(talk)西安大模型开发者talk
# ai 研究
- 中国的大模型相对的全球性没有那么强
- 美国限制中国购卡
- nature 子刊表示大模型的落地准确率还需改善(如医疗)
- 开发的时候幻觉是一个比较大的问题
# 大模型应用开发实践(科大讯飞)大模型落地的沟通案例
- 人工智能技术的三个层次: 计算智能,感知智能,认知智能
- 需要比较流畅的语言表达
- 步骤: 预训练,有监督微调,人类反馈的强化学习(学,教,考)
- 目前b端落地加快
---
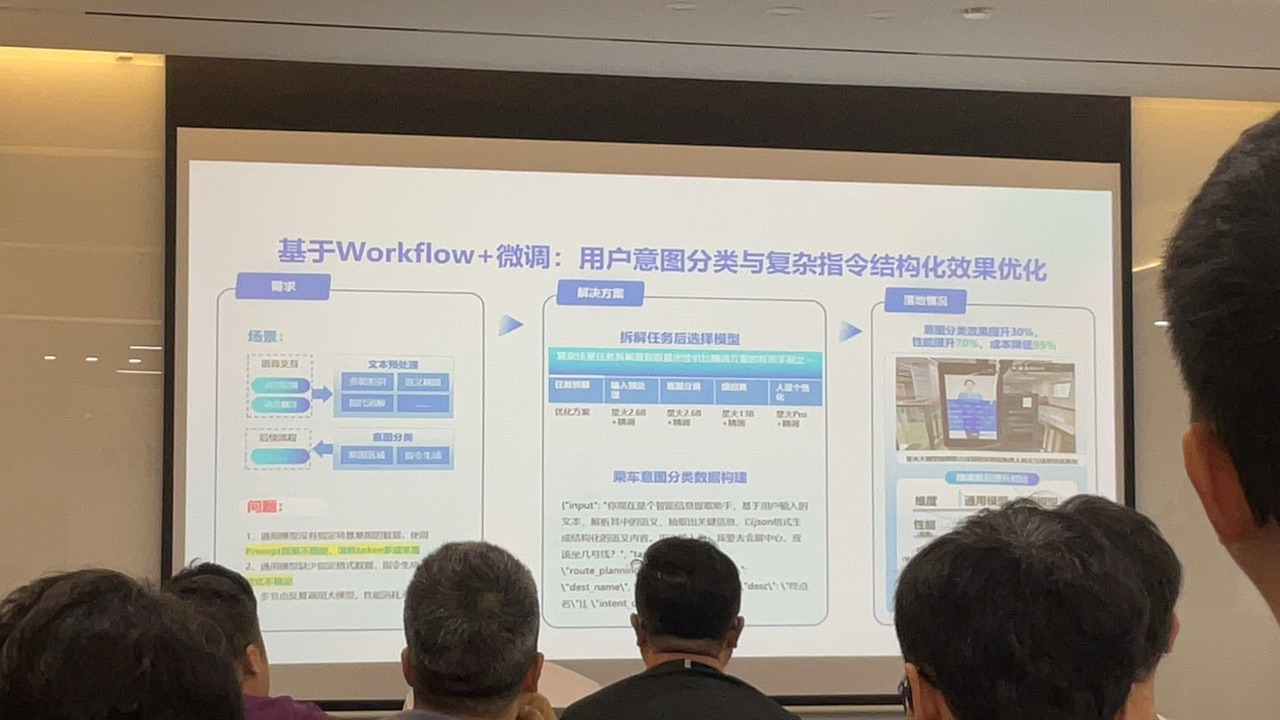
- 1,根据作者(博主)以往的作品来生成需要的内容;2,rag + 微调方案解决通用模型的回复幻觉问题;3,智能客服,降低延迟,兜底回答,根据大模型的输出特性进行实时合成;4,信息分析的b端需求场景应用更多,在目前占b端需求的50%(例如网约车进行司乘匹配);5,朋友圈二手车信息提取处理,结构化;6,智能客服数据训练的来源要做配比,如果全是有问题的信息来源,模型遇到新的测试集就会开始找问题;7,精细化特定场景需求,例如论文检索;8,OCR需要把离散的字符组合连续化;

(流程图较多,突出重点
b端相对于c端有更多的容错和耐心
# agent 开发平台落地和实践
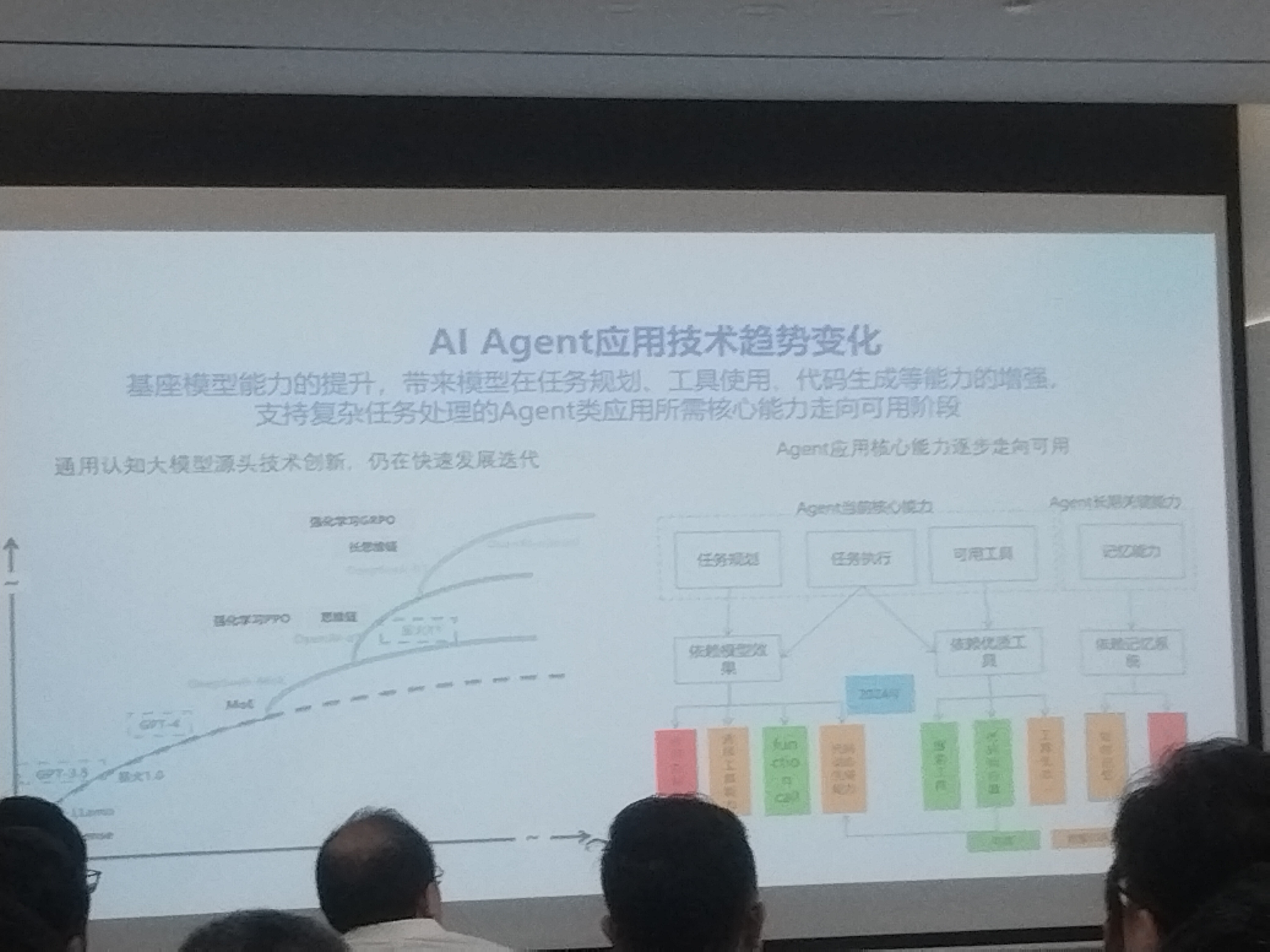

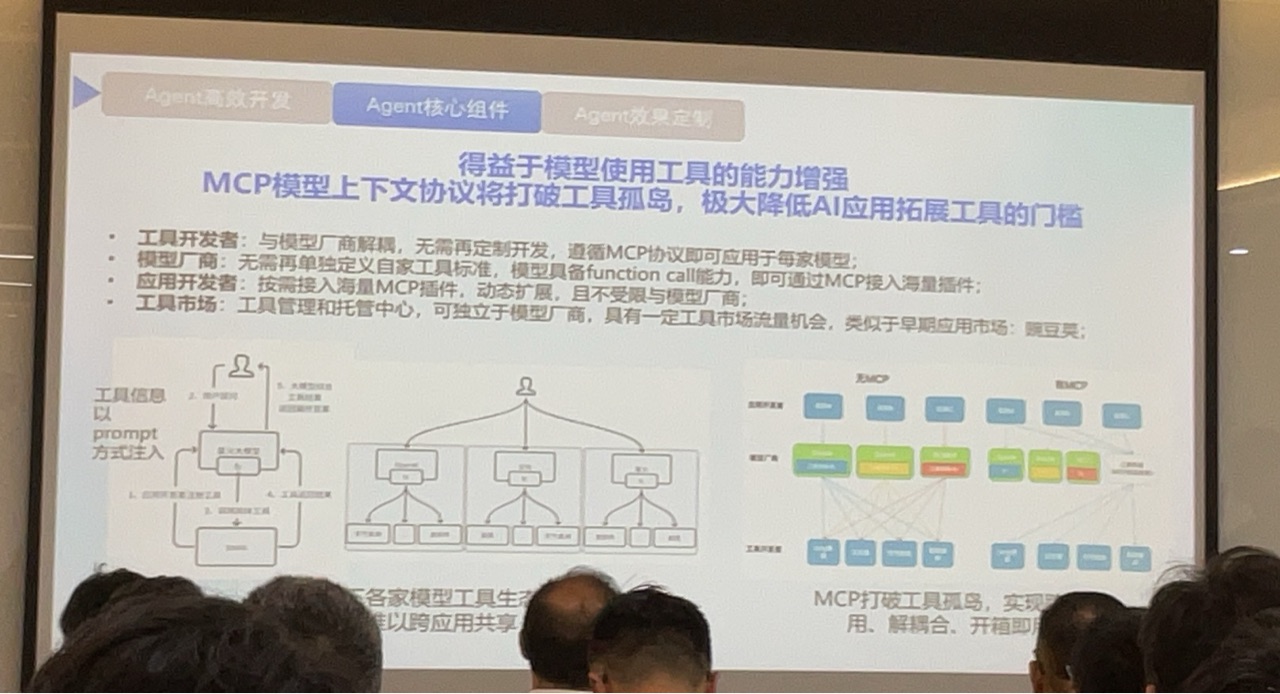
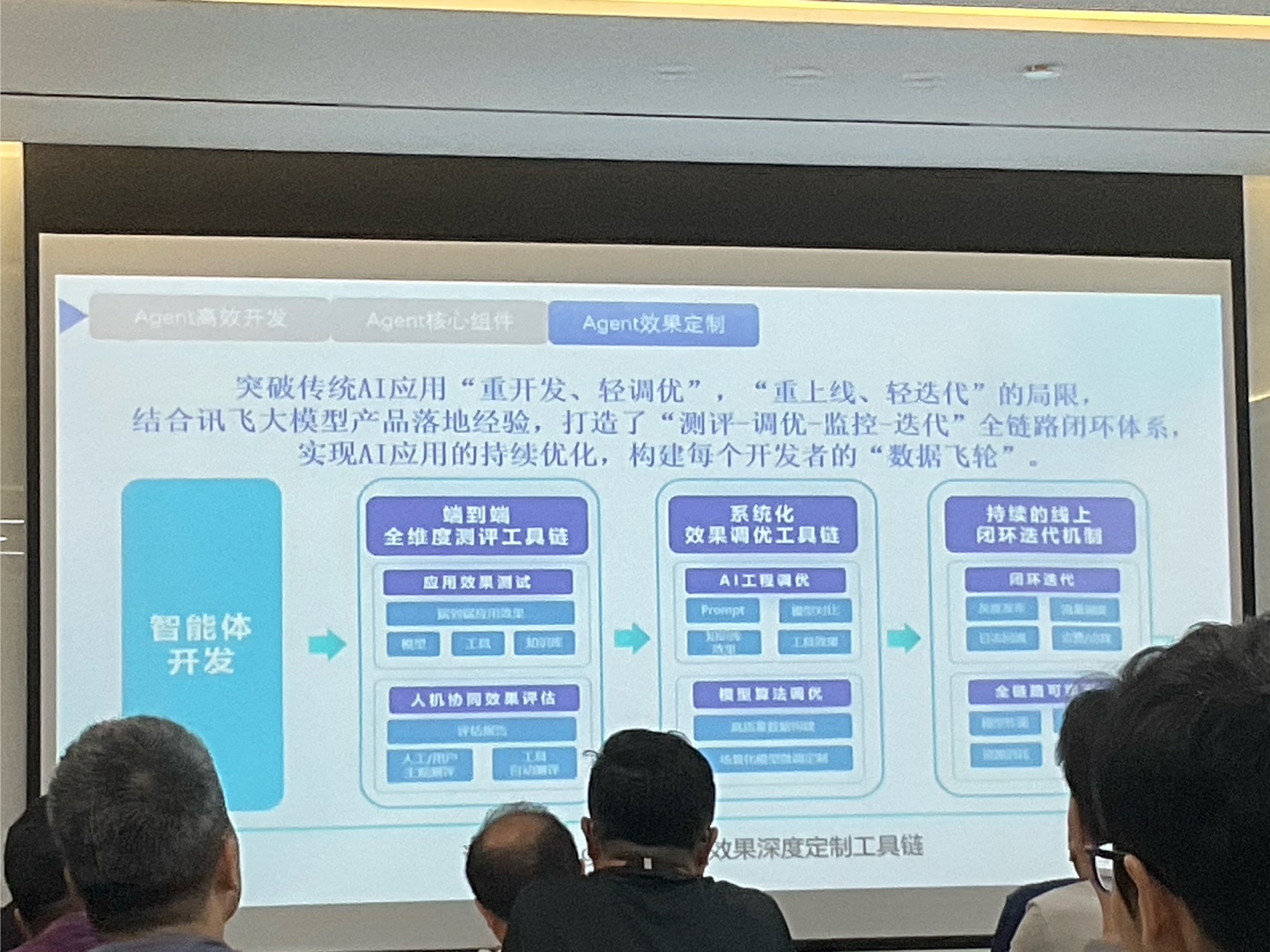

- 例如地铁自助买票,生成json
(如果用市面上的大模型,一方面成本高效果一般,另一方面响应时间长
- 例如,高德调用星火agent查询api
- 例如,基于上下文的ai辩论

# 星火文旅智能未来,方天圣华
- 5g + ar 落地



- 亚马逊云社区
 ?
?