基于RTSP|RTMP低延迟视频链路的多模态情绪识别系统构建与实现
引言:从低延迟播放到情绪计算的实时闭环
在 AI 技术快速落地的浪潮中,情绪识别(Affective Computing) 正从实验室中的研究课题,转变为安防监控、在线教育、零售体验、智慧医疗等行业的关键能力之一。相比传统的视频分析任务,情绪识别不仅要求模型具备高准确率,还对视频链路的实时性与稳定性有着更高的门槛:如果面部表情或语音情绪的捕捉存在显著延迟,模型推理结果的价值将被大幅削弱,甚至无法驱动后续的交互与决策。
因此,构建一条低延迟、稳定、可控且易于集成的视频传输通道,成为情绪计算系统落地的前提条件。大牛直播SDK(SmartMediaKit)提供的 RTSP、RTMP 低延迟播放器模块,正是解决这一问题的核心组件——它将复杂的流媒体协议解析、弱网环境优化、跨平台硬件解码等技术能力,封装为可直接嵌入的播放内核,使得从摄像端 → 传输链路 → 播放端/分析端 → 情绪识别推理与结果回传的全链路实现真正的毫秒级响应。
借助这一能力,系统不仅能在实验室环境下高效运行,更能直接部署于需要实时感知的业务场景,例如课堂教学的情绪反馈、客服中心的情绪监测、心理咨询的远程交互,乃至公共安全中的人群情绪动态分析,实现从数据采集到智能决策的全流程闭环。
1. 系统架构:视频链路 × 多模态情绪识别
一个稳定、可扩展的多模态情绪识别系统,必须在视频链路与AI 推理链路之间形成紧密耦合,确保数据采集、传输、解码、分析和反馈环节的延迟都被压缩到毫秒级别。整体架构可分为五大模块:
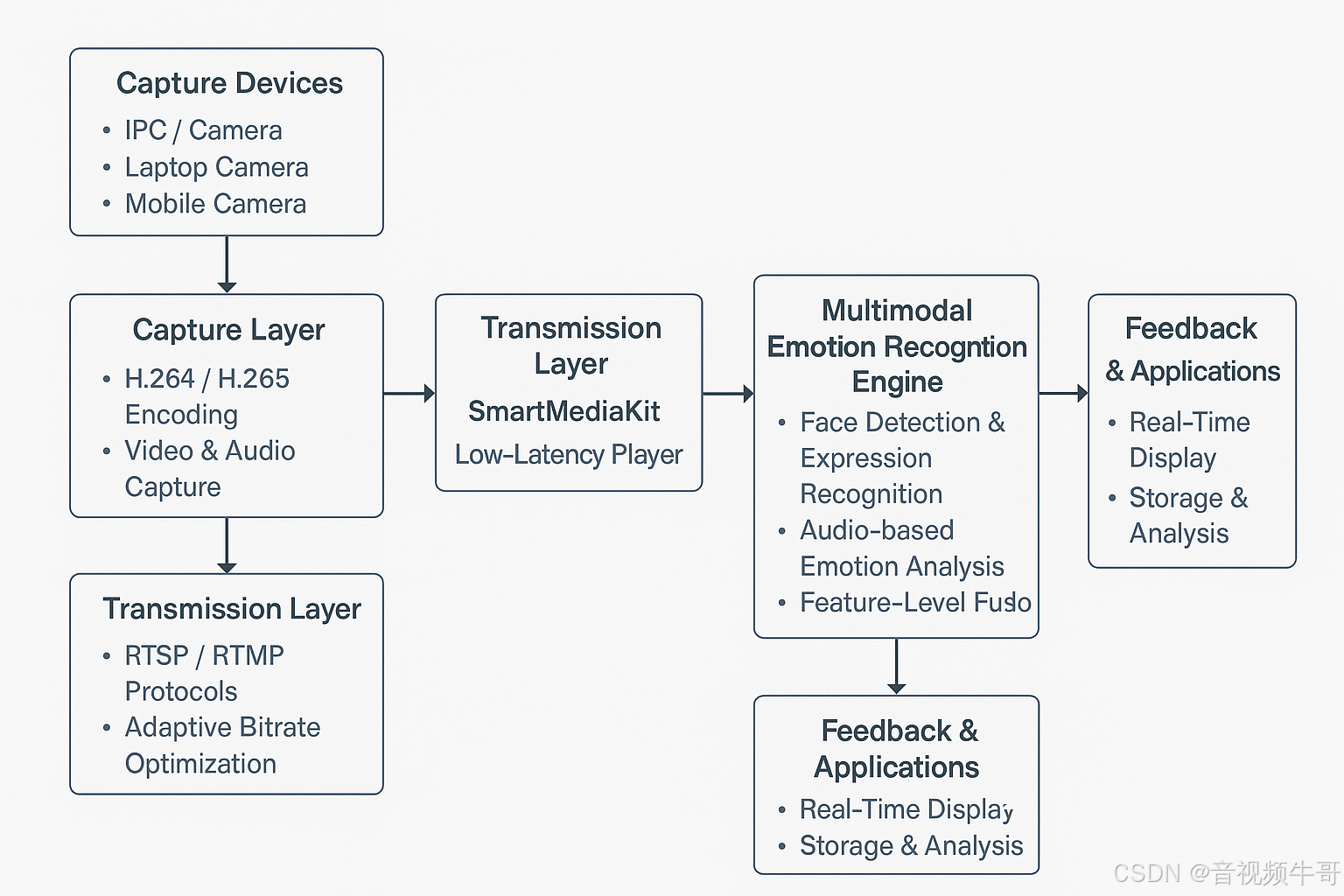
(1) 视频采集端(Capture Layer)
-
数据源:可来自固定部署的 IPC 摄像机、笔记本摄像头、工业平板摄像头,或移动终端的前/后置摄像头
-
编码能力:支持 H.264/H.265 硬编码及 AAC 音频编码,确保在低码率下保持画质稳定
-
多模态同步采集:除视频外,还可同时采集语音信号,作为情绪识别的音频输入
(2) 低延迟传输链路(Transmission Layer)
-
协议支持:RTSP、RTMP 双协议,适应不同业务平台的推流需求
-
优化策略:内置弱网自适应(码率调整、帧丢弃策略)、TCP/UDP 动态切换,确保复杂网络下的持续稳定
(3) 播放与解码端(Playback & Decoding Layer)
-
核心组件:大牛直播SDK(SmartMediaKit)低延迟播放器模块
-
解码方式:跨平台硬件解码(Android MediaCodec / iOS VideoToolbox),降低延迟与 CPU 占用
-
帧级数据回调:支持在解码后的 YUV/PCM 数据层直接接入 AI 推理模块,无需额外转码
(4) 多模态情绪识别引擎(AI Inference Layer)
-
视觉特征提取:基于 CNN/Transformer 的人脸检测与表情识别模型,识别七大类或更多情绪(如快乐、愤怒、惊讶、悲伤等)
-
音频情绪分析:利用声学特征(MFCC、Spectrogram)与 RNN/Transformer 模型分析语音情绪
-
多模态融合:通过特征级或决策级融合策略,将视觉与音频情绪信号进行加权整合,提高准确率与鲁棒性
(5) 反馈与应用层(Feedback & Application Layer)
-
实时反馈:可在播放端叠加情绪识别结果标签,实现可视化监控
-
数据存储与分析:支持将识别结果推送至后端数据库,进行趋势分析、统计报表生成
-
业务对接:与课堂互动平台、客服管理系统、心理干预系统对接,实现自动化响应
2. 核心技术链路解析
在“低延迟播放 × 多模态情绪识别”体系中,技术链路不仅仅是一个单向的视频传输过程,而是由多个相互协同的关键环节构成:
(1) 视频采集与编码
前端摄像设备(可为IPC、摄像头模组、移动终端等)负责捕捉面部及其表情变化。
-
分辨率与帧率:需在保证细节可识别的前提下,尽量选择较高帧率(如 30fps)以捕捉细微表情动态。
-
编码标准:H.264/H.265 视频编码,AAC 音频编码,确保与 RTSP/RTMP 播放模块的最佳兼容性。
(2) 低延迟视频传输
依托大牛直播SDK的 RTSP/RTMP 播放器模块,视频流在传输过程中经过以下优化:
-
弱网自适应缓冲:在网络波动时动态调整缓存,减少卡顿。
-
硬件解码加速:充分利用 GPU/硬件编解码器降低延迟。
-
码流快速首帧策略:减少连接建立到首帧渲染的延迟。
(3) 多模态数据融合
情绪识别并不仅限于视觉特征,通常还需要引入其他模态的数据:
-
视觉模态:面部表情、眼部运动、头部姿态。
-
语音模态:语调变化、语速、音色波动。
-
上下文模态:对话语境、历史行为模式。
(4) 深度学习情绪识别引擎
-
模型架构:常用 CNN + LSTM、3D-CNN、Vision Transformer 等组合,用于时序表情特征提取。
-
多模态融合策略:Early Fusion(输入级融合)、Late Fusion(决策级融合)或 Hybrid Fusion(混合融合)实现特征互补。
-
推理加速:部署 TensorRT、OpenVINO、CoreML 等推理引擎,确保在毫秒级完成分析。
(5) 推理结果回传与可视化
-
回传链路:可通过 WebSocket、MQTT、HTTP API 等方式将情绪标签和置信度实时返回业务系统。
-
可视化:在播放端 UI 中叠加情绪状态、置信度曲线、事件标记,实现“播放+情绪洞察”的一体化体验。
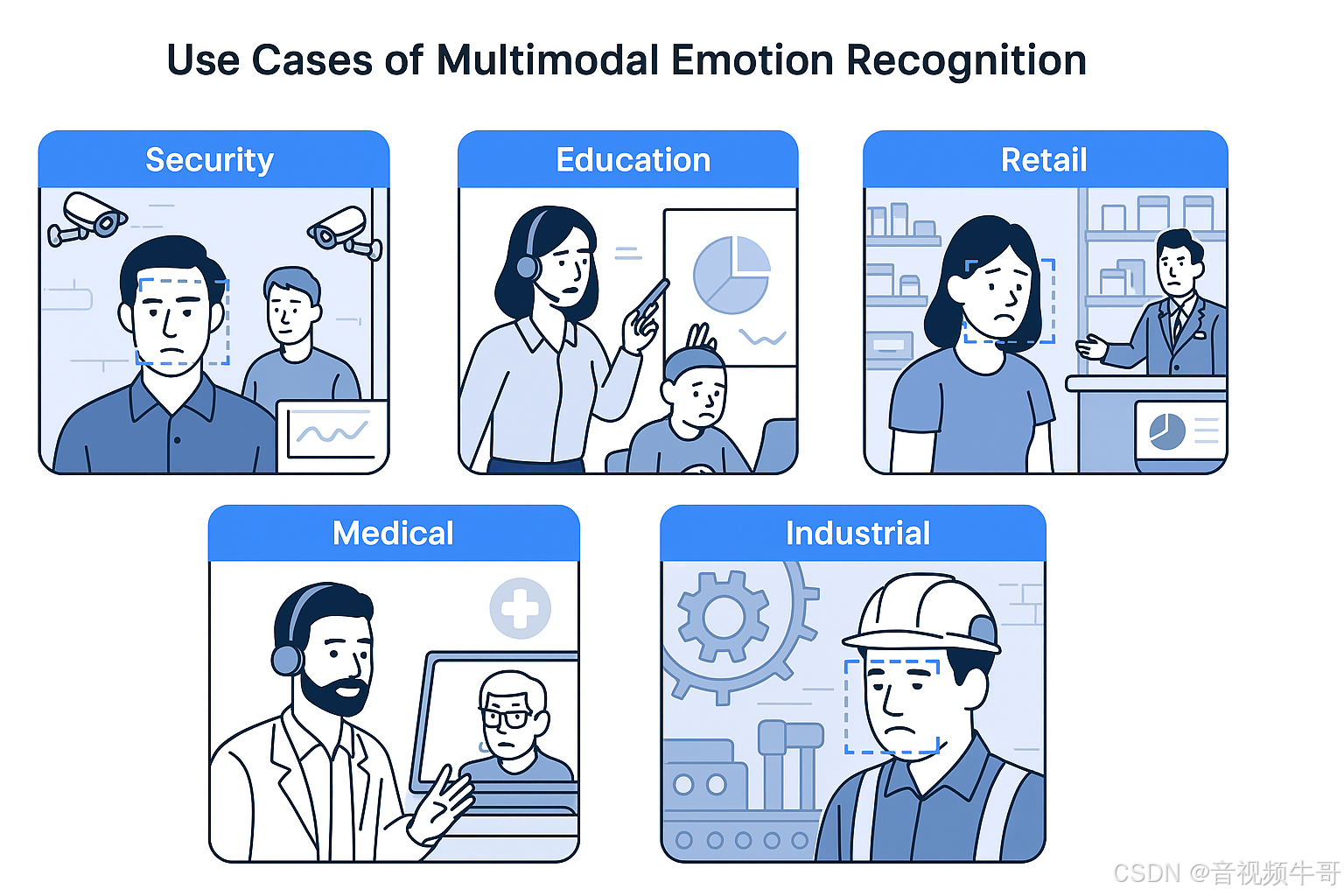
3. 业务落地场景
在“低延迟播放 × 多模态情绪识别”的架构之上,不同行业可以将其定制化为面向特定需求的业务方案,实现从实时感知到智能反馈的闭环。以下列举几个典型落地方向:
(1) 教育领域:课堂互动与情绪分析
在在线教育与智慧教室中,教师不仅需要了解学生是否在线,还需要实时掌握学生的专注度与情绪状态。
-
视频链路作用:通过 RTSP/RTMP 低延迟播放器,教师端可实时看到学生表情变化,无需等待延迟数秒的画面。
-
情绪识别应用:多模态引擎分析学生的面部表情和语音语调,评估其参与度、兴趣度,辅助教师动态调整授课节奏与互动方式。
-
价值体现:教学过程更精准,学习数据可量化,支持后续个性化辅导。
(2) 零售领域:客户体验监测
在实体零售与银行等线下场景,顾客情绪直接影响消费决策与服务评价。
-
视频链路作用:低延迟播放确保管理人员实时获取顾客与服务人员的交互画面。
-
情绪识别应用:分析顾客表情变化、音量波动等,判断其满意度或不满情绪,并可与 CRM 系统联动触发优惠券、VIP 服务等。
-
价值体现:提升客户留存率,降低服务投诉率,增强品牌体验。
(3) 医疗领域:远程心理与康复监测
心理咨询、康复训练等场景对情绪波动的实时捕捉尤为关键。
-
视频链路作用:RTSP/RTMP 模块保证远程医生端获得毫秒级延迟的视频流,最大限度减少网络传输对交流的干扰。
-
情绪识别应用:监测患者面部微表情、声调波动,辅助判断情绪状态,甚至提前发现异常情绪趋势。
-
价值体现:提高诊断准确率,改善医患沟通体验,降低突发事件风险。
(4) 安防与应急指挥:情绪驱动的风险预警
在公共安全领域,异常情绪往往是突发事件的先兆。
-
视频链路作用:低延迟播放将重点监控点位的视频流实时推送至指挥中心。
-
情绪识别应用:通过多模态识别模型,分析人群或个体的情绪异常(如恐慌、愤怒、焦躁),并与行为识别结果结合触发预警。
-
价值体现:从“事后回放”升级为“事中干预”,将安防响应前置化。
4. 技术实现细节与优化策略
为了让“低延迟播放 × 多模态情绪识别”在真实场景中稳定运行,需要在视频链路构建、多模态数据同步、模型推理优化等多个维度进行工程级优化。以下从关键技术点展开说明:
安卓轻量级RTSP服务采集摄像头,PC端到安卓拉取RTSP流
Android平台RTSP播放器时延测试
(1) 低延迟播放链路优化
-
协议选型:在内网或专网场景下优先使用 RTSP(UDP 传输)以降低抖动延迟;公网或跨网场景可采用 RTMP(TCP)保障稳定性,并通过缓冲区动态调节实现延迟与流畅度平衡。
-
硬件解码加速:充分利用 Android / Windows / iOS 等平台的硬件解码能力(如 MediaCodec、VideoToolbox)降低 CPU 占用,避免解码延迟造成的推理等待。
-
弱网自适应:通过 SDK 内部的码率自适应等机制,确保视频帧在高丢包率下仍可稳定送达。
(2) 多模态数据同步机制
情绪识别往往需要结合视频帧与音频特征,因此必须确保两类数据时间戳严格对齐。
-
统一时钟基准:在采集端与播放端使用统一的 NTP 时间基准,保证视频帧与音频帧的同步精度在毫秒级。
-
多路数据分流:通过 RTP/RTMP 内部分路机制,将视频与音频分开解复用,分别进入视觉特征提取与语音特征提取管线,再在推理前融合。
-
时序补偿:当弱网导致单一模态延迟偏差时,系统可通过缓存对齐或插帧(视频)/补帧(音频)策略进行动态平衡。
(3) 深度学习推理加速
-
轻量化模型:在边缘端部署 MobileNetV3、EfficientNet-Lite、DistilBERT(用于语音情感)等轻量模型,减少计算开销。
-
硬件推理加速:利用 GPU(CUDA/OpenCL)、NPU(如 Android NNAPI、华为 Ascend、Google Edge TPU)进行模型推理,显著降低延迟。
-
批量推理与流水线:在服务器端进行批量推理可提升吞吐量,同时配合流水线架构,实现数据接收、预处理、推理、回传的并行化处理。
(4) 异常检测与反馈通道
-
实时反馈链路:将情绪识别结果通过 WebSocket / MQTT / gRPC 等低延迟协议实时回传至业务端。
-
告警联动机制:在安防场景下,可将异常情绪标签直接联动 PTZ 摄像机,实现自动跟踪或焦点调整。
-
可视化接口:提供前端 SDK,将视频画面与情绪标签、概率值叠加显示,便于业务人员快速判断。
5. 应用场景与落地案例
基于 RTSP/RTMP 低延迟播放器 × 多模态情绪识别 架构,系统不仅在实验室环境中表现优异,更具备在多行业、多场景快速部署的可行性与扩展性。以下为几个典型落地案例:
(1) 智能安防与行为分析
-
场景描述:在公共场所、校园、地铁站等安防监控点,通过现有摄像机 + 智能终端部署情绪识别模块。
-
应用价值:
-
实时检测人群中异常情绪(恐慌、愤怒等)
-
与视频监控平台联动触发报警与视频标记
-
结合人脸识别、轨迹跟踪实现事前预警
-
-
技术特点:
-
RTSP(UDP)保障毫秒级视频传输
-
情绪推理结果可实时叠加在视频画面或回传至中控平台
-
(2) 教育评估与课堂互动
-
场景描述:在智慧教室或在线教学平台中,采集学生端摄像画面,实时分析课堂专注度与情绪变化。
-
应用价值:
-
教师可实时了解学生的专注度、困惑度分布
-
课后可生成情绪热力图与参与度曲线,辅助教学改进
-
-
技术特点:
-
RTMP 低延迟模式保障跨省市远程互动
-
多模态融合可同时分析视频表情与语音情绪
-
(3) 零售门店与客户服务监控
-
场景描述:在商场、银行、酒店等服务场所,对客户的情绪反应进行实时感知与分析。
-
应用价值:
-
当检测到客户不满情绪时,系统可即时提示服务人员介入
-
长期数据可用于优化服务流程、培训话术
-
-
技术特点:
-
可嵌入现有收银台或迎宾屏幕终端
-
弱网优化可在商场 Wi-Fi 等不稳定网络环境下稳定运行
-
(4) 远程医疗与心理咨询
-
场景描述:在远程诊疗、心理咨询平台中,实时获取患者表情、语音情绪特征,辅助医生做出更准确判断。
-
应用价值:
-
实时检测患者情绪波动
-
与电子病历系统结合,形成情绪健康档案
-
-
技术特点:
-
视频低延迟传输保障医生与患者的实时互动体验
-
支持端到端加密,满足医疗隐私与数据安全要求
-
(5) 工业生产与安全巡检
-
场景描述:在危险作业场所(如化工厂、高空作业平台),通过工人佩戴的智能头盔采集面部及语音数据,实时监测其情绪状态。
-
应用价值:
-
在高压或疲劳情绪下,系统可提前预警
-
结合传感器数据实现更全面的安全防护
-
-
技术特点:
-
嵌入式优化,适配低功耗工业终端
-
跨网络适配,可在 4G/5G/卫星链路下稳定运行
-
6. 结语与展望
随着深度学习与视频技术的不断融合,情绪识别正从“实验室可行”加速走向“业务可用”。在这一过程中,视频链路的低延迟与稳定性 与 情绪识别模型的准确率与鲁棒性 一样重要。大牛直播SDK(SmartMediaKit)通过 RTSP、RTMP 等低延迟播放模块,为多模态情绪识别系统提供了稳定、高效、跨平台的视频输入能力,使得 AI 推理结果能够在真实场景中做到秒级甚至毫秒级反馈。
未来,这一技术闭环将朝着以下方向演进:
-
更广泛的多模态融合:除视频与音频外,结合语义分析、姿态估计、生理信号等,实现更精准的情绪理解。
-
端云协同与边缘智能:在前端设备侧完成部分推理计算,降低网络压力与时延。
-
跨场景适配:在安防、教育、零售、医疗、工业等领域形成针对性优化模型与数据流策略。
-
隐私与合规保障:引入本地化处理、加密传输与可控存储,满足不同国家与行业的合规要求。
情绪识别不再只是“计算机看懂人”,而是构建起人机交互的新维度;而低延迟视频链路,则是让这一维度在真实世界发挥价值的基石。通过视频通道与 AI 引擎的深度结合,我们正迈向一个机器能够实时感知并理解人类情绪的时代。
📎 CSDN官方博客:音视频牛哥-CSDN博客