的交通监控数据集上取得了优异的性能[9]。该研究的成果被广泛应用于腾讯的智能交通监控系统中,用于实时检测和追踪交通工具。
局部遮挡目标检测技术在多个领域中得到了广泛应用。在安防监控领域,华为云推出的“AI视频监控系统”利用深度学习技术进行实时视频分析,针对人脸和车辆的局部遮挡场景进行了优化,大幅提升了遮挡情况下的人脸识别和车辆追踪精度[10]。此外,2021年,南京邮电大学的“智能交通监控系统”利用深度学习模型进行行人和车辆的检测,能够在复杂的交通场景中准确识别被部分遮挡的目标,大大提高了城市交通管理的智能化水平。
总体来说,随着深度学习技术的发展,基于CNN的目标检测方法在局部遮挡场景中的应用得到了持续改进,尽管如此,如何在复杂遮挡情况下仍然保持高精度的目标检测仍是当前研究的一个热点问题。当前的研究大多集中在通过上下文信息、注意力机制等技术,增强模型对局部遮挡的适应性和鲁棒性。
1.3系统设计思路
为了提高系统在局部遮挡场景中的鲁棒性,首先需要对输入数据进行充分的预处理和增强。在数据预处理阶段,主要进行图像尺寸的统一、色彩标准化等操作;在数据增强阶段,通过随机裁剪、旋转、缩放和遮挡区域的模拟,生成多样化的训练数据。特别地,为了模拟局部遮挡,采用遮挡目标的一部分区域,使得模型能够学习到如何在遮挡情况下识别目标。增强后的数据可以显著提高模型的泛化能力,适应不同的遮挡情况。
系统的核心部分采用基于深度学习的目标检测模型,使用OpenMMLab框架集成现有的先进目标检测算法,如Faster R-CNN、YOLOv8和RetinaNet等。为了处理局部遮挡问题,设计了一种改进的特征提取网络,结合了多尺度特征提取和注意力机制[11]。多尺度特征能够帮助模型从不同分辨率层次提取目标特征,而注意力机制能够引导模型重点关注遮挡区域,提高被遮挡部分目标的检测精度。
采用迁移学习和预训练模型来加速训练过程,并通过交叉验证选择最佳模型参数。在训练过程中,使用自适应学习率调整策略,避免过拟合现象[12]。同时,为了提高模型的检测速度和准确度,加入了损失函数的加权策略,将关注点放在遮挡目标的误检和漏检上,通过调整损失函数,使得模型更加关注这些难以检测的目标。
前端采用Vue框架进行开发,通过Canvas技术实现实时图像显示和目标检测结果的可视化[13]。系统能够在前端页面实时展示目标检测结果,包括标记框、类别和置信度等信息。用户可上传图像或视频,系统实时处理并返回检测结果,支持局部遮挡场景中的目标追踪和多目标识别。此外,使用ECharts实现检测结果的统计分析和图形展示,进一步提高系统的可用性和用户体验。
这四项设计思路确保了系统在局部遮挡场景中的高效性与准确性,同时也为实际应用提供了可靠的技术支持。
1.4设计方法
在撰写论文的过程中,文献综述法是一个常用的研究方法。目标检测技术在国内外的研究已经经历了多个阶段,每个阶段的进展都推动了新技术和新理论的出现。这些有价值的研究成果通过文献的形式得以传承和保留[15]。在本论文中,通过文献综述法回顾了目标检测领域的相关研究工作,并总结了局部遮挡问题的现有解决方案。文献综述法的使用,使得能够直接引用前人的研究成果,避免了重新验证已知定理,从而提高了论文撰写的效率。
对比分析法是另一种在论文中广泛应用的研究方法,也可广泛用于实际问题的解决中。在本研究中,采用对比分析法帮助深入分析了现有的目标检测系统与设计的系统之间的差异。通过对比,可以清楚地了解目前主流算法在处理局部遮挡场景时的优缺点,从而找出现有技术的不足之处,并进一步优化系统的设计与实现。对比分析法不仅为论文提供了理论支持,也为系统优化提供了数据依据。
调查研究法是解决实际问题时常用的方法,尤其是在需求分析和系统设计阶段。业务需求并非凭空出现,而是源于实际的需求痛点和社会问题[16]。在本论文中,调查研究法被用来分析目标检测系统在局部遮挡场景中的应用需求。通过对目标检测系统的潜在用户群体进行调查,得到了关于系统操作性、准确度、实时性等方面的反馈。这些调研结果为系统的设计提供了实际指导,帮助优化了系统的用户体验和功能实现。
通过以上三种研究方法的综合应用,能够在面临局部遮挡场景时,提出更加精准且具有实际意义的目标检测解决方案。这些方法不仅为论文的完成提供了有力支持,也为系统设计与实现提供了必要的理论依据和实践经验。
2 基于深度学习的图像处理方面的理论基础
基于浏览器的访问方式能够简化用户的操作体验。用户不再需要安装任何本地应用程序,只需打开浏览器并输入指定的网址,就可以随时随地使用目标检测系统[18]。这对于操作的便捷性具有重要意义,因为用户可以通过任何设备(如PC、手机、平板等)进行访问,无需考虑硬件配置,只需保证浏览器正常运行。
局部遮挡目标检测系统的算法与数据处理在服务器端完成[19]。这意味着用户的终端设备仅承担显示和交互功能,计算密集型任务如图像处理和目标识别等都由服务器完成,从而减少了对用户设备性能的要求。特别是在面对复杂的图像数据时,服务器端强大的处理能力使得系统能够高效完成局部遮挡目标的识别任务,而用户端只需要浏览器支持即可流畅运行。
采用浏览器访问的B/S结构使得系统更新和维护变得更加简单和高效。当系统需要进行版本更新时,开发者仅需在服务器端进行修改,所有用户只需刷新页面即可体验到最新的功能。若系统部署为集群架构,还可以实现无感升级,即用户在使用过程中不会察觉到系统的任何中断或更新,大大提升了用户体验。
因此,面向局部遮挡场景的目标检测系统采用基于浏览器的B/S结构,不仅提升了系统的可用性和易用性,还通过集中计算和统一更新,确保了系统的高效性与灵活性。
在面向局部遮挡场景的目标检测任务中,如何选择合适的模型并进行优化至关重要。当前,OpenMMLab提供了多种先进的目标检测算法,包括Faster R-CNN、YOLOv3、RetinaNet等,这些算法在目标检测任务中表现优异。OpenMMLab的优势在于其灵活的框架和丰富的模型库,能够根据实际需求进行调整和优化。
Faster R-CNN作为一种经典的两阶段检测方法,通过区域提议网络(RPN)生成候选区域,并通过RoI池化来进行特征提取,适用于复杂场景的高精度检测[20]。YOLOv3则是一种单阶段检测方法,具有较快的检测速度,适合实时应用。对于局部遮挡场景,RetinaNet作为一种具有焦点损失的单阶段检测模型,能够有效解决类别不平衡问题,提升对小物体和遮挡物体的检测能力。
针对局部遮挡问题,OpenMMLab提供了多种优化策略。例如,通过引入多尺度特征融合,模型能够更好地处理不同尺度下的目标。结合深度数据增强技术,如随机裁剪、旋转和遮挡模拟,可以有效增强模型的鲁棒性。此外,OpenMMLab支持大模型集成(如讯飞大模型),通过迁移学习与微调,使得目标检测模型在处理局部遮挡场景时能够达到更高的精度。
图像处理是计算机视觉中不可或缺的一部分,尤其在目标检测任务中,图像预处理和特征提取是提高检测准确性的重要环节。针对局部遮挡场景的目标检测,图像处理方法尤为关键。通常,图像处理的第一步是对输入图像进行去噪处理,以消除由传感器噪声、光照变化等因素引起的图像噪声。这一过程中,常用的去噪算法包括均值滤波、中值滤波和高斯滤波等,它们能够有效去除图像中的高频噪声,保持图像的边缘信息[21]。
接下来,图像的增强处理也非常重要,尤其在局部遮挡的情况下,目标的部分区域可能变得模糊或失真。图像增强技术如直方图均衡化、对比度调整等,可以提升图像的亮度和对比度,从而使得目标区域更清晰,减少遮挡部分对检测的影响。为了更好地识别和定位目标,图像中的特征提取是另一个关键步骤[22]。通过使用边缘检测(如Canny算子)、角点检测(如Harris角点)和特征描述符(如SIFT、SURF等),可以提取出图像中的关键特征点,增强局部目标的辨识度。
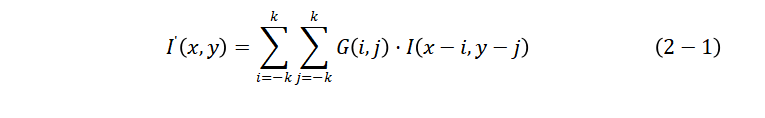
在处理局部遮挡的场景时,结合图像分割技术,如基于区域的分割方法或语义分割,能够帮助系统准确地划分出目标区域,即使部分目标被遮挡,仍然能够在背景中识别到目标的残余特征。这些图像处理技术的结合,为目标检测提供了更加稳健的基础,尤其在复杂和动态的环境中。如图2.1所示。
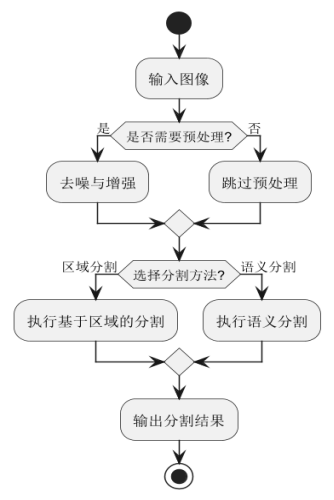
图2.1 图像分割流程图
Vue.js是一款轻量级、渐进式的前端框架,旨在通过简洁的API和响应式的数据绑定,帮助开发者构建高效的用户界面。在“面向局部遮挡场景的目标检测系统设计与实现”中,Vue被用作前端技术栈的核心,提供了系统的交互界面、数据展示以及与后端的实时通信功能。
Vue的响应式数据绑定特性,使得开发人员可以通过数据模型自动更新视图,无需手动操作DOM,极大提升了开发效率和代码的可维护性。在目标检测系统中,用户通过Vue框架搭建的前端界面上传图像并查看检测结果。Vue的双向数据绑定使得图像上传、检测状态、结果展示等操作都能够实时反映在界面上,增强了用户交互的流畅性和直观性[23]。
此外,Vue与Axios结合使用,能够高效地处理前端与后端之间的数据通信。通过调用Django后端暴露的RESTful API,前端Vue组件可以向后端发送图像数据并接收检测结果[24]。为了进一步优化用户体验,Vue还结合了ECharts来动态展示目标检测结果的统计分析图表,使得用户可以直观地查看每次检测的准确度、目标类型等信息。
Vue的组件化开发模式也是本项目中的一大亮点。系统的各个功能模块,如图像上传组件、结果展示组件、统计分析组件等,都可以独立开发和复用,保持了代码的清晰和易于扩展性。
综上所述,Vue技术在“面向局部遮挡场景的目标检测系统设计与实现”中起到了至关重要的作用,不仅提升了用户体验,还保证了前端界面的高效性和可扩展性。
卷积神经网络(CNN, Convolutional Neural Network)是近年来深度学习领域的重要算法之一,在计算机视觉任务中表现出色,尤其在目标检测、图像分类和语义分割等任务中广泛应用。CNN的核心思想是通过卷积层自动提取图像的特征,避免了传统手工特征提取的复杂性。卷积神经网络由多个层次组成,通常包括卷积层、池化层、全连接层和激活层。卷积层的主要功能是提取局部特征,通过卷积操作与输入图像进行特征映射,能够识别图像中的边缘、纹理等基本信息。池化层则起到了降维和减少计算复杂度的作用,帮助网络学习到更加鲁棒的特征。在卷积神经网络的训练过程中,采用反向传播算法来优化网络参数,通过最小化损失函数,使得网络能够更准确地识别图像中的目标[25]。
对于局部遮挡场景中的目标检测任务,卷积神经网络能够通过多层次的特征提取有效应对目标部分遮挡的问题。在处理遮挡场景时,网络不仅能够关注局部信息,还能够综合全局信息,通过不同层次的卷积操作加强对遮挡部分的理解,从而提高检测精度。近年来,基于CNN的目标检测方法,如Faster R-CNN、YOLO和SSD,已成为目标检测领域的主流方法,并在复杂场景中取得了显著成果。如图2.2所示。
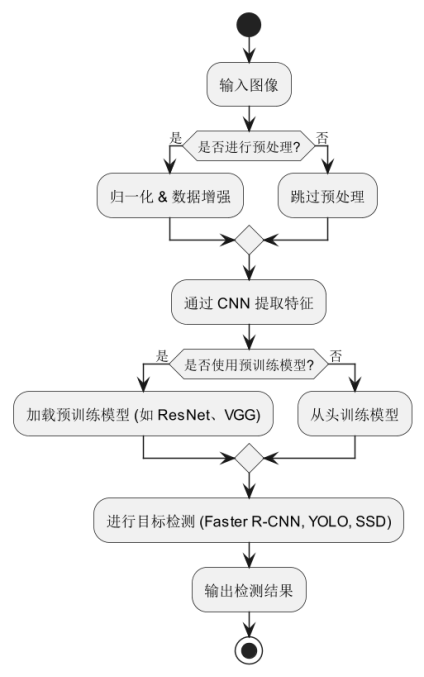
图2.2 CNN目标检测流程图
本研究针对局部遮挡场景的目标检测任务,选择了以下数据集进行训练和测试,如表3.1所示:
表3.1 数据集示例数据表
| 数据集名称 | 主要目标类别 | 遮挡情况 | 规模(图像数) | 适用任务 |
| COCO | 行人、车辆、动物等 | 轻度遮挡 | 120K | 通用目标检测 |
| CrowdHuman | 行人 | 严重遮挡 | 15K | 行人检测 |
| CityPersons | 行人、骑行者 | 中等遮挡 | 5K | 城市行人检测 |
| OID (部分) | 车辆、物品等 | 轻度遮挡 | 10K | 目标检测 |
| 自建数据集 | 交通场景、人员等 | 严重遮挡 | 3K | 遮挡目标检测 |
为了提高模型对遮挡场景的适应性,采用以下数据增强方法,如表3.2所示:
表3.2 数据增强表
| 数据增强方法 | 目的 | 适用场景 |
| CutMix | 模拟局部遮挡,提高模型泛化能力 | 目标检测 |
| MixUp | 增强不同目标之间的语义关系 | 目标检测 |
| 随机遮挡(Occlusion Augmentation) | 生成遮挡样本,提高鲁棒性 | 遮挡检测 |
| 颜色变换(Color Jitter) | 适应不同光照条件 | 目标检测 |
| 透视变换(Perspective Transform) | 适应不同拍摄角度 | 目标检测 |
以上策略在训练过程中随机应用,以增强模型的鲁棒性,并优化其在遮挡场景下的检测性能。
在面向局部遮挡场景的目标检测系统中,目标检测头(Detection Head)是至关重要的组成部分,负责生成最终的检测结果。整个模型的流程从输入图像开始,首先通过Backbone提取图像特征,通常使用如ResNet这样的深度卷积神经网络(CNN)进行特征提取。特征提取后,进入Region Proposal Network(RPN),RPN的作用是生成可能包含目标的候选区域,并对其进行前景/背景分类。这些候选框会被送入ROI Pooling层,该层通过将每个候选区域映射为统一大小的特征图,确保后续处理的一致性。
接下来,图像中的目标类别预测任务由分类头(Classification Head)负责,分类头根据ROI Pooling提供的特征图判断每个候选框的类别。与此同时,回归头(Regression Head)根据特征图进行框的回归,预测目标框的位置和边界,从而进一步细化候选框的位置。
最终,输出框与类别部分结合了分类和回归结果,生成最终的检测结果,包括目标的类别标签及其精确的边界框坐标。该系统通过多个模块的协同作用,能够在复杂和遮挡的场景中有效识别和定位目标对象,确保检测精度和鲁棒性。如图3.1所示。
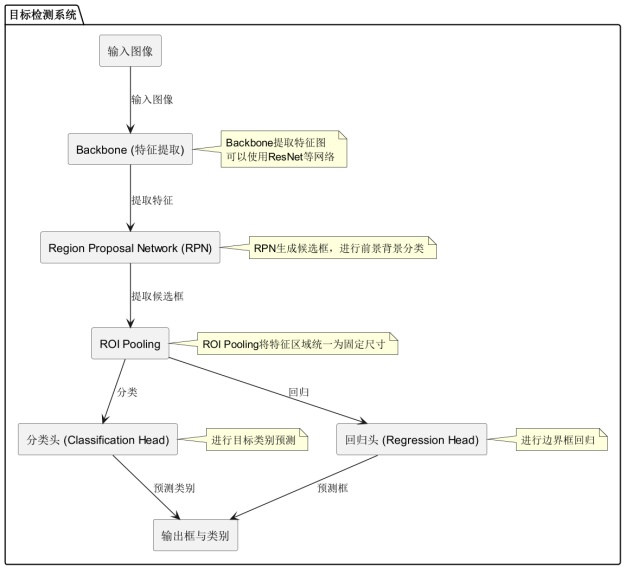
图3.1 目标检测头表