Multimodal RAG Enhanced Visual Description
Multimodal RAG Enhanced Visual Description
Authors: Amit Kumar Jaiswal, Haiming Liu, Ingo Frommholz
Deep-Dive Summary:
多模态 RAG 增强视觉描述
摘要
对于多模态输入的文本描述,需要反复优化查询以生成相关的输出图像。尽管人们努力解决模型规模和数据量扩展等挑战,但预训练和微调的相关成本仍然相当高。然而,预训练的大型多模态模型(LMMs)面临模态差距的问题,即在公共嵌入空间中文本和视觉表示之间存在不对齐。尽管微调可能缓解这一差距,但由于需要大量领域驱动的数据,通常成本高昂且不切实际。为了克服这一挑战,我们提出了一种轻量级的无需训练的方法,利用检索增强生成(RAG)通过线性映射扩展跨模态能力,这种映射可以高效计算。在推理过程中,该映射被应用于由 LMM 嵌入的图像,使得能够从训练集中检索最接近的文本描述。这些文本描述与指令一起作为语言模型的输入提示,以生成新的文本描述。此外,我们引入了一种迭代技术,通过语言模型生成合成描述来提炼映射,从而优化标准使用的图像描述指标。在两个基准多模态数据集上的实验结果显示出显著的改进。
CCS 概念
· 信息系统 → 多媒体内容创建;多媒体和多模态检索。
关键词
自然语言生成,多模态检索,深度学习
ACM 参考格式
Amit Kumar Jaiswal, Haiming Liu, and Ingo Frommholz. 2025. 多模态 RAG 增强视觉描述. 收录于第34届ACM国际信息与知识管理会议(CIKM’25)论文集,2025年11月10-14日,韩国首尔。ACM,纽约,NY,美国,5页。https://doi.org/10.1145/XXXXXX.XXXXXX
1 引言与背景 总结 (中文)
以下是对论文《1 Introduction and Background》的总结,内容以中文呈现,原文中的图片部分按原格式保留在适当位置。
传统的图像描述任务涉及生成与参考图像-文本对分布一致的文本描述。这些视觉描述有多种用途,包括图像搜索、基于内容的图像检索以及为有视觉障碍的阅读障碍用户提供辅助[29]。然而,典型多模态数据集中的文本描述过于简短,可能无法明确识别相关图像。通过使用专门在网络来源的图像-文本对上训练的模型,这种问题有所缓解。生成方法如RAG能够通过生成图像的固有信息性描述(或视觉描述),理解文本和视觉元素之间的相互作用。尽管通过大规模数据集的广泛预训练和微调促进了领域可迁移性,但将基础模型与这种方法结合会带来显著的计算开销。近期轻量级描述方法[26]通过在训练过程中选择性地更新少量参数来减少计算负担。利用预训练的大型多模态模型有助于增强轻量级图像描述中的检索机制,展现出实际效果。这些方法依赖于预训练的对比语言-图像预训练(CLIP)模型[25],从数据集中检索与输入图像最相似的描述。然而,CLIP面临模态差距现象[18],即网络数据集中的图像-文本对存在固有噪声和差异,从而影响学习公共语义空间的效果,进而影响多模态环境中的密集检索。为了解决这一差异,现有的图像描述方法需要以端到端的方式进行训练[23, 26, 33]。我们的主要目标是有效减少后续视觉描述任务中的模态差距,同时保持与替代轻量级描述技术的竞争性能。我们的方法利用线性映射技术,并使用RAG提取与图像对应的最接近的文本描述,将其与提示一起作为输入提供给大型语言模型(LLM),以生成新的视觉描述。此外,我们引入了一种新颖的持续改进过程,通过整合通过无训练方法生成的合成描述来扩展映射技术的训练数据集。无训练的概念是仅执行从视觉嵌入空间到文本空间的映射(而不是训练神经网络的某些层),通过简单的线性最小二乘解[21]实现。这种方法提供了一种经济高效的方式来改进使用预训练LLM的检索增强描述技术,从而解决模态差距问题。我们的无训练方法在两个著名的多模态数据集MSCOCO[20]和Flickr30k[36]上进行了评估,在仅使用100万可训练参数的情况下,在两个数据集上均取得了有竞争力的结果。我们探索了方法在数据集(如从MSCOCO到Flickr30k)间的泛化能力。此外,我们对生成的描述进行阈值处理的持续改进过程略微提升了性能,从而证实了文本描述可以增强图像描述效果的观点。我们发现,当优化传统的无参考指标[1o]时,我们的方法倾向于产生幻觉内容。相反,当基于参考指标(如BLEU (B)[24]、ROUGE ®[19]、SPICE (S)[2]和CIDEr (C-D)[32])进行过滤时,这些性能指标均显示出一致的改进。

我们的主要贡献包括:a) 我们提出了一种轻量级无训练的图像内容描述方法;b) 我们证明了从预训练LLM生成的图像描述可进一步增强我们在后续图像描述任务中的方法;c) 我们评估了线性映射方法在文本嵌入空间中保留图像语义的能力,并通过用户行为驱动的指标(如标准化折现累积增益,nDCG)结合监督措施(即涉及人类参考)进行验证。
1.1 相关工作
多模态语义: 结合多个语义空间来表示图像特征可以提升检索性能。近期大型语言模型(LLMs)的进步推动了研究如何通过视觉输入对其进行条件化以提升生成能力。这通常通过预训练单模态模型之间的交叉注意力机制实现 [1, 16, 35],或通过训练图像与LLM输入空间之间的映射网络来完成 [5, 11, 15]。因此,强调在大量的图像-文本配对数据集上进行预训练,然后针对图像描述任务进行微调 [30, 37]。一些方法还使用对比学习来实现图像和文本模态之间的语义对齐 [25]。我们的方法通过普通最小二乘映射增强了基于图像的检索增强文本生成。与某些仅依赖文本数据进行图像描述的方法不同 [34],我们通过线性映射将图像与文本描述 grounding,解决了模态差距问题。而其他方法通过调整预训练目标以更好地对齐图像和文本模态 [8],但它们的训练数据集规模小于CLIP。因此,我们使用CLIP进行检索,并通过线性映射来 grounding 视觉特征空间。
用于视觉描述的LMMs: 图像-语言预训练(如CLIP [25])因其零样本学习和迁移能力而备受关注。近期进展,如e-CLIP [28] 和 DeCLIP [17],利用自监督和多模态监督来提升性能。然而,大规模对比预训练 [12, 25, 27] 需要数亿到数十亿样本的数据集。我们提出了利用预训练LMM和端到端训练的交叉注意力机制进行检索增强。BLIP [16] 使用自举的图像 grounding 文本编码器来消除噪声描述,但需要微调,导致模型参数增加。与先前方法不同,我们探索使用LLMs在CLIP [25] 的联合嵌入空间中将图像与训练数据集中的描述对齐,从而缓解模态差距。这种方法增强了检索机制,仅需向语言模型提供检索到的文本描述。所有这些方法都优化了从图像空间到预训练LLM嵌入或隐藏空间的映射。
2 预备知识
我们使用源数据集S(MSCOCO),包含图像-文本对 (Xi,Ti)(X_i, T_i)(Xi,Ti)。首先,我们使用CLIP图像编码器(IE)Φ1E\Phi_{1E}Φ1E 对训练集 Strain⊂SS_{train} \subset SStrain⊂S 进行编码,其中 ppp 表示像素空间,ddd 表示嵌入空间的维度。随后,我们利用CLIP文本编码器(TE)ΦTE:D→Rd\Phi_{TE}: D \rightarrow R^dΦTE:D→Rd 来嵌入相关的文本描述,其中 nnn 表示 StrainS_{train}Strain 中嵌入的文本描述数量。考虑到MSCOCO [20] 中每个图像伴随多种文本描述,我们将图像的每个实例视为源数据集S中的一个独立事件。然后,我们将图像嵌入作为输入,对应的文本嵌入 ei∈EStraine_i \in E_{S_{train}}ei∈EStrain 作为目标,目标是最小化 ∑(Xi,Ti)∈Strain∥e^i−ei∥22\sum_{(X_i, T_i) \in S_{train}} \| \hat{e}_i - e_i \|_2^2∑(Xi,Ti)∈Strain∥e^i−ei∥22,以解决图像和文本语义之间的差距。检索过程具有线性复杂度 O(n)O(n)O(n),而线性映射的计算成本为立方复杂度 O(d3)O(d^3)O(d3),其中 ddd 表示LMM(CLIP)语义空间的维度,nnn 表示存储在向量数据库中的嵌入数量。我们的方法不受此场景限制,因为在CPU上拟合最小二乘解可以在几分钟内完成,因为我们预计算了用于管道中的向量数据库的嵌入。
我们的方法:mRAG-gim
我们提出了一种新颖的方法,即多模态检索增强用于图像 grounding 的方法(mRAG-gim),该方法采用线性映射来在统一的嵌入空间内保留多模态语义。mRAG-gim 利用预训练的大型多模态模型(LMMs)来检索与给定输入图像相关的文本描述。随后,这些描述通过一种提示工程技术传递给预训练的大型语言模型(LLM),作为生成新的视觉描述的提示。然而,检索的有效性受到预训练 LMMs 中固有的模态差距的阻碍。mRAG-gim 旨在通过一种轻量级的线性映射来弥合这一差距,该映射可通过最小二乘准则 [21, 22] 计算闭式解。因此,这种映射可以针对特定数据集(或任务)进行定制,从而无需进行端到端的微调。我们在图 2 中对我们的方法进行了示意性描述。该流程分为两个阶段,在初始阶段(阶段 I),我们的语义线性映射(Lm)实现了图像编码器与生成式语言模型的耦合,促进了基于图像输入生成语言的过程。在阶段 I 中,输入图像 X∈RpX \in \mathbb{R}^pX∈Rp 随后被嵌入为 v=ΦiE(X)v = \Phi_{iE}(X)v=ΦiE(X),并
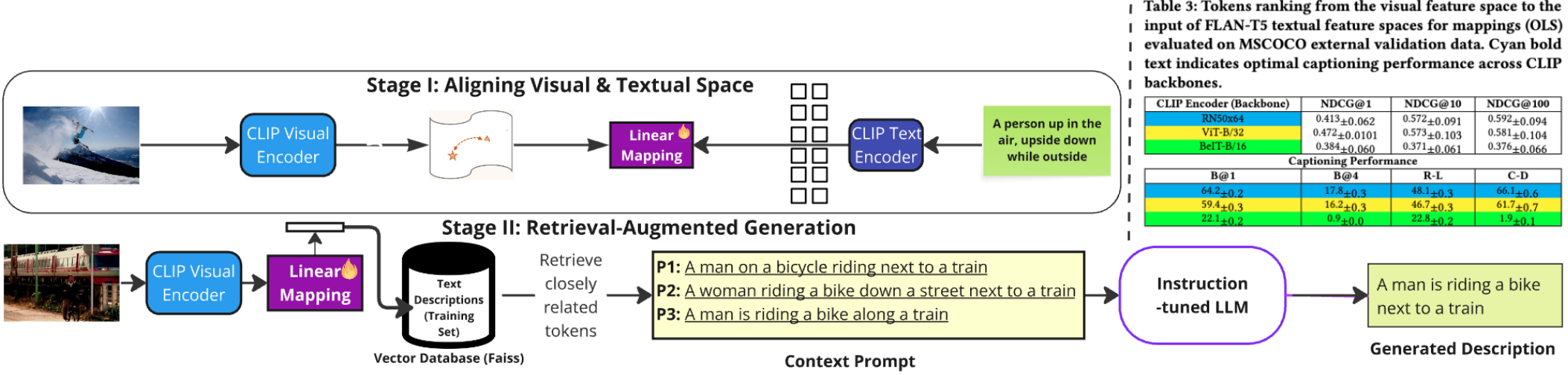
算法1 mRAG-gim:基于RAG的视觉描述
以下是对论文中关于“Algorithm 1 mRAG-gim: RAG-based Visual Descriptions”部分的中文总结,保留了原文中的图像部分在适当位置。
算法概述
该部分介绍了mRAG-gim算法,用于基于检索增强生成(RAG)的视觉描述生成。算法的主要输入包括图像编码器 ΦIEΦ_{IE}ΦIE、文本编码器 ΦTEΦ_{TE}ΦTE、训练数据 Strain=(Xj,Ti)S_{train} = (X_j, T_i)Strain=(Xj,Ti)、测试数据 Stest=(Xj)S_{test} = (X_j)Stest=(Xj)、大型语言模型(LLM)作为生成模型、超参数 kkk 以及提示 P1P_1P1。算法步骤如下:
- 使用图像编码器 ΦIEΦ_{IE}ΦIE 和文本编码器 ΦTEΦ_{TE}ΦTE 对训练数据中的图像和文本进行编码,得到编码后的表示 {oi,ei}i=1\{o_i, e_i\}_{i=1}{oi,ei}i=1。
- 拟合线性映射 LMLMLM,基于训练数据的编码对 {oi,ei}\{o_i, e_i\}{oi,ei} 预计算映射方案。
- 使用训练数据的文本描述构建视觉描述集 VD={ei}VD = \{e_i\}VD={ei}。
- 对测试数据中的图像 XjX_jXj,通过 ΦIEΦ_{IE}ΦIE 编码后应用线性映射 LMLMLM,得到测试图像在CLIP空间中的表示 {LMtest}\{LM_{test}\}{LMtest}。
- 从向量数据库中检索与测试图像最相似的 top-kkk 描述,计算方式为 Dj=topk({LM∞j},VD,k)D_j = \text{topk}(\{LM_{\infty j}\}, VD, k)Dj=topk({LM∞j},VD,k)。
- 将检索到的描述 DjD_jDj 与提示 PPP 拼接后输入LLM,生成新的文本描述 Gj=LLM(concatenate(P+Dj))G_j = \text{LLM}(\text{concatenate}(P + D_j))Gj=LLM(concatenate(P+Dj))。
输出为生成的文本描述集 {Gj}\{G_j\}{Gj}。
检索 top-kkk 文本描述时,采用余弦相似度(cos)作为度量标准,具体为 D=argmaxXi∈1..ncos(ei,LMo)D = \arg \max_{X_i \in 1..n} \cos(e_i, LM_o)D=argmaxXi∈1..ncos(ei,LMo)。
持续改进与数据增强
算法还支持通过持续改进检索增强机制,利用生成的文本描述进一步优化模型性能。生成的描述会被嵌入并附加到参考集中,从而增强训练数据集 StrainS_{train}Strain。目标是选择高质量的生成描述加入训练数据,以提升模型预测的整体性能。为此,使用图像描述评价指标 TTT(如 BLEU@4、ROUGE-L、CIDEr-D 和 SPICE)对候选描述与参考描述进行评估,输出单一数值分数。
具体步骤包括:
- 首先在验证集上评估 mRAG-gim 的性能,计算平均指标 ttt,以此判断生成描述的质量是否符合预期。
- 随后,通过LLM为训练数据集 StrainS_{train}Strain 中的图像随机生成一批新的文本描述,并计算每个描述的个体指标得分 t(.,.)t(., .)t(.,.)。
- 丢弃得分低于平均值 ttt 的文本描述。
- 对 StrainS_{train}Strain 中所有图像生成合成文本描述后,将其加入训练数据和向量数据库,并重新训练线性映射 LMLMLM。
- 在验证集上评估更新后的 LMLMLM 性能,调整平均性能指标 ttt。
- 重复此过程多次,直到指标 ttt 不再提升为止。

实验部分
在实验部分,作者在广泛使用的文本-图像数据集 MSCOCO 和 Flickr30k 上评估了该方法在图像描述任务中的表现。还对映射技术进行了消融分析,探索不同级别的语言监督(在词素级别)以确定最佳配置。通过对线性映射方法进行评估,作者对与图像参考描述具有词汇对应关系的词素进行排名(结果见表3)。
4.1 实现细节与结果
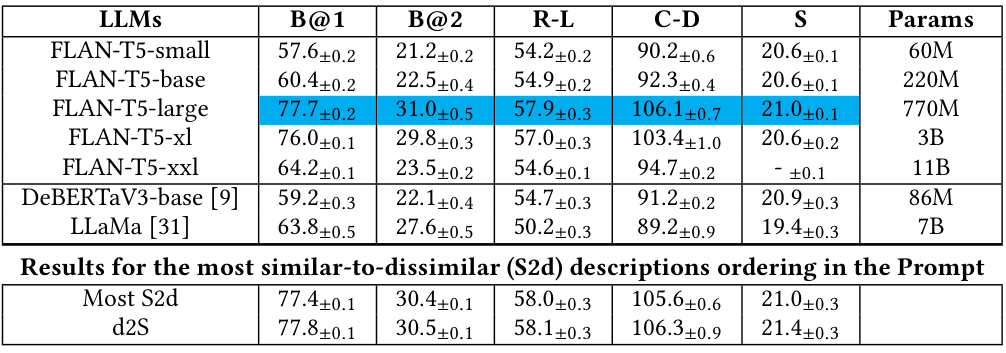
数据集按照标准协议[14]被划分为训练集、验证集和测试集。在进一步分析之前,我们进行了预处理步骤,包括长度归一化和图像及文本嵌入向量的均值中心化,这与[3]中的相关策略一致。我们发现嵌入空间的均值中心化尤为重要。此外,我们在训练子集中的图像-文本对上使用普通最小二乘法(OLS)计算映射。我们观察到,通过OLS在CLIP骨干模型和FLAN-T5之间进行的映射实现了视觉和文本嵌入空间的最佳对齐,并在表3中报告了最高的NDCG分数。此外,该映射的参数数量取决于维度、图像编码器、语言模型、解码技术和提示策略的详尽搜索。我们采用向量数据库Faiss[13]存储数据产物,因为其在向量数据库中高效处理存储和检索任务的能力。我们的最终配置结合了RN50x64 CLIP编码器和FLAN-T5模型[4]的大型实例。我们使用FLAN-T5生成描述,并采用与先前研究类似的一致提示策略。具体来说,我们的图像描述为:“”,并在占位符处插入最相似的描述。我们进行了提示总结实验,尽管结果略显不佳。在算法2的背景下,我们探索了不同的指标来评估生成描述的质量阈值,如图1所示。我们的发现表明,CIDEr-D[32]非常适合此目的,并且通常在所有其他评估指标上带来轻微的提升。在表2中,我们展示了在MSCOCO上的方法结果。仅具有100万可训练参数的mRAG-gim在训练时间上显著优于竞争基线方法。尽管训练预算较低,mRAG-gim在SPICE指标上取得了接近SmallCap[26]的性能。然而,在监督(基于n-gram)的指标上仍存在显著差距。SmallCap和mRAG-gim的推理时间相似(在L4 GPU上平均约为0.2秒)。通过mRAG-gim的持续优化,SmallCap在SPICE分数上得到增强,两次迭代后观察到显著改进。mRAG-gim在CIDEr-D和SPICE上的得分略低。然而,通过持续优化过程,mRAG-gim在一次迭代后有效消除了这一差距,此后未观察到进一步的改进。相反,算法2的一次迭代后SPICE分数略有下降。我们检查了mRAG-gim从MSCOCO到Flickr30k的迁移,作为消融测试的一部分,涉及两种情境:(a) 使用域内数据迁移映射,(b) 同时迁移嵌入数据产物和映射。我们评估了映射上正交性约束的影响。与SmallCap(唯一采用RAG的轻量级字幕方法)相比,我们使用算法2的方法取得了最高的CIDEr-D分数,超过了SmallCap,而mRAG-gim仅比SmallCap有轻微改进。这一现象仅在将映射迁移到未训练数据时出现,表明mRAG-gim在利用新数据而不需训练方面的卓越效能。

我们的消融分析显示,CLIP经常为mRAG-gim token生成的低质量字幕分配过高的分数。我们分析了评估指标之间的皮尔逊相关性,期望指标与字幕质量之间存在强烈的正相关。然而,尽管像C-D、R-L和B@4这样的监督指标强烈相关,基于CLIP的指标仅显示轻微的正相关。令人惊讶的是,在表1报告的消融测试中,SPICE与其他指标几乎不相关。此外,我们在表2中的发现表明,改变提示中描述的顺序会导致性能变化,从而证实了大型LLM中存在近因偏差[38]。在 dissimilar-to-similar (d2S) 排序的情况下,最相似的描述最初出现,导致CIDEr-D分数表现更好。
5 结论
我们提出了 mRAG-gim,一种基于 RAG 的方法,通过线性映射生成图像的视觉描述,以缩小众所周知的多模态差距。利用通过最小二乘法计算出的映射,我们为给定图像从训练集中检索最接近的标题,这些标题连同指令一起作为生成式语言模型的输入,用于生成新的标题。我们展示了我们的线性映射保留了排名最佳的词元,这种映射能够很好地从视觉嵌入空间转移到文本空间,在标题生成任务中表现出色。此外,我们提出了一种由 LLM 生成的持续改进策略。我们选择性地保留高评分的合成标题来扩充训练集,从而提升标题生成指标。我们在消融分析中证明,无监督指标如 CLIP-score 容易受到误导性线索的影响。我们的方法与现有的轻量级图像标题方法相比,取得了具有竞争力的性能。重要的是,我们的映射使得小型 LLM(如 FLAN-T5 [6])的使用成为可能,为资源受限的用户普及了图像标题生成。
GenAI 使用声明
我们在本文中从写作和开发的角度均未使用任何自动化工具(LLM 或 GenAI 工具)。
Original Abstract: Textual descriptions for multimodal inputs entail recurrent refinement of
queries to produce relevant output images. Despite efforts to address
challenges such as scaling model size and data volume, the cost associated with
pre-training and fine-tuning remains substantial. However, pre-trained large
multimodal models (LMMs) encounter a modality gap, characterised by a
misalignment between textual and visual representations within a common
embedding space. Although fine-tuning can potentially mitigate this gap, it is
typically expensive and impractical due to the requirement for extensive
domain-driven data. To overcome this challenge, we propose a lightweight
training-free approach utilising Retrieval-Augmented Generation (RAG) to extend
across the modality using a linear mapping, which can be computed efficiently.
During inference, this mapping is applied to images embedded by an LMM enabling
retrieval of closest textual descriptions from the training set. These textual
descriptions, in conjunction with an instruction, cater as an input prompt for
the language model to generate new textual descriptions. In addition, we
introduce an iterative technique for distilling the mapping by generating
synthetic descriptions via the language model facilitating optimisation for
standard utilised image description measures. Experimental results on two
benchmark multimodal datasets demonstrate significant improvements.
PDF Link: 2508.09170v1
部分平台可能图片显示异常,请以我的博客内容为准
