基于数据结构用java实现二叉树的排序器
1. 设计概述
本文介绍的排序器基于二叉搜索树(BST)数据结构实现,通过Java泛型编程,支持对实现了Integer接口的类型进行排序。该设计充分利用BST的天然排序特性,提供高效的元素插入和有序遍历功能。
2. 核心架构
2.1 节点类(Node)
作为BST的基本单元,具有以下特性:
存储结构:包含元素项(
item)、左子树指针(left)和右子树指针(right)插入逻辑:
若新节点值小于当前节点,递归插入左子树
若新节点值大于当前节点,递归插入右子树
遍历方式:通过中序遍历(左-根-右)实现升序输出
2.2 排序器主体(BinaryTreeSort)
根节点管理:维护树的入口节点
root操作方法:
add(E element):构建排序树结构sort():触发中序遍历输出排序结果
3. 关键算法分析
3.1 插入算法
时间复杂度:
最优/平均情况(平衡树):O(log n)
最坏情况(退化成链表):O(n)
空间复杂度:递归栈深度O(h),h为树高
3.2 排序算法
中序遍历始终保证O(n)时间复杂度
输出稳定性:原始相等元素的相对顺序可能改变(非稳定排序)
package com.DataStructure.BinaryTree;/*** 基于二叉树结构实现元素排序处理的排序器* @param <E>*/
public class BinaryTreeSort<E extends Integer>{/*** 定义节点类*/class Node<E extends Integer>{private E item; //存储元素private Node left; //存储左子树地址private Node right; //存储右子树地址public Node(E item) {this.item = item;}/*** 添加结节点*/public void addNode(Node node){// 完成新节点中的元素与当前节点中的元素的判断// 如果新节点中的元素小于当前节点中的元素,那么新结点则放到当前节点的左子树中if(node.item.intValue() < this.item.intValue()){if(this.left == null){this.left = node;}else{this.left.addNode(node);}}else{// 如果新节点中的元素大于当前节点中的元素,那么新结点则放到当前节点的右子树中if(this.right == null){this.right = node;}else{this.right.addNode(node);}}}/*** 使用中序遍历二叉树*/public void inorderTraversal(){// 找到最左八则的那个节点if(this.left != null) this.left.inorderTraversal();System.out.println(this.item);if(this.right != null) this.right.inorderTraversal();}}private Node root; // 存储树的根节点的地址/*** 将元素添加到排序器中*/public void add(E element){// 实例化节点对象Node<E> node = new Node<>(element);// 判断当前二叉树中是否有根节点,如果没有那么新节点则为新节点if(this.root == null){this.root = node;}else{this.root.addNode(node);}}/*** 对元素进行排序*/public void sort(){// 判断根节点是否为空if(this.root == null)return;this.root.inorderTraversal();}}
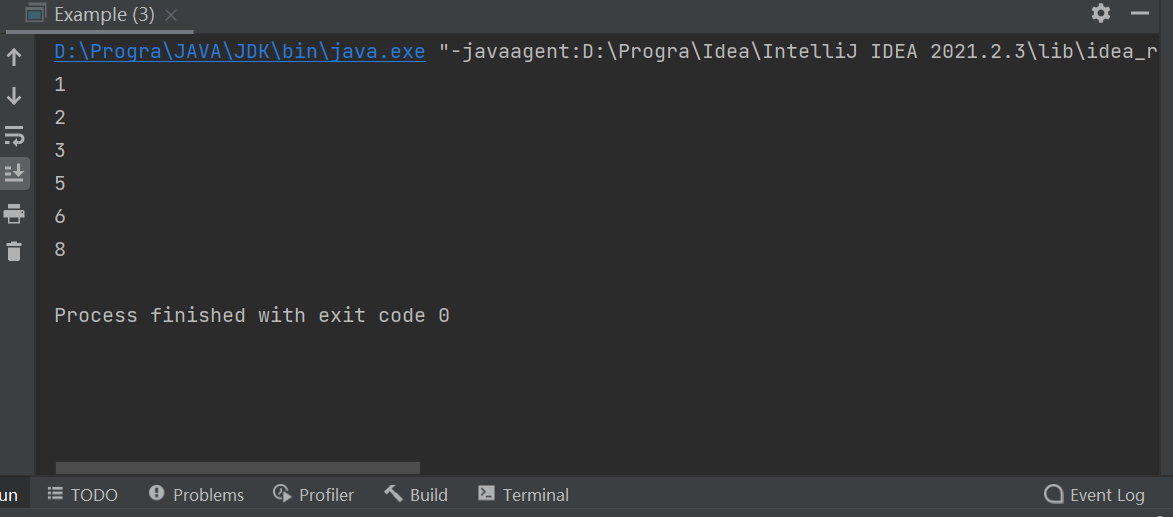
package com.DataStructure.BinaryTree;public class Example {public static void main(String[] args) {BinaryTreeSort<Integer> sort = new BinaryTreeSort<>();// 1,8,6,3,5,2sort.add(1);sort.add(8);sort.add(6);sort.add(3);sort.add(5);sort.add(2);sort.sort();}
}