SVM算法实战应用
目录
用 SVM 实现鸢尾花数据集分类:从代码到可视化全解析
一、算法原理简述
二、完整代码实现
三、代码解析
1. 导入所需库
2. 加载并处理数据
3. 划分训练集和测试集
4. 训练 SVM 模型
5. 计算决策边界参数
6. 生成决策边界数据
7. 绘制样本点
8. 绘制决策边界
9. 设置坐标轴范围
10. 标记支持向量
11. 显示图像
用 SVM 实现鸢尾花数据集分类:从代码到可视化全解析
支持向量机(SVM)是一种经典的机器学习算法,特别适合处理小样本、高维空间的分类问题。本文将通过鸢尾花(Iris)数据集,从零开始实现基于 SVM 的分类任务,并通过可视化直观展示分类效果。
一、算法原理简述
SVM 的核心思想是寻找最大间隔超平面,通过这个超平面将不同类别的数据分开。对于线性可分的数据,存在无数个可分超平面,SVM 会选择距离两类数据最近点(支持向量)距离最大的那个超平面,从而获得更好的泛化能力。
当数据线性不可分时,SVM 可以通过核函数将低维数据映射到高维空间,使其在高维空间中线性可分。本文使用线性核(kernel='linear')进行演示,适合处理线性可分的鸢尾花数据集。
二、完整代码实现
下面是基于鸢尾花数据集的 SVM 分类完整代码,包含数据加载、模型训练、决策边界可视化等功能:部分数据集如下:
import pandas as pd
from sklearn.svm import SVC
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import metrics# 1. 加载数据
f = pd.read_csv('iris.csv') # 读取鸢尾花数据集# 2. 数据划分(按类别拆分用于可视化)
data = f.iloc[:50,:] # 第一类数据(前50条)
data1 = f.iloc[50:,:] # 后两类数据(第50条之后)# 3. 准备特征和标签
x = f.iloc[:,[1,3]] # 选择第2列和第4列作为特征(萼片宽度和花瓣宽度)
y = f.iloc[:,-1] # 最后一列为标签(花的类别)# 4. 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0) # 20%数据作为测试集# 5. 初始化并训练SVM模型
svm = SVC(kernel='linear', C=1, random_state=0) # 线性核,正则化参数C=1
svm.fit(x_train, y_train)# 6. 获取模型参数(用于绘制决策边界)
w = svm.coef_[0] # 权重系数
b = svm.intercept_[0] # 偏置项# 7. 生成决策边界数据
x1 = np.linspace(0,7,300) # 生成300个从0到7的均匀点
x2 = -(w[0]*x1 + b)/w[1] # 决策边界公式:w0*x1 + w1*x2 + b = 0 → 求解x2
x3 = 1 + x2 # 边界1(决策边界+1)
x4 = -1 + x2 # 边界2(决策边界-1)# 8. 绘制散点图(样本点)
plt.scatter(data.iloc[:,1], data.iloc[:,3], marker='+', color='b', label='第一类')
plt.scatter(data1.iloc[:,1], data1.iloc[:,3], marker='*', color="r", label='其他类别')# 9. 绘制决策边界
plt.plot(x1, x3, linewidth=1, color='r', linestyle='--', label='边界1')
plt.plot(x1, x2, linewidth=2, color='r', label='决策边界')
plt.plot(x1, x4, linewidth=1, color='r', linestyle='--', label='边界2')# 10. 设置坐标轴范围
plt.xlim(4,7)
plt.ylim(0,5)# 11. 标记支持向量
vets = svm.support_vectors_ # 获取支持向量
plt.scatter(vets[:,0], vets[:,1], c='b', marker='x', label='支持向量')# 12. 添加图例和标题
plt.legend()
plt.title('SVM分类鸢尾花数据集(线性核)')
plt.show()# 13. 模型评估
y_pred = svm.predict(x_test)
print("模型准确率:", metrics.accuracy_score(y_test, y_pred))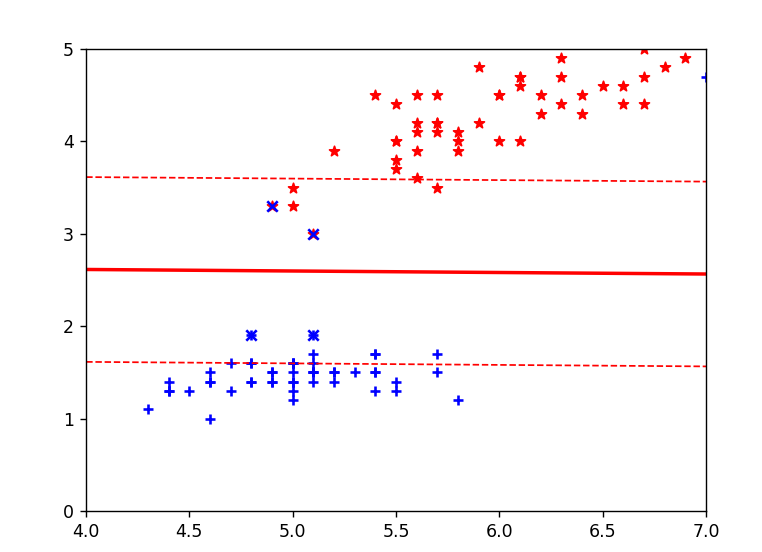
三、代码解析
1. 导入所需库
import pandas as pd # 用于数据处理和分析
from sklearn.svm import SVC # 从sklearn库导入支持向量分类器
import numpy as np # 用于数值计算
import matplotlib.pyplot as plt # 用于数据可视化
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集
from sklearn import metrics # 用于模型评估2. 加载并处理数据
f = pd.read_csv('iris.csv') # 读取鸢尾花数据集(CSV格式)鸢尾花数据集包含 100 条样本,分为 2类鸢尾花,每条样本有 4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和 1 个标签(花的类别)。
data = f.iloc[:50,:] # 取前50条数据(第一类鸢尾花,通常是setosa)
data1 = f.iloc[50:,:] # 取第50条之后的数据(后两类鸢尾花,通常是versicolor和virginica)这里按行索引拆分数据,用于后续可视化时区分不同类别。
x = f.iloc[:,[1,3]] # 选择特征:取所有行的第2列(索引1)和第4列(索引3)
y = f.iloc[:,-1] # 选择标签:取所有行的最后一列(花的类别)- 特征选择第 2 列和第 4 列(通常对应花萼宽度和花瓣宽度),便于二维可视化
- 标签为最后一列(花的种类)
3. 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0) # 划分数据集x_train:训练集特征(80% 的数据)x_test:测试集特征(20% 的数据)y_train:训练集标签y_test:测试集标签test_size=0.2:测试集占比 20%random_state=0:随机种子,保证每次运行划分结果一致
4. 训练 SVM 模型
svm = SVC(kernel='linear', C=1, random_state=0) # 初始化SVM模型
svm.fit(x_train, y_train) # 用训练集训练模型kernel='linear':使用线性核函数(适用于线性可分数据)C=1:正则化参数,控制对误分类的惩罚程度(值越大惩罚越重)random_state=0:随机种子,保证结果可复现fit():训练模型,通过训练集学习特征与标签的关系
5. 计算决策边界参数
w = svm.coef_[0] # 获取权重系数(对于线性核,shape为[特征数])
b = svm.intercept_[0] # 获取偏置项(截距)对于线性 SVM,决策边界是一个超平面,二维情况下是一条直线,公式为:
![]()
(其中(w0, w1)是权重,b是偏置,(x1, x2)是两个特征)
6. 生成决策边界数据
x1 = np.linspace(0,7,300) # 生成300个从0到7的均匀点(作为x轴数据)
x2 = -(w[0]*x1 + b)/w[1] # 计算决策边界的y值(由超平面公式推导)
x3 = 1 + x2 # 决策边界上方的辅助线(间隔边界)
x4 = -1 + x2 # 决策边界下方的辅助线(间隔边界)x1是横轴坐标,x2是决策边界在对应x1处的纵轴坐标x3和x4是决策边界两侧的间隔边界,用于展示 SVM 的 "最大间隔" 特性
7. 绘制样本点
# 绘制第一类样本(蓝色+号)
plt.scatter(data.iloc[:,1], data.iloc[:,3], marker='+', color='b')
# 绘制后两类样本(红色*号)
plt.scatter(data1.iloc[:,1], data1.iloc[:,3], marker='*', color="r")scatter():绘制散点图data.iloc[:,1]和data.iloc[:,3]:分别取第一类样本的第 2 列和第 4 列特征作为 x、y 坐标marker:指定点的形状(+ 号和 * 号区分不同类别)
8. 绘制决策边界
plt.plot(x1, x3, linewidth=1, color='r', linestyle='--') # 上方间隔边界(虚线)
plt.plot(x1, x2, linewidth=2, color='r') # 决策边界(实线)
plt.plot(x1, x4, linewidth=1, color='r', linestyle='--') # 下方间隔边界(虚线)plot():绘制直线- 红色实线是 SVM 找到的最优决策边界,虚线是间隔边界,两条虚线之间的距离是 "最大间隔"
9. 设置坐标轴范围
plt.xlim(4,7) # x轴范围设置为4到7
plt.ylim(0,5) # y轴范围设置为0到5限制坐标轴范围,使图像聚焦在样本密集区域,更清晰地展示分类效果。
10. 标记支持向量
vets = svm.support_vectors_ # 获取支持向量(距离决策边界最近的样本点)
plt.scatter(vets[:,0], vets[:,1], c='b', marker='x') # 用x标记支持向量- 支持向量是决定决策边界位置的关键样本,SVM 的决策仅由这些点决定
vets[:,0]和vets[:,1]:支持向量的两个特征值
11. 显示图像
plt.show() # 显示绘制的图像总结
这段代码的核心逻辑是:
- 加载鸢尾花数据集并选择特征
- 划分训练集和测试集
- 训练线性 SVM 模型
- 计算并绘制决策边界、间隔边界
- 可视化样本点和支持向量