AI测试平台实战:深入解析自动化评分和多模型对比评测
在AI技术迅猛发展的今天,测试工程师面临着如何高效评估大模型性能的全新挑战。本文将深入探讨AI测试平台中自动化评分与多模型对比评测的关键技术与实践方法,为测试工程师提供可落地的解决方案。

多模态模型评测的行业现状与挑战
当前主流多模态大模型(如GPT-4V、Claude等多模态版本)能够同时处理文本、图像等多种输入形式,这为测试工作带来了全新维度。根据行业实践数据显示:
-
评测复杂度高:一次完整的竞品对比评测通常涉及5-10个不同模型,参数量从20亿到780亿不等
-
人工成本居高不下:2000条测试数据的人工标注需要约一周时间,效率瓶颈明显
-
评分标准主观性强:同一测试案例不同人员标注结果可能存在差异,缺乏客观标准
"在多模态时代,测试工程师需要像算法工程师一样思考模型能力边界,同时保持测试人员的严谨性。"一位资深AI测试专家如此描述当前的角色转变。
自动化评分系统设计与实现
核心设计原则
-
模型分离原则:评分模型与被测模型应尽量不同,避免"自己评自己"的偏见
-
场景分类原则:不同测试场景(如OCR识别、内容概述等)需制定差异化评分标准
-
规则明确原则:通过精心设计的prompt明确评分规则,减少主观判断
关键技术实现
动态Prompt生成
-
# 场景分类与评分标准示例 prompt_templates = {"OCR识别": "若answer与ground truth文字内容一致(忽略大小写和标点),返回正确","内容概述": "若answer包含ground truth中80%以上的关键信息点,返回正确","知识问答": "若answer核心实体与ground truth一致,返回正确" }def generate_prompt(question_type, question, ground_truth, model_answer):return f"""你是一位专业的评分员,请根据以下规则评估:场景类型:{question_type}评分标准:{prompt_templates[question_type]}问题:{question}预期答案:{ground_truth}模型答案:{model_answer}"""
多模型调用架构
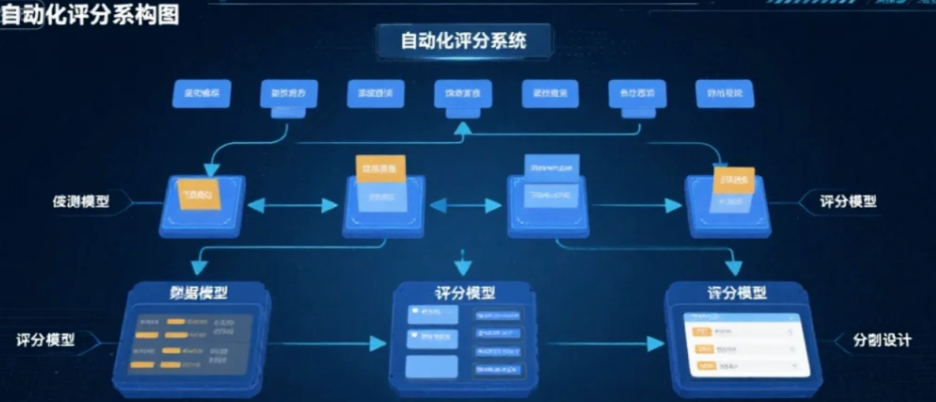
图:自动化评分系统架构,包含被测模型与评分模型的分离设计
准确性提升实践
-
分层抽样验证:对自动化评分结果按场景分层抽样,人工复核
-
prompt迭代优化:基于bad case持续优化评分prompt
-
多模型交叉验证:使用2-3个不同模型进行评分,取共识结果
实测数据显示,经过优化的自动化评分系统可以达到92%的准确率,相比纯人工评测提升效率300%以上。
多模型对比评测方案
核心交互设计
-
任务勾选:支持多任务并行选择
-
动态列生成:自动适配不同数量的对比模型
-
批量标注:同屏显示多模型结果,提升标注效率
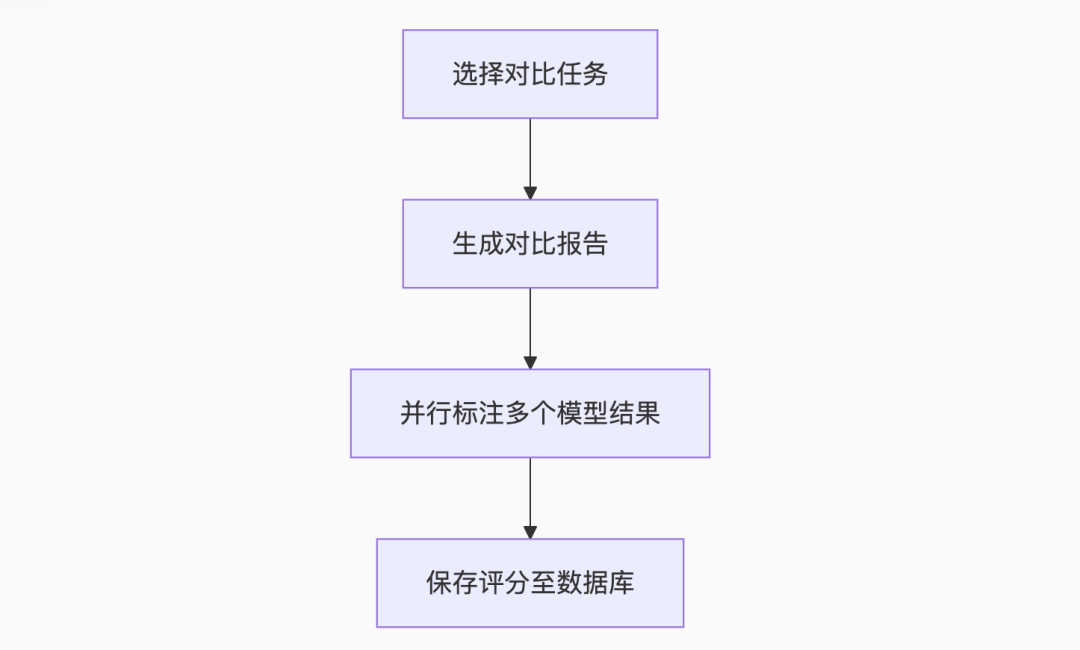
关键技术难点突破
动态列渲染技术
# 动态列生成示例comparison_df = pd.DataFrame()for task in selected_tasks:model_name = task['name']comparison_df[f"{model_name}_answer"] = task['answers']comparison_df[f"{model_name}_score"] = task['scores']# 前端渲染st.data_editor(comparison_df,column_config={"image": st.column_config.ImageColumn(),"score": st.column_config.SelectboxColumn(options=["正确","错误"])})
结果对比可视化
实测数据显示,对比评测模式可将标注效率提升40%,同时更易于发现模型间的差异点。
典型问题与解决方案
问题1:自动化评分准确性争议
解决方案:
-
建立分层抽样复核机制
-
输出评分模型的准确率报告(如92%)
-
强调"相同标准下对比"的价值,即使评分绝对准确率不是100%,仍能有效对比模型优劣
问题2:主观性强的测试场景
解决方案:
-
场景细分:将"内容概述"等主观场景进一步细分
-
关键点标注:为每项测试标注3-5个关键验证点
-
多人评分:对高价值案例采用多人评分取平均
问题3:大规模测试数据管理
解决方案:
-
采用"文件路径+数据库索引"的混合存储方案
-
保持原始测试结果文件不变,便于直接查看
-
数据库只存储关键指标和元数据,平衡性能与灵活性
演进方向与行业展望
-
智能化数据挖掘:利用大模型自动从海量数据中挖掘特定测试场景案例
-
自动化流水线:与CI/CD系统深度集成,实现"提交即测试"
-
众包协作平台:支持分布式团队协同标注与评审
-
大模型安全测试:增加对抗测试、提示词攻击等安全评测维度
"未来的AI测试平台将不再是简单的工具集合,而是融合测试、分析与优化的智能系统。"一位AI质量保障专家如此展望行业未来。
写给测试工程师的建议
-
掌握大模型原理:理解token、attention等核心概念,不再做"黑盒测试"
-
培养prompt工程能力:将测试用例转化为有效的prompt是一门艺术
-
建立场景化思维:不同测试场景需要差异化的评估策略
-
平衡自动与人工:合理划分自动化与人工评审的边界
-
注重数据资产积累:构建高质量的测试案例库是核心竞争力
随着AI技术的快速发展,测试工程师的角色正在从质量守门员向质量赋能者转变。掌握这些先进的评测方法与工具,将帮助我们在AI时代保持不可替代的价值。
"优秀的测试平台应该像活体组织一样持续进化,与团队共同成长。" —— 来自一线AI测试团队的经验分享
推荐阅读:
AI术语详解:从新手到专家的43个核心概念指南
10分钟无痛部署!字节Coze开源版喂饭教程
手把手玩转本地大模型:Ollama+DeepSeek+Dify 零门槛全流程指南
一文搞定 AI 智能体架构设计的10大核心技术
Agent的深度解析:从原理到实践
AI|大模型入门(六):GPT→盘古,国内外大模型矩阵速览