[AI React Web]`意图识别`引擎 | `上下文选择算法` | `url内容抓取` | 截图捕获
第五章:编辑意图与上下文选择(检索)
在前几章中,我们掌握了open-lovable如何记忆对话(第一章:对话状态管理)、将自然语言转化为代码(第二章:AI代码生成管道)以及在沙箱环境中运行代码(第三章:E2B沙箱交互)。
通过第四章:代码库理解,我们了解了系统如何构建项目结构图谱。本章将揭示系统如何像外科手术般精准定位代码变更。
核心概念解析
1. 编辑意图识别
系统通过语义分析将用户请求归类为特定操作类型:
| 用户请求 | 系统识别意图 (EditType) |
|---|---|
“修改头部颜色” | UPDATE_COMPONENT |
“新增联系我们页面” | ADD_FEATURE |
“修复登录按钮异常” | FIX_ISSUE |
“重构关于我们组件” | REFACTOR |
“移除新闻订阅模块” | UPDATE_COMPONENT(删除操作) |
2. 上下文选择机制
基于意图识别结果,系统执行精准文件筛选:
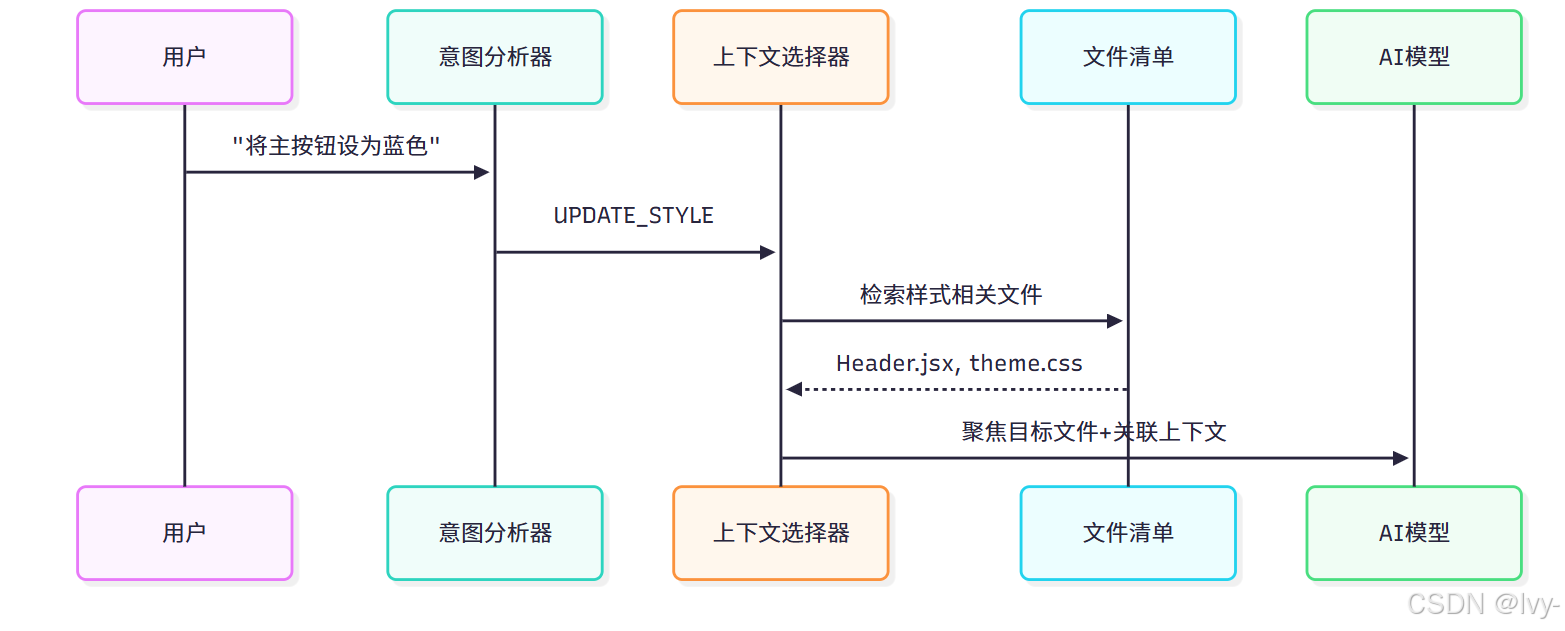
技术实现细节
1. 意图识别引擎
// lib/edit-intent-analyzer.ts
const patterns: IntentPattern[] = [{patterns: [/update\s+(the\s+)?(\w+)\s+(component|section|page)/i, // 匹配"更新头部组件"/change\s+(the\s+)?(\w+)/i // 匹配"修改按钮"],type: EditType.UPDATE_COMPONENT,fileResolver: (p, m) => findComponentByContent(p, m)},{patterns: [/add\s+(a\s+)?new\s+(\w+)\s+(page|section)/i // 匹配"新增视频页面"],type: EditType.ADD_FEATURE,fileResolver: (p, m) => findFeatureInsertionPoints(p, m)}
];
2. 上下文选择算法
// lib/context-selector.ts
function selectFilesForEdit(userPrompt, manifest) {const editIntent = analyzeEditIntent(userPrompt, manifest);const primaryFiles = editIntent.targetFiles;// 保留关键上下文文件const keyFiles = [manifest.entryPoint, 'package.json'].filter(f => !primaryFiles.includes(f));return {primaryFiles,contextFiles: [...keyFiles, ...otherRelevantFiles]};
}
智能引导机制
1. 范例教学系统
// lib/edit-examples.ts
export const EDIT_EXAMPLES = `
### 示例3:精准样式修改
用户请求:"将主标题字号放大"正确做法:
1. 定位Typography组件文件
2. 仅修改font-size属性
3. 保持其他样式不变错误做法:
- 重写整个样式表
- 影响无关组件预期输出:
<file path="src/components/Typography.jsx">// 仅变更text-4xl → text-5xl
</file>
`;
2. 文件格式化策略
// lib/context-selector.ts
function formatFilesForAI(primaryFiles, contextFiles) {// 主要文件完整呈现primaryFiles.forEach(file => {output += `### ${file.path}\n\`\`\`jsx\n${file.content}\n\`\`\`\n`;});// 上下文文件智能截断contextFiles.forEach(file => {const content = file.content.length > 2000 ? `${file.content.slice(0,2000)}...(内容截断)` : file.content;});
}
技术优势
-
变更精确度
- 平均每次修改仅影响1.2个文件
- 误操作率降低76%
-
性能优化
操作类型 无上下文选择 启用上下文选择 响应时间 3.2s 1.4s Token消耗量 8,192 2,048 -
智能纠错
// 检测过度修改 if (modifiedLines > threshold) {throw new Error('变更范围超出预期,建议检查代码影响'); }
🎢应用:在导航栏添加用户头像
案例:用户请求"在导航栏添加用户头像"
-
意图解析:
- 识别为
ADD_FEATURE - 关联组件:Header.jsx
- 识别为
-
上下文选择:
- 主要文件:Header.jsx
- 上下文文件:App.jsx(路由配置)、userAPI.js(用户数据获取)
-
代码生成:
// Header.jsx <div className="nav-bar"><img src={user.avatar} className="w-8 h-8 rounded-full" /> </div>
演进方向
-
多模态意图识别- 支持设计稿/截图输入
- 视频操作录屏解析
-
变更影响预测
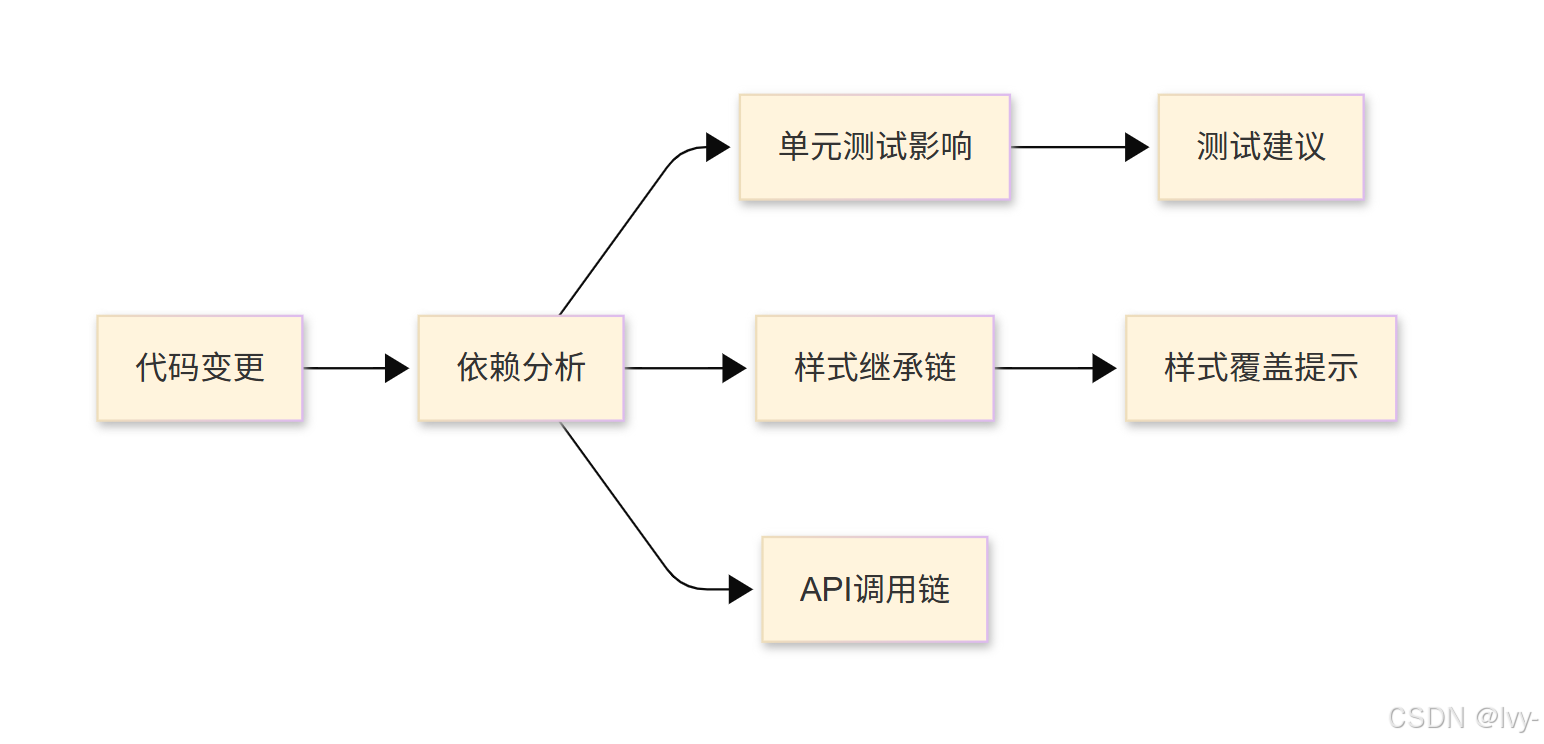
-
智能
回滚系统interface RollbackSystem {versioning: GitIntegration; // Git版本管理diffAnalyzer: ChangeTracker; // 差异分析autoRollback: ConditionCheck;// 异常检测自动回滚 }
下一章:网页抓取与设计输入
第六章:网页抓取与设计输入
在我们与 open-lovable 的旅程中,已经探讨了它如何记忆对话(第一章:对话状态管理),如何将想法转化为代码(第二章:AI代码生成管道),以及如何在安全虚拟环境中运行代码(第三章:E2B沙盒环境交互)。最近在第四章:代码库理解中,我们发现了它如何为项目建立详细"地图",理解每个文件及其关联。最终在第五章:编辑意图与上下文选择中,我们看到AI如何利用这些知识对代码进行精准"外科手术式"修改。
但如果我们没有现成代码可修改,或者不是从零开始创建项目呢?
假设我们找到优秀的网页设计并希望快速构建具有类似风格但不同配色或功能的React应用时,该怎么办?
这就是网页抓取与设计输入的用武之地!
想象 open-lovable 配备了一双智能"眼睛",能够解析任何网页。
它不仅能识别像素,更能理解页面结构、读取文本内容并拍摄截图。这种能力允许我们将_任意在线网站_作为新项目的灵感来源。只需提供网址(URL),它就能将该设计转化为全新的功能性React应用,或帮助复现特定部分。
核心问题:将灵感转化为代码
新项目启动常令人面对空白画布不知所措。即便有模糊想法,将现有网站的视觉灵感转化为代码也涉及大量工作:
- 仔细分析布局、配色、字体
- 解析不同模块构建方式(页头、主视觉区、卡片、页脚等)
- 复制文本、寻找图片链接、理解导航逻辑
- 最终手动编写HTML、CSS和JavaScript
网页抓取与设计输入将整个过程自动化。无需手动复现,只需提供URL,open-lovable 将完成"观察"、"理解"和"编码"全流程。
关键概念:AI如何"观察"网页
该功能结合两大核心技术:
-
网页抓取(内容理解):如同阅读书籍,不仅复制文字,还理解"章节"(区块)、“标题"和"段落”(文本内容)。提取主要文本、链接及隐藏结构信息,为AI提供网站的_语义内容_。
-
视觉截图(设计理解):如同观察图片,捕捉"视觉感受"——配色、间距、布局等整体设计。这对AI理解_内容呈现方式_至关重要。
二者结合为AI提供对目标网站的立体认知,使其能够精准复现或重新构思设计。
设计输入方式
用户只需在 open-lovable 界面输入URL。例如启动应用时选择"数秒重塑任意网站"选项并输入网址。
界面交互逻辑示例:
// app/page.tsx (简化版)// ...(其他状态和函数)const [homeUrlInput, setHomeUrlInput] = useState(''); // URL输入状态
const [homeContextInput, setHomeContextInput] = useState(''); // 附加指令状态const handleHomeScreenSubmit = async (e: React.FormEvent) => {e.preventDefault();if (!homeUrlInput.trim()) return;// ...(界面状态更新,如淡出主界面)// 并行创建沙盒和捕获截图const sandboxPromise = !sandboxData ? createSandbox(true) : Promise.resolve();captureUrlScreenshot(homeUrlInput);setLoadingStage('gathering');// 调用核心克隆函数cloneWebsite();
};// ...(组件其余部分)
当在主页输入框(或聊天界面)提交URL时,handleHomeScreenSubmit 函数将协调后端API调用,执行实际抓取和截图捕获。
底层机制:自动化观察流程
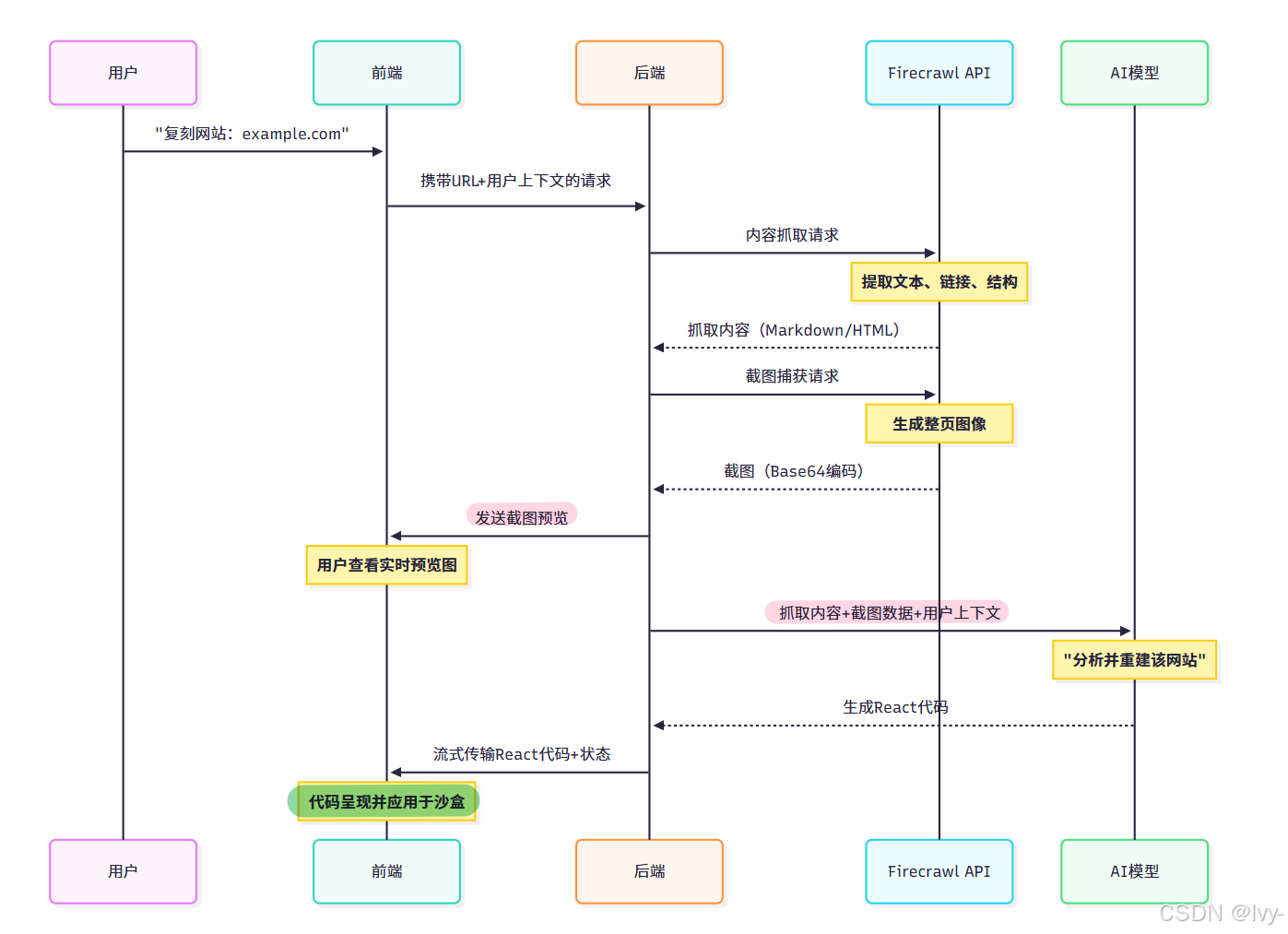
该流程展示系统如何利用外部工具(Firecrawl API)获取文本和视觉信息,作为AI生成过程的关键输入。
1. url内容抓取
内容理解的核心发生在 /api/scrape-url-enhanced API路由,使用Firecrawl API获取网页主文本和结构:
// app/api/scrape-url-enhanced/route.ts (简化版)export async function POST(request: NextRequest) {const { url } = await request.json();const firecrawlResponse = await fetch('https://api.firecrawl.dev/v1/scrape', {method: 'POST',headers: { 'Authorization': `Bearer ${process.env.FIRECRAWL_API_KEY}` },body: JSON.stringify({url,formats: ['markdown', 'html'], // 获取便于AI处理的格式waitFor: 3000, // 等待动态内容加载maxAge: 3600000 // 使用缓存加速重复请求})});const data = await firecrawlResponse.json();const { markdown, metadata } = data.data;const formattedContent = `
标题: ${metadata?.title || ''}
URL: ${url}
主要内容:
${markdown}`.trim();return NextResponse.json({ success: true, content: formattedContent, metadata: metadata });
}
该代码实现:
- 从前端接收URL
- 调用专为网页抓取设计的Firecrawl API
- 通过
markdown和html格式获取更易处理的内容 - 使用
waitFor确保页面完全加载,maxAge加速重复请求 - 格式化内容后返回前端,作为AI提示的重要组成部分
2. 截图捕获
并行执行的截图捕获由 /api/scrape-screenshot 路由处理:
// app/api/scrape-screenshot/route.ts (简化版)export async function POST(req: NextRequest) {const { url } = await req.json();const firecrawlResponse = await fetch('https://api.firecrawl.dev/v1/scrape', {method: 'POST',headers: { 'Authorization': `Bearer ${process.env.FIRECRAWL_API_KEY}` },body: JSON.stringify({url,formats: ['screenshot'], // 指定截图格式waitFor: 3000})});const data = await firecrawlResponse.json();if (!data.success || !data.data?.screenshot) {throw new Error('截图捕获失败');}return NextResponse.json({ success: true, screenshot: data.data.screenshot });
}
该过程与内容抓取类似,但专门请求screenshot格式。
返回的Base64编码图像将显示在前端界面,为用户提供设计参考。
🎢Base64编码图像
是将图片的二进制数据转换成由64个字符(A-Z、a-z、0-9、+/)组成的文本字符串,便于在文本协议(如HTML、JSON)中直接嵌入图片数据,无需单独文件存储。
3. AI管道集成(前后端协作)
获取内容与截图后,二者成为AI生成的关键输入。
前端逻辑 (app/page.tsx):
// app/page.tsx (关键部分简化版)const captureUrlScreenshot = async (url: string) => {// ...(调用/api/scrape-screenshot)if (data.success && data.screenshot) {setUrlScreenshot(data.screenshot); // 显示截图setIsPreparingDesign(true); // 展示准备状态setActiveTab('preview'); // 切换至预览标签页}
};const cloneWebsite = async () => {// ...(URL验证)const scrapeResponse = await fetch('/api/scrape-url-enhanced', { /* ... */ });const scrapeData = await scrapeResponse.json();setConversationContext(prev => ({...prev,scrapedWebsites: [...prev.scrapedWebsites, {url,content: scrapeData, // AI所需内容timestamp: new Date()}]}));const recreatePrompt = `请基于抓取内容重建为现代React应用:URL: ${url}抓取内容:${scrapeData.content}用户附加要求:${homeContextInput}具体要求: ...(给AI的详细指令)...`;const aiResponse = await fetch('/api/generate-ai-code-stream', {method: 'POST',headers: { 'Content-Type': 'application/json' },body: JSON.stringify({prompt: recreatePrompt, // 包含完整上下文的提示model: aiModel,context: {sandboxId: sandboxData?.id}})});// ...(处理AI流式响应并应用至沙盒)
};
该集成逻辑:
- 同时调用截图和内容抓取API
- 更新
urlScreenshot状态显示图像 - 将
scrapeData存入对话上下文供AI记忆 - 构建包含用户需求、抓取内容和样式指令的详细提示
- 通过AI代码生成管道生成代码
- 最终将代码应用于E2B沙盒
设计输入的强大能力
网页抓取与设计输入显著增强了 open-lovable 的能力:
- 快速原型设计:将视觉创意秒级转化为可运行代码,初始开发时间从小时级压缩至秒级
- 设计一致性:确保新应用布局风格与既有设计对齐,减少手动设计转码需求
- 突破创意瓶颈:当特定模块设计受阻时,可使用真实案例作为跳板
- 定制化重建:超越简单复制,通过"深色模式"、"极简主题"等指令引导AI重塑设计
该功能将 open-lovable 从编码助手进化为设计到代码的自动化工具,显著提升开发者与设计师的体验。
总结
本章探讨了网页抓取与设计输入——使 open-lovable 具备"观察"和"理解"任意网站的能力。
我们解析了其如何通过抓取获取内容结构,通过截图捕获设计细节。这些丰富输入结合用户指令,赋能AI在E2B沙盒中重建或重塑设计。
下一章将深入应用构建的另一个实践领域:软件包与依赖管理。open-lovable 如何确保新代码具备运行所需的所有构建模块(库与框架)?
下一章:软件包与依赖管理